卷积神经网络及其在手写体数字识别中的应用
2017-12-11马媛媛史加荣
马媛媛,史加荣
( 西安建筑科技大学 理学院,陕西 西安 710055)
卷积神经网络及其在手写体数字识别中的应用
马媛媛,史加荣*
( 西安建筑科技大学 理学院,陕西 西安 710055)
深度学习是机器学习领域的研究热点,它使机器学习更加接近人工智能。作为深度学习的一类经典模型,卷积神经网络已被广泛应用于语音识别、图像识别和自然语言处理等领域中。本文探讨了卷积神经网络的基本原理、实现及应用。首先回顾了卷积神经网络的发展历史,阐述了它的基本原理,研究了卷积层和下采样层;其次总结了卷积神经网络的三大重要特性:稀疏连接、权值共享和池采样,并将卷积神经网络应用在MNIST手写体数字识别任务中;最后指出了卷积神经网络未来的重点研究方向。
卷积神经网络;深度学习;卷积;下采样;手写体数字识别
人工智能是一门研究开发模拟、延伸和扩展人类智能的技术,其主要研究内容可归纳为四个方面:机器感知、机器思维、机器行为和机器学习[1]。而机器学习是利用计算机、概率论、统计学等知识,通过给计算机程序输入数据,让计算机能够学习新知识和新技能,其最初的研究动机是为了让计算机系统具有人的学习能力以便实现人工智能[2]。深度学习是基于学习特征的更广泛的机器学习方法,它试图在多个层次中进行学习,其中较高层次的概念是从较低层次的概念中定义的,而较低层次的概念可以帮助定义许多更高层的概念[3]。
随着研究的不断深入,深度学习技术已经被应用到数以百计的实际问题中,且超出了传统的多层神经网络的内涵。2006年机器学习领域泰斗Hinton教授提出了利用受限的玻尔兹曼机进行预训练的方法[4-5],主要观点为:人工神经网络模型的层数越深,其特征学习能力越强;可通过“逐层训练”的学习算法解决深度神经网络在训练上的难题。该方法引发了深度学习在研究和应用领域中的浪潮。同年,Hinton等人还提出了一种贪婪的逐层学习算法:深度置信网络,该网络先采用无监督学习对整个网络进行预训练,再采用监督学习对整个网络进行反向微调[6]。此后,深度学习的各种模型被相继提出,主要包括:自编码器[7]、稀疏自编码器[8]、卷积神经网络[9]、循环神经网络[10]等,其中,卷积神经网络(Convolutional Neural Network, CNN)是深度学习的一种较为经典的神经网络模型。
卷积神经网络是一类特殊的用于数据处理的神经网络,它受视觉系统结构的启发,由生物学家Hubel和Wiesel于1962年提出。他们通过对猫的实验发现:人的视觉系统的信息处理是分级的,初级视觉皮层提取边缘特征,中级视觉皮层提取形状或者目标,更高层的视觉皮层得到特征组合[11]。受此启发,Lecun等人[12]于1989年提出了卷积神经网络。此后,卷积神经网络被广泛地应用于图像处理、语音识别和时间序列分析[13]等领域中,并衍生出许多改进模型。
2012年,Krizhevsky等[14]提出了AlexNet模型,该模型为包含8个学习层的卷积神经网络,并在该年ImageNet[15]国际计算机视觉挑战赛中夺得冠军,这使卷积神经网络成为学术界关注的焦点。此后,每年的ImageNet挑战赛中都出现了新的卷积神经网络模型,这些模型不断地刷新着AlexNet在ImageNet上创造的记录。深度卷积神经网络已成为众多学科研究的热点,被广泛地应用于图像识别[16]、语音识别[17]和自然语言处理[18]等领域中。
1 卷积神经网络的基本原理
卷积神经网络是一类特殊的深度前馈神经网络,主要由输入层、隐层、全连接层和输出层组成,而隐层是由卷积层和下采样层交替连接的。一个经典的卷积神经网络模型如图1所示,该模型共七层,其中包括一个输入层、两个卷积层、两个采样层、一个全连接层和一个输出层。卷积层通过卷积操作提取特征,再通过下采样操作将提取的特征组合成更加抽象的特征,接着将组合的特征输入到一个或多个全连接层,而全连接层的每一个神经元与前一层的所有神经元进行全连接,最后一个全连接层连接到输出层。下面分别介绍卷积神经网络的各个模块[19]。
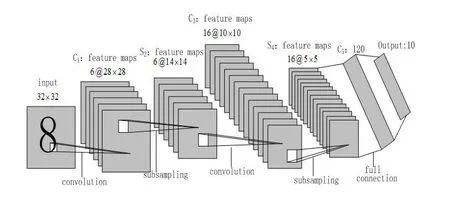
图1 卷积神经网络架构图
1.1输入层与输出层
在输入层中,一般输入数据是图像。对于灰度图像或RGB图像,像素的取值范围为0~255,它代表像素灰度。输出层一般采用softmax逻辑回归函数进行分类。
1.2卷积层
卷积是数学分析中一种重要的线性运算,是两个变量在某范围内逐点相乘求和的结果[20-21]。在图像处理中,图像通常表示成二维矩阵的形式。因此只考虑离散序列情形,且只对二维卷积做阐述。图2给出了一个二维卷积操作的例子(不包含卷积核的翻转)。在图2中,左上角为输入数据(4×4矩阵),右上角为卷积核(2×2滤波器),下方为卷积操作结果(3×3矩阵)。由该图可以看出,卷积核被重复地应用于整个输入数据中,最终得到卷积的输出结果。

图2 二维卷积运算示意图

(1)

1.3下采样层
下采样层也称池化层[19-24],它可以大大减少神经元的个数,在一定程度上降低网络的拟合程度。下采样层旨在通过降低特征维数来获得具有空间不变性的特征。池化就是将输入图像进行缩小,这在一定程度上保留了一些重要或者突出的信息。常用的池化方法有最大池化(max pooling)或均值池化(average pooling)[24-25]。最大池化是指取采样区域中的最大值作为像素值,该方法特别适用于分离特别稀疏的特征的情形。图3给出了最大池化运算示意图。在图3中,9×9的原始数据按2×2的大小大致被分成3×3的分块矩阵,而每个子块矩阵用其最大值来代替。通过最大池化运算,9×9的矩阵被缩小为3×3的矩阵。

图3 最大池化运算示意图
均值池化是指取采样区域内所有值的均值作为结果的输出值,该方法用到了采样区域内所有的采样点。图4给出了均值池化运算示意图,其左边为输入数据,右边为经过均值池化运算后的输出矩阵。在进行均值池化运算时,取输入图像中每一个大小为2×2的子块的平均值作为输出像素值,如果子块大小不足 ,则用0补充。经过均值池化操作后,一幅图像大约也缩小为原来的四分之一。

图4 平均池采样运算示意图

(2)

1.4全连接层
全连接层可以整合卷积层或者下采样层中具有类别判别性的局部信息[26]。为了提升卷积神经网络的性能,全连接层的每个神经元的激励函数可采用ReLU函数[27]或者其他非线性函数,其中,ReLU函数为f(x)=max(0,x)。与sigmoid、tanh等函数相比,ReLU的数学公式简单,且只有一个阈值0,因此它可以避免梯度弥散现象。全连接层的主要目的是维度变换,即把高维分布式特征表示变成低维的样本标记。在这个过程中,有用的信息被保留下来,但会损失特征的位置信息。
2 卷积神经网络的重要特性
卷积神经网络有三大重要特性:稀疏连接、权值共享和池采样,它们可以帮助改善机器学习系统。这些特性使卷积神经网络在一定程度上具有平移、缩放和扭转不变性。
2.1稀疏连接
卷积神经网络是对BP神经网络的改进,它们都采用信号的正向传播计算输出值,且使用误差的反向传播对模型进行监督训练。但卷积神经网络的相邻层之间并不是全连接,而是稀疏连接或部分连接,即某个神经元的感知区域来自于上层的部分神经元。例如,在处理图像时,输入图像可能具有数千甚至数百万个像素,但侦测到有意义的特征只占很小的一部分,如内核边缘只占据几十或几百个像素。换言之,我们需要存储更少的参数,既能减少模型的内存需求,又能提高统计效率[19,24,27]。卷积神经网络采用稀疏连接的方法,从而限制了每个输出可能具有的连接数。假设有m个输入节点和n个输出节点,全连接方法需要m×n个参数;而稀疏连接的方法限制了每个输出可能具有的连接数k(k远远小于m),有k×n个参数。图5给出了神经元之间的全连接示意图, 图6给出了神经元之间的稀疏连接示意图。以输入节点x3及输出节点S为例,全连接中的所有输出节点都受到x3的影响,而稀疏连接只有三个输出节点受x3影响。

图5 全连接示意图

图6 稀疏连接示意图
2.2权值共享
在传统的神经网络中,当计算某层的输出时,权值矩阵的每个元素只被使用了一次。而在卷积神经网络中,卷积核共享相同的参数,即相同的权值矩阵和偏置。权值共享是卷积核的参数共享,参数共享并不影响前向传播的计算复杂度,并且还降低了网络复杂度[19,24,28]。
2.3池化
卷积层在获得图像特征之后,可以利用所提取的特征进行分类器训练,但这通常会产生极大的计算量。因此,在获取图像的卷积特征后,通过池化方法对卷积特征进行降维,且在一定程度上保留了一些重要或者突出的信息[24,29]。当下采样区域为特征映射的连续区域时,得到的下采样单元具有平移不变性。
3 卷积神经网络在MNIST数据集中的应用
3.1 MNIST数据集简介
MNIST数据集是一个非常简单的手写体数字识别数据集(http://yann.lecun.com/exdb/mnist/),包含0~9共10类手写体数字图像,每幅图像大小为28×28。将此数据集分成60000个训练样本和10000个测试样本[30-31]。本文的算法在Matlab R2014a版本中编码,并在具有2.9GHz CPU的电脑上运行。本文参考DeepLearnToolbox的代码[31],其网址如下:
https://github.com/rasmusbergpalm/DeepLearnToolbox
手写体数字识别是字符识别领域中最具挑战性的课题,有很大的难度,主要原因如下。由于书写者的因素,字符图像的随意性很大;对于同一个数字而言,写法有很大的不同且有很大的区域性,故很难有较高的识别率;在银行和金融等实际应用中,对数字识别率的要求比文字要苛刻很多。
3.2实验设计
使用MNIST数据集来验证卷积神经网络的有效性。除输入层和输出层外,将卷积神经网络设置为一个四层的神经网络,即两个卷积层和两个下采样层。第一个卷积层(C1)有6个卷积核,大小均为5×5,经卷积后得到6张特征图;第一个下采样层(S2)的采样核大小为2×2;第二个卷积层(C3)有12个卷积核,大小均为5×5,经卷积之后得到12张特征图;第二个下采样层(S4)的采样核大小为2×2。
卷积神经网络的训练参数设置如下:
opts.batchsize=50;
%每次选择50个样本进行更新
opts.alpha=1; %学习率
opts.numpochs=50; %最大迭代次数
卷积神经网络的设置和训练程序如下:
cnn=cnnsetup(cnn, train_x, train_y);
% 对各层参数进行初始化,包括权重和偏置
cnn=cnntrain(cnn, train_x, train_y, opts);
% 开始训练,包括BP算法及迭代过程
式中,train_x为训练数据集,train_y为测试数据集,第一个输入的cnn表示将其设置传递给cnnsetup,据此构建一个完整的CNN网络,第二个输入的cnn表示CNN网络结构的初始化, 再根据训练样本来更新CNN网络。
3.3实验结果与分析
图7绘出了卷积神经网络在MNIST数据集上的均方误差图,其中横坐标是网络训练过程中的迭代次数,纵坐标是该网络模型在训练过程中对MNIST数据集的均方误差。由于在网络设置时选择了50个样本为一批进行更新,且共有60000个样本,所以迭代了1200次。
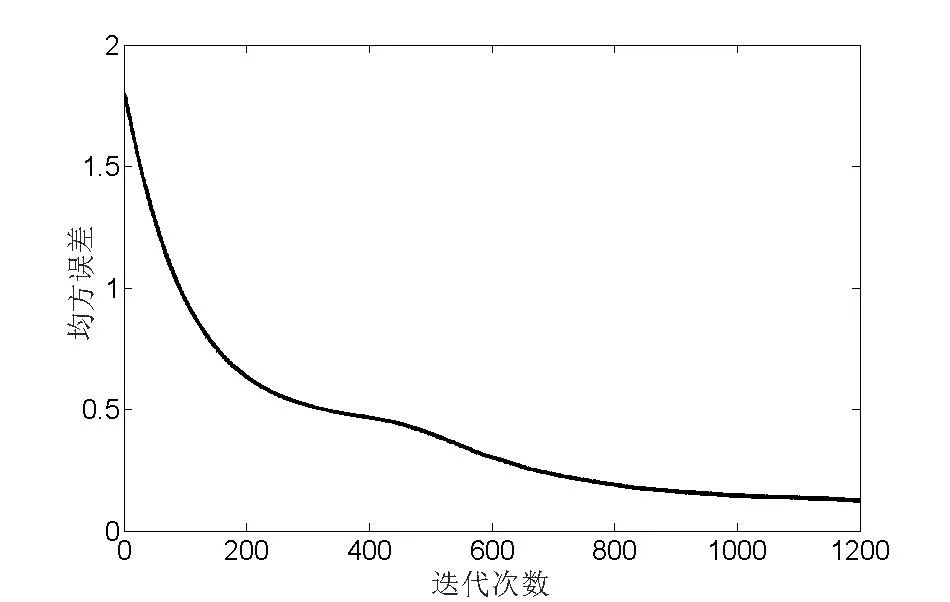
图7 CNN在MNIST数据集上的均方误差
从图7可以看出,在进行了1200次迭代后,该网络的均方误差达到0.11,之后趋于稳定状态,因此可以认为达到了算法的终止条件。卷积神经网络的1200次迭代共用时间139秒,网络的识别率为98.62%,而人工神经网络的识别率为93.46%,卷积神经网络比人工神经网络的识别率大约提高了5%。
4 卷积神经网络的研究展望
作为一种深度学习技术,卷积神经网络的发展极其迅速,是近几年来研究和应用最为广泛的深度神经网络。但卷积神经网络也面临着更多的挑战,主要体现在以下几个方面。
4.1理论研究
卷积神经网络是受生物学启发而提出的,其本身是对生物视觉成像的一种模拟。但目前的研究还未对卷积神经网络的运作机理给出详细的阐述。Nguyen等通过进化算法将原始图像处理成人们完全无法识别和解释的一种形式,但卷积神经网络却对转化后的图像形式给出了非常准确的物体类别判断[32]。这种卷积神经网络出现的被“欺骗”现象引起了人们对卷积神经网络特征提取的完备性关注。
与传统的神经网络相比,卷积神经网络在提取特征时受网络结构、学习算法以及训练集等多种因素影响,对其原理的分析与解释比人工设计特征更加抽象和困难[33]。2017年,Levine等学者发现深度卷积算术电路所实现的函数与量子多体波函数之间存在某种等价性[34],但是否可用物理学打开深度学习的黑箱还有待进一步研究。学术界普遍采用的是以实验为导向的研究方式,这导致卷积神经网络的发展缺乏理论研究的支持。因此,卷积神经网络的相关理论研究是目前最为匮乏、最有研究价值的内容。
4.2应用领域
经过多年的发展,卷积神经网络的应用领域已从最初的手写体识别和人脸识别,逐渐扩展到一些更为广泛的领域,如:自然语言处理、语音识别和目标检测等。在目标检测应用中,许多卷积神经网路的改进模型相继被提出,如R-CNN[35]、Fast-CNN[36]和Faster-CNN[37],这些模型在一定程度上突破了卷积神经网络的瓶颈。在人工智能领域,AlphaGo成功地利用了卷积神经网络对围棋的盘面形势进行判断[37]。在语音识别方面,Abdel-Hamid等人将语音信息建模成符合卷积神经网络的输入模式,并结合了隐马尔科夫模型[17]。
4.3开源框架
近年来,卷积神经网络的研究热潮持续高涨,各种开源工具层出不穷。代表性的开源工具包括Caffe[38]、Tensorflow[39]和Theano[40]等。作为深度学习框架之一,Caffe基于C++语言编写,并且具有BSD开源代码,可以在CPU及GPU上运行,且支持Matlab和Python接口。Caffe提供了一整套的数据流程,如数据预处理、训练、测试、微调等。Tensorflow是谷歌公司在2015年底发布的开源人工智能系统,此系统架构灵活,在很多平台上都可以使用,支持一个或多个CPU。与Tensorflow相似,Theano系统的架构也比较灵活,它由LISA实验室在蒙特利尔大学开发,是深度学习较早的库之一。Theano实际上是一个Python库,允许用户定义、优化和计算数学表达式,特别是提高多维数组的运算性能。这些工具的使用虽然加快了深度学习的发展,但仍然存在一些遗留的框架问题,比如:Caffe不善于处理循环神经网络问题,且灵活性较差;Tensorflow在单个GPU上的性能不如其它几个框架; Theano不能直接进行卷积神经网络的预训练。
4.4网络结构
卷积神经网络的层数越深,实验结果可能越好,在实际应用中网络层数已多达上千层。随着网络传播深度的增加,模型的参数也会相应增加,此时网络需求大量的有标签数据,否则可能导致网络的过拟合;而相应的网络权重会越来越小,出现网络的权重衰减。这些问题使卷积神经网络难以在普通设备上应用[41-42]。因此,网络结构设计上的优化需符合应用,注重模型架构中的分支数量,而不是继续增加网络的深度等。
5 结束语
本文从卷积神经网络的基本原理和重要特性来研究卷积神经网络理论。首先回顾了卷积神经网络的重要组成部分:卷积层、下采样层和全连接层,接着讨论了卷积神经网络的三大特性:稀疏连接、权值共享、池采样,然后将卷积神经网络应用于手写体数字识别上,最后展望了卷积神经网络未来的研究。如何避免过拟合现象、提高网络的学习能力和设置合理的参数将是卷积神经网络今后亟待解决的问题。
[1] 陈雯柏. 人工神经网络原理与实践[M]. 西安:西安电子科技大学出版社, 2016.
[2] Arel I, Rose D C, Karnowski T P. Deep machine learning-a new frontier in artificial intelligence research[J]. IEEE Computational Intelligence Magazine, 2010, 5(4): 13-18.
[3] Deng L, Yu D. Deep learning: methods and applications[J]. Foundations and Trends in Signal Processing, 2014, 7(3): 197-387.
[4] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
[5] Bengio Y, Lamblin P, Popovici D,et al. Greedy layerwise training of deep networks[C]// Advances in neural information processing systems. 2007: 153-160.
[6] Hinton G E, Osindero S, Teh Y W. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527-1554.
[7] Deng L, Seltzer M L, Yu D, et al. Binary coding of speech spectrograms using a deep auto-encoder[C]//Eleventh Annual Conference of the International Speech Communication Association. 2010: 1692-1695.
[8] Bengio Y, Courville A, Vincent P. Representation learning: A review and new perspectives[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1798-1828.
[9] Abdel-Hamid O, Deng L, Yu D. Exploring convolutional neural network structures and optimization techniques for speech recognition[C]//Interspeech, 2013: 3366-3370.
[10] Martens J, Sutskever I. Learning recurrent neural networks with hessian-free optimization[C]// International Conference on International Conference on Machine Learning. Omnipress, 2011:1033-1040.
[11] Hubel D H, Wiesel T N. Receptive fields, binocular interaction, and functional architecture in the cat’s visual cortex[J]. Journal of Physiology,1962, 160(1):106-154.
[12] Lecun Y, Bottoy L, Bingio Y, et al. Gradient-based learning applied to document recognition [J].Proceedings of the IEEE,1998, 86(11): 2278-2324.
[13] LeCun Y, Bengio Y. Convolutional networks for images, speech, and time series[J]. The Handbook of Brain Theory and Neural Networks, 1995, 3361(10): 255-258.
[14] Krizhevsky A,Sutskever I ,Hinton G E.ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems,2012,1097-1105.
[15] Deng J,Dong W, Socher R, et al.Imagenet:a large-scale hierarchical image database[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009:248-255.
[16] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J].arXiv preprint arXiv:1409.1556, 2014.
[17] Abdel-Hamid O, Mohamed A, Jiang H, et al. Convolutional neural networks for speech recognition[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(10):1533-1545.
[18] Kalchbrenner N, Grefenstette E, Blunsom P. A convolutional neural network for modelling sentences[J]. arXiv preprint arXiv: 1404.2188, 2014.
[19] 邓力,俞栋.深度学习方法及应用[M].北京:机械工业出版社,2015.48-57.
[20] Bouvrie J. Notes on Convolutional Neural Networks[J]. Neural Nets, 2006.
[21] Bengio Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1): 1-127.
[22] 周飞燕,金林鹏,董军.卷积神经网络研究综述[J]. 计算机学报, 2017,40(6):1229-1251.
[23] 马世龙,李小平.大数据与深度学习综述[J].智能系统学报, 2016,11(6): 728-742.
[24] Goodfellow L, Bengio Y, Courvile A. Deep learning[M].MIT press,2016.
[25] Sainath T N, Mohamed A, Kingsbury B, et al. Deep convolutional neural networks for LVCSR[C]// IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).2013: 8614-8618.
[26] O’Shea K, Nash R. An introduction to convolutional neural networks[J]. arXiv preprint arXiv: 1511.08458,2015.
[27] 焦李成, 赵进, 杨淑媛,等. 深度学习、优化与识别[M].北京:清华大学出版社,2017: 100-120.
[28] Yu D, Deng L. Deep learning and its applications to signal and information processing [J]. IEEE Signal Processing Magazine, 2011, 28(1): 145-154.
[29] Zeiler M D, Fergus R.Visualizing and understanding convolutional networks[C]//European Conference on Computer Vision. Springer, Cham, 2014: 818-833.
[30] Deng L. The MNIST database of handwritten digit images for machine learning research[J]. IEEE Signal Processing Magazine, 2012, 29(6): 141-142.
[31] Palm R B. Prediction as a candidate for learning deep hierarchical models of data[J]. Technical University of Denmark, 2012(5).
[32] Nguyen A, Yosinski J, Clune J. Deep neural networks are easily fooled: high confidence predictions for unrecognizable images[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 427-436.
[33] 李彦冬, 郝宗波, 雷航.卷积神经网络研究综述[J].计算机应用, 2016, 36(9):2508-2515.
[34] Levine Y, Yakira D, Cohen N, et al. Deep learning and quantum physics: a fundamental bridge[J]. arXiv preprint arXiv: 1704.01552, 2017.
[35] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
[36] Girshick R. Fast r-cnn[C]//Proceedings of the IEEE International Conference on Computer Vision, 2015: 1440-1448.
[37] Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Advances in Neural Information Processing Systems, 2015: 91-99.
[38] Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional architecture for fast feature embedding[C]//Proceedings of the 22nd ACM International Conference on Multimedia, 2014: 675-678.
[39] Abadi M, Barham P, Chen J, et al. TensorFlow: a system for large-scale machine learning[C]//OSDI. 2016, 16: 265-283.
[40] 孙志军,薛磊,许阳明, 等.深度学习研究综述[J].计算机应用研究, 2012, 29(8):2806-2810.
[41] Schmidhuber J. Deep learning in neural networks: An overview[J].Neural networks, 2015, 61: 85-117.
[42] Ba J, Frey B. Adaptive dropout for training deep neural networks[C]//Advances in Neural Information Processing Systems, 2013: 3084-3092.
(责任编辑:熊文涛)
ConvolutionNeuralNetworkandItsApplicationinHandwrittenDigitsRecognition
Ma Yuanyuan, Shi Jiarong*
(SchoolofScience,Xi′anUniversityofArchitectureandTechnology,Xi′an,Shaanxi710055,China)
Deep learning is a new research focus in the field of machine learning and its emergence makes machine learning closer to the goal of artificial intelligence. As a classical model in deep learning, convolution neural network has been widely applied in the fields of speech recognition, image recognition, natural language processing, etc. This paper discussed the basic principle, realization and applications of convolution neural network. Firstly, it reviewed the history of convolution neural network and elaborated its basic principle of convolution neural network and investigated the convolution layer and the sub-sampling layer. Secondly, it summarized the three important characteristics of convolution neural network, i.e., sparse connection, weight sharing and sub-sampling. The handwritten digits recognition task of convolution neural network was also realized in the MNIST database. Finally, it gave future key research directions for convolution neural network.
convolution neural network; deep learning; convolution; sub-sampling; handwritten digits recognition
TP183
A
2095-4824(2017)06-0066-07
2017-08-15
国家自然科学基金青年科学基金(61403298);中国博士后科学基金(2017M613087)
马媛媛(1991- ),女,陕西富平人,西安建筑科技大学理学院硕士研究生。
史加荣(1979- ),男,山东东阿人,西安建筑科技大学理学院副教授,博士,本文通信作者。
