互联网藏文信息舆情分析系统设计*
2017-07-31安见才让拉毛措孙琦龙
安见才让,拉毛措,孙琦龙
(1.青海民族大学计算机学院,西宁810007;2.西藏大学藏文信息技术研究中心,拉萨850000)
互联网藏文信息舆情分析系统设计*
安见才让1,拉毛措2,孙琦龙1
(1.青海民族大学计算机学院,西宁810007;2.西藏大学藏文信息技术研究中心,拉萨850000)
信息传播技术的快速发展推动了藏文信息的迅速传播,舆情分析越来越受到人们的关注。介绍了研究互联网藏文信息舆情分析的必要性、重点及难点,详细介绍了藏文舆情分析的关键技术,最后,说明了藏文舆情分析系统的设计和实现框架。
藏文信息;舆情分析;文本分类;藏文情感倾向性;数据挖掘;主题识别
1 引言
随着互联网的迅速发展和普及,互联网为依托的藏文信息也已深入人们的日常生活。互联网上言论自由达到新高度,互联网舆情通过微博、博客、新闻跟贴、转贴、QQ、微信等形式对现实生活中某些热点、焦点问题等进行反应,不论是对国家政策、国内或国际重大事件,还是对企业产品或某些个人都能马上形成网上舆论。这种用互联网来表达观点、传播思想产生舆论压力,达到任何部门、机构都无法忽视的地步。在大数据环境背景下,互联网舆情信息的挖掘较以往的其他媒体更加困难,且更加难以规范。如何识别民众所关注的热点话题并有效地分类,如何判断民众对社会事件的态度是正向还是反向,如何分析和把握社会热点事件的波动性等,是网络舆情研究中亟待解决的重点问题[1],对认识和引导网络舆情具有重要的科学意义。
2 系统关键技术研究
2.1 互联网舆情藏文信息采集
采集网络舆情藏文信息的方法是通过各种不同功能的采集器,即网络爬虫(Crawler)自动在互联网上爬取网页。根据信息采集器的采集方式,可以把采集器分为两种类型:增量式数据采集和基于主题的网络数据采集[2]。基于主题的Web信息采集方式则根据用户首先定制的某类主题内容,有选择地爬取,自动识别并将与主题相关的有藏文信息的链接放入待爬取的URL队列,过滤与主题无关的链接。基于主题的Web藏文信息采集由聚焦爬虫实现,需要完成以下任务:识别藏文web网页;定义主题;决定待爬行的URL次序;判断页面与主题相关度;提高爬虫的覆盖。
主题识别判断模块的作用是对所下载的网页首先进行页面解析,然后进行主题相关性判断,包括当前网页及其链接网页的主题相关性。主题相关性的判别一般有两种方式,一种是根据与主题相关的关键词来判别,另一种是先标注相关领域的训练文本,然后通过文本分类的方法判断页面的主题是否和事先标注的文本类别一致,完成网页主题相关性判断。如果判断结果是属于此次舆情挖掘的有效页面,则下载这些网页并进行网页去重、提取URL和URL去重等操作,最后以文本形式保存至舆情数据库[3]。
2.2 基于Fi sher判别的特征提取方法
将Fisher判别准则应用到藏文文本分类中,用于分类特征的选择。所选择的特征t应使得它同时在不同类别中的差别尽可能大。而在相同类别中的频率差别尽可能小。于是定义
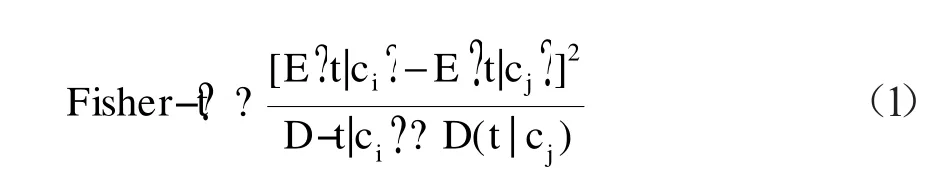
为特征t的关于类别ci和cj的Fisher准则,其中E(t|ci)、E(t|cj)、D(t|ci)、D(t|cj)分别表示特征t对类别ci、cj的条件均值和条件方差[4]。
(E t|c −E t|c )是特征t在两类文本中平均出现的强度之差,它反映了t出现的类间差,称为t的类间离散度。类间离散度越大说明t的分类能力越强。?D ? t |ci?−D(t|cj)表示了特征t对ci和cj总类内离散度。类内离散度越小意味着特征t的文本表达能力越强。可用频数来近似(1)中的均值和方差,求出每个特征t对不同类别的Fisher准则。
2.3 主题识别的算法
朴素贝叶斯分类方法(NB)是一种简单又非常有效的文本分类方法[5],应用十分普遍,经常作为分类评判的基准。NB方法遵循贝叶斯假设:文档的特征之间是相互独立的。这个假设一方面使得NB计算简单,但另一方面忽略了特征之间的上下文联系。
设d为一任意文档,它属于文档类C={c1,c2,…,ck)中的某一类ci,分类器的参数由先验类概率值p(ci)和基于类特征的条件概率p(tk│ci)组成,由已标注的训练集文档计算研究。每个类ci的先验类概率值p(ci)的计算公式:
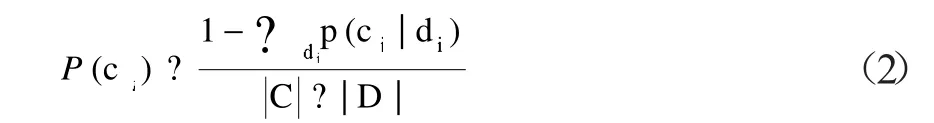
其中,|C|是类别数,|D|为训练集中的文档数。p(tk|ci)由式(3)估计
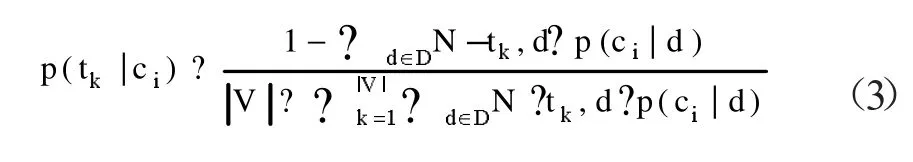
上式中,N tk,d ?表示在文档d中特征项出现的次数;|V|代表文档集合中全部不同的特征项数目。若文档 d属于类别 ci时,p ( c |d) 1,否则,p ( c |d) ?0。
利用已经训练好的分类器,对测试集中的文档进行分类。用 ?td,k表示文本d中的第k个特征项,则我们可以求出文本d属于类别ci的后验概率。
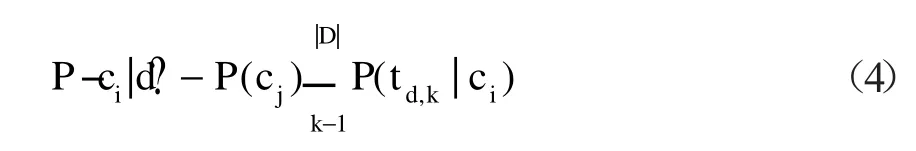
按照公式(4)计算所有文档类在给定文档d下的概率,概率值最大的类就为d所在的类,即贝叶斯分类法则为:
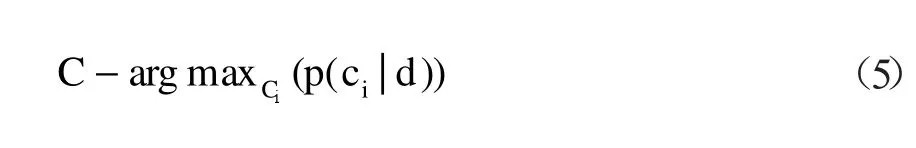
2.4 基于最大熵分类器的藏文文本情感倾向性分类方法
最大熵方法(Maximum Entropy)是一种有监督的学习算法[6],它的基本思想是在只获得关于未知分布的部分知识时,应该选取符合这些知识且熵最大的概率分布模型。因为符合已知知识的概率分布可能不止一个,而熵是表示随机变量不确定性的信息量,计算使熵最大化的概率分布就是对满足已知条件的最不确定的推断。和贝叶斯分类器不同的是,最大熵方法并不假设特征词之间相互无关。利用最大熵分类器,将客观性文本和主观性文本分开,它把训练集中与分类有关的数据表达为一系列的特征,这些特征一般情况下是二值函数。对于情感分类问题,以“特征词一类别”模式作为一个特征。
通常,最大熵分类器利用最大熵模型将文档d的类别指定为c,以使得(6)最大:
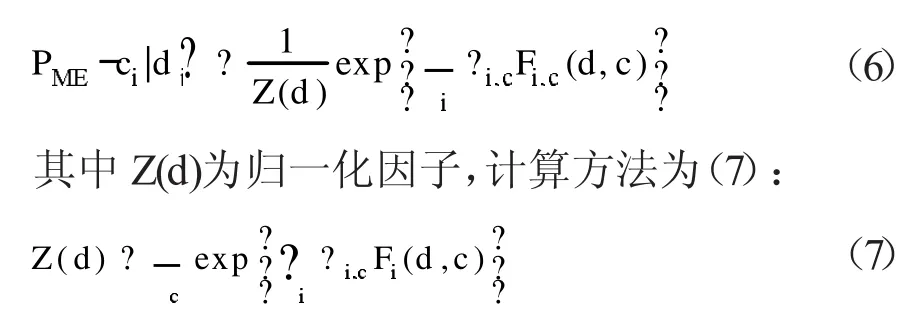
Fi,c(d,c)为二值函数,用输出0或1值来表示样本是否包含某个特征,?i,c为特征函数的权值,?i,c越大则该特征对于类别c的重要度越高。通过在训练集上的机器学习,使用IIS(Improved Irerative Scaling)算法得到? ?i,c的值,从而找到与样本数据分布最接近的概率模型:最大熵模型的构造。在独立假设条件不满足的情况下,最大熵比朴素贝叶斯的分类效果好。
对特定的语气词,用最大熵模型可识别出其情感对象。具体算法:①求每个候选情感对象与意见表达之间的语义路径;②选出全部可能的候选情感对象集{h1,h2…,hn};③通过求条件概率P(hI{h1,h2…,hn})来选出可能性最大的候选情感对象,P(hI{{h1,h2…,hn}通过K个特征函数(8)计算得到:
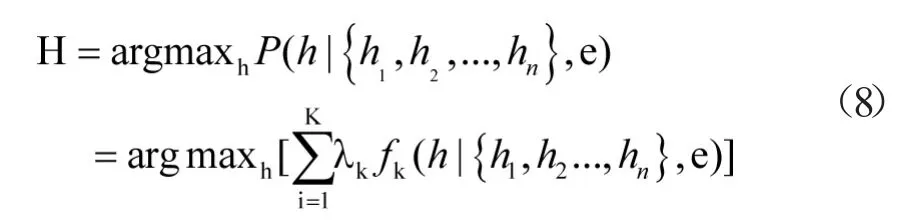
3 系统设计与实现
在系统设计与开发过程中,需建立若干知识库,并要使用垂直搜索、知识发现、藏文网页识别、主题网页识别、自动分词、特征提取、藏文情感网页自动分类等技术,实现对海量互联网藏文信息进行监测、互联网舆情的自动分析和发现。该系统实现的首要任务是要采集围绕主题的海量数据,并经过处理形成规范性的藏文数据再进行挖掘,输出有用的决策信息,系统结构图如图1所示。
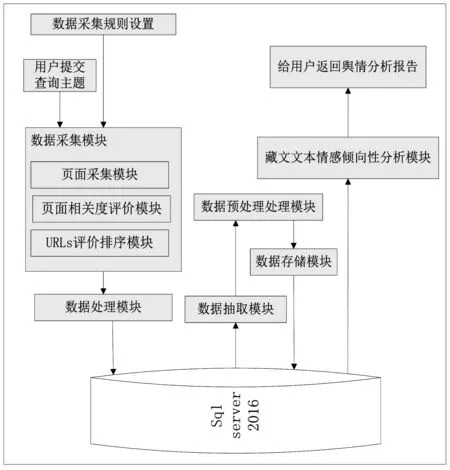
图1 互联网藏文信息的舆情分析系统框架图
3.1 互联网藏文数据采集模块
进行互联网舆情分析的前提是获取基于设定的主题、数量足够多的、完整的互联网[7]藏文数据。为解决这个问题,系统建设时考虑通过建立数据采集规则来达到此目的。在数据采集规则中主要考虑要采集的主题、要搜索的范围、采集要到达的数据量等。在规则制定后,信息采集模块利用“基于主题的互联网爬虫”技术,按照已经设置的采集规则,到互联网上进行数据采集。该模块有三个子模块:页面采集模块、页面相关度评价模块和URLs评价排序模块。数据采集后按照主题归于相应的数据库中,以便下一步的数据处理。
3.2 藏文数据处理模块
需要把采集数据转为有用的信息,在采集到相关数据后,先期对已经采集完成的数据进行格式化、数据清洗、信息处理加工等步骤,最终形成规范的、适于统计的数据。然后再利用数据挖掘技术对数据进行挖掘,形成相应的统计信息,便于查询输出。
3.3 原始数据预处理
在数据挖掘分析前对数据进行预处理,形成最终有效的待分析数据。首先是继续格式化数据,利用数据格式化实现对各种网页格式的数据进行模式化解析,形成系统统一的数据格式;然后进行数据清洗,把“脏”的“洗掉”。该处理步骤主要把不完整的数据、错误的数据、重复的数据等不规范的数据进行清洗,去除无效、重复的数据,形成数量足够、时间段连续、内容围绕主题的数据,为下一步的深度挖掘做准备。
经过预处理的数据还只是数据,并没有形成与主题相关的有用信息,所以系统内置了多种数据挖掘技术。针对藏文信息的分析与处理,系统中的藏文自动分词和词性标注子模块以词典、规则和统计为基础,对采集的藏文数据进分词和词性标注,在此基础上获取词频、词性、位置信息等关键信息[8]。
3.4 藏文数据存储模块
考察目前已经成熟的数据库管理系统,发现Sql server 2016是最合适的。所以本系统就采用Sql server 2016作为数据存储的数据库系统。互联网舆情藏文数据量不是太多,但为了提高查询速度和将来的系统扩展,系统通过Sql server 2016全文索引技术和多维查询技术,对存储在数据仓库中的数据建立合理的索引,使数据查询和输出速度及准确性得到提高,特别是对重要特征字进行检索时能提高查询速度。
3.5 藏文数据的情感倾向性分析处理模块
为解决藏文文本情感倾向性自动分类的难题,系统内置自动分类组件,采用基于Fisher判别的特征提取方法对训练库进行学习,获取每个分类的特征,然后采用基于最大熵分类器方法,对未知分类情况的数据进行情感性倾向性分类。系统通过关联分析、趋势分析,从藏文数据中抽取关联规则。同时,利用趋势分析技术,分析互联网舆论等随时间的发展趋势情况,以便实现对舆论环境的监测和不良倾向的预警。
3.5 友好的数据显示界面
对于输出的技术要求, 在数据输出时系统利用Sql Server2016的Olap技术结合系统提供的查询页面框架,可以实现用户从多个角度对各类数据的查询。针对输出内容,系统内置了生成部分图文并茂的统计报表组件。
4 结束语
介绍了研究互联网藏文信息舆情分析的必要性、重点及难点,详细介绍了藏文舆情分析的关键技术,最后说明了藏文舆情分析系统的设计框架。
[1]王兰成.网络舆情分析技术[M].北京:国防工业出版社,2014. Wang Lancheng.Analysis Techniques on Internet Public Opinion[M].Beijing:National Defense IndustryPress,2014.
[2]万源.基于语义统计分析的网络舆情挖掘技术研究[D].武汉:武汉理工大学,2012. Wan yuan.Research on Mining of Internet Public Opinion Based on Semantic and Statistic Analysis[D].Wuhan:Wuhan UniversityofTechnology,2012.
[3]黄微,张耀之,李瑞.网络舆情信息语义识别关键技术分析[J].图书情报工作,2015,59(21):33-36. Huang Wei,Zhang Yaozhi,Li Rui.Analysis on Key Technologies of Semantic Recognition of Network Public Opinion
[5]何柳,陈勇,吴斌,等.PCI/PCI-E高速实时DMA传输驱动设计[J].电子技术应用,2012,38(11):143-145. He Liu,Chen Yong,Wu Bin,et al.Design a high speed and real time PCI/PCI-E DMA transmission driver[J].Application ofElectronic Technique,2012,38(11):143-145.
[6]邹晨.FPGA设计中跨时钟域信号同步方法[J].航空计算技术,2014,44(4):131-134. Zou Chen.Method of signal synchronization of cross-clock domain in design ofFPGA[J].Aeronautical ComputingTechnique,2014,44(4):131-134.
[7]PLX Technology,Inc.PLX SDK User Manual(Version 7.20) [EB/OL].(2015-01-09)[2016-01-18]http://www.avagotech.com/products/pcie-switches-bridges/software-dev-kit
[8]Zhyang.PCI DTK V2.0 User Manual[EB/OL].(2011-08-26)[2016-01-18]http://wenku.baidu.com/view/8533ca 8283 d049649b66582c.html
[9]Mark S.Qt高级编程[M].吴迪,戚彬,高波,等译.北京:电子工业出版社,2011. Mark S.Advanced Qt Programming[M].Translated by Wu Di,Qi Bin,GaoBo,et al.Beijing:Publishing House ofElectronics Industry,2011. [J].Libraryand Information Service,2015,59(21):33-36.
[4]周志华.机器学习[M].北京:清华大学出版社,2014. Zhou Zhihua.MACHINE LEARNING[M].Beijing:Tsinghua UniversityPress,2014.
[5]李岩.基于深度学习的短文本分析与计算方法研究[D].北京:北京科技大学,2016. Li Yan.Research on Analysis and Computation Methods for Short Text with Deep Learning[D].Beijing:UniversityofScience and TechnologyBeijing,2016.
[6]黄仁,张卫.基于word2vec的互联网商品评论情感倾向研究[J].计算机科学:2016,43(6A):387-389. Huang Ren,Zhang Wei.Study on Sentiment Nalyzing of Internet Commodities ReviewBased on Word2vec[J].Computer Science:2016,43(6A):387-389.
[7][美]丹尼尔·里夫,[美]斯蒂文·赖斯,[美]弗雷德里克·G.菲克著,嵇美云,译.内容分析法:媒介信息量化研究技巧[M].北京:清华大学出版,2010:78-98. Riffe D,Lacy S,Fico F G.Analyzing Media Messages Using Quantitative Content Analysis in Reearch[M].Beijing: Tsinghua UniversityPress,2010:78-98.
[8]安见才让.藏文搜索引擎系统中网页自动摘要的研究[J].微处理机,2010(5):77-80. An Jiancairang.Research on Automatic Abstract of Web Document Summarization of Tibetan Search Engine[J]. MICROPROCESSORS,2010(5):77-80.
Design of Internet Public opinion Analysis System of Tibetan Information
An Jiancairang1,La Maocuo2,Sun Qilong1
(1.Computer Department,Qinghai University for Nationalities,xining 810007,China;(2.Research Center of Tibet Information Technology of University of Tibet,Lhasa 850000,China)
The rapid development of information technology promotes the rapid dissemination of Tibetan information and people pay more and more attention on public opinion.This paper introduces the necessity,the importance and the difficulties of researching internet public opinion analysis of Tibetan information,as well as the key technologies and the design framework.
Tibetan information;Public opinion analysis;Text classification;Tibetan text sentiment;Data mining;Topic recognition
10.3969/j.issn.1002-2279.2017.02.013
TP391
A
1002-2279-(2017)02-0056-03
国家民委(14QHZ003)和青海省科技厅(2016-ZJ-Y04)项目资助
安见才让(1969-),男(藏族),青海省西宁市人,教授,硕士研究生,主研方向:自然语言信息处理。
2016-12-01
