基于属性相似性的极大团∗
2017-12-18周翠莲
周翠莲
(昆明理工大学信息工程与自动化学院 昆明 650500)
基于属性相似性的极大团∗
周翠莲
(昆明理工大学信息工程与自动化学院 昆明 650500)
极大团枚举是图论中一个基本问题,且在生活中具有广泛的应用。但一直以来,关于极大团的研究主要集中在图的拓扑结构上,而较少关注顶点上的信息。论文定义一种结合图的结构和属性相似性的极大团,SA-clique,并提出了它的应用场景。针对该SA-clique查询,论文提出一种其充分利用等价点剪枝策略有效求解算法SCQuery。通过实验证明该算法具有较高的效率。
极大团;属性信息;相似性
1 引言
一直以来,极大团枚举一直是学术界的研究热点问题之一,特别是大数据时代的到来,它在各个领域都发挥着重要的作用。例如,在社交网络分析[1]、行为和认知网络中的结构学习[2]和恐怖模式的发现[3]、金融网络中的统计分析[4]、动态网络图聚类[5],以及在生物计算领域中蛋白质相互作用的发现[6]等等。
当然,随着数据信息的急剧增长,也带来了一系列的挑战。处理的图数据不仅结构关系更多,顶点上的属性信息也越来复杂。传统的极大团算法往往只考虑图的结构特性而忽略了图的顶点信息。如图1社交关系网络中,图中顶点r代表用户,顶点r上的属性P是收藏过的网页,边代表用户之间的好友关系。图1有两个3-clique,分别是Q1=(r1,r2,r3),Q2=(r4,r5,r6)。从结构上分析 Q1和Q2都是团,团中的顶点具有强连通性,而从顶点属性上看,Q2比Q1拥有的相同属性更多,Q1有的相同属性是空,而Q2拥有两个相同属性P4、P5。表明了现实生活中Q2中的用户比Q1拥有更多的相似性(具体根据属性内容决定),关系更紧密,且易从Q2推断出用户之间隐藏的关联信息,比如相似爱好等。
为了更好地解决上述问题,本文提出SA-clique,能够很好地解释图的结构关系和属性信息。SA-clique是一种结合图的结构特性和顶点属性的极大团,它将图的拓扑结构和顶点上包含的属性信息紧密关联起来,即此时的SA-clique既满足图的拓扑结构上的强连通性又满足顶点属性的相似性。图1中,从图的结构特征和顶点属性上看,Q2和Q3都是团,但Q2中的顶点之间共同属性值更多。而Q2就是要描述的SA-clique作为一种基于顶点的属性相似性的极大团查询,SA-clique枚举进一步丰富了图查询问题。为了有效查询极大紧密团,本文提出一种利用等价点剪枝策略算法SCQuery。在搜索过程不断缩小候选集大小,提高算法效率。
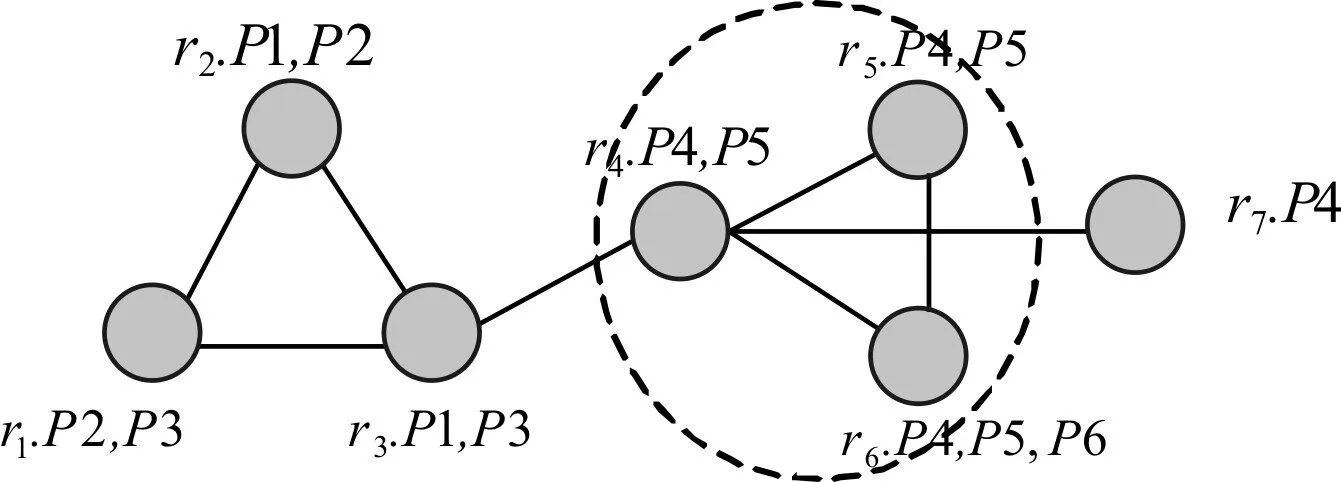
图1 社交关系网络
本文将具体阐述SA-clique的概念,和具体的应用场景,并提出一种等价点剪枝策略的极大紧密团查询算法SCQuery。通过实验结果进一步分析参数c和算法运行时间的关系,算法的效率问题。
2 相关工作
极大团枚举工作一直是学术界关注的热点,其研究成果也很多。Tomita等[4]很早就提出枚举极大团的时间复杂度的问题,并证明在给定一个具有n个结点和m条边的图中,最坏情况下枚举出极大团的时间复杂度是O(3n/3),因为在n个顶点的图中,至多存在3n/3个极大团。接着Jeffrey等[5]在Tomita基础上又证明能在多项式时间内枚举出极大团。
上述较早的文献都只关注了图的结构特性,而忽视了图的属性信息。近些年来,随着图数据的急剧增长,包含的属性信息也愈复杂化,具有重要的研究意义。Zhou等[6]提出基于图结构和属性上的图聚类算法SA-Cluster,将属性转化成一种附加的结构,使得属性和结构统一,最终将原图划分为K簇并且同一簇中结点属性值尽可能相同。孙焕良等[7]提出Top-k属性差异的q-clique查询,该查询旨在发现图中属性差异较大的极大团。
而本文提出的基于频繁属性集的极大紧密团,是结合结构特征和顶点属性两个方面进行的,旨在发现图中顶点属性集尽量相似的极大团,这个相似性本文使用固定参数c去控制,从而使得同一团内的顶点不光从结构上保持强连通性,从顶点属性上也能保持尽量相同。和文献[6]Top-k属性差异的q-clique查询极大团比较,文献[7]查询旨在发现图中属性差异较大的极大团,而SA-clique是发现图中属性值尽量相同的极大团,所以SA-clique顶点属性上更为一致,具有更高的相似性。而文献[11]是将属性转化成图中的结点,使得属性和结构统一,再使用统一度量方式划分,保证同一簇里面的结点属性值尽量相似,这里尽量相似具有不确定性,因为它没有一个指标去控制。而本文SA-clique不仅能够使得同一极大团中的属性值尽量相似,还通过阈值保证了相同属性值的相似性。
3 SA-clique模型
定义1(属性图) G=(V,E,A)表示一个属性图,其中V是无向图G的顶点集,E⊆V×V是图G的边集,用A表示图中每个顶点的相关属性;对于图G中∀v∈V,A(v)表示该顶点的属性集合,它为一个列表{a1,a2,a3,…,an} ,其中 ai为顶点 v 的一个属性值。本文使用二元变量表明该属性值存在的状态,0表示不存在,1表示存在。
例子1 以图1为例,图中每个顶点代表一位用户,具有“网页列表”的属性,图中边表示彼此具有好友关系。顶点r1的属性集合表示为A(r1)={P1,P2}。
定义2(顶点间相似性) 给定图G=(V,E,A),图中具有二元变量属性值的顶点 r1,r2,且(r1,r2)∈E,则其顶点间的相似性定义成:
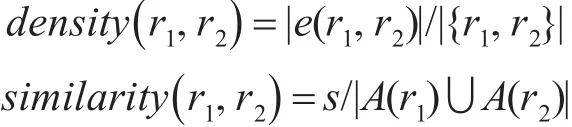
其中,其中s是顶点r1值为1而顶点r2值为1的数目。易知,极大团的density一直为1。所以极大团的相似性取决于顶点属性的相似性。
例子2 以图1为例,例如图中团Q=(r1,r2,r3)的顶点集为{r1,r2,r3} ,它的顶点相似性是

定义3(SA-clique) 给定图 G=(V,E,A)和给定参数c,若图中顶点集V′顶点间的相似满足c,且∄V″⊆V∩V′⊂V″,使得顶点V″导出的子图上的顶点属性相似性满足c,即similarity(V'')≥c,则称V′为图G上的SA-clique。
例子3 以图1为例,自定义c=1,由于顶点集V′={r1,r2} ,有 similarity(V′)=1≥c,又顶点集V′是图G上的团,则称V′是图G上的紧密团。又V″={r1,r2,r3} 的支持度都不满足 c ,所以V′又是图G上的SA-clique。
定义4(等价点) 给定图 G=(V,E,A),若∃A(v1)⊇A(v2)和 e=(v1,v2),则称 v2是 v1的等价点。
定理1:如果V′是图G上的SA-clique,那么V′任何子集也是相似的。
证明:对于 ∀X⊆V′,由于 V′是图G上的SA-clique,即有 similarity(V')≥c。因为包含V′的顶点必包含X,所以有similarity(X)≥c成立,即顶点集X是相似的。
定理2:如果顶点集Y在图G中是非相似的,那么Y的任何超集是非相似的。
证明:反证法。如果∃X⊇Y,且顶点集 X是相似的,根据定理1,Y也是相似。与已知Y为非相似的相矛盾。所以Y的任何超集在图G上都是非相似的。
定理3:如果v1是相似的,存在v2是v1的等价点,那么v2也是相似的,它们的顶点集合也是相似的。
证明:存在 similarity(v1)≥c,由于 v2是v1的等价 点 ,即 ∃A(v1)⊇A(v2) 且 e=(v1,v2) ,即similarity(v2)≥c ,similarity(v1,v2)=s/|A(r1)∪ A(r2)|=s/|A(r1)|=similarity(v1)≥c,similarity(v1,v2)≥c,所以v2也是相似的,它们的顶点集合也是相似的。
4 算法
在极大紧密团搜索过程中,可以充分利用定理3的性质来缩小候选集的大小,提高算法的效率。假设x是已选顶点集,A(x)是x的属性集合,而y是候选集中的任意一个顶点,若存在y是x的等价点,则根据定理3知,y和x的顶点集合也是相似的。因此将顶点y从候选集合中删除,直接合并到已选节点集中。例如图1社交网络关系图,r5,r6彼此之前是等价关系,在搜索过程中,若其中任一顶点是紧密的,则其它也是紧密的,这极大的降低了算法的运算时间。
算法SCQuery具体执行过程如算法1所示。
算法 1:SCQuery(CAND,c,m_Q)
输入:候选集合cand,初始化为G的顶点集V
给定参数c
当前已选集合snodes
输出:存储极大紧密团集合mc
1. if cand=Ø
2. if snodesQ∉mc
3. mc←snodes
4. return
5. if snodes!=Ø
6. calculate候选集合cand中的等价点
7. 将等价点从cand中删除,加入snodes
8. while cand!=Ø
8. if cand∈mc return
9. Q=cand中相似性最大的顶点
12. cand=cand-Q
13. if similarity(snodes,Q)≥c)
14. snodes add Q
15. candq=cand∩Q的邻居节点
16. SCQuery(candq,c,snodes)
步骤1~4描述当前的候选集cand为空时,表明SA-clique已经出现,此时步骤2判断该极大紧密团是否被发现,如没有则加入到SA-clique集合中,搜索结束。若候选集不为空,需对当前的候选集继续搜索,首先判断候选集存在与已选集合等价关系的等价点,将它们直接从候选集cand中删除,加入已选集合中。步骤8~16描述了非等价点的处理,如候选集已经SA-clique则停止搜索,否则从cand任选一顶点赋值给Q,计算已选集合snodes在加入Q后是否相似,若相似,将Q加入snodes中,根据极大团的结构特性计算新的候选集合。否则,返回步骤8,继续向下搜索。SCQuery的时间复杂度O(n2)。
5 实验分析
5.1 实验环境
本文的算法采用C++实现,实验平台是C++开发工具Visual Studio 2010和图分析库SNAP(Stanford Network Analysis Platform)。所有实验都是在一台PC机上运行的,PC机的配置如下:处理器Intel双核,3.0GHz,内存4GB,Windows7操作系统。
5.2 实验数据
本文实验使用DBLP数据集。从数据集中抽取出作者发表论文信息,建立作者合作关系图,图中顶点作者,边代表作者之间存在合著文献的关系,顶点上的属性是作者论文列表。
5.3 算法效率分析
本文通过设置不同的参数进行实验对比,比较算法的效率。
通过实验结果对比图可以发现,图2(a)随着图的大小不断增大,算法的运行时间是不断提高的,这是因为要处理的计算量越来越大。而通过图2(b)发现,相似性和算法效率成反比,参数c设置的越大反而算法的运行时间越短。因为实际上在作者合作关系网络中,作家合著的文献数是较低的,当参数c的值越高,满足SA-clique的候选集越少。
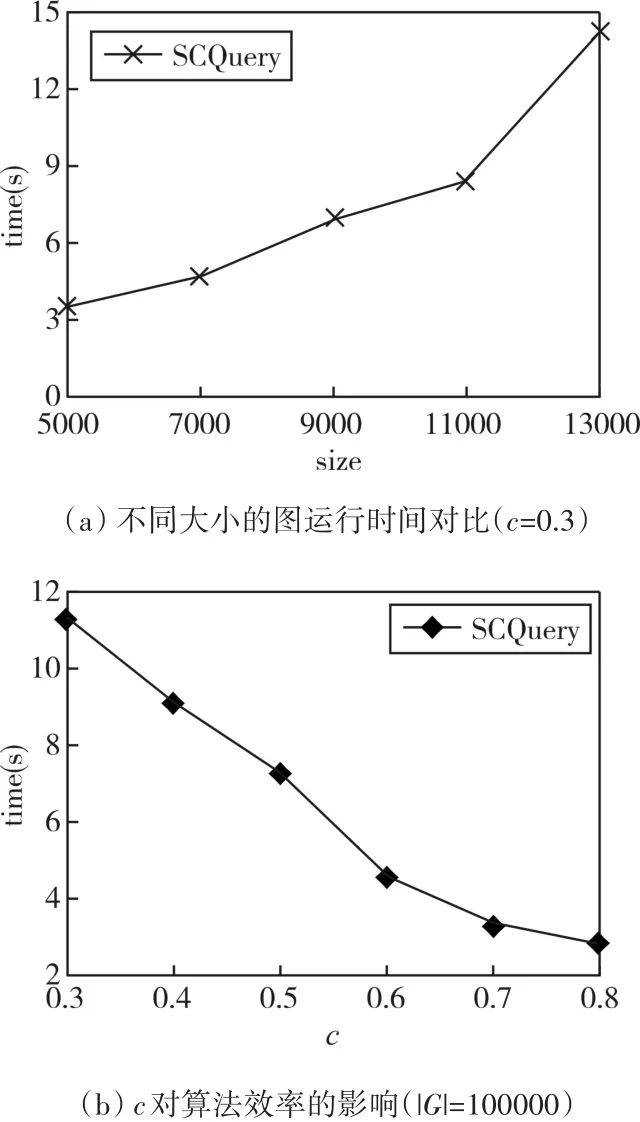
图2 DBLP-Papers数据集实验结果对比
6 结语
本文提出了一种结合图的结构特征和顶点上的属性相似性的极大团SA-clique:图的结构和顶点属性满足一定的紧密性和相似性的。例如图1枚 举 出 的 SA-cliqueQ2=(r4,r5,r6) 、比 极 大 团Q1=(r1,r2,r3)成员之间交往的更频繁和紧密,表明了SA-clique具有重要的实用价值。为了有效枚举SA-clique,本文提出一种等价点剪枝策略算法SCE-PE,在搜索过程中不仅利用图的结构特性和Apriori性质减去不能形成极大团的枝,同时利用等价点剪枝策略,减小候选集大小提高算法性能。最后本文利用DBLP-Papers对算法效率进行测试。实验表明SCQuery能够有效的枚举出SA-clique。
[1]Wasserman,Faust.Social Network Analysis:Methods and Applications[J].American Ethnologist,1997,24(1):219-220.
[2]H.R.Bernard,P.D.Killworth.Informant Accuracy in Social Network Data iv:A Comparison of Clique-Level Structure in Behavioral and Cognitive Network data[J].Social Networks,2(3):191-218,1979.
[3]N.M.Berry,T.H.Ko,T.Moy,J.Smrcka,J.Turnley.Emergent Clique Formation in Terrorist Recruitment[J].In The AAAI-04 Workshop on Agent Organizations:Theory and Practice,2004.
[4]Boginski V.Statistical Analysis of Financial Networks[J].Computational Statistics&Data Analysis,2005,48(2):431-443.
[5]V.Stix.Finding all Maximal Cliques in Dynamic Graphs[J].Computational Optimization and Applications,2004,27:173-186.
[6]F.N.Abu-Khzam.On the Relative Efficiency of Maximal Clique Enumeration Algorithms,with Applications to High-through Put Computational Biology[C]//In International Conference on Research Trends in Science and Technology,2005.
[7] Tomita,E.,Tanaka,A.,Takahashi.The Worst-case Time Complexity for Generating all Maximal Cliques and Computational Experiments[J].Theory.Compute.Sci.,2006,363(1):28-42.
[8]Chang L,Yu J X,Qin L.Fast Maximal Cliques Enumeration in Sparse Graphs[J].Algorithmica,2013,66(1):173-186.
[9]Zhou Yang.Cheng Hong,Yu Jeffrey Xu.Graph Clustering Based on Structural//Attribute Similarities[C]//Proceedings of the VLDB Endowment,2009,2(1):718-729.
[10] Sun Huangliang,Lu Zhi.Top-k Attribute Difference q-clique Queries in Graph Data[J].Chinese Journal of Computes,2012,11:2265-2274.
Maximal Clique Based on Attribute Similarities
ZHOU Cuilian
(Faculty of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650500)
Maximal clique enumeration is a fundamental problem in graph theory and widely applied to various fields However,many existing graph clustering methods mainly focus on the topological structure,but largely ignore the vertex properties.In this paper,a novel maximal clique,SA-clique,based on both structural and attribute through a attribute similarities measure is proposed,and its application scenarios is present.Meanwhile,an efficient algorithm SCQuery is proposed,which takes full advantage of the equivalent pruning strategy.The efficiency of the algorithm is proved by experiments.
maximal clique,attribute,similarities
TP391
10.3969/j.issn.1672-9722.2017.11.028
Class Number TP391
2017年5月4日,
2017年6月18日
周翠莲,女,硕士,研究方向:数据挖掘和图挖掘。
