近红外光谱法快速无损测定奶粉的脂肪含量
2017-12-26何佳艳李亭郭长凯胡蝶邹婷婷王莹
何佳艳,李亭,郭长凯,胡蝶,邹婷婷*,王莹
1(北京工商大学 北京市食品风味化学重点实验室/食品添加剂与配料北京高校工程研究中心,北京,100048)2(吉林省食品检验所,吉林 长春,130022)
近红外光谱法快速无损测定奶粉的脂肪含量
何佳艳1,李亭1,郭长凯1,胡蝶1,邹婷婷1*,王莹2
1(北京工商大学 北京市食品风味化学重点实验室/食品添加剂与配料北京高校工程研究中心,北京,100048)2(吉林省食品检验所,吉林 长春,130022)
将11种奶粉原样配制及组成77个奶粉样本,以脂肪含量为检测指标,结合偏最小二乘法开展近红外光谱定量分析研究。2次异常光谱剔除,识别出异常样本(14,52,76)并予以剔除。74个奶粉样本进行平滑、导数和标准变量变换等6种光谱预处理,确定标准正态变量变换结合Norris一阶导为最佳光谱预处理方式,其交叉验证均方根误差为0.354 7,交叉验证相关系数平方达到0.990 8;最佳前处理光谱结合3种波段选择方法优化模型性能,与全光谱模型形成对比,确定随机蛙跳(random frog,RF)为最佳波段选择方式,其模型的训练集和测试集相关系数平方分别为0.997 2和0.997 0,训练集和测试集均方根误差分别为0.186 2和0.198 2。结果表明:采用蒙特卡罗异常光谱剔除(Monte-Carlo sampling,MCS),光谱预处理结合随机蛙跳波段优化技术可提高奶粉脂肪近红外定量模型的泛化性和预测能力。
近红外光谱技术;无损检测;脂肪;蒙特卡罗异常光谱剔除(Monte-Carlo sampling,MCS);随机蛙跳(random frog,RF)
奶粉营养丰富,包含人体所需的蛋白质(氨基酸)、脂肪酸、碳水化合物和维生素等营养物质,而且易被人体消化和吸收,奶粉还可长期贮藏、携带便利,备受大众青睐。脂肪是奶粉中重要的营养成分,也是直接反映奶粉质量的重要指标,测定奶粉中脂肪含量是保证奶粉质量的重要内容。近几年来,频频曝光的乳制品质量问题,使得广大消费者对乳制品安全忧心忡忡。所以,高效快速地检测乳制品品质,控制乳制品质量是解决问题的关键。目前,奶粉脂肪含量测定的常规方法多为化学检测技术,此类方法虽然精度高,但耗时费力,操作过程相对复杂,而且会对样品造成破坏。与化学分析方法相比,近红外光谱技术具有快速无损分析、无污染绿色环保等特点,在食品领域得到广泛应用[1-7],其中也应用于乳制品领域的研究[8-11],包括乳制品中营养成分检测的研究,例如脂肪酸及多不饱和脂肪酸含量[12-15]、蛋白质和脂肪含量等研究[16-19]。
近红外光谱法(near infrared spectroscopy,NIR)是指波数在12 800~4 000cm-1的电磁波,对物质分子中C—H,N—H,O—H等含氢基团的倍频和合频吸收。长波近红外光谱采集波数范围10 000~4 000 cm-1的样品光谱,所得谱图包含丰富的样品信息和噪音信号(如仪器噪音、环境干扰等),谱图复杂,重叠严重,通常将结合化学计量学提取样本特征信息,并可采取异常值剔除、光谱预处理等方法进行模型优化。全光谱数据通常包含几千个变量进行PLS模型构建,其数据量大,即包含所有相关和无关数据信息,相对耗时长,其模型准确性受无关信息变量影响。有效波段的选择[20-25],能简化建模数据,提取关键特征波段信息,改善预测性能。波数筛选方法包括蒙特卡罗无信息变量消除(Monte Carlo uninformative variable elimination,MC-UVE),随机蛙跳(random frog)和竞争自适应重加权采样(competitive adaptive reweighted sampling,CARS)算法等。
本文结合近红外光谱和偏最小二乘法检测奶粉中脂肪含量,首先采用蒙特卡洛奇异光谱剔除,然后,进行平滑、导数等光谱前处理,最后对最优光谱进行波段筛选,压缩建模数据量,从而实现快速分析,并且提高模型的稳健性和预测能力。
1 材料与方法
1.1 实验材料
不同品牌不同种类不同批次的奶粉原样共11个样品,购于大型超市,奶粉原样脂肪测定值见表1。脂肪含量以中华人民共和国国家标准GB 5413.3—2010测定值为参考值。

表1 不同品牌奶粉脂肪含量表Table 1 Fat content of different brands of milk powder
1.2 样品配制
将11个奶粉原样以不同比例混合制成66个样品,包括奶粉原样总计得到77个样本,样本浓度为16.70~28.46 g/100g,平均值为21.84 g/100g。
1.3 仪器与软件
尼高力6700傅立叶红外光谱仪(配有积分球、光纤漫反射探头、样品杯等附件及OMNIC和TQ Analyst软件)赛默飞世尔科技公司。光谱数据处理采用Matlab-R2010软件和libPLS代码包,libPLS代码由公共平台下载:http://www.libpls.net/.
1.4 测量条件与原始光谱图
近红外光谱仪开机并预热稳定1 h,保持实验室的温度和湿度稳定,温度一般控制在25 ℃;采用漫反射光谱法,将样品置于样品杯:设置光谱仪测定参数:光源为白光,光栅为12,波数范围10 000~4 000 cm-1,分束器CaF2,采集次数为64次,分辨率8 cm-1。取平均值作为该样本的原始光谱。图1-a为77个样本的近红外原始光谱图,没有基线分离和锐峰的谱峰,每个近红外谱图都是若干个不同基频的合频和倍频谱带的组合,大量的是重叠谱峰和肩峰。最终从近红外光谱谱图提取的是弱信息,需进行光谱预处理和波段筛选并结合化学计量学方法。
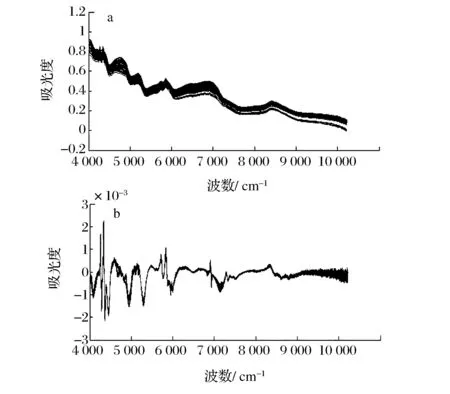
图1 77个奶粉样品的近红外漫反射光谱图(a)和74个经Norris一阶导前处理的奶粉样品光谱图(b)Fig.1 The raw spectra of 77 milk powder samples (a) and preprocessed spectra using Norris+1st derivative of 74 milk powder samples (b)
1.5 模型性能评估

2 结果与分析
2.1 奇异样本剔除和样品分组
构造稳健的奶粉脂肪含量模型,依赖于精准的光谱数据。首先,最重要的是光谱数据中奇异样本的剔除。校正模型建立时,异常样本的存在严重影响模型的预测精度。所谓的异常样本是指样本光谱或浓度标准值具有较大误差的样本。剔除异常样本能有效提高模型的稳健性、范化和预测能力,所以,剔除异常值是近红外光谱法定量分析过程中模型建立的重要环节。常用的异常值剔除方法有:浓度残差剔除、马氏距离(mahalanobis distance,MD)、蒙特卡洛采样算法(Monte-Carlo sampling,MCS)、杠杆值法(leverage)等。其中,MCS算法是一种基于预测残差的异常样本识别方法,通过预测残差对异常样本的敏感特性,降低异常样本的掩蔽效应。文中根据样品的预测残差分布图进行异常样本的剔除。通常,MCS算法将异常样本分为三类:第一,Y轴方向上的独立变量点,远离正常的Y轴上的点分布,造成较大的误差平方和;第二、X轴方向上的独立变量点,远离X轴上正常点的分布;第三、同时远离X和Y轴方向的异常点。
采用蒙特卡洛采样(Monte-Carlo sampling,MCS)诊断奇异样本,通过各样本标准偏差和预测误差平均值对近红外光谱数据进行异常值检验,位于高均值或高标准偏差的样本最有可能是奇异样本。文中共随机采样1 000次,各样本均得到一组预测残差,计算各样本预测残差的均值和方差,绘制均值-方差分布图,如图2所示。

a:一次MCS;b:二次MCS图2 样本均值-方差分布图Fig.2 The result of variance of residuals versus mean of residuals on milk powder
图2-a显示,1个样本光谱(76)被判断为异常值,属于第三类异常值,同时远离X轴和Y轴正常分布点,具有较大的预测误差均值和方差。为进一步剔除潜在异常值,进行了二次异常样本剔除,结果表明,一次异常样本的剔除并未剔除所有的异常值,如图2-b所示,其中包含了两类异常值,样本52属于远离Y轴正常分布点的异常样本,样本14属于远离X轴正常分布点的样本,都应予以剔除。因此,经2次异常样本剔除,共剔除3个异常值,将采用74个样本进行以下的分析。
74个样本随机分成2组,一组为训练集(training set,50个),另一组为测试集(test set,24个),保证2组样品浓度均匀。训练集和测试集样本浓度分布情况见表2,训练集浓度范围16.70~28.46 g/100g,平均值为21.78 g/100g,测试集浓度范围16.90~28.46 g/100g,平均值为21.99 g/100g。

表2 训练集和测试集奶粉脂肪含量分布表 单位:g/100gTable 2 Fat content of training set and test set
2.2 光谱数据前处理
除了有用的光谱信息,光谱还包含一些噪音信息,如样本本身,仪器、环境等造成的基线漂移,光散射等干扰信息。为了建立可靠的光谱模型,通常进行光谱前处理进行干扰信息的削弱和有用信息的筛选。文中共采用6种光谱前处理方法,主要是平滑和导数处理。其中,平滑是最常用的降噪方法,其实质是一种加权平均法,强调中心点的中心作用,常用的有Savitzky-Golay平滑(S-G平滑)和Norris平滑。Savitzky-Golay卷积平滑可以降低谱图的数据分辨率,并平滑掉小的谱峰。Norris平滑常用于增加被宽谱带覆盖的尖峰。导数光谱可有效地消除基线和其他背景的干扰,分辨重叠峰,提高分辨率和灵敏度,常用的有光谱的一阶导数(FD)和二阶导数(SD)。
训练集50个奶粉样品的原始光谱,不同的光谱前处理方法结果如表3所示,其中,标准正态变量变换结合Norris一阶导(SNV+N+FD)是最佳的预处理方式,模型相关系数平方达到了0.9908,交叉验证均方根误差为0.3547,最佳主成分数为6,模型泛化能力较强。图1-b是Norris一阶导光谱图,显然强化了特征峰,特征峰主要集中于波数为4 400 cm-1和5 800 cm-1附近。

表3 近红外光谱预处理结果Table 3 The results of different data preprocessing
注:(1) FD、SD:一阶、二阶导数;(2) SNV:标准正态变量变换;(3)SG、N:Savitzky-Golay卷积平滑、Norris平滑。
2.3 全光谱和波长选择模型
蒙特卡罗无信息变量消除将蒙特卡罗过程和无信息变量消除相结合,充分利用样本之间的内部相关性,对高维光谱数据中波长变量的贡献进行评价,根据每个波长的贡献值设定一阈值,消除其中无信息的波长。CARS算法根据达尔文的“适者生存”原则,经多次自适应加权采样技术(ARS)筛选出模型中回归系数绝对值大的波长点,去除权重小的波长点,最后通过交叉验证(CV)选出交叉验证均方差值最低的子集。随机蛙跳算法基于利用少数变量多次迭代高维数据,计算每个变量的选择频率,决定该变量的重要性,有效建立预测模型。与全光谱数据建模相比,具有以下特点:(1)改善了预测性能;(2)减少了建模波数变量数;(3)突出变量与浓度相关性大的变量。结果如表4和图3所示。

表4 不同变量筛选方法的模型参数比较Table 4 Comparison of parameters with different variable selection method

图3 不同波长选择方法选择的变量分布图Fig.3 The distribution of the selected variables obtained variables using different wavelength selection methods
如表4所示,MC-UVE算法从全光谱3 112个建模变量中提取57个关键变量用于建模,训练集交叉验证均方根误差和交叉验证相关系数平方分别为0.371 9和0.989 8,校正模型校正均方根误差和校正相关系数平方分别为0.286 9和0.993 2。CARS算法从全光谱3 112个建模变量中提取233个关键变量用于建模,训练集交叉验证均方根误差和交叉验证相关系数平方分别为0.229 0和0.996 1,校正模型校正均方根误差和校正相关系数平方分别为0.069 1和0.999 6。如图3所示,虽然CARS算法选取的波数点较多,但其独立选点的特点使结果优于UVE算法的连续选点。如表4所示,RF算法仅使用10个变量建模,训练集交叉验证均方根误差和交叉验证相关系数平方分别为0.213 1和0.996 7,校正模型校正均方根误差和校正相关系数平方分别为0.186 2和0.997 2。如图3所示,虽然RF算法选取的波数点较少,但其结果最佳,表明其选取了最佳的波数点进行建模。综上所述,与MC-UVE和CARS算法相比, RF算法使建模变量数显著较少,剔除了高维变量中的无关信息变量,优化了建模过程,简化了模型。
2.4 测试集对模型的外部验证
测试集作为未知样品对校正模型性能的验证是近红外光谱模型泛化性评估的必备步骤。图4-a是最佳光谱前处理全光谱(SNV+Norris一阶导+3 112个波数点)的校正集和测试集模型参考值和预测值相关性图,图4-b是最佳光谱前处理结合最佳波段选择(SNV+Norris一阶导+RF算法)的校正集和测试集模型参考值和预测值相关性图。显而易见,RF算法使模型的预测精度更高。

a:全光谱模型;b:采用随机蛙跳选择10个波数点图4 脂肪含量参考值与预测值关系图Fig.4 The correlation between the predicted values and measured values
3 结论
本文将快速高效、绿色无损的近红外光谱技术结合偏最小二乘法测定奶粉中的脂肪含量,研究结果表明,蒙特卡罗异常光谱剔除、光谱预处理结合随机蛙跳波段优化技术后,最终模型结果具有最高的交叉验证相关系数和最低的交叉验证均方根误差,建模数据量大大减少,克服了高维数据空间的繁琐,模型性能得到优化,模型更加可靠稳健。
[1] 陈辰,鲁晓翔,张鹏,等. 玫瑰香葡萄贮藏期间糖酸品质的近红外检测[J]. 食品与发酵工业, 2015, 41(6):175-180.
[2] 邹婷婷,何佳艳,齐庆璇,等. 采用正交投影偏最小二乘法快速无损分析乳粉蛋白质含量[J]. 食品与发酵工业, 2016, 42(4):179-182.
[3] 冯叙桥,匡立学,宫元娟,等. 近红外无损检测寒富苹果可溶性固形物含量(TSS)[J]. 食品与发酵工业, 2013, 39(4):200-204.
[4] 王雁飞. 近红外漫反射光谱法快速定量分析八角茴香中八角茴香油[D]. 长春:吉林大学, 2010.
[5] 孙通, 江水泉. 基于可见/近红外光谱和变量优选的南水梨糖度在线检测[J]. 食品与机械, 2016, 32(3):69-72.
[6] YUN Yong-huan, WEI Yang-chao, ZHAO Xing-bin, et al. A green method for the quantification of polysaccharides in Dendrobium officinale[J]. Rsc Advances, 2015, 5(127):105 057-105 065.
[7] YANG Mei-yan, NIE Shao-ping, LI Jing, et al. Near-infrared spectroscopy and partial least-squares regression for determination of arachidonic acid in powdered oil[J]. Lipids, 2010, 45(6):559-565.
[8] 褚莹. 基于近红外光谱技术实现羊奶新鲜度检测及掺假检测的研究[D]. 杨凌:西北农林科技大学, 2012.
[9] MELFSEN A, HARTUNG E, HAEUSSERMANN A. Accuracy of milk composition analysis with near infrared spectroscopy in diffuse reflection mode[J]. Biosystems Engineering, 2012, 112(3):210-217.
[10] INGLE P D, CHRISTIAN R, PUROHIT P, et al. Determination of protein content by NIR spectroscopy in protein powder mix products.[J]. Journal of Aoac International, 2016, 99(2):360-363.
[11] MADALOZZO E S, SAUER E, NAGATA N. Determination of fat, protein and moisture in ricotta cheese by near infrared spectroscopy and multivariate calibration.[J]. Journal of Food Science and Technology, 2015, 52(3):1 649-1 655.
[12] 穆同娜, 庄胜利, 赵玉琪,等. 近红外光谱法快速检测婴儿配方奶粉中的脂肪酸含量[J]. 现代食品科技, 2015, 31(4):278-281.
[13] 庄胜利, 孙继红, 穆同娜,等. 应用近红外光谱结合偏最小二乘法快速测定乳粉中多不饱和脂肪酸的含量[J]. 食品科技, 2014, 39(6):267-271.
[14] WANG Yan-wen, WU Ding, KOU Li-ping, et al. A Non-destructive method to assess freshness of raw bovine milk using FT-NIR spectroscopy[J]. Journal of Food Science and Technology, 2015, 52(8):1-6.
[16] 张华秀,李晓宁,范伟,等. 近红外光谱结合CARS变量筛选方法用于液态奶中蛋白质与脂肪含量的测定[J]. 分析测试学报,2010, 29(5):430-434.
[17] 朱向荣, 单杨, 李高阳,等. 近红外光谱法快速测定液态奶中蛋白质和脂肪含量[J]. 食品科学, 2011, 32(12):191-195.
[18] 匡静云, 管骁, 刘静. 原料乳中蛋白质与脂肪的近红外光谱快速定量研究[J]. 分析科学学报, 2015, 31(6):783-786.
[19] 张华秀. 近红外光谱法快速检测牛奶中蛋白质与脂肪含量[D]. 长沙:中南大学, 2010.
[20] 刘智超, 蔡文生, 邵学广. 蒙特卡洛交叉验证用于近红外光谱奇异样本的识别[J]. 中国科学:化学, 2008, 38(4):316-323.
[21] BIN Jun, AI Fang-fang, FAN Wei, et al. An efficient variable selection method based on variable permutation and model population analysis for multivariate calibration of NIR spectra[J]. Chemometrics& Intelligent Laboratory Systems, 2016, 158(15):1-13.
[22] LI Hong-dong, LIANG Yi-zeng, XU Qing-song, et al. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration[J]. Analytica Chimica Acta, 2009, 648(1):77-84.
[23] WU Di, PENG Cheng-nie, He Yong, et al. Determination of calcium content in powdered milk using near and mid-infrared spectroscopy with variable selection and chemometrics[J]. Food and Bioprocess Technology, 2012, 5(4):1 402-1 410.
[24] 陈立旦, 赵艳茹. 可见-近红外光谱联合随机蛙跳算法检测生物柴油含水量[J]. 农业工程学报, 2014, 30(8):168-173.
[25] YUN Yong-huan, LI Hong-dong, WOOD L R, et al. An efficient method of wavelength interval selection based on random frog for multivariate spectral calibration[J]. SpectrochimicaActa Part A Molecular &Biomolecular Spectroscopy, 2013, 111(7):31-36.
Rapidnondestructivedeterminationofmilkpowerfatcontentbynear-infraredspectroscopy(NIR)
HE Jia-yan1,LI Ting1,GUO Chang-kai1,HU Die1,ZOU Ting-ting1*,WANG Ying2
1(Beijing Key Laboratory of Flavor Chemistry/Beijing Higher Institution Engineering Research Center of Food Additives and Ingredients,Beijing Technology and Business University, Beijing 100048,China)2(Jilin Institute For Food Control,Changchun 130022,China)
Eleven milk powers were diluted into 77 samples. Choosing fat content as the index, the near-infrared spectrum quantitative analysis combined with the partial least squares method were used. Abnormal samples (14, 52 and 76) shall be recognized and removed through twice abnormal spectrum removals. Seventy four milk power samples were studied by six spectrum pretreatments such as smoothing, derivative and standard variable transformation. The best pretreatment method was the standard normal variable transformation combined with Norris first order derivative, which root-mean-square error of cross validation was 0.354 7 and correlation coefficient square of cross validation reached 0.990 8. The established model performance improved by optimal pretreatment spectrum with three band selections. Random Frog (RF) was the optimal band selection method after comparing with the full-spectrum model, which correlation coefficient square of training set and test set were 0.997 2 and 0.997 0 respectively. The root-mean-square of training set and test set were 0.186 2 and 0.198 2 respectively. The result is that Monte-Carlo sampling (MCS), spectrum pretreatment and band optimization technology can improve the generalization and prediction in milk power fat dectection near-infrared quantitative model.
near-infrared spectroscopy; non-destructive testing; fat; Monte-Carlo sampling(MCS) outlier detection; random frog(RF)
10.13995/j.cnki.11-1802/ts.013921
硕士研究生(邹婷婷为通讯作者,E-mail:zou2010@aliyun.com)。
2017-01-23,改回日期:2017-05-08
