制造物联中弹性分布式海量数据分析系统的设计与实现
2017-08-12程良伦
杜 量 程良伦
(广东工业大学计算机学院 广东 广州 510006)
制造物联中弹性分布式海量数据分析系统的设计与实现
杜 量 程良伦
(广东工业大学计算机学院 广东 广州 510006)
对于制造物联领域中持续产生的海量、多源、结构复杂的工业生产数据来说,具有数据量大、易堆积、分析处理困难以及难以可视化的特点。设计实现了一种弹性分布式的海量数据分析系统,以弹性分布式的大数据计算框架为核心,并采用模块化和层次化的系统设计,使其具有松耦合、易拓展及容错性强的特点。把该系统应用于某汽车零配件生产企业,实际应用效果表明,该系统可以很好地应对制造物联领域中的海量数据分析处理问题。
制造物联 海量数据处理 分布式 数据分析系统
0 引 言
制造物联是物联技术在制造领域中渗透和应用的产物[1-2],其在提升企业生产制造效率和促进制造业转型发展有着重要的作用。在制造物联领域中,特别是具有生产过程复杂、生产工序繁多、产品质量把控严格的特点的现代工业产品制造过程中。为了保证生产过程的高效率进行和高质量的工业产品产出,实时的数据采集和监控系统会采集和汇总各项生产数据,并需要相应的数据分析处理系统对以上数据进行及时地分析处理。而对于这些来源复杂多样的数据来说,其具有如下特点[3]:
1) 数据海量性。伴随生产过程的进行,数据采集和监控系统每天收集的数据可达GB级甚至更大量级。
2) 数据类型多样。数据中包含关系型数据、半结构化数据流数据、多维数据,以及无结构的文档等。
3) 数据时空相关及动态流式特性。制造物联中数据采集系统所收集的数据往往存在空间属性和时间属性,并且数据特性上普遍存在动态流式的特性。
由于以上的制造物联中的数据特性,使得传统、常规的数据分析处理手段或系统在面对以上的数据时显得捉襟见肘。而对于制造物联中工业数据的处理分析恰恰是制造物联中不可或缺的重要一环。因此,设计和实现高效、强大的海量数据分析处理系统来解决海量、多源、复杂的制造物联数据所带来的数据处理分析问题就变得十分重要了。
根据以上描述,本文设计实现了一种制造物联环境下的以弹性分布式数据管理平台为基础的海量实时数据分析处理系统。该系统以大数据分布式计算集群为核心层,采用分层的系统架构,各层之间采用模块化设计,使得系统具有高可用性和高扩展性。并且依赖于模块间的松耦合,使得模块可实现依据业务场景的热插拔及高容错性。该系统的具体实现以及在某汽车零配件生产企业中的实际运行效果表明,该系统能够很好地解决制造物联中海量数据分析处理问题。
1 相关背景
对于制造物联中的海量数据处理来说,传统的数据存储和分析处理方法一般来说难以满足其分析处理要求,特别是在面对PB级数据量及多元结构的数据类型时,更是显得捉襟见肘[5]。因此,当前的研究者们主要是借助分布式的机器集群以及高效强大的大数据处理框架来实现大数据处理分析平台以实现海量数据的存储、管理以及分析研究[6]。
1) 以数据源为中心构建的数据分析以及管理框架的研究[7],包括物联网环境下的数据存储与查询研究[8]、多来源数据的整合分析研究;
2) 构建高可用性大数据处理集群和更高效的大数据处理工具如Hadoop、Spark等来实现制造物联中的数据分析处理[9];
3) 结合云计算等技术实现制造物联领域中海量数据的分析处理[13],如文献[6,13-14]中通过结合云计算进行海量数据的分析处理和挖掘。
通过以上的分析可以看出,针对制造物联中的海量数据特点和分析处理要求[15],需要研究设计以分布式大数据集群为基础来构建具有高可用性、高可拓展性的海量数据分析处理系统来解决海量数据的高效率存储、查询和分析处理问题[16]。
2 系统设计描述
针对制造物联中的海量数据以及对其的分析处理要求,相应的处理分析系统也当具备高可用性、高拓展性、高容错性以及近实时的特点。本文中设计实现的系统以分布式大数据机器集群为核心,并辅以清晰的系统层次划分和各层中模块化的软件设计。下面给出系统设计的详细描述:
系统总体架构上采用分层结构,在每层中采用模块化的设计。对于每层中的模块会依据业务场景的不同和数据处理的需要进行相应地选择和插拔,模块化和层次化的结构特性以及高可用性的分布式集群使得系统具有松耦合、高可用性高容错性的特点。系统设计如图1所示。

图1 系统架构图
对于系统总体来说,将其划分为数据采集层、数据仓库层、海量数据分析处理层、中间结果存储层以及最终的可视化前端展示层。数据会依次进入系统的每个层次,并通过位于每层中的数据处理模块中进行相应的分析和处理。
首先,对于生产过程中的原始数据来说,会通过数据采集层进行采集和汇总,并随后导入数据仓库层。在该层中通过诸如Hive等数据仓库工具进行原始数据的必要清洗和依据业务的数据ETL操作。在完成原始数据的入库后,位于系统核心的数据处理分析层会依据业务场景从数据仓库中进行相应数据的选取。采用弹性分布式大数据处理集群以及如Hadoop、Spark等大数据处理工具进行相应的分析处理,并将分析处理结果导入中间结果处理层。在该层中数据会分别进入企业级搜索引擎如Elasticsearch、Lucene以及RDMS中或NOSQL数据库中。最终,在前端展示层中会通过如Spring mvc等Web框架获取中间结果层的数据并依据业务场景的可视化要求进行最终结果的展现。
2.1 数据采集层与数据仓库层
通常,制造物联中的原始数据在进行数据采集时往往会依赖于基于RFID数据采集系统的企业级的数据采集系统进行工业生产数据采集,并且相应数据的存储和持久化会在数据采集系统中进行完成。
针对制造物联中生产数据的数据仓库建设和大量数据的高效存储要求,在完成数据采集后进行制造物联中数据仓库的构建时,考虑到制造物联领域中的生产数据特点,其数据仓库的构建时必须具备如下维度:1) 设备维度,包括设备型号、设备功能、设备状态、设备损耗状态等设备信息;2) 生产周期维度(时间维度),包括生产计划、生产进度、生产量等生产周期信息;3) 产品维度,包含产品型号、产品规格、产品质量信息等产品信息;4) 生产人员维度,包含员工编号、员工工位、员工技能等人员信息;5) 生产工序维度,包含工序编号、工序详情、工序原料等生产工序必备信息。对于制造物联中的数据特点在进行数据存储时需要实现数据本身以及数据存储的高可用性(HA)。针对制造物联中的制造企业的特点在实现高可用性时,基于冗余的本地高可用以及基于冷备、热备,增量全量的备份容灾方案为建设时的必须要求。而对于数据仓库的具体建设和数据在数据仓库层的基本操作如依据业务的数据ETL等,在技术实现上则可采用当前主流的数据仓库工具,如可采用Hive、kettle、Sqoop等工具进行数据仓库的搭建、数据ETL以及数据迁移。数据采集与数据仓库层如图2所示。
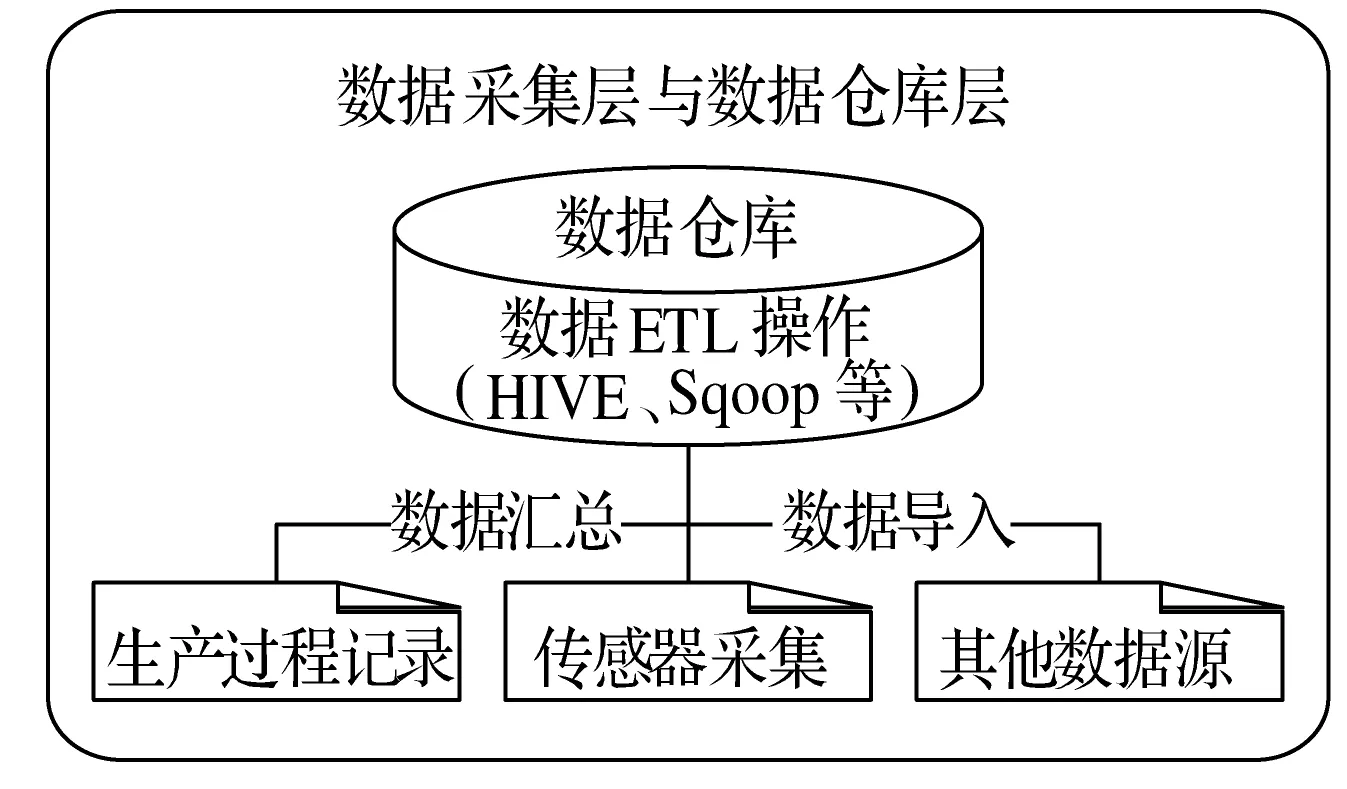
图2 数据采集与数据仓库层
2.2 海量数据分析处理层
对于制造物联中的数据分析处理系统来说,海量制造数据的分析处理模块构成其系统核心,并且主要的数据业务操作也在该模块中进行实现。
依据制造物联中不同制造企业的数据特性以及处理要求,在海量数据分析处理层会采用高可用性、可拓展的分布式大数据处理集群来作为其硬件实现,集群的具体规模依据不同制造企业的数据处理需求进行扩充或缩减。对于集群的基础性软件配置则采用当前主流的大数据处理框架及相关技术软件,如Hadoop、Spark等大数据处理框架,Zookeeper、Yarn等资源管理软件以及资源流任务调度如Oozie、Kettle等调度框架。
特别地,对于当前制造业中存在的离散工业生产数据来说,其数据往往具有流式的数据特性,并且在其数据处理要求上往往要求数据处理具有实时性。对于以上的数据处理要求和业务场景在技术工具选型上则采用如Storm、Spark-Streaming等流式数据处理工具进行实现。而对于需要进行制造数据的深层挖掘分析时,如需要进一步挖掘分析制造数据中的隐藏信息时,则需要有选择地采用数据挖掘、机器学习等高级数据分析方法进行更高层次的数据分析处理。
对于在该层中进行处理分析完成后的数据会转存到中间结果存储层中进行数据的持久化。该层的层次划分以及模块组织如图3所示。

图3 数据分析处理层
至此,可以看出,针对制造物联中制造业企业的数据分析处理要求,特别是依据诸如数据量、数据特性、不同制造企业的数据业务需求进行可伸缩的集群弹性配置和灵活的数据分析处理工具选择、可以使得本文系统具有高弹性、高可用性以及强大的适用性。
2.3 中间结果存储层
当数据在数据分析处理层中完成针对数据业务的分析处理后,需要进行数据结果的持久化存储以及处理结果的可视化展示。在本文的系统中以上步骤在中间结果存储层中进行数据的保存。
一般地,结果数据的存储和持久化的主要目的可分为:1) 作为数据结果展示层的数据源;2) 作为二次数据分析处理的数据源。针对以上两种中间数据结果存储要求,该层采用企业级搜索引擎和数据库来作为数据存储,其中数据库的选择会依据数据量以及具体的业务要求灵活地选用关系型数据库或非关系型数据库。
特别地,当数据结果需要作为结果展示层的数据源时,为了在数据展示时数据获取的简便,中间结果的存储会直接从数据分析处理层中导入到当前主流的企业搜索引擎如ElasticSearch、Lucence中或关系型数据库如MySQL中。而当数据作为二次数据分析处理的数据源时,数据的存储一般会采用直接文件存储或存储在Hbase等NoSQL数据库中。
对于中间数据的导出以及在中间结果层的存储,则可以采用与数据分析处理层兼容的数据迁移工具或技术。如当采用Spark或Hadoop工具在数据分析处理完成后继续进行数据写入到中间结果存储层的搜索引擎或数据库中。该层的详细设计如图4所示。

图4 中间结果存储层
2.4 前端可视化层
对于制造物联中数据的处理分析结果,其最终会依数据可视化的方式进行结果的最终展示,并以数据的处理分析结果作为可视化层的数据源。
通常地,数据的可视化会依据不同的制造企业业务需求或者不同的展示方式需求进行灵活的可视化方案选择。当前主流的可视化方式为采用B/S或C/S架构的技术方案。对于采用B/S架构时,Web后台可选用当前使用广泛的Spring MVC、Django等,前端框架可采用BootStrap或前端开发语言CSS、JS等进行灵活的前端数据可视化展示。特别地,对于制造企业来说,数据分析报表的生成和汇总是必不可少的业务需求。因此,数据分析报表的制作与导出将在数据可视化层中进行功能实现,该层的详细设计如图5所示。

图5 前端可视化层
3 系统应用与分析
现针对某汽车零配件生产企业中以生产数据为数据源时所面对的产品质量分析对比需求,构建与实现本文中的数据分析处理系统。该企业中生产质量数据的数据源来自RFID数据采集点(2 400/个),采集频率为2 000(条/个/天),采集周期会依据生产任务不同持续数月到一年左右。
本文中选取30 GB所采集的产品质量数据进行系统测试。在该场景中数据分析处理要求包括:生产质量采集数据与质量标准数据对比,分析给出产品质量合格信息,其中分析粒度分别为工序处理信息、任务出来信息以及型号处理信息,并需出具数据处理报表和Web端图表可视化结果。
对于该应用场景,针对该制作企业的实际数据分析处理业务需求,现给各层模块阐述和相应的技术描述。
对于本案例中的数据采集层与数据仓库层,会接入该企业的RFID数据采集系统进行数据的汇总,并且采用Hive、Kettle等大数据工具进行企业的数据仓库构建。其中数据仓库中数据维度包括:设备维、物料维、生产周期维(时间维)、产品维、人员信息维。而对原始数据的ETL等数据清洗处理操作则将产品生产数据作为重点数据操作对象;接着,构建上高可用性大数据集群上的核心数据分析处理层会从数据仓库层中进行原始数据的读取,并采用以Spark、Hadoop为核心的大数据处理框架进行业务的数据分析处理。在本案例中则会采用Spark进行产品质量数据与标准数据的对比操作,并将结果写入中间结果存储层的Hbase数据库,以及搜索引擎ElasticSearch中。随后,基于Spring MVC以及BootStrap前端框架的前端展示层会从中间结果存储层的搜索引擎ElasticSearch中读取最终处理结果数据,并进行Web形式的结果展示以及相应的报表导出。
其中测试系统的软硬件系统配置摘要如下:集群硬件配置为单机32 GB内存,1 TB硬盘共三台。核心软件配置摘要为:Ubuntu12.4, Hive1.x, CDH4.X,spark1.5,ElasticSearch2.x MySQL5.X。最终采用B/S结构的可视化展示方法,通过Spring Web框架进行最终结果展示。其Web端处理分析结果部分摘要分别如图6和图7所示。

图7 生产任务检测信息
图6表示由任务批次、生产工序和工序相应的检验项目所确定的工序工艺要求检测结果。在完成本系统中的数据分析处理后,能够检验该产品在相应工序下是否满足生产标准,并且出具相应的检测值方差和标准差等信息。图7为汇总该生产批次下某项任务的批次检测结果,能够出具不合格工序和未检测任务以及检测合格任务等信息。
对于本文中的数据分析系统,可以实现在产品生产过程中数据周期化、自动化的检测分析。在该企业中固定的产品数据检测分析时间区间为3天,即以三天为周期运行该系统,并依据系统分析处理结果进行产品质量问题的监测和追溯。该系统的高可用性以及所依赖的计算集群的可拓展性可以在短时间内给出产品的质量分析结果相对企业有的人工质量分析处理分析方式,在保证准确性的同时,极大地节省了处理时间。在本文中测试环境下,系统处理时间与数据量关系趋势可参见图8。
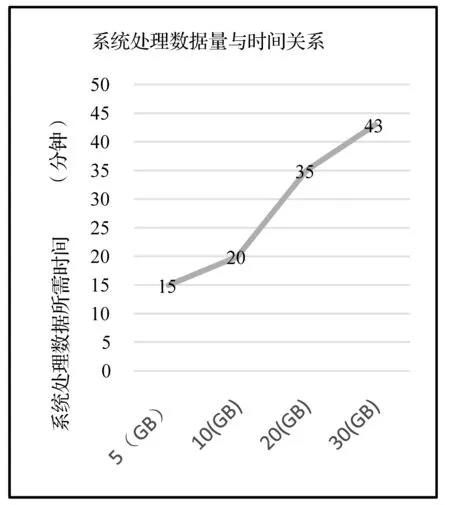
图8 该系统处理数据时间与数据量关系趋势图(不同系统软硬件配置下时间会有差异)
4 结 语
本文针对制造物联领域中的海量数据分析处理问题,设计与实现了一种以分布式大数据集群为基础的海量实时数据分析处理系统。该系统采用分层的系统架构和模块化的软件设计使得该系统具有松耦合、高容错以及适用性强的特点。特别地,该系统针对制造物联中制造业企业中数据多源、结构复杂、数据处理业务复杂的的特点,进行了各模块与层次的针对性设计,如在数据仓库中添加了具有针对性的数据维度设计,在数据核心分析处理层中采用可伸缩性的数据处理集群构建使得本系统可以灵活地应对数据量的伸缩以及数据处理业务的变化。
此外,该系统在某企业实际应用中的效果表明,依赖于该系统可实现海量工业数据的准确快速的分析处理,极大地节省企业中数据处理分析的时间和精力。文中提出的数据分析处理系统默认为在企业内网中运行,因此,并没有考虑系统的安全性和用户隐私保护,而对于当下日益恶劣的工业网络安全环境来说,系统的安全性和稳定性显然是今后需要研究和着重关注的研究点。
[1] 侯瑞春, 丁香乾, 陶冶,等. 制造物联及相关技术架构研究[J]. 计算机集成制造系统, 2014, 20(1):11-20.
[2] 程良伦, 王涛, 肖红,等. 智能制造物联网及应用实例[J]. 高科技与产业化, 2015, 11(3):68-75.
[3] 胡迎新, 马新娜, 郑丽娟. 物联网数据管理研究[J]. 物联网技术, 2014(4):79-82.
[4] Anantharam P, Barnaghi P, Sheth A. Data processing and semantics for advanced internet of things (IoT) applications:modeling, annotation, integration, and perception[C]// International Conference on Web Intelligence, Mining and Semantics. 2013:1-5.
[5] 杨正益. 制造物联海量实时数据处理方法研究[D]. 重庆大学, 2012.
[6] 赵永波, 陈曙东, 管江华,等. 基于海云协同的物联网大数据管理[J]. 集成技术, 2014(3):49-60.
[7] 丁治明, 高需. 面向物联网海量传感器采样数据管理的数据库集群系统框架[J]. 计算机学报, 2012, 35(6):1175-1191.
[8] 何凤成. 面向时空特性物联网数据存储系统设计与实现[D]. 中国科学院大学, 2013.
[9] Zhang Y, Xiang L. Design and implementation of IoT data analysis and processing software[J]. Digital Communication, 2013,40(3):30-33.
[10] Satoh I. MapReduce Processing on IoT Clouds[C]// 2013 IEEE 5th International Conference on Cloud Computing Technology and Science (CloudCom). IEEE Computer Society, 2013:323-330.
[11] 刘文峰, 顾君忠, 林欣,等. 基于Hadoop和Mahout的大数据管理分析系统[J]. 计算机应用与软件, 2015, 32(1):47-50.
[12] Rizwan P, Rajasekharababu M. Performance Improvement of Data Analysis of IoT Applications Using Re-Storm in Big Data Stream Computing Platform[J]. International Journal of Engineering Research in Africa, 2016, 22:141-151.
[13] 邓仲华, 刘伟伟, 陆颖隽. 基于云计算的大数据挖掘内涵及解决方案研究[J]. 情报理论与实践, 2015, 38(7):103-108.
[14] Son J, Ryu H, Yi S, et al. SSFile: A novel column-store for efficient data analysis in Hadoop-based distributed systems[J]. Information Sciences, 2015, 316:68-86.
[15] 何炎祥, 喻涛, 陈彦钊,等. 物联网环境中数据存储与查询机制研究[J]. 计算机科学, 2015, 42(3):185-190.
[16] 史俊茹, 黑敏星, 杨军. 一种物联网数据管理框架研究[J]. 计算机科学, 2015, 42(S1)294-298.
THE DESIGN AND IMPLEMENTATION OF AN ELASTICITY-DISTRIBUTED MASSIVE DATA ANALYSIS SYSTEM IN MANUFACTURING INTERNET OF THINGS
Du Liang Cheng Lianglun
(SchoolofComputerScienceandTechnology,GuangdongUniversityofTechnology,Guangzhou510006,Guangdong,China)
For the massive, multi-source and complex structure data in the manufacturing Internet of things, it has the characteristics of large amount, easy to accumulate, difficult to analyze and process as well as difficult to visualize. In view of the above problems, an elasticity-distributed massive data analysis system is designed and implemented with the core of massive data computing framework, adopting the system design of modularization and layering to make the system can be very good to deal with massive data analysis problem in the industrial internet of things, besides it has the following advantages: module division is clear, easy expansibility and fault tolerance. The practical application shows that the system works well when analyzing the massive data in manufacturing Internet of things.
Manufacturing Internet of things Mass data processing Distributed Data analysis system
2016-06-13。杜量,硕士生,主研领域:数据挖掘,软件工程。程良伦,教授。
TP274
A
10.3969/j.issn.1000-386x.2017.07.012
