融合用户相似度与信任度的协同过滤推荐算法
2017-07-12蒋宗礼李慧
蒋宗礼+李慧

摘要:传统的协同过滤算法难以解决“稀疏性”和“冷启动”等问题。鉴于此,提出一种融合用户相似度和信任度的方法。首先根据用户对共同项目的评分创建初始信任度,通过信任关系的传递规则,建立没有直接信任关系的用户之间的信任关系,然后融合用户相似度与信任度,用于传统的协同过滤推荐系统,找出用户的最近邻居集,进行项目的评分预测,从而产生推荐列表。实验表明,改进后的算法能有效提高系统推荐的准确性。
关键词:协同过滤;推荐系统;信任度;用户相似度
DOIDOI:10.11907/rjdk.162798
中图分类号:TP312
文献标识码:A 文章编号:1672-7800(2017)006-0028-04
0 引言
随着互联网的迅猛发展,信息过载问题越发严重。为了缓解该问题,在海量信息中找到真正所需的信息,Goldberg等[1]在1992年首次提出了协同过滤推荐算法。该算法利用用户对项目的评分记录,计算与目标用户有着相似兴趣爱好的最近邻居用户集,并根据该邻居集对目标项目的评分情况,计算目标用户对目标项目的预测评分值,最终把N个最高预测评分值的项目推荐给目标用户。协同过滤推荐算法简单高效,已经成为目前最流行的个性化推荐算法之一。然而,随着系统规模的扩大,协同过滤算法会出现数据稀疏性(Data Sparsity)、冷启动(Cold Start)、可扩展性等问题,使得协同过滤算法容易受到这些问题的困扰[2]。
针对稀疏性问题,Sarwar等[3]提出使用矩阵奇异值分解的方法对评分矩阵进行降维以减少稀疏性。邓爱林等[4]提出首先根据基于项目的协同过滤算法预测部分项目评分,减少评分稀疏性,再根据基于用户的协同过滤算法为用户推荐。Herlocker等[5]将信任引入商品推荐系统中,该系统通过维护用户对其他用户的信任或不信任列表来建立用户间的信任关系,基于信任的推荐系统认为用户会倾向于采取受信任的身边用户的建议,目前,基于信任的推荐系统已经得到了广泛研究与应用。经过验证,融合信任的推荐算法可以取得比传统协同过滤算法更好的效果,尤其是在缓解用户“冷启动”和数据“稀疏性”等方面[6-7]。
周林轲[8]提出无需用户主动地给出对其他用户的信任评分,而是通过挖掘用户间的社交信息从而预测出用户的信任度。Victor P等[9]则利用信任网络特征计算信任度,并构建基于信任的推荐系统。林韶娟等[10]提出使用GenTrust算法,利用二值的信任网络来预测扩展信任网络, 提高了算法准确率。
还有一些学者利用信任传播的方法计算信任度,也起到了改善数据稀疏性的作用。文献[11]提出了一种基于信任传播的加权平均方法计算信任度。文献[12]则是利用信任传播过程中信任值的衰减,设计了3种信任度计算方法。
本文提出信任度的构建方法是基于用户共同评论的项目,而不依赖用户主动给出对其他用户的信任评分。有共同评论项目的用户之间可以直接计算出信任值,没有共同评论项目的用户之间虽然不存在直接信任关系,但是可以通过信任的传递,间接地建立信任关系,而间接信任关系的建立在一定程度上解决了数据稀疏问题。最后将用户信任度与相似度结合起来,引入到传统的协同过滤推荐系统中,找出用户的最近邻居集,进行项目的评分预测,从而产生推荐列表。实验表明,本文提出的相似度与信任度相融合的方式能有效地提高系统推荐的准确性。
1 相似度计算
1.1 用户模型建立
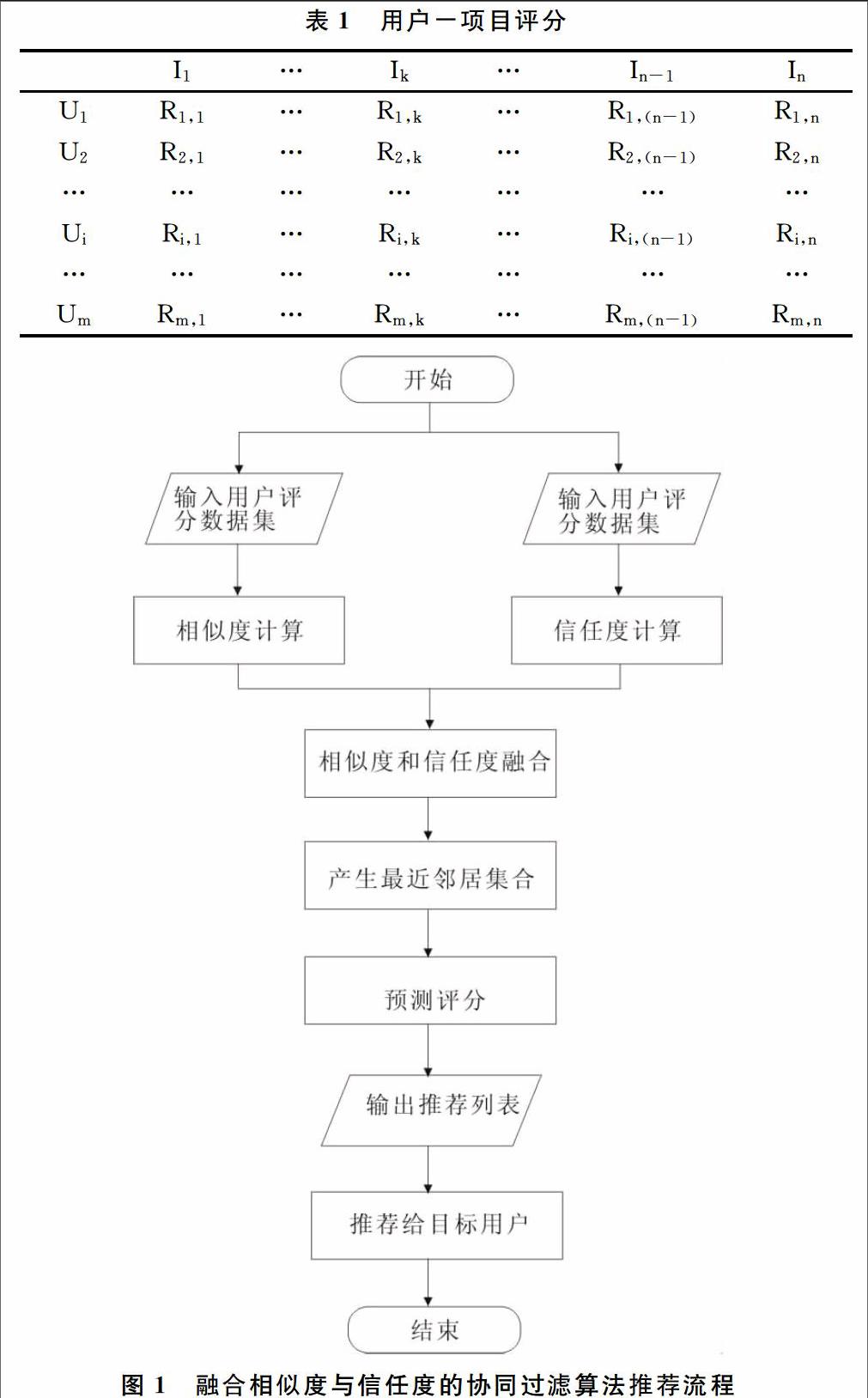
协同过滤推荐算法的根本出发点是任意用户的兴趣不是孤立存在的,也即假如两个用户对一些项目的评价比较相似,那么他们对其它项目的评价也会比较相似。因此,协同过滤推荐算法的核心是计算用户之间的相似度,根据相似度找出最近邻居集,通过他们对项目的评分,预测评分较高的项目并推荐给用户。可以用一个m*n的用户-项目评分矩阵A来对用户相似度进行建模。如表1所示,矩阵A中的m行代表m个用户,n列代表n个项目,第i行第j列元素Ri,j表示第i个用户对第j个项目的评分(如果用户对项目没有进行评分,则Ri,j=0)。
计算得到用户对项目的预测评分值后,将预测的评分值从大到小排序,将评分值大于指定阈值或前N个评分最高的项目推荐给目标用户。
融合相似度与信任度的协同过滤推荐算法的推荐过程如图1所示。
4 实验
本文提出了融合相似度与信任度的协同过滤算法,为了证明本方法的有效性,做了一系列实验,其中也包括对传统基于相似度的协同过滤算法相关实验。
4.1 数据集选取
本文所有實验均在公开的MovieLens数据集上进行,该数据集包含了943位用户对1 682部电影的100 000条评分记录,每个用户至少有20条评分记录。评分有5个等级,用1~5的整数表示,数值越大表示用户对该电影的喜爱程度越高。
将整个MovieLens数据集进一步划分为训练集和测试集。为此,引入变量x作为测试集占整个数据集的百分比。本文选用x=0.2,即在整个数据集中,训练集占80%,测试集占20%,即训练集为100 000*80%=80 000条数据,测试集为100 000*20%=20 000条数据。
4.2 评价标准
本文采用度量标准平均绝对误差( MAE) 作为评价标准来评价推荐系统的推荐效果。在推荐算法研究中,MAE是最常用也是应用最广泛的评价指标。MAE的基本思想是计算系统对项目的预测评分与用户对项目的实际评分之间的平均绝对偏差,MAE值越小表示推荐系统的推荐精度越高。MAE的计算公式如下所示:
4.3 结果分析
在计算信任度矩阵时,λ值的选取以及信任传递的深度MPD会影响整个信任矩阵的计算,因此针对这两个重要参数进行了实验,找出最佳的参数组合,利用参数组合对各种不同的推荐方案进行实验比较。
首先,对λ的取值进行实验,实验结果如图2所示。
图3中的Sim&Trust表示将相似度与信任度相结合的推荐方案,Trust表示只利用信任度的推荐方案。实验结果是在MPD=2,最近邻居数量为20的前提下所得出。从实验结果中可以看到,当λ值在0~0.1时,推荐方案的MAE值比较稳定,在0.05时,Sim&Trust推荐方案取得最小值,大于0.1后MAE有上升趋势。因此,可以认为0.05对于系统而言是一个比较好的参数,在后面的推荐系统对比实验中,也是将λ值设置为0.05。
确定λ的取值之后,对信任传递深度进行实验,实验结果如图3所示。
实验中一共设置了5组对比实验,实验结果是在λ=0,最近邻居数量为20的前提下所得出。
当信任传递的深度小于3时,随着MPD的增加,MAE的值逐渐减小,当超过3之后趋于平稳,考虑到算法的复杂度和运行时间,认为MPD取值为3比较合适。
当决定信任度矩阵的λ和信任度最大传播深度MPD的值确定后,对传统协同过滤算法的3种计算相似度的方法以及基于信任度的协同过滤算法中只有信任度和信任度与相似度相结合的方法进行实验比较。实验结果如图4所示。
从图4可以看出,本文提出的相似度与信任度相融合的方法在MAE表现来看,其效果优于传统推荐方案。从邻居数量的选取对MAE的影响来看,随着邻居数量的增加,除Pearson外,所有推荐系统都会有性能上的提升。从现实意义上讲,给你提建议的人越多,你值得信任的人就可能越多,综合给出的推荐效果就会越好。但并不是邻居越多越好,到达一定程度,对实验结果的影响就会越来越不明显。如图4所示,当最近邻居的数量超过100之后,MAE的值趋于稳定,那是因为邻居到达一定程度后,新扩展的邻居与目标用户相关性太低,以至于无法产生影响。
5 结语
融合用户相似度和信任度的方法选择余弦相似度和Jaccard相似度相结合的方式计算用户间的相似度,在计算用户信任度时分为直接信任度和间接信任度。之后将信任度和相似度融合,通过融合后的用户相关度找出与某用户相关性最强的用户群作为该用户的邻居集,用于传统的协同过滤推荐系统中,找出用户的最近邻居集,进行项目的评分预测。实验表明,改进后的算法能有效提高系统推荐的准确性。鉴于相同地区相似年龄的同性人群对事物的观点可能类似的假设,下一步的工作是,将用户的个人信息加入到相似度的构建之中,希望可以进一步提高推荐系统的准确性。
参考文献:
[1]D GOLDBERG,D NICHOLS,D TERRY.Using collaborative filtering to weave an information tapestry[C].Communications of the ACM,1992.
[2]范永全,杜亚军.一种融合用户偏好与信任度的增强协同过滤推荐方法[J].西华大学学报,2015,34(4):8-12.
[3]B SARWAR,G KARYPIS,J KONSTAN.Item-based collaborative filtering recommendation algorithms[C].In Proceedings of the 10th International Conference on World Wide Web,New York,USA,2001:285-295.
[4]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[C].软件学报,2003,14(9):1621-1628.
[5]MASSA P,AVESANI P.Trust metrics in recommender systems[M].Computing with Social Trust.London:Springer,2009:259-285.
[6]U SHARDANAND,P MAES.Social information filtering: algorithms for auto mating "word of mouth"[C].in Proceedings of the SIGCHI Conference on Human Factors in Computing Systems,Denver,Colorado,USA,1995:210-217.
[7]D GOLDBERG,D NICHOLS,D TERRY.Using collaborative filtering to weave an information tapestry[C].Communications of the ACM,1992.
[8] 周林轲.电子商务中基于信任的推荐算法研究[D].长沙:湖南大学,2011.
[9]VICTOR P,CORNELIS C,TEREDESAI A M,et al.Whom should I trust? the impact of key figures on cold start recommendations[C].Proceedings of the 2008 ACM Symposium on Applied Computing,2008:2014-2018.
[10]林韶娟,陶晓鹏.基于二值信任网络的推荐算法改进[J].计算机应用与软件,2012,29(12):157-160.
[11]CHAKRABORTY P S,KARFORM S.Designing trust propagation algorithms based on simple multiplicative strategy for social networks[J].Procedia Technology,2012:534-539.
[12]SCHAFER J B,KONSTAN J A,RIED J.E-commerce recommendation applications[J].DataMining and Konwledge Discovery,2001,5(1-2):115-153.
(責任编辑:孙 娟)
