动态误分类代价下代价敏感属性选择分治算法
2018-02-07黄伟婷
黄伟婷,赵 红
1.闽南师范大学 计算机学院,福建 漳州 363000
2.闽南师范大学 粒计算及其应用重点实验室,福建 漳州 363000
1 引言
代价敏感学习是数据挖掘的十大最具挑战性问题之一[1]。代价是在数据的获取或处理过程中产生的,是数据不可分割的一部分,将其引入数据挖掘是解决实际问题的必然趋势。现实中的代价有很多类,Turney[2]提出了代价分类法,常见的有测试代价和误分类代价。近十年来,代价敏感学习的研究受到越来越多学者的关注,被广泛应用到医学[3]、模式识别[4-5]、统计学[6]、经济[7]等各个研究领域。
属性选择是数据挖掘中最活跃和重要的研究问题之一。代价敏感属性选择问题是经典属性选择问题的自然扩展。代价敏感属性选择的目的是通过权衡测试代价和误分类代价,得到总代价最小的属性子集。代价敏感属性选择问题经过多年的研究,有了长足的进展。Min等[8]定义了代价敏感决策系统模型,并在回溯算法中引入三种有效的剪枝技术,以解决最小代价属性选择问题。文献[9]提出了一种指数加权算法,通过对属性重要度进行加权处理,来提高算法的效率。文献[10]设计了新的代价敏感适应度函数,并运用于遗传搜索算法,解决了代价敏感属性选择问题。Zhao等[11]定义了基于置信水平的覆盖粗糙集模型,研究了不同粒度下的代价敏感属性选择方法。文献[12]定义了新的属性重要度函数,并给出了缺失值数据下的多目标属性选择方法。文献[13]提出了四种相对评价指标,并利用粒子群优化方法来解决代价敏感属性选择问题。文献[14]基于自适应邻域模型,对异构数据进行了测试代价敏感属性约简研究。
目前,多数的代价敏感属性选择算法均采用静态误分类代价机制,即事先统一假定为某一固定值,与算法所选择的属性子集无关。而在现实问题中,为了减少误分率,往往需要增加检测。此时,若仍然错分,则惩罚加重,误分类代价会相应地增大。如在金融诈欺中,识别过程越长,所遭受的损失越大。因此,如果采用固定的误分类代价,就会忽略误分类代价与所选属性子集的相关性,这跟现实问题不太相符。另外,在实际应用中,类别不平衡[15]的数据集往往存在着误分类代价不等的问题。如在医疗诊断中,将正常人误分类为病人,将影响其正常工作和生活,并付出治疗费用;而将病人误分类为正常人,则会延误病情,甚至导致生命危险。显然,后者所付出的代价远大于前者。
为此,本文定义一种新的动态误分类代价机制,考虑数据集类别不平衡的情况,根据所选属性子集动态生成最优误分类代价,并提出了动态误分类代价下的代价敏感属性选择分治算法。该算法结合分治法,将大规模数据集分解为多个独立的、规模较小的子数据集,缩小了问题的规模,从而提高了算法的效率。实验结果验证了算法的有效性。
2 动态误分类代价下的代价敏感决策系统
本章主要介绍代价敏感决策系统和动态误分类代价机制,并在此基础上给出动态误分类代价下的代价敏感决策系统及其相关定义。
2.1 代价敏感决策系统
定义1代价敏感决策系统是一个七元组[8]:S=(U,C,D,V={Va|a∈C∪D},I={Ia|a∈C∪D},tc,smc),其中U是对象集合,C是条件属性集合,D是决策属性集合,Va是属性a的值集合,Ia:U→Va是一个信息函数,tc:C→R+∪{0}是独立测试代价函数,smc:k×k→R+∪{0}是静态误分类代价函数,k=|ID|。
独立测试代价函数tc可以用一个代价向量tc=[tc(a1),tc(a2),…,tc(a|c|)]来表示。对任意属性子集B⊆C,属性子集B的测试代价为静态误分类代价函数smc可以用一个k×k矩阵来表示。smc(i,j)表示将类别i误分为类别 j所导致的固定代价,通常smc(i,i)=$0。
一个代价敏感决策系统如表1和表2所示,静态误分类代价矩阵

表1 一个决策系统

表2 测试代价向量
2.2 动态误分类代价机制
现有的大多数代价敏感属性选择算法,并未考虑所选属性子集对误分类代价的影响,而是对不同的数据集及其不同的属性子集预先设置相同的误分类代价。然而,在实际问题中,随着检测的属性越多,错分时所遭受的惩罚会越重。可见,误分类代价与所选属性子集之间具有一定的相关性。同时,在现实数据集中,类分布不均衡的情况是普遍存在的,错分少数类所付出的代价往往大于错分多数类所付出的代价。这里,假设类别i为少数类,类别j为多数类,对任意属性子集B⊆C,定义动态误分类代价dmc(B)为:

其中,当i≠j时,dmc(B)(i,j)为错分少数类的误分类代价,dmc(B)(j,i)为错分多数类的误分类代价,α和β为调整参数,以保证所得到的总代价最小。图1给出了数据集Voting,在参数β值取1时,不同参数α值下总代价的变化情况。可见,dmc(B)(i,j)过大时,会使得总代价加大,通过参数α可以调整dmc(B)(i,j)的大小。同时,当数据集的规模增大时,所选属性子集的大小会随之变大,使得总代价增加。图2给出了数据集Voting和Kr-vs-kp,在参数α值取0.1时,不同参数β值下总代价的对比情况。显然,对于不同规模的数据集,为使得总代价最小,应根据数据集的规模分别设置参数β的值。
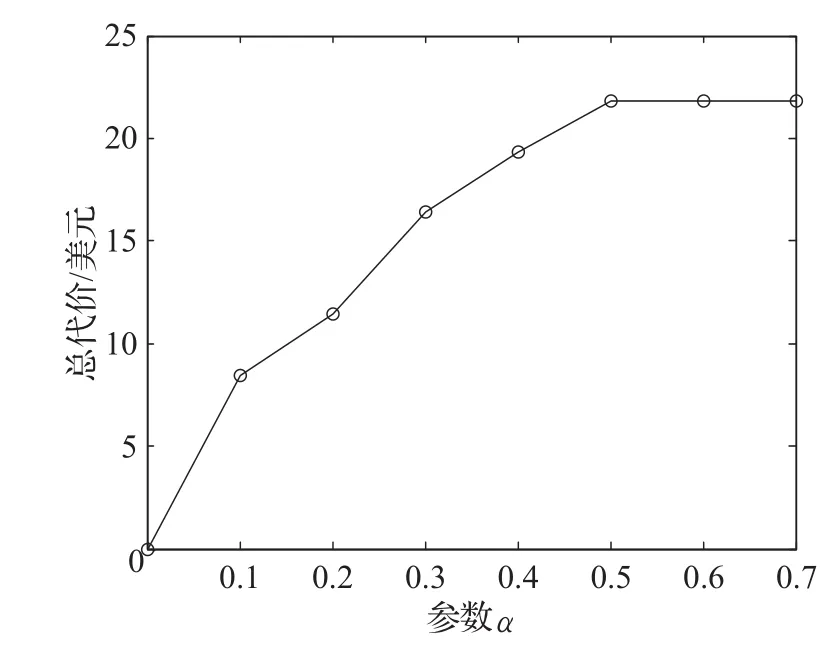
图1 不同参数α值下的总代价

图2 不同参数β值下的总代价
以表1和表2为例,“d=0”为多数类,“d=1”为少数类,若B={a2,a5},α=0.5,β=1,由式(1)可得,dmc(B)(1,0)=
2.3 动态误分类代价下代价敏感决策系统
定义2动态误分类代价下的代价敏感决策系统是一个七元组:S=(U,C,D,V,I,tc,dmc),其中U、C、D、V、I和tc的定义与定义1中相同,dmc:k×k→R+∪{0}是动态误分类代价函数,k=|ID|,可以用一个k×k矩阵来表示,矩阵元素值由式(1)计算得到。
为了评价所选属性子集的优劣,引入平均总代价概念。设B为一个属性子集,IND(B)为U的一个划分,对象集合U′∈IND(B),U′的动态误分类代价记为dmc(U′,B),平均动态误分类代价(Average Dynamic Misclassification Cost,ADMC)表示为:
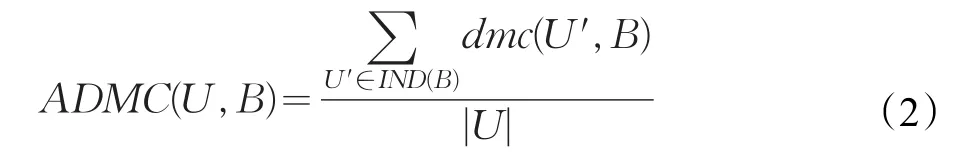
平均总代价(Average Total Cost,ATC)表示为:
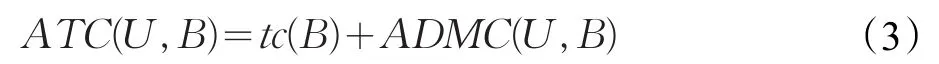
定义3设S是一个动态误分类代价下的代价敏感决策系统,对于任意属性子集B⊆C,当且仅当满足ATC(U,B)=min{ATC(U,B′)|B′⊆C},则称 B为最小平均总代价属性子集。
3 动态误分类代价下的代价敏感属性选择
本章将介绍分治法,并给出动态误分类代价下的代价敏感属性选择分治算法。
3.1 分治法
目前,有些代价敏感属性选择算法存在效率低的问题,特别是对大规模数据集。分治法是一种简单的粒计算方法,它将一个大的、难以直接解决的问题,分割成若干个问题相同且规模较小的子问题,以便逐一解决,分而治之。这将会节省时间,提高计算效率。显然,分治法是一种处理大规模数据集的高效算法。
3.2 动态误分类代价下代价敏感属性选择分治算法
代价敏感属性选择问题是在测试代价和误分类代价之间权衡,使得所选属性子集的总代价最小。为解决该问题,本文提出了动态误分类代价下代价敏感属性选择分治算法(以下简称为算法1),算法思想以流程图形式表示,如图3所示。

图3 算法1流程图
在算法1中,参数size表示初始每个子数据集所包含的条件属性个数,参数k表示每次参与合并的子数据集个数。为了控制每个子数据集的大小,并保证多路合并时有足够多的子数据集,参数size值可根据各数据集规模的不同而变化。当参数size≤|C|/k时,能够保证多路合并的有效性。若参数k=1,即参数size=|C|时,算法1退化为经典的回溯算法。同时,为了提高算法的效果,在对各子数据集求解时,采用了竞争策略。
4 实验结果与分析
为验证算法1的有效性,本文从UCI中选取六个不同规模的数据集进行实验,并通过复制数据集Mushroom生成数据集DS。各数据集的描述如表3所示,其中|C|表示条件属性的个数,|U|表示对象个数。因篇幅关系,本章的所有表中只列出各数据集的编号(No.),其编号和表3中的一致。另外,本章的所有图中将“Housevotes-84”简写为“HV84”。
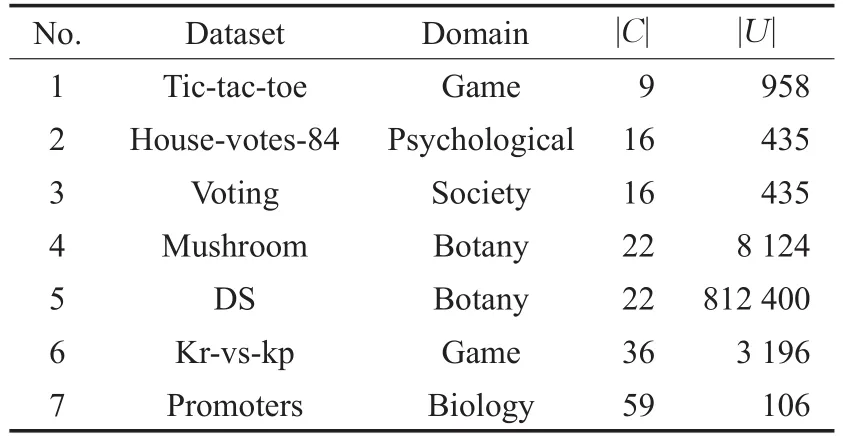
表3 数据集信息
由于UCI数据集自身并不含测试代价,因此本文采用Uniform和Normal两种分布方式[16]来生成测试代价,测试代价为[1,10]区间内的整数。这两种分布方式是日常生活中常见的概率分布,模拟了现实生活中不同的应用,表明了算法能适用于不同的代价分布。为保证多路合并的有效性,本文根据数据集规模自适应生成参数size的值,设置参数。另外,本文将参数α值设为0.1,参数β值根据数据集的规模分别设置:对前五个数据集,参数β值设为1;对后两个数据集,参数β值设为0.3。本章的所有柱状图中,柱体的总高度均表示各数据集的平均总代价,而柱体空白部分的高度均表示各数据集的测试代价。
4.1 算法的效果
为了分析参数k对算法1的效果和效率的影响,这里,参数k值分别设为2、3和4进行对比实验,实验结果如图4、表4和表5所示。
从图4和表4可以看出:
(1)在前六个数据集中,随着参数k值的增大,测试代价和平均总代价基本保持不变或减小。当参数k=2时,数据集Promoters的测试代价为$0。
(2)在各数据集上,随着参数k值的增大,运行时间均减少,特别是对最后三个数据集。

图4 不同参数k值下的平均总代价对比
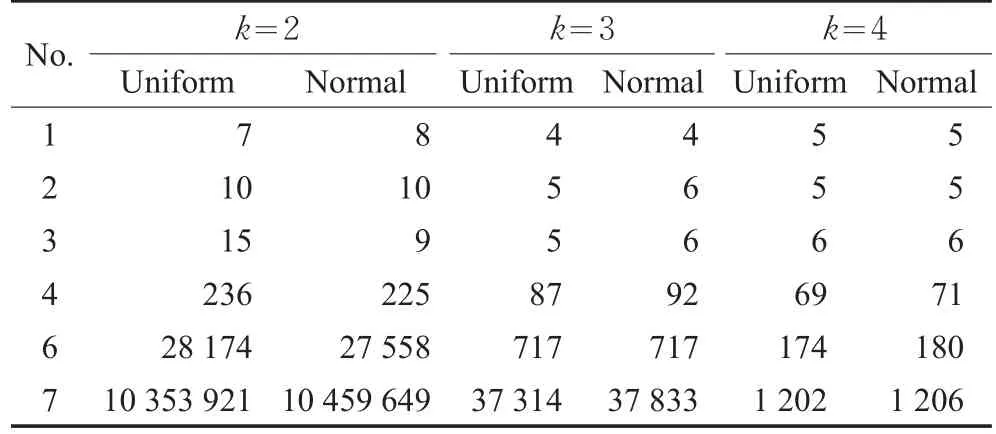
表4 不同参数k值下的运行时间对比 ms
(3)从以上分析可见,当参数k值增大时,既保证了算法的效果,也提高了算法的效率,说明该分治算法是有效的。
表5列出了各数据集在不同参数k值下,由式(1)生成的动态误分类代价。从表5可以看出:
(1)对于同一数据集,随着参数k值的增大,各数据集的动态误分类代价的变化不大,保证了该分治算法的稳定性。
(2)对于不同规模的数据集,在参数β的调节作用下,动态误分类代价未发生显著变化,说明参数β的调节是有效的,其值应根据数据集的规模分别设置。
准确率是平均误分类代价的特例。当误分类代价矩阵主对角线上的值均为0,且副对角线上的值均相等时,最小化平均误分类代价等价于最大化准确率[8]。为了计算算法1下的准确率,设置dmc(0,1)=dmc(1,0)=280×|C|,并选取小规模数据集Voting、中等规模数据集Mushroom和大规模数据集DS进行实验。实验运行100次,统计平均总代价等于测试代价的概率,从而得到准确率,实验结果如表6所示。从表6可以看出,随着参数k值的增大,准确率更好。
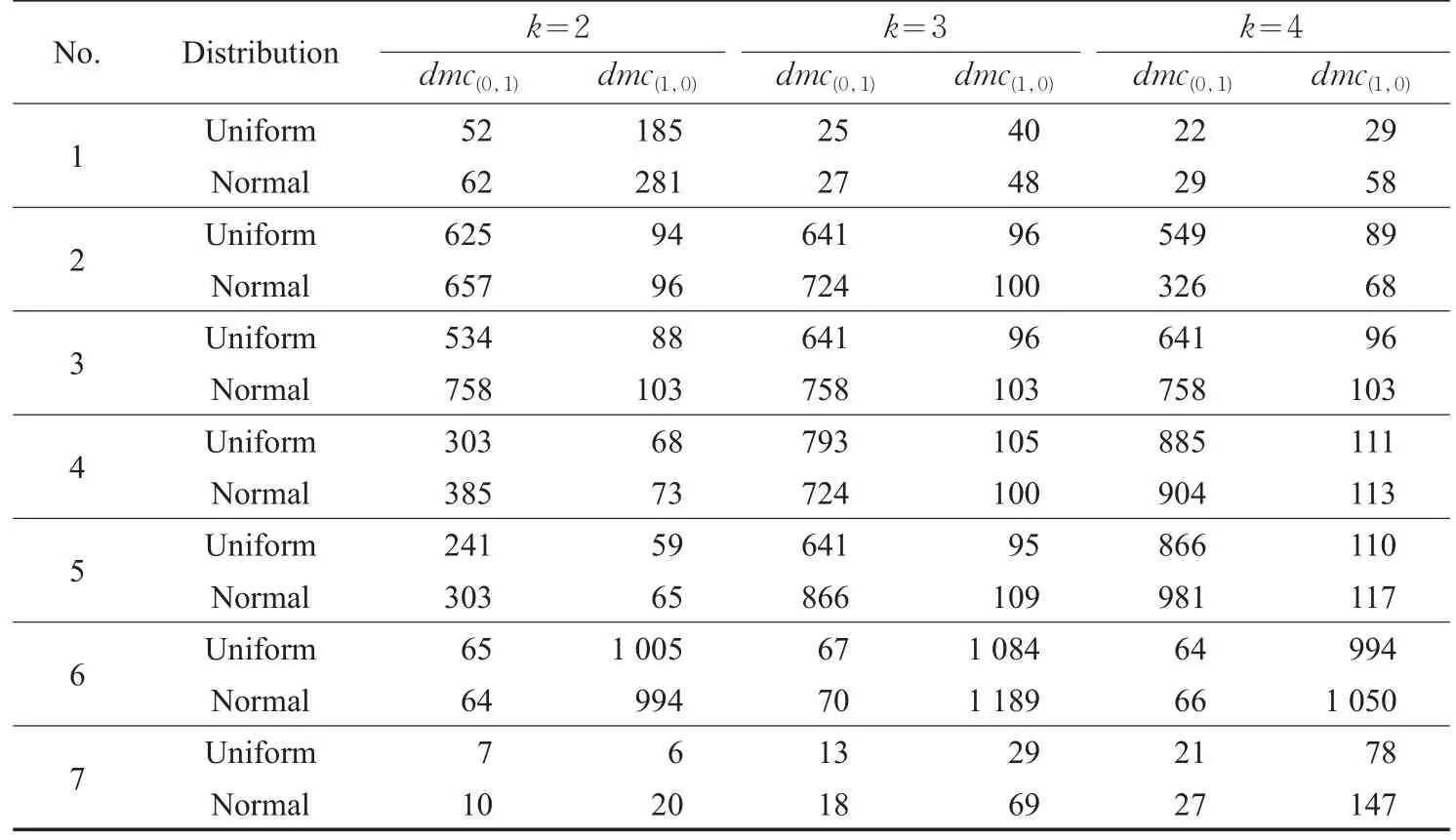
表5 不同参数k值下的动态误分类代价 美元

表6 不同参数k值下的准确率对比
4.2 算法的有效性
为了验证动态误分类代价机制的有效性,本文取参数k=3,分别在静态误分类代价机制和动态误分类代价机制下进行算法1的对比实验,实验结果如图5和表7所示。在静态误分类代价机制下,设置smc(0,1)=$800,smc(1,0)=$200;而动态误分类代价则由式(1)生成。
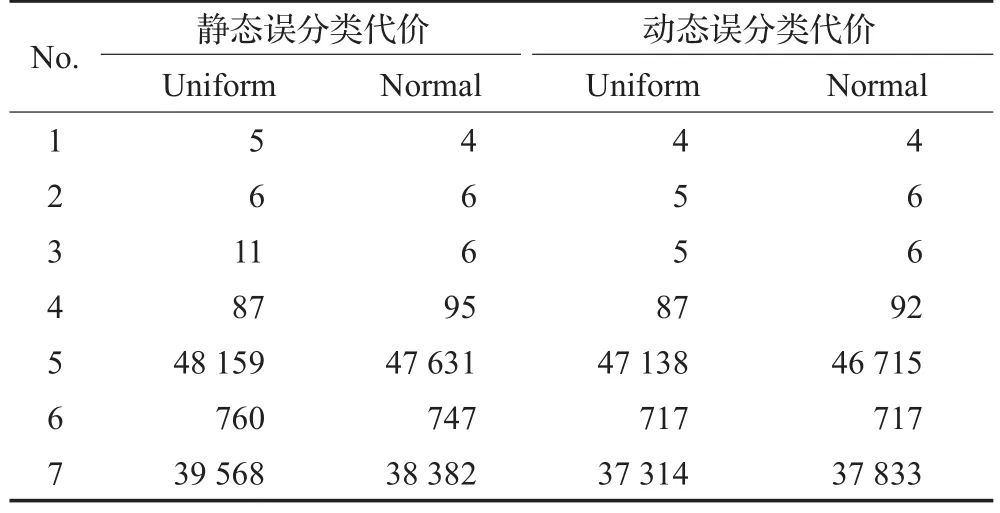
表7 两种误分类代价机制下的运行时间对比 ms
从图5和表7可以看出:
(1)动态误分类代价下的平均总代价和测试代价均小于或等于静态误分类代价下的平均总代价和测试代价。
(2)在前四个数据集上,两种误分类代价机制下的运行时间基本相同;在后三个数据集上,动态误分类代价下的运行时间较少,特别是数据集DS和Promoters上的运行时间差距明显。

图5 两种误分类代价机制下的平均总代价对比
(3)从以上分析可见,采用动态误分类代价机制,可以在不影响算法效率的同时,提高算法的效果,说明该动态误分类代价机制是有效的。
4.3 几种算法的实验对比
为进一步验证算法1的有效性,本节选取了表3中的四个数据集House-votes-84、Voting、DS和Kr-vs-kp,在Uniform分布方式下,将算法1、文献[8]的回溯算法和文献[9]的启发式算法进行对比实验,实验结果如图6和表8所示。在算法1中,参数k值设为3,动态误分类代价由式(1)生成;在另两个算法中,设smc(0,1)=$1 200,smc(1,0)=$300。

图6 Uniform分布下三种算法平均总代价对比

表8 Uniform分布下三种算法运行时间对比ms
从图6和表8可以看出:
(1)在数据集House-votes-84、Voting和Kr-vs-kp上,算法1的测试代价和平均总代价均小于其他两个算法。在数据集DS上,回溯算法的效果最好,算法1略好于启发式算法。
(2)在这四个数据集上,算法1的运行时间均小于其他两个算法,特别是在数据集DS和Kr-vs-kp上,算法1的运行时间明显减少。
(3)从以上分析可见,算法1的整体性能优于其他两种算法,并且在较大规模数据集上的效率明显高于其他两种算法,说明动态误分类代价下的代价敏感属性选择分治算法是有效的。
5 结束语
本文针对静态误分类代价机制的不足,考虑了误分类代价与所选属性子集之间的相关性,设计了动态误分类代价函数,并结合分治思想,提出了动态误分类代价下的代价敏感属性选择分治算法,最后从多方面进行了对比实验。实验结果表明,相对于静态误分类代价机制,本文所提出的算法能在提高计算效率的同时改善运行效果,验证了该分治算法和动态误分类代价机制的有效性。本文仅对动态误分类代价机制进行了初步的探讨,在今后的工作中:(1)除了用初等函数来表示动态误分类代价,还可以采用复合函数来表示动态误分类代价。(2)在复合函数中,除了考虑动态误分类代价与属性子集的相关性,是否还可以考虑与数据集样本数的关系。动态误分类代价是实际应用中存在的客观问题,有待进一步研究。
[1]Yang Qiang,Wu Xindong.10 challenging problems in data mining research[J].InternationalJournalofInformation Technology&Decision Making,2006,5(4):597-604.
[2]Turney P D.Types of cost in inductive concept learning[C]//Proceedings of the Workshop on Cost-Sensitive Learning at the 17th ICML,California,2000:15-21.
[3]Hsu J L,Hung P C,Lin H Y,et al.Applying undersampling techniques and cost-sensitive learning methods on risk assessment of breast cancer[J].Journal of Medical Systems,2015,39(4):1-13.
[4]Fan Jianping,Zhang Ji,Mei Kuizhi,et al.Cost-sensitive learning of hierarchical tree classifiers for large-scale image classification and novel category detection[J].Pattern Recognition,2015,48(5):1673-1687.
[5]Li Huaxiong,Zhang Libo,Huang Bing,et al.Sequential three-way decision and granulation for cost-sensitive face recognition[J].Knowledge-Based Systems,2016,91:241-251.
[6]Lu J,Liong V E,Zhou J.Cost-sensitive local binary feature learning for facial age estimation[J].IEEE Transactions on Image Processing,2015,24(12):5356-5368.
[7]Jahromi A T,Stakhovych S,Ewing M.Customer churn models:a comparison of probability and data mining approaches[M]//Looking forward,looking back:drawing on the past to shape the future of marketing.[S.l.]:Springer International Publishing,2016:144-148.
[8]Min F,Zhu W.Minimal cost attribute reduction through backtracking[M]//Database theory and application,bioscience and bio-technology.Berlin/Heidelberg:Springer,2011:100-107.
[9]Li Xiangju,Zhao Hong,Zhu W.An exponent weighted algorithm for minimal cost feature selection[J].International Journal of Machine Learning and Cybernetics,2014:1-10.
[10]Weiss Y,Elovici Y,Rokach L.The CASH algorithm-costsensitive attribute selection using histograms[J].Information Sciences,2013,222:247-268.
[11]Zhao Hong,Zhu W.Optimal cost-sensitive granularization based on rough sets for variable costs[J].Knowledge-Based Systems,2014,65:72-82.
[12]Shu Wenhao,Shen Hong.Multi-criteria feature selection on cost-sensitive data with missing values[J].Pattern Recognition,2016,51:268-280.
[13]Dai Jianhua,Han Huifeng,Hu Qinghua,et al.Discrete particle swarm optimization approach for cost sensitive attribute reduction[J].Knowledge-Based Systems,2016.
[14]Fan Anjing,Zhao Hong,Zhu W.Test-cost-sensitive attribute reduction on heterogeneous data for adaptive neighborhood model[J].Soft Computing,2015:1-12.
[15]Krawczyk B,Woźniak M,Schaefer G.Cost-sensitive decision tree ensembles for effective imbalanced classification[J].Applied Soft Computing,2014,14:554-562.
[16]Min Fan,He Huaping,Qian Yuhua,et al.Test-cost-sensitive attribute reduction[J].Information Sciences,2011,181(22):4928-4942.
