基于自适应花授粉算法的BP神经网络结构优化
2018-02-07卞京红贺兴时范钦伟伊宝民
卞京红,贺兴时,范钦伟,伊宝民
1.西安工程大学 理学院,西安 710048
2.长安大学 工程机械学院,西安 710064
1 引言
BP神经网络是由Rumelhart等人于1986年提出的一种误差反向传播网络,由于其具有较强的学习能力、灵活的非线性建模能力以及大规模的并行计算能力,从而受到了学者的广泛关注,已经被广泛应用于图像处理[1]、经济预测[2]及网络分类器[3]等领域。传统BP神经网络是通过梯度下降法来调整网络中的权值和阈值,因此初始权值和阈值的选取对网络的学习结果起着至关重要的作用,特别对于高维冗余的样本数据,如果选取的初始值不好,则极易导致训练结果陷入局部最优,因而限制了网络的泛化能力及学习能力。为了解决BP神经网络存在的问题,很多学者利用智能算法(如遗传算法[4]、粒子群算法[5-6]、蚁群算法[7]、生物地理学算法[8]等)来优化神经网络的初始权值和阈值,但是仍未解决其收敛速度慢、易陷入局部最优等缺陷,因此本文提出利用全局寻优能力较好的花授粉算法来优化BP网络的结构。
花授粉算法(Flower Pollination Algorithm,FPA)是由杨新社学者于2012年提出的一种新型启发式算法[9],由于该算法具有结构简单、参数较少、无需梯度信息、易于实现等优点,已被广泛地应用到解决约束优化以及多目标优化[10]等问题中。但是由于FPA算法存在后期收敛速度慢等缺陷,使其应用受到限制,因此为了更好地利用FPA算法对BP神经网络的权值和阈值进行优化,本文首先对FPA算法中的转换概率做自适应调整,并在局部授粉过程中引入自适应的变异因子,提出了一种自适应的花授粉算法(SFPA)。
利用启发式算法优化网络权值和阈值的方式通常有两种:第一,将通过启发式算法得到的权值和阈值的组合直接作为BP网络开始训练的初始权值和阈值[11];第二,将启发式算法与BP网络融合成一个新的网络,在每次训练中,先运行一次算法得到权值和阈值的组合,把得到的组合作为BP算法训练的初始值,然后运行一次BP算法,从而完成一次训练[12]。文中利用这两种方式将SFPA算法与BP神经网络进行结合,从而提出了基于自适应花授粉算法的BP神经网络,且利用第一种方法得到SFPA1-BP网络,利用第二种方式得到SFPA2-BP网络。
2 BP神经网络和花授粉算法
2.1 BP神经网络
Cybenko[13]等人已经从理论上证明,单隐含层的BP神经网络能够以任意精度逼近任何非线性函数,因此本文只对单隐层的BP神经网络进行研究。
假设BP神经网络的输入层节点数为n,隐层节点数为m,输出层节点数为s,即BP神经网络结构为:n-m-s,选择可微非线性Sigmoid函数作为BP神经网络的激活函数,即激活函数为:f(x)=1(1+e-x)。在BP网络训练开始之前,首先随机初始化网络的权值和阈值,然后利用训练样本,通过网络输出值与理论值之间误差的反向传播来调节权值和阈值,以使网络的输出值与理论值之间的误差梯度下降,当误差达到要求时,BP神经网络的权值和阈值即得到确定,此即BP神经网络的训练过程,其具体训练过程如文献[1]中所述。
2.2 花授粉算法
在FPA算法中,为了更好地模拟全局授粉过程和局部授粉过程,做以下假设[9]:
(1)非生物的自花授粉可以看做是局部授粉过程。
(2)交叉授粉是携带花粉配子的传播者,通过Lévy飞行进行全局授粉。
(3)花的常性即繁衍概率,繁衍概率与所参与的两朵花的相似性成比例关系。
(4)转换概率p∈[0,1]控制着全局授粉和局部授粉之间的转换。
在FPA的初始阶段,随机产生一个由N个个体组成的种群X=(X1,X2,…,XN),其中第i个粒子为一个D维向量,代表第i个花粉在D维搜索空间中的位置,即表示优化问题的一个潜在解,其中D是优化问题的维数,t是当前迭代次数。N为种群的大小,代表解的多样性,表示的是每次都有N个个体进行迭代,在算法的运行过程中,种群数一般设定在10~30之间,在本文的数值实验中,设种群数N为20。
全局授粉的过程如下:

局部授粉的过程如下:

在FPA算法迭代之前先产生一个随机数rand∈(0,1),若p>rand,则执行式(1)的全局搜索,若p≤rand,则执行式(2)的局部搜索,即利用转换概率p控制全局授粉和局部授粉的执行概率,使算法能够利用群体全局信息以及个体局部信息进行协同搜索。
FPA算法与其他智能算法同样存在易陷入局部最优且收敛速度慢等缺陷。为改进智能算法存在的不足,众多学者对此进行了深入的研究。杨帆等人[14]对粒子群算法的惯性权重进行自适应的调整,通过信息素浓度以及粒子在搜索空间中分布的先验知识来确定各个惯性权重的选择概率,从而提出了一种基于蚁群系统的惯性权重自适应蚁群算法(AS-PSO),并通过实验证明AS-PSO的收敛速度和解的精度方面优于标准PSO;Xie等人在文献[15]中,对遗传算法中的遗传算子进行自适应调整,并将提出的自适应遗传算法应用在多目标优化问题中得到较好的结果;李宏在文献[16]中对标准的粒子群优化算法引入了两个自适应加速因子,并对粒子群优化算法的权函数做了改进,若算法陷入局部最优值,则采用新的粒子更新方式,从而提出了一种自适应的粒子群优化算法,并将其应用到图像分割问题中。
在本文中,为了更好地利用花授粉算法对BP神经网络的结构进行优化,首先对花授粉算法中的转换概率及变异因子进行自适应的调整,提出了一种自适应的花授粉算法(SFPA),然后利用SFPA来实现对BP神经网络的结构优化。
3 花授粉算法的改进
3.1 对转换概率做自适应调整
在基本花授粉算法中p为常数,即在算法执行过程中,执行全局授粉操作和局部授粉操作的概率是不变的。 但是若p值过大,则执行全局授粉操作的次数较多,此时,算法不易于收敛;若p值过小,则执行局部授粉操作的次数较多,此时易陷入局部最优解,因此,对转化概率p做自适应的调整。在标准FPA算法[9]中表明,当p值取0.8时,算法的性能较好,因此基于自适应参数的p设定为在0.8附近浮动,鉴于转换概率p∈(0,1),所以使用数值0.2控制p值在0.8附近浮动的范围,即自适应p值的计算公式为:

其中,rand1是[0,1]之间产生的随机数,该改进方法能够控制p值过大或过小。在改进后的算法中,每迭代一次,p值更新一次,自适应地调节全局搜索和局部搜索的执行概率,有效地解决了算法的开发能力和探索能力之间的平衡问题,不仅能够避免FPA算法陷入局部最优,同时能够提高算法的收敛速度。
3.2 对变异因子ε的自适应调整
在FPA的局部授粉过程中,利用[0,1]之间的随机数ε来控制第i个花粉的变异概率,若ε过小,那么在执行局部授粉过程时,迭代前后花粉的位置过于紧密,虽然可以遍历所有位置,但需要太多的运行时间,致使算法的收敛速度较慢;若ε过大,则迭代前后花粉的位置过于松散,虽然可以节省大量的运行时间,但跳跃步长过大,不利于找到最优解,因此随机的变异概率会导致算法的收敛速度较慢,或者收敛到较差的解。在文献[17]中,采用了固定因子F作为ε的值来改进FPA的局部授粉过程中,即第i个花粉的变异概率是固定不变的,且证明当F∈(0.25,0.75)时算法的性能较好。因此,对变异因子ε进行如下改进:
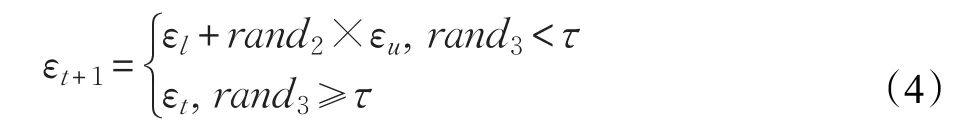
其中rand2,rand3是[0,1]之间产生的随机数,εt是第t次迭代时变异因子的值。利用控制变量法通过实验发现,τ ,εl,εu的值分别取 0.1, 0.1, 0.9时,该算法性能达到最好。ε的初始值ε0为(0.25,0.75)之间的随机数。通过这种改进方法,可以使得ε以较小的可能发生变化,即ε以较大的可能性保持为定值,在算法的进化过程中保持了种群的多样性,有利于提高算法的收敛速度,从而提高了算法的性能。
在对转换概率p及变异因子ε的自适应调整过程中虽然利用了随机向量rand1, rand2, rand3,但事实上这两个参数的变化并不是随机的,自适应参数的基本形式即:选择性、随机化,该自适应方法已经用于遗传算法、粒子群算法、差分进化算法[18]等众多智能算法中。
通过对转化概率做自适应的调整以及引入自适应的变异因子,提出了自适应花授粉算法(SFPA),其实现步骤如下:
步骤1初始化算法的基本参数。设置种群数N,变异因子的初始值ε0,并设置最大迭代次数或搜索精度作为算法结束的条件。
步骤2随机初始化个体的位置,并计算每个个体的的适应度函数值。
步骤3随机生成rand1,并按式(3)计算转换概率p,以调节全局搜索和局部搜索之间的转换。
步骤3.1随机产生rand∈[0,1],若转换概率p>rand,则按式(1)进行全局搜索。
步骤3.2若转换概率p≤rand,按式(4)计算ε,并将ε值代入式(2)中进行局部搜索。
步骤4计算每个花粉的适应度函数值,并找出当前最优解。
步骤5判断是否满足循环结束的条件,若不满足,转步骤3,若满足,转步骤6。
步骤6输出结果,结束算法。
4 基于SFPA算法的BP神经网络结构优化
利用花授粉算法优化BP网络时主要包括以下几个方面。
4.1 数据的归一化处理
利用自适应的花授粉算法(SFPA)优化神经网络时,如果输入样本全部为正值或者负值,那么输入层到隐含层之间的权值只能同时增加或者减小,从而导致网络的学习速率慢等问题。且由于本文中采用Sigmoid函数作为网络的激活函数,因此,通过数据的归一化处理可以避免大量的数据进入饱和区。采用式(5)对数据进行归一化处理:

其中,Xmax,Xmin分别表示训练样本中的最大值和最小值。
4.2 个体编码
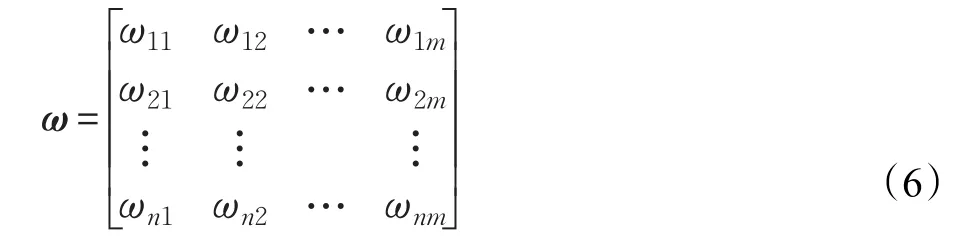
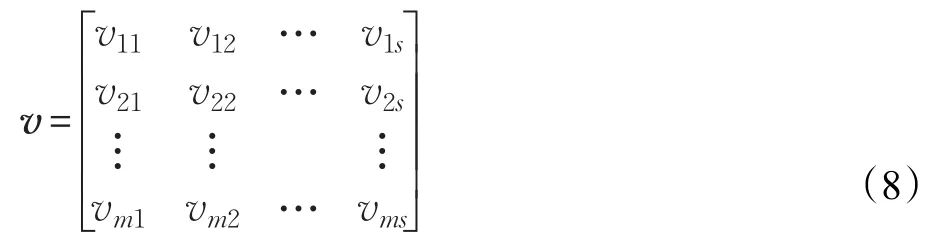
本文采用实数编码的形式将神经网络的连接权值和阈值表示为花粉个体。由于输入层神经元的个数为n,隐层神经元个数为m,输出层神经元的个数为s,则花粉个体的字符串长度为L=n×m+m×s+m+s。
假设输入层到隐含层之间的权值矩阵为:
隐含层的阈值向量为:

隐层到输出层的权值矩阵为:
隐含层到输出层的阈值向量为:

则花粉个体的编码形式为:
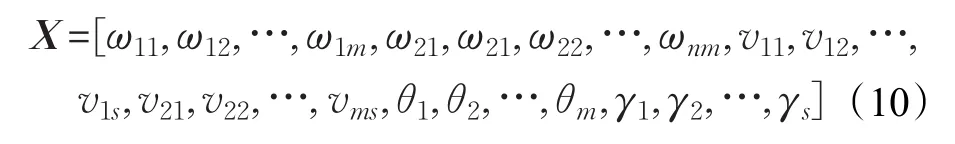
4.3 评价标准
在训练样本的过程中,将网络实际输出与期望输出之间的均方误差(MSE)作为网络的评价标准,因此在花授粉算法中使用的适应度函数为:

其中N为输入样本的总数,yi为第i个样本的实际输出值为第i个样本的期望输出值。MSE的值越小,表明网络的性能越好,因此利用花授粉算法优化网络结构的目的就是找到能够使BP神经网络的实际输出值与期望值之间的均方误差较小的粒子。
4.4 隐层节点数的确定
根据经验公式[15],取隐层节点数为:

其中,m为隐层节点数,n为输入层节点数,s为输出层节点数。
4.5 基于SFPA算法的BP神经网络
利用两种不同的结合方式得到的SFPA1-BP网络和SFPA2-BP网络的基本实现步骤如下。
4.5.1 SFPA1-BP神经网络实现的基本步骤
步骤1初始化SFPA算法以及BP神经网络的参数,包括种群数N,变异因子的初始值ε0,网络的学习参数α,β,输入层、隐层以及输出层的节点数,并设置最大迭代次数或搜索精度作为网络训练结束的条件。
步骤2编码:采用实数编码的方式,按照式(10)将BP神经网络的权值和阈值统一编码到花粉个体中,那么每个花粉个体即代表一个BP网络结构。
步骤3根据式(5)对训练数据做归一化处理,并随机初始化个体的位置。利用式(11)计算每个个体的适应度函数值,并保留适应度值最小的个体。
步骤4随机生成rand1,并按式(3)计算转换概率p,以调节花授粉算法中全局搜索和局部搜索之间的转换。
步骤4.1随机产生rand∈[0,1],若转换概率p>rand,则按式(1)进行全局搜索。
步骤4.2若转换概率p≤rand,按式(4)计算ε,并将ε值代入式(2)中进行局部搜索。
步骤5根据式(11)计算每个花粉的适应度函数值,并找出当前最优解。
步骤6判断是否满足SFPA算法结束的条件,若不满足,转步骤4;若满足,则转步骤7。
步骤7解码:将花粉个体解码为BP神经网络的权值和阈值,以此作为BP网络的初始权值和初始阈值,并对BP网络进行训练。
步骤8判断是否满足网络训练结束的条件,若不满足,转步骤7;若满足,转步骤9。
步骤9得到最优的网络结构,可输入检测样本进行预测或分类。
4.5.2 SFPA2-BP神经网络实现的基本步骤
步骤1初始化花授粉算法以及BP神经网络的参数,包括种群数N,变异因子的初始值ε0,网络的学习参数α,β,输入层、隐层以及输出层的节点数,并设置最大迭代次数或搜索精度作为网络训练结束的条件。
步骤2编码:采用实数编码的方式,根据式(10)将BP神经网络的权值和阈值统一编码到花粉个体中,因此每个花粉个体即代表一个BP网络结构。
步骤3根据式(5)对训练数据做归一化处理,并随机初始化个体的位置。利用式(11)计算每个个体的适应度函数值,并保留适应度值最小的个体。
步骤4随机生成rand1,并按式(3)计算转换概率p,以调节花授粉算法中全局搜索和局部搜索之间的转换。
步骤4.1随机产生rand∈[0,1],若转换概率p>rand,则按式(1)进行全局搜索。
步骤4.2若转换概率p≤rand,按式(4)计算ε,并将ε值代入式(2)中进行局部搜索。
步骤5根据式(11)计算每个花粉的适应度函数值,并找出当前最优解。
步骤6解码:将花粉个体解码为BP神经网络的权值和阈值,以此作为BP网络的初始权值和初始阈值,并对BP网络进行一次训练。
步骤7判断是否满足网络训练结束的条件,若不满足,转步骤4;若满足,转步骤8。
步骤8得到最优的网络结构,可输入检测样本进行预测或分类。
5 仿真对比实验及结果分析
5.1 函数逼近
为了验证本文提出的SFPA1-BP网络和SFPA2-BP网络的性能,在Windows7环境中,利用Matlab7.0编程,对以下7个网络做比较实验:标准BP、FPA1-BP、FPA2-BP、SFPA1-BP、SFPA2-BP以及GA-BP、PSO-BP。根据经验和实验的测试情况,设定参数:种群的规模N为20,在FPA1-BP和SFPA1-BP中,花授粉算法的最大迭代次数500,BP网络的最大训练次数为500;在FPA2-BP和SFPA2-BP中,网络的训练次数为500,学习率α=0.7 ,β=0.7。
对复杂函数:
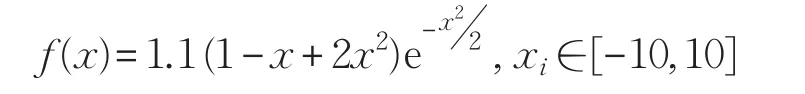
进行拟合仿真,由于f(x)有一个因变量,一个自变量,因此网络的输入层有1个节点,输出层有1个节点,根据经验公式(12)得到隐含层有5个节点,所以网络结构为:1-5-1。在网络的训练过程中,训练样本是在定义域(-10,10)上均匀分布的300个数据对,测试样本是(-10,10)上均匀分布的75个数据对(训练样本和测试样本分别占总样本的80%,20%)[16]。利用7种网络分别对f(x)单独拟合30次,并统计出平均运行时间以及平均网络误差,其中平均运行时间代表网络收敛的速度,平均网络误差代表网络的拟合能力,统计结果如表1所示。
通过比较表1中的平均网络误差值可以看出,本文提出的SFPA1-BP的拟合能力优于另外6种网络,且该网络运行时间较短。通过比较表1中的平均运行时间可以看出,FPA2-BP和SFPA2-BP的运行时间较长,这是由于FPA2-BP和SFPA2-BP每次训练都会运行花授粉算法和BP算法,因此使得运行时间大大增加。
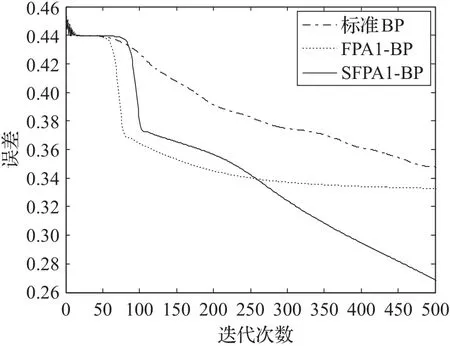
图1 标准BP、FPA1-BP、SFPA1-BP的误差变化图
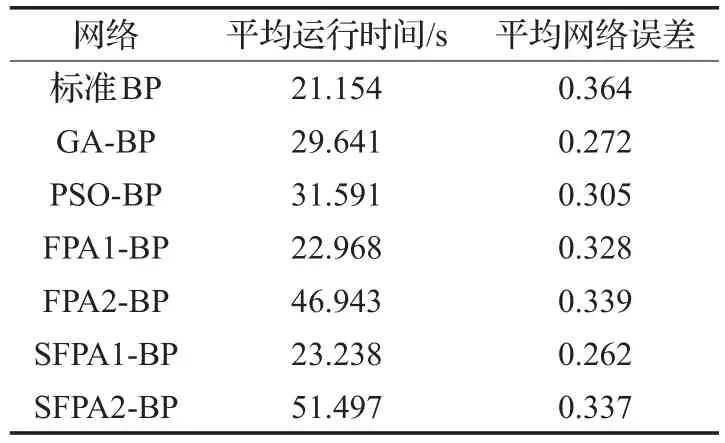
表1 7种网络的实验结果对比
为了更加直观地比较改进后的自适应花授粉算法(SFPA)与原始的花授粉算法(FPA)对网络的影响,首先给出标准BP、FPA1-BP、SFPA1-BP以及标准BP、FPA2-BP、SFPA2-BP在训练过程中的误差变化图,分别如图1、图2所示。
从图1和图2中不难看出,FPA1-BP、SFPA1-BP、FPA2-BP、SFPA2-BP的性能都优于标准的BP网络,不仅能够在较短的时间内达到收敛状态,且最终的误差值也较好。
相较于原始的FPA算法,通过改进得到的SFPA算法对BP网络的性能都有不同程度上的改进,从图1中可以看出,SFPA1-BP相较于FPA1-BP有了明显的改进。SFPA1-BP和FPA1-BP首先利用SFPA或FPA的全局寻优能力找到能够使误差达到相对较小的权值和阈值的组合,然后通过BP网络的局部寻优能力找到最优的组合,由于SFPA的全局寻优能力优于FPA算法,所以在训练BP神经网络之前,利用SFPA得到的权值和阈值的组合要优于FPA得到的组合,因此与FPA1-BP相比,SFPA1-BP的性能有了大幅度的提高。从图2中可以看出,SFPA2-BP与FPA2-BP的误差曲线图并没有太大的差异,即SFPA2-BP与FPA2-BP性能并无较大差异,这是由于在SFPA2-BP网络和FPA2-BP网络训练的过程中,每次训练都是先通过SFPA算法或FPA算法迭代一次,然后利用BP算法再训练一次,由于SFPA算法和FPA算法在初始迭代阶段并没有差异,因此导致SFPA2-BP与FPA2-BP的性能并没有太大的差异。
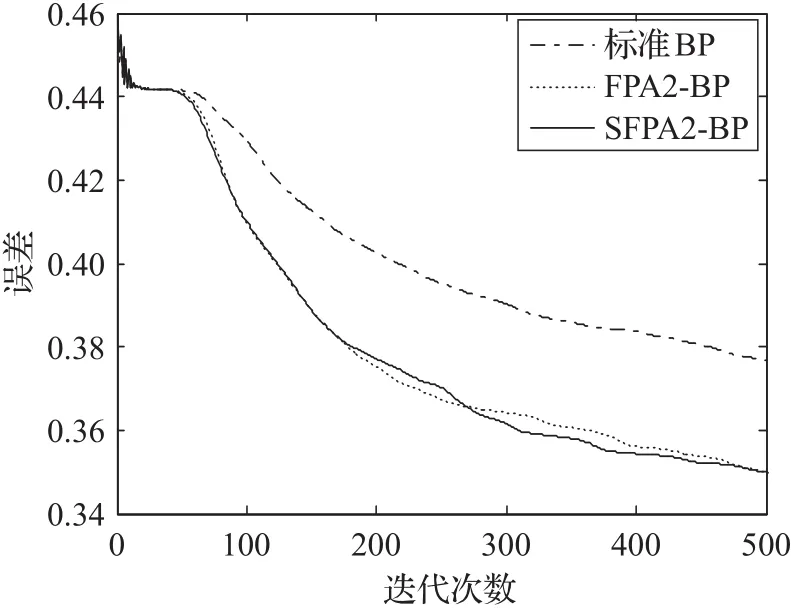
图2 标准BP、FPA2-BP、SFPA2-BP的误差变化图
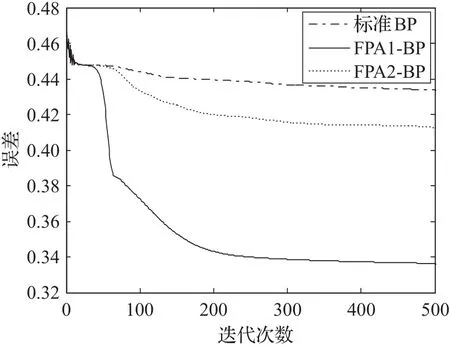
图3 标准BP、FPA1-BP、FPA2-BP的误差变化图
为了进一步验证哪一种方法更适合花授粉算法与BP网络的结合,给出标准BP、FPA1-BP、FPA2-BP以及标准BP、SFPA1-BP、SFPA2-BP的误差变化图,分别如图3、图4所示。
从图3中可以看出,虽然FPA1-BP和FPA2-BP几乎同时达到收敛状态,但是FPA1-BP最终达到的误差远小于FPA2-BP所达到的误差。从图4中可以看出,当SFPA2-BP已经达到收敛状态的时候,SFPA1-BP仍在进一步的收敛,且最终达到的误差值较小。因此,从图3和图4中不难看出,FPA1-BP的拟合能力优于FPA2-BP,且SFPA1-BP的拟合能力优于SFPA2-BP。
这是因为FPA1-BP和SFPA1-BP在BP网络训练之前,先利用FPA和SFPA算法的全局寻优能力得到接近最优权值和阈值的组合,然后在得到的组合附近利用BP算法的局部寻优能力找到能够使网络性能达到最好的权值和阈值,从而达到利用花授粉算法来优化BP网络结构的目的。这种结合方法充分地利用了FPA算法和SFPA算法的全局寻优能力以及BP算法的局部寻优能力。但是利用第二种结合方法得到的FPA2-BP和SFPA2-BP在网络的训练过程中,首先迭代一次FPA或SFPA算法,然后利用BP算法进行训练,然而FPA或SFPA并不能在迭代次数较少的情况下就找到全局的最优解,所以利用FPA或SFPA算法在初期得到的权值和阈值的组合并不能接近最优组合,因此FPA2-BP和SFPA2-BP并没有充分利用FPA或SFPA算法的全局寻优能力。从而可以得到结论:相较于FPA2-BP,SFPA2-BP,利用第一种结合方式得到的FPA1-BP,SFPA1-BP性能较好,且具有收敛速度快等优点。
最后给出BP、SFPA1-BP、SFPA2-BP对测试函数f(x)的拟合图像,如图5所示。
通过图5不难看出,SFPA1-BP对函数的逼近效果较好,SFPA2-BP的效果次之,但是SFPA1-BP和SFPA2-BP都优于BP网络的拟合能力。
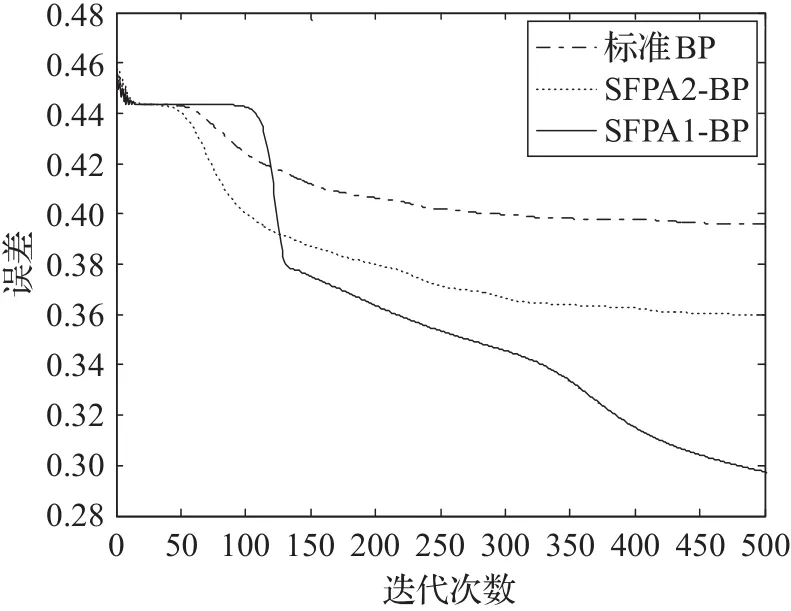
图4 标准BP、SFPA1-BP、SFPA2-BP误差变化图
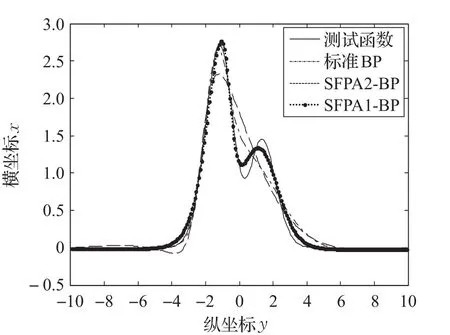
图5 BP、SFPA1-BP、SFPA2-BP的拟合图像
通过以上分析可知,在函数的逼近实验中,SFPA1-BP和SFPA2-BP网络的性能优于标准BP网络、FPA1-BP、FPA2-BP,更进一步的,SFPA1-BP的性能优于SFPA2-BP网络。通过实验验证,先通过花授粉算法得到较优权值和阈值的组合,然后利用BP算法的局部寻优能力在较优组合的附近找到能够使网络性能达到最好的权值和阈值的结合方式,更能够充分发挥SFPA算法的全局寻优能力以及BP算法的局部寻优能力,从而提高网络的性能。
5.2 分类实验
为了验证本文提出的SFPA1-BP神经网络、SFPA2-BP神经网络的分类能力,使用UCI数据库中的Iris数据集[19](属性4个,样本150个,类别3个)作为测试数据。那么网络输入层的节点数为4,输出层的节点数为3,根据经验公式,隐层的的节点数为6,因此网络的结构为4-6-3。
仿真实验在Windows7环境下运行,利用Matlab7.0进行编程。根据经验和实验测试情况,设定参数:种群的规模N为20,在FPA1-BP和SFPA1-BP中,FPA算法的最大迭代次数500,BP网络的最大训练次数为500;在FPA2-BP和SFPA2-BP中,网络的训练次数为500,学习率α =0.7 , β=0.7。
为了消除算法和BP网络的随机性带来的影响,分别利用7种网络:标准BP、FPA1-BP、FPA2-BP、SFPA1-BP、SFPA2-BP以及GA-BP、PSO-BP在Iris数据集上独立运行30次,并统计出平均运行时间以及平均分类正确率,其中平均运行时间表示的是网络的收敛速度,平均分类正确率表示的网络的分类能力,结果如表2所示。
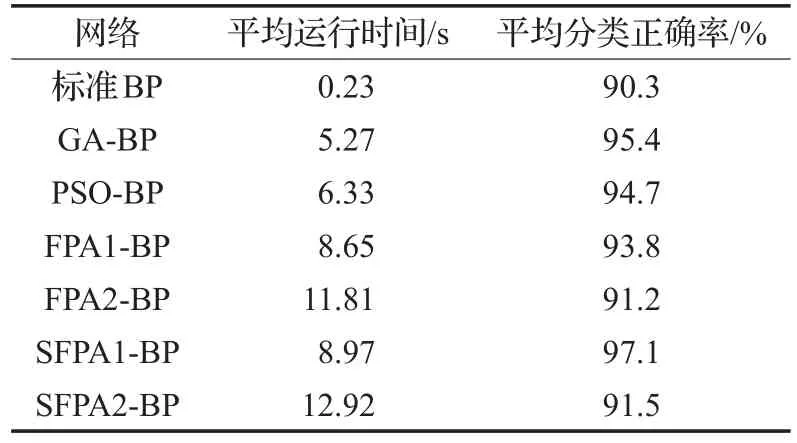
表2 7种网络分类性能的比较
由表1中的统计结果可知,在Iris数据集的分类过程中,7种网络表现出较为明显的差异。虽然BP网络分类时间短,但是分类正确率较低。本文提出的SFPA1-BP的分类能力优于另外6种网络,且运行时间较短。SFPA2-BP不仅分类时间长,且分类能力较低,这是由于SFPA2-BP网络的每次训练都要运行花授粉算法和BP算法,从而使得运行时间较长,又因为SFPA2-BP在每次训练时运行花授粉算法的次数较少,因此并没有充分发挥花授粉算法的全局寻优能力,使得SFPA2-BP在分类方面的能力较差。
5.3 实验结论
通过对以上函数逼近以及Iris数据集分类实验结果的分析可知,SFPA1-BP的学习能力和泛化能力较好,这是由于SFPA1-BP首先利用SFPA算法的全局寻优能力得到接近最优权值和阈值的组合,然后利用BP算法的局部寻优能力找到最优的权值和阈值的组合,这种结合方法充分地利用了SFPA的全局寻优能力以及BP神经网络局部搜索能力,从而提高了网络的学习能力和泛化能力。
6 结束语
在训练的过程中,BP神经网络利用梯度下降法来调整权值及阈值的大小,所以未经优化的初始权值和阈值易导致网络陷入局部最优且收敛速度慢等缺陷,因此提出利用改进的FPA算法对神经网络的初始权值和阈值进行优化。文中首先介绍了传统的BP神经网络和花授粉算法(FPA)的相关内容,并对FPA算法进行改进,然后将改进后的花授粉算法(SFPA)与BP神经网络结合,最后进行函数逼近实验和Iris数据的分类实验。实验结果表明,虽然SFPA1-BP和SFPA2-BP的性能都优于标准的BP神经网络,但是由于SFPA1-BP充分地发挥了SFPA的全局搜索能力以及BP算法的局部搜索能力,因此该网络具有更好的函数逼近能力和较好的分类能力。SFPA1-BP的优势在于能够处理一些传统方法不能处理的例子,如不可导的特性函数或者没有梯度信息存在的节点,且学习能力和泛化能力较好。
虽然SFPA1-BP具有较好的性能,但是如何提高其收敛速度,以及网络隐层节点数的确定将是下一步的研究工作。此外,将本文提出的新网络应用到图像处理、模式识别等领域,也是值得研究的。
[1]Shi W Z,Zhao Y L,Wang Q M.Sub-pixel mapping based on BP neural network with multiple shifted remote sensing images[J].Journal of Infrared and Millimeter Waves,2014,33(5):527-532.
[2]徐华,赵军.基于遗传BP神经网络的工业经济运行指标预测[J].微型机与应用,2016,35(7):90-92.
[3]Wen Hui,Xie Weixin,Pei Jihong,et al.An incremental learning algorithm for the hybrid RBF-BP network classifier[J].Eurasip Journal on Advances in Signal Processing,2016,5:7-10.
[4]Bagheripour P.Core porosity estimation through different training approaches for neural network:Back-propagation learning vs.genetic algorithm[J].International Journal of Computer Applications,2013,63(5):11-15.
[5]Mirjalili S A,Hashim S Z M,Sardroudi H M.Training feedforward neural networks using hybrid particle swarm optimization and gravitational search algorithm[J].Applied Mathematics and Computation,2012,218:11125-11137.
[6]吴文铁,宋曰聪,李敏.蚁群优化神经网络的网络流量混沌预测[J].计算机工程与应用,2012,48(34):97-101.
[7]Socha K,Blum C.An ant colony optimization algorithm for continuous optimization:Application to feed-forward neural network training[J].Neural Computing&Applications,2007,16(3):235-247.
[8]Mirjalili S A,Mirjalili S M,Lewis A.Let a biogeographybased optimizer train your Multi-layer perceptron[J].Information Sciences,2014,269(8):188-209.
[9]Yang X S.Flower pollination algorithm for global optimization[C]//Durand-Lose J.Lecture Notes in Computer Science,Unconventional Computation and Natural Computation,France,2012.Berlin Heidelberg:Springer-Verlag,2012,7445:240-249.
[10]Yang X S,Karamanoglum M,He X.Flower pollination algorithm:A novel approach for multiobjective optimization[J].Engineering Optimization,2013,46(9):1222-1237.
[11]贺兴时,余兵,韩琳.基于差分进化的BP网络学习算法[J].纺织高校基础科学学报,2006,19(2):178-181.
[12]李勇平.基于改进粒子群神经网络的电信业务预测模型研究[D].广州:华南理工大学,2009.
[13]Cybenko G.Approximation by superpositions of a sigmoidal function[J].Mathematics of Control,Signals,and Systems,1989,4(2):303-314.
[14]杨帆,胡春平,颜学封.基于蚁群系统的参数自适应粒子群算法及其应用[J].控制理论与应用,2010,27(11):1479-1488.
[15]Xie Shanyi,Zhai Ruicong,Liu Xianhu,et al.Self-adaptive genetic algorithm and fuzzy decision based multiobjective optimization in microgrid with DGs[J].Open Electrical and Electronic Engineering Journal,2016,10(1):46-57.
[16]李宏.自适应粒子群优化算法及其在图像分割中的应用[D].辽宁大连:大连理工大学,2006.
[17]Dubey H M,Pandit M,Panigrahi B K.A biologically inspired modified flower pollination algorithm for solving economic dispatch problem in modern power system[J].Cogntive Computation,2015,7(5):1-15.
[18]吴亮红,王耀南,袁小芳,等.基于快速自适应差分进化算法的电力系统经济负荷分配[J].控制与决策,2013,28(4):557-562.
[19]University of California Irvine.UCI machine learning repository[EB/OL].(2016-09-12).http://archive.ics.uci.edu/ml/.
