融合社交网络特征的协同过滤推荐算法*
2018-02-05郭宁宁王宝亮侯永宏
郭宁宁,王宝亮+,侯永宏,常 鹏
1.天津大学 电子信息工程学院,天津 300072
2.天津大学 信息与网络中心,天津 300072
1 引言
大数据时代的快速发展造成日益严重的信息过载现象,信息检索已经无法满足用户日益增长的个性化信息获取的需求。个性化推荐系统因为其可靠性高,推荐结果准确,迅速成为解决信息过载的方式之一。其基本思想是依据用户的历史行为推荐用户感兴趣的用户或商品集,并且为获得更好的用户体验提供个性化服务[1]。目前,个性化推荐技术主要分为协同过滤推荐[2]、基于内容的推荐[3]、基于图的推荐[4]、混合推荐技术[5]。其中协同过滤推荐又包括基于模型的协同过滤[6]和基于记忆的协同过滤[7],该技术在分析用户资源的基础上,充分挖掘用户潜在兴趣,并以此作为预测和推荐依据,现已成为推荐系统中发展最成熟、应用最广泛的推荐技术,也是本文主要的研究对象。
协同过滤推荐技术取得广泛应用,在信息海洋时代节省了用户获取信息的时间代价,但该技术也存在一些固有缺陷。首先,协同过滤技术依靠用户-商品评分矩阵进行推荐,但是在现实生活中评分矩阵存在严重的数据稀疏性问题;其次,部分用户只对很少部分商品进行评分,因此该技术存在冷启动问题;最后,传统的协同过滤技术仅仅依靠用户-商品评分矩阵为用户推荐,由于数据源单一,造成推荐结果失真[8]。
随着社交网络技术的发展,用户之间的联系更多依赖网络社交工具,比如Facebook、微信等。社交关系为推荐系统提供了一个独立的信息源,在社交推荐算法中起着越来越重要的作用[9]。基于社交关系的推荐方法[10-14],在一定程度上缓解了用户稀疏性和冷启动问题,同时提高了推荐准确率,但是依然存在一些问题。首先现有的网络数据集中,只有少部分数据集有用户社交关系矩阵,且矩阵数值都是二值数据,因此很难区别用户间的信任程度;其次对用户社交数据建模时,大部分模型建立仅仅依靠用户显性信任关系,从而忽视了用户的隐性社交关系,如相似性等。
为解决上述存在的问题,本文提出了一种融合社交网络关系的协同过滤推荐方法,即融合用户间社交网络信息和用户评分信息,对传统基于分解模型的协同过滤算法进行优化。本文方法包含以下几个步骤:(1)将用户评分矩阵和用户信任矩阵分别映射到低维空间,即用户空间、商品空间、信任空间和被信任空间;(2)用社交特征、商品特征矢量和用户相似性近似估计稀疏用户评分矩阵;(3)依据密集用户评分矩阵选择评分最高的N个商品,形成推荐列表。最后在Epinions公开数据集上验证本文算法,证明了该算法有效缓解了数据稀疏性对推荐结果的影响,并有效降低了平均绝对误差,提高了推荐准确率。
本文组织结构如下:第2章简要介绍传统分解模型的协同过滤算法和本文提出的基于社交网络关系的协同过滤方法;第3章对本文推荐算法进行仿真验证与实验结果分析;第4章对全文进行总结。
2 基于社交关系的协同过滤推荐算法
2.1 问题分析
传统协同过滤推荐算法往往只分析用户的评分矩阵数据,容易忽视用户之间存在的社交信息。但在实际推荐应用中,社交网络信息在推荐系统中的重要性越来越明显,越来越多的研究者将社交网络中的信任关系引入推荐系统中。Massa等人在2004年首次提出将社交中的信任关系融入推荐算法中,用用户间的信任度替代传统相似度对用户空缺值进行预测评分[11],该方法对比传统协同过滤推荐算法准确性有很大提升。Ma等人在推荐系统中引入社交规则的概念,阐述了所提出的两种社交规则对推荐系统的贡献,实验证明基于社交规则的推荐可以有效提高推荐的准确性[12]。文献[7]融合用户社交信任度和评分相似性,提出了一个新矩阵填充的推荐方法,使预测评分准确度明显提升,改善了推荐过程中存在的稀疏性问题。文献[9,14]将高维用户评分矩阵映射到低维特征矩阵,融合用户的社交信息以及各自的隐性数据源进行推荐,实验结果证明该方法可以提高推荐准确度,但会造成部分信息丢失。
假设研究的推荐系统含有m个用户和n个商品,用户对商品的评分矩阵为R=[Ru,i]m×n,如图1(a)。Ru,i∈[1,5]表示用户u对商品i的评分值,5表示最喜欢,1表示最讨厌,评分值为空表示用户未对该商品评分。其中,U={u1,u2,…,um}表示全部的用户集,I={i1,i2,…,in}代表全部的商品集。如何有效得到未评分商品的预测值,是个性化推荐至关重要的一步。最后计算真实评分和预测评分之间的差异最小值来评估推荐系统的推荐准确性,则上述问题变成求最优解问题,目标函数如式(1):

通常情况若只分析用户评分矩阵来预测缺失评分,易导致评分预测不准确。通过增加额外的社交网络数据源辅助用户评分数据,来提高预测值的准确性[12]。这种方法的评分预测依据是:两个用户之间的偏好具有相似性或存在信任的社交关系,如果其中一个用户对某商品的评分较高,则可以认为另一用户对该商品的评分也较高。社交网络中用户间的信任关系可以用矩阵T表示,T=[Tu,v]m×m,其中Tu,v∈[0,1]表示用户间信任程度,如图1(b),用户u1信任用户u3、u4、u5;用户之间的不信任关系用矩阵D表示,D=[Du,v]m×m,Du,v∈(0,1]表示用户间的不信任程度,如图1(c),用户u1不信任u2。本文研究的内容主要是引入社交网络数据源对用户评分数据中的空缺值进行填充,从而完成相关推荐。
2.2 传统矩阵分解模型

Fig.1 Asample of user-item matrix and users'relationship图1 用户评分矩阵与用户关系举例
矩阵分解(matrix factorization,MF)模型被广泛应用在协同过滤推荐算法中,适用于对用户-商品评分矩阵数据进行分析,近似预测缺失数据[15]。其思想是将高维用户评分矩阵分解成为低维用户特征矩阵U∈ℝl×m和商品特征矩阵I∈ℝl×n,其中l≤min(m,n),分解后的用户特征只由几个少量的重要特征决定[16],评分矩阵R可以用UTI近似替代,UT为矩阵U的转置。为了方便研究,通常用函数f(x)=x/Rmax将用户评分数据映射到[0,1]之间[1],Rmax是用户评分的最大值。传统的基于矩阵分解模型的协同过滤方法利用简单的线性模型R=UTI近似拟合评分矩阵,容易造成预测评分过分偏离真实评分,使预测失真。本文引入非线性logistic函数g(x)=1/(1+e-x),将预测评分值映射在[0,1]内。
为了避免过拟合现象,添加正则化约束项,求解最小代价函数L如式(1)时的用户特征矩阵U和商品特征矩阵I,则上述问题的目标函数如式(2):
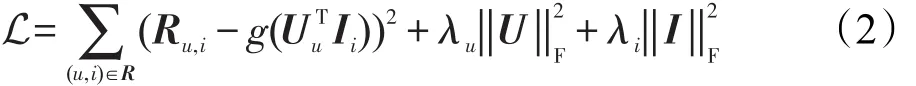

2.3 基于社交网络的协同过滤方法
传统基于矩阵分解模型的协同过滤推荐算法依据用户对商品的评分来预测空缺评分数据,忽视了用户、商品属性以及用户之间的社交关系,推荐预测并不一定准确[10]。目前社交关系被广泛应用于社交推荐系统中,社交推荐系统基于如下基本假设:如果用户u与v之间存在正相关社交信任关系,则认为用户u、v之间的兴趣偏好程度高于不相关的陌生人[1],近几年的很多研究已经证明在社交网络中具有正相关社交关系的用户之间可以很好地传播这种正相关特性,通过利用这种正相关性能够有效地提高推荐准确率[7,17]。基于以上依据可以认为在实际社交推荐过程中,用户更容易接受与其具有正相关社交关系的用户的推荐。此处用户之间的信任关系可以由信任评分矩阵显性表示,如果数据集中用户之间的信任程度由显性的信任数据表示,信任数据范围是[0,1],无评分则为空,如Epinions数据集;若没有显性信任数据时,信任度可以依据用户共同评分项等隐性信任数据构建,即用户之间的共同评分项的评分趋向越一致,则用户之间的信任程度越高,反之越低,如 UPS(user position similarity)方法[17]、用户间接可信度[11]等方法构建用户之间的信任度。本文主要基于已知社交信任数据下的协同过滤推荐算法进行研究。
社交网络关系一般存在以下几个特点:(1)用户信任关系具有传递机制,如果用户u、v之间,v、w之间分别存在信任关系,则v、w之间被认为也存在信任关系,但是三者间的信任程度不同,Tuw≤min(Tuv,Tvw);(2)用户间社交网络信任关系不存在对称性,即使用户u信任用户v,不一定用户v信任用户u;(3)社交网络中的不信任关系不存在传递机制。
依据2.2节中的矩阵分解模型的分解方法,可以将用户间的信任关系矩阵T∈ℝm×m映射成两个低维特征矩阵,即信任特征矩阵P∈ℝk×m和被信任特征矩阵Q∈ℝk×m,则信任矩阵T的信任值可通过T=PTQ线性组合近似估计,其中m表示用户数量,k≤m表示特征数量。假如某个用户u是否信任用户v由k个特征因素决定,那么可以用一个k维向量Pu=[p1,p2,…,pk]T表示用户u的信任标准。用Qv=[q1,q2,…,qk]T表示被信任用户v本身的特征,用户u对用户v的信任值Tuv可以用PuTQv近似表示,但由于噪声的存在,这种分解并不准确,从而用代价函数L评估真实值与预测值之间的差异,代价函数L最小时对应求得的特征矩阵P、Q即为最优解。代价函数为式(4):

其中,λp、λq为正则化系数;是正则化项。预测到的社交信任数据通过非线性logistic函数g(x)=1/(1+e-x)映射到[0,1]之间。
通常用户之间不是完全相互独立的,而是具有一定相关性的。相关性度量方法通常有余弦相似性和Pearson相关性,本文采用Pearson相关性方法计算用户之间的相关程度,计算方法如式(5):
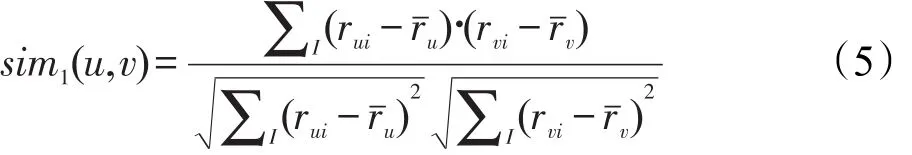
其中,I表示用户u、v的共同评分商品集,i∈I;rui和rvi分别表示用户u和v对项目i的评分值;分别表示用户u和用户v的评分均值。通常用户间的共同评分项的评分倾向越一致,则认为二者对项目的关注程度越一致,二者的相似性值也越高。定义用户评分偏好程度如式(6):
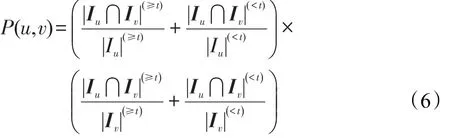
其中,t是区分评价好坏的阈值,超过阈值记为积极评分,否则为消极评分;Iu、Iv分别表示用户u、v的评分商品集合。将用户偏好程度融入相似度计算中,即基于偏好程度的相似性度量方法,计算如式(7):

其中,P(u,v)表示用户间评分偏好程度;sim1(u,v)为用户间Pearson相关系数。社交信任关系的代价函数为式(8):

通过对基于社交网络的研究,用户对商品预测评分可用社交特征和商品特征修正,如式(9):

其中,β,γ,θ∈(0,1),且β+γ+θ=1,是调控信任特征向量、被信任特征向量和相似性的贡献率参数。
在社交网络关系中,如果两个用户u、v之间不存在信任关系,而是怀疑关系,那么认为两个用户的兴趣偏好存在较大偏差,对同一商品的评分差别可能较大。在本算法中,可以计算用户特征空间的欧氏距离描述用户之间兴趣偏好的差异。

基于以上描述,最小代价函数修正成式(11):

其中,λ1、λ2是社交网络差异特征矩阵正则化系数;λp、λq和λv是矩阵P、Q和V正则化系数,以防止过拟合现象。
根据上述模型描述,使损失函数最小时P、Q和V的值即为最优解。为了求代价函数的最优解,算法采用随机梯度下降法求代价函数关于Pu、Qu和Vi的偏导数,如式(12)、(13)、(14)即为梯度方向。
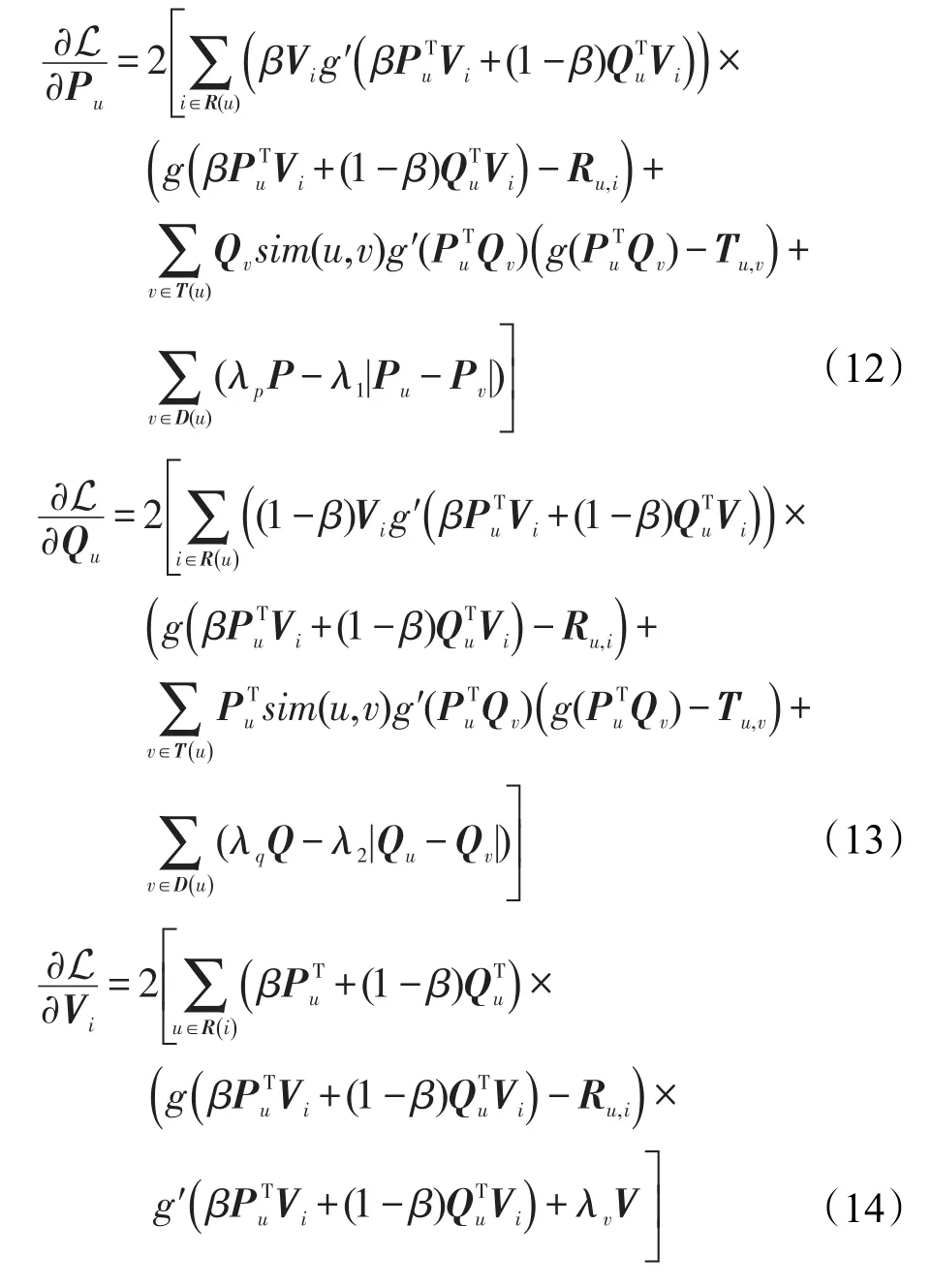
其中,R(u)表示用户u评分过的商品集;T(u)表示用户u信任的用户集;D(u)表示用户u怀疑的用户集;R(i)表示给商品i评分过的用户集。沿梯度的负方向不断迭代更新P、Q和V直至收敛,即可认为得到最优解。
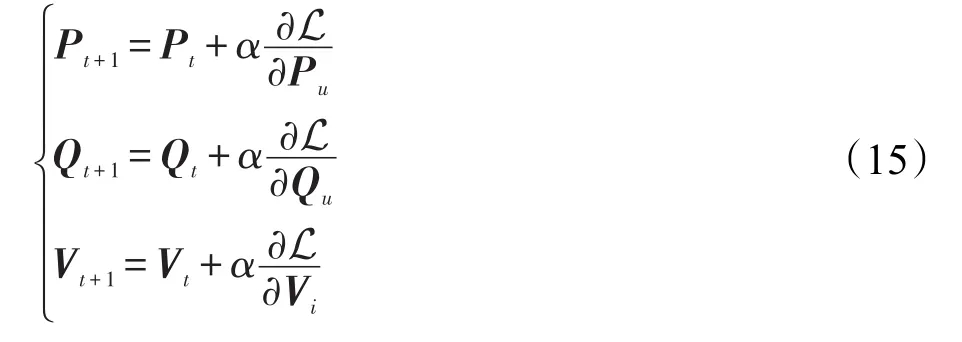
其中,α表示学习速率;Pt、Qt和Vt用随机数进行初始化,t表示迭代次数,t∈[1,∞)。通过不断迭代更新,P、Q和V的值会趋于稳定,稳定后的值即为最优解。高维评分矩阵、社交信任矩阵通过分解变成低维用户信任特征矩阵、被信任特征矩阵、商品特征矩阵,利用式(9)对用户评分矩阵进行预测评估,稀疏矩阵变为密集矩阵,选择目标用户中评分最高的N个商品推荐给用户,即完成Top-N推荐。
2.4 复杂度分析
评价一个算法性能,主要计算算法的时间复杂度,即语句总的执行次数[18]。在本研究中,用户之间的相似性以及评分矩阵、社交矩阵分解等计算过程都是离线条件下完成的,因此本文基于社交网络的协同过滤推荐算法的计算复杂度主要受代价函数和梯度下降特征矩阵维数变量的影响。其中代价函数的计算复杂度是O(k(|R|+|T|+|D|)),k表示隐性特征维数,|R|、|T|和|D|表示存在的非空用户评分数量、用户信任连接数量和用户不信任连接数量。梯度∂L/∂P、∂L/∂Q和 ∂L/∂V的复杂度分别为O(k(|R|+|T|+|D|))、O(k(|R|+|T|+|D|))和O(k|R|),因此本算法的复杂度为O(k(|R|+|T|+|D|)),即时间复杂度与观察到的用户评分数、信任连接数与不信任连接数的和成线性关系,因此适合用于大规模数据集的推荐。
3 实验及结果分析
为了验证本文算法的可靠性和有效性,利用Epinions真实数据集,采用五折交叉验证方法,对本文算法与其他现有的社交推荐算法进行实验对比,统计分析不同方法在推荐准确性方面的平均绝对误差(mean absolute error,MAE)和均方根误差(root mean square error,RMSE)指标。同时对推荐系统在Top-N推荐时每个算法在不同的推荐数量N的情况下的查准率、查全率和F1-Measure值进行统计并分析,以此验证本文算法的可靠性。
3.1 数据集描述
本文选择Epinions公开数据集作为研究的真实数据集,它由Massa在http://www.epinions.com网站收集整理所得[19]。该数据集是一极度稀疏的数据集,稀疏度用空评分数据数量(/用户数量×商品数量)表示,为99.991 35%,包含49 290个用户对139 738个不同商品的评分数据,用户评分数据为1~5内的整数,1表示最差,5表示最好;同时也包含664 824条用户间的社交数据,其中487 181条记录表示用户间的关系是积极的,认为是信任数据,信任值为1,其余不存在信任关系即为0。经对数据统计分析可得每类评分的贡献情况,评分数据中评分为5的记录数占总数的45%,评分为4的占29%,评分为3的占11%,评分为2的占8%,评分为1的占7%,所有评分的平均值约为3.9,接近一半的用户给商品的评分为最高值5。如果用户的评论数量低于5,则被认为是“冷启动”用户,该类用户数量为26 037,那么数据集中有超过一半的用户属于冷启动用户。
3.2 实验设置
3.2.1 实验方法
K折交叉验证:为验证本文算法的有效性和真实性,本实验采用5折交叉验证的方法[7]将所研究的数据集平分成5份,每次实验随机选取数据集中的1组作为测试数据,剩下的4组数据集作为训练数据,每个实验进行5次,实验结果为5次实验的平均值,并进行比较分析。
3.2.2 实验评估指标
(1)为了验证推荐算法的准确性,常用的推荐性能评估指标主要包括平均绝对误差MAE和均方根误差RMSE[20],用来评估推荐结果的误差分布。MAE计算的是所有测试用户对测试项目的预测评分和实际评分的平均误差大小,RMSE计算真实评分与预测评分值的均方根误差,如式(16)、(17):

其中,Tu表示测试集中的用户数据集合;N表示测试集中商品数量;表示用户u对商品i的预测评分;Ru,i表示真实评分。
(2)另一种预测推荐系统质量的方法是计算推荐的正确率(Precision)、召回率(Recall)和F1-Measure值[16]。准确率和召回率是评估推荐系统常用的两个度量指标。其中准确度可以衡量推荐系统的查准率,即推荐结果满足用户喜好的概率;召回率衡量的是推荐系统的查全率,即所有推荐结果与用户喜好相关的概率。两者取值在0和1之间,数值越接近1,查准率或查全率就越高。F1-Measure是结合Precision和Recall两者给出的综合评价指标。定义如下:

其中,Lu表示用户u由训练数据集得到的推荐商品集合;Bu表示在测试数据集给出正反馈评分的商品集合;Tu表示测试集中的用户数据集合。
3.2.3 方法比较
为了评估本文算法的性能,采用以下几种方法进行对比验证。
(1)SocialMF(matrix factorization in social networks):该算法是一种基于信任传递机制的社交推荐算法[21]。
(2)TDMF(matrix factorization with trust and distrust information):该算法利用社交信任和不信任信息进行推荐[22]。
(3)TDRec(matrix factorization with explicit trust and distrust side information for improved social recommendation):该算法通过显式信任和非信任数据进行社交推荐[23]。
(4)TDSRec(similarity social recommendation with trust and distrust information):该算法是本文算法模型,在考虑社交网络的同时,融合基于用户评分偏好的相似性,共同对用户评分矩阵中的数据值进行评分预测。
为了便于比较,将各个算法的参数设置为表1,参数的设置来自于参考文献或者本研究模型。在矩阵分解过程中,特征矩阵的维数设置为5和10,分别统计特征维数的误差值。
3.3 实验结果及分析
在表2、表3中,分别统计了所有用户和冷启动用户(用户对商品评分个数少于5)在矩阵特征数k为5和10时,本文算法与现有算法的平均绝对误差(MAE)和均方根误差(RMSE),并计算得到本文算法比现有算法的提升率,观察到本文算法的MAE和RMAE小于已有算法,实验证明了本文算法提升了推荐准确度。

Table 1 Parameter settings表1 参数设置
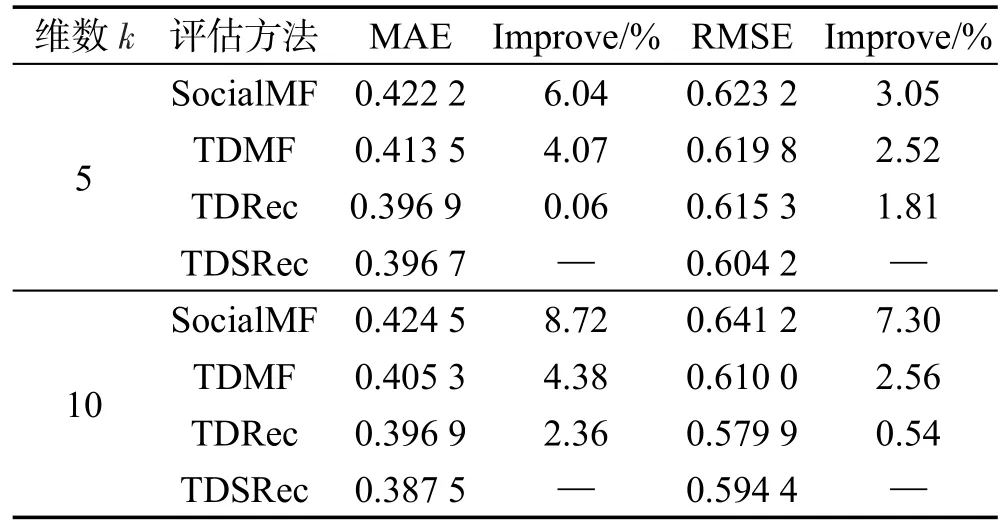
Table 2 MAE and RMSE results of different algorithms on all users表2 所有用户在不同算法得到的MAE、RMSE值

Table 3 MAE and RMSE results of different algorithms on cold-start users表3 冷启动用户在不同算法得到的MAE、RMSE值
由图2、图3可以得出,在特征矩阵维数k=10时,随着迭代次数的增加,MAE和RMSE逐渐趋于稳定。结果显示,本文算法的MAE和RMSE低于被比较对象,性能优于被比较算法。
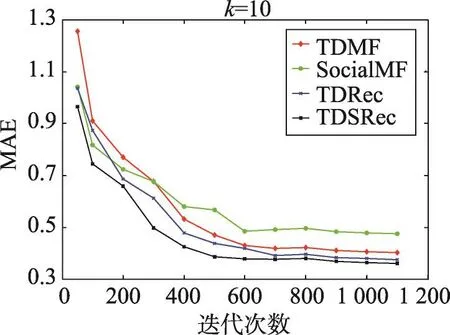
Fig.2 MAE at different iterations on all users图2 所有用户不同迭代次数时的MAE
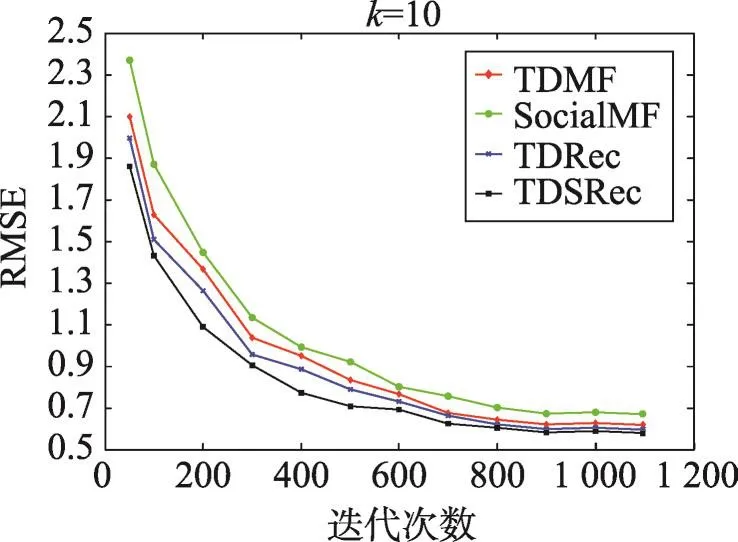
Fig.3 RMSE at different iterations on all users图3 所有用户不同迭代次数时的RMAE
通过实验对比分析本文算法与已有算法,证明本文提出的协同过滤推荐算法在不同的推荐数量N下的查准率、查全率和综合指标F1-Measure都优于被比较算法。同时由图4、图5可知算法的查全率和查准率呈相反趋势增长,由图6可知综合两者特性的F1-Measure参数也有增长趋势。
4 结束语
协同过滤推荐技术是推荐系统中应用最广和最多的推荐技术,在过去的十几年内,已有很多基于社交网络特征的协同过滤推荐方法,数据稀疏性、推荐准确性方面在一定程度上都得到提升[9],但是推荐系统的固有缺陷仍然存在,导致推荐质量较差,很难满足用户个性化需求。本文针对推荐系统中存在的固有的数据稀疏和冷启动问题,创新性地提出一种融合社交网络特征的协同过滤推荐算法。本文算法主要基于传统矩阵分解模型,分解用户评分矩阵为两个低维的用户特征矩阵和商品特征矩阵的同时,分解社交网络矩阵数据为信任特征矩阵和被信任特征矩阵;在求解分解矩阵过程中通过融合用户评分偏好程度计算用户相似性使代价函数最小,如式(11),使用梯度下降法不断迭代更新得到对应分解后的特征矩阵,如式(12)、(13)、(14);利用信任特征矩阵、被信任特征矩阵、商品特征矩阵预测用户对商品的评分值,如式(9)。以此缓解矩阵稀疏性,提高推荐结果的准确性和有效性。

Fig.4 Precision图4 查准率

Fig.5 Recall图5 查全率

Fig.6 F1-Measure图6 F1-Measure
为了验证本文算法的可靠性,基于Epinions公开数据集进行实验分析,采用五折交叉验证方法,分析对比了本文算法较现有的社交网络推荐算法如TDMF、SocialMF、TDRec等算法的先进性和优越性。实验结果表明,本文算法在使用相同数据集的情况下与其他算法相比,平均绝对误差、均方根误差都有所下降,有效地提高了推荐算法的性能。在现实推荐中,本文算法可以有效用于大规模用户商品集的推荐,有效缓解数据稀疏性,提高预测准确度和推荐准确度,改善推荐质量。
本文提出的融合社交网络的协同过滤推荐算法,虽然在一定程度上缓解了评分数据稀疏性对推荐结果的影响,并对于大量数据的推荐运算具有一定效果,但是不足以支撑超大规模数据推荐,此时可以在本文基础上考虑超大规模推荐的并行算法来克服此局限性。同时本文算法未考虑时间差异对推荐产生的影响,由于用户对商品的兴趣爱好时间长短不一,同一用户对同一商品的评分在不同时间点存在差异,由此可以发现可疑用户,以此提高推荐准确率。以上两点可以作为下一步的研究方向。
[1]Bai Tiansheng,Yang Bo,Li Fei.TDRec:enhancing social recommendation using both trust and distrust information[C]//Proceedings of the 2nd European Network Intelligence Conference,Karlskrona,Sep 21-22,2015.Washington:IEEE Computer Society,2015:60-66.
[2]Breese J S,Heckerman D,Kadie C.Empirical analysis of predictive algorithms for collaborative filtering[C]//Proceedings of the 14th Conference on Uncertainty inArtificial Intelligence,Madison,Jul 24-26,1998.San Francisco:Morgan Kaufmann Publishers Inc,1998:43-52.
[3]Wang Licai,Meng Xiangwu,Zhang Yujie.Context-aware recommender systems[J].Journal of Software,2012,23(1):1-20.
[4]Zhang Yanmei,Wang Lu,Cao Huaihu,et al.Recommendation algorithm based on user-interest-item tripartite graph[J].Pattern Recognition and Artificial Intelligence,2015,28(10):913-921.
[5]Lu Zhongqi,Dou Zhicheng,Lian Jianxun,et al.Contentbased collaborative filtering for news topic recommendation[C]//Proceedings of the 29th Conference on Artificial Intelligence,Austin,Jan 25-30,2015.Menlo Park:AAAI,2015:217-223.
[6]Guo Lanjie,Liang Jiye,Zhao Xingwang.Collaborative filtering recommendation algorithm incorporating social network information[J].Pattern Recognition and Artificial Intelligence,2016,29(3):281-288.
[7]Wang Meiling,Ma Jun.A novel recommendation approach based on users'weighted trust relations and the rating similarities[J].Soft Computing,2015,20(10):3981-3990.
[8]Wang Shengsheng,Zhao Haiyan,Chen Qingkui,et al.Latent factor model for personalized recommendation[J].Journal of Chinese Computer System,2016,37(5):881-889.
[9]FelfernigA,Ninaus G,Grabner H,et al.An overview of recommender systems in requirements engineering[M]//Ma-alej W,Thurimella A K.Managing Requirements Knowledge.Berlin,Heidelberg:Springer,2013:315-332.
[10]Pan Junchi,Zhang Xingming,Wang Xin.Improved singular value decomposition recommender algorithm based on user reliability[J].Journal of Chinese Computer System,2016,37(10):2171-2176.
[11]Massa P,Bhattacharjee B.Using trust in recommender systems:an experimental analysis[C]//LNCS 2995:Proceedings of the 2nd International Conference on Trust Management,Oxford,Mar 29-Apr 1,2004.Berlin,Heidelberg:Springer,2004:221-235.
[12]Ma Hao,Zhou Dengyong,Liu Chao,et al.Recommender systems with social regularization[C]//Proceedings of the 4th International Conference on Web Search and Web Data Mining,Hong Kong,China,Feb 9-12,2011.New York:ACM,2011:287-296.
[13]Chen Wei.Multi-collaborative filtering trust network for online recommendation[J].Information Systems Frontiers,2015,15(4):533-551.
[14]Ma Hao,Lyu M R,King I.Learning to recommend with trust and distrust relationships[C]//Proceedings of the 2009 Conference on Recommender Systems,New York,Oct 23-25,2009.New York:ACM,2009:189-196.
[15]Koren Y,Bell R,Volinsky C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37.[16]Wang Peiying.Community discovery and collaborative filtering recommendation in social networks[D].Beijing:Beijing Jiaotong University,2016.
[17]Du Yongping,Du Xiaoyan,Huang Liang.Improve the collaborative filtering recommender system performance by trust network construction[J].Chinese Journal of Electronics,2016,25(3):418-423.
[18]Fouss F,Saerens M.Evaluating performance of recommender systems:an experimental comparison[C]//Proceedings of the 2008 International Conference on Web Intelligence and Intelligent Agent Technology,Los Alamitos,Dec 9-12,2008.Washington:IEEE Computer Society,2008:735-738.
[19]Rennie J D M,Srebro N.Fast maximum margin matrix factorization for collaborative prediction[C]//Proceedings of the 22nd International Conference on Machine Learning,Bonn,Aug 7-11,2005.New York:ACM,2005:713-719.
[20]Mao Yiyu,Liu Jianxun,Hu Rong,et al.Sigmoid functionbased Web service collaborative filtering recommendation algorithm[J].Journal of Frontiers of Computer Science and Technology,2017,11(2):314-322.
[21]Jamali M,Ester M.A matrix factorization technique with trust propagation for recommendation in social networks[C]//Proceedings of the 4th ACM Conference on Recommender Systems,Barcelona,Sep 26-30,2010.New York:ACM,2010:135-142.
[22]Forsati R,Mahdavi M,Shamsfard M,et al.Matrix factorization with explicit trust and distrust side information for improved social recommendation[J].ACM Transactions on Information Systems,2014,32(4):17.
[23]Park C,Kim D,Oh J,et al.Improvingtop-Krecommendation with truster and trustee relationship in user trust network[J].Information Sciences,2016,374(C):100-114.
附中文参考文献:
[3]王立才,孟祥武,张玉洁.上下文感知推荐系统[J].软件学报,2012,23(1):1-20.
[4]张艳梅,王璐,曹怀虎,等.基于用户-兴趣-项目三部图的推荐算法[J].模式识别与人工智能,2015,28(10):913-921.
[6]郭兰杰,梁吉业,赵兴旺.融合社交网络信息的协同过滤推荐算法[J].模式识别与人工智能,2016,29(3):281-288.
[8]王升升,赵海燕,陈庆奎,等.个性化推荐中的隐语义模型[J].小型微型计算机系统,2016,37(5):881-889.
[10]潘骏驰,张兴明,汪欣.融合用户可信度的改进奇异值分解推荐算法[J].小型微型计算机系统,2016,37(10):2171-2176.
[16]王培英.社会网络中的社区发现及协同过滤推荐技术研究[D].北京:北京交通大学,2016.
[20]毛宜钰,刘建勋,胡蓉,等.采用Sigmoid函数的Web服务协同过滤推荐算法[J].计算机科学与探索,2017,11(2):314-322.
