基于卷积网络的句子语义相似性模型*
2017-06-21黄江平姬东鸿
黄江平 姬东鸿
(武汉大学 计算机学院, 湖北 武汉 430072)
基于卷积网络的句子语义相似性模型*
黄江平 姬东鸿
(武汉大学 计算机学院, 湖北 武汉 430072)
句子间语义相似性的计算已成为自然语言处理领域的重要研究内容,如何有效地对句子建立语义模型已成为释义识别、文本相似性计算、问答和文本蕴涵等自然语言处理应用的基础任务.文中提出了一种并行的卷积神经网络模型,该模型的两个卷积网络不仅对句子对中的单个句子建立句子向量表示,还对句子经卷积池化后的特征进行相似性度量,并获得句子间的相似性特征.采用释义识别及文本相似性两项任务进行模型性能的实验评测,结果显示,该模型能够较好地表示句子语义信息,其释义识别F1值相比基准实验提高了7.4个百分点,语义相似性评测的皮尔森相关系数比逻辑回归方法有7.1个百分点的提高.
卷积网络;释义识别;句子模型; 语义相似性
识别句子间的语义相似性已成为自然语言处理领域的重要研究内容,如何有效地对句子建立语义模型已成为问答、释义识别、文本蕴涵和文本分类等自然语言处理应用的基础任务.
为句子建立语义模型的目的就是分析和表示一个句子的语义信息,也是自然语言理解的基础.尽管在建立句子语义模型的过程中,很少仅针对单个句子进行分析,但句子中频繁出现的用于表示句子的词和n-gram却被高度关注,因为句子模型相关的特征函数需要从这些词和n-gram中抽取特征来表示句子[1].
大量基于语义组合的方法已经被用来表示句子的语义信息,在这些组合方法中,主要是把学习的词汇语义向量进行代数操作生成句子向量[2- 3].而通过特定的句法关系[4]和特殊的词汇类型学习组合函数[5]也被用来表示句子的语义内容.尽管这些模型在相应的任务上都取得了较好的效果,但它们都有一个共性就是基于神经网络进行语义组合.利用神经网络进行句子建模有很多优势,例如,可以通过句子中词或者短语的上下文训练得到通用的词或短语的向量表示,也可以通过监督训练得到针对特定任务的神经句子模型,此外还可以用神经句子模型来生成句子表示进行句子分类[6]等.
各种神经句子模型已经被用于句子表示[7],最常见的是神经词袋(NBoW)模型,这类模型包含一个映射层,其映射词、子词及n-gram到高维向量表示,而这些表示又通过诸如求和等操作进行逐个分量的联合,联合的句子向量再通过一个或多个全连接层进行分类.目前用于句子表示的主要有递归神经网络和循环神经网络模型.
递归神经网络(RvNN)是常用来表示句子的一种模型,该模型以依存树结构作为输入,树中每个节点的左右子节点逐层进行联合,每层的权重由树中的所有节点共享,当计算到树的根节点时,输出句子的表示[8- 9].循环神经网络(RNN)作为递归神经网络的一种特殊情况,主要用于语言模型,当其被作为线性结构时也可以用于对句子建模,当这种结构计算到最后一个词时,才能表示整个句子.然而这两种模型最大的不足在于低阶的特征会被直接用于与高阶的特征进行联合,例如当前词会与先前表示的整个从句特征进行组合[10- 11].
文中提出一种基于卷积神经网络的句子语义模型,该模型能够把变长的句子生成多个n-gram低阶特征,再逐层抽取更高阶的特征,避免了RvNN及RNN低阶和高阶特征直接组合的缺陷.把变长的输入句子序列通过多层卷积、池化后,再把得到的高阶特征通过全连接层来表示固定长度的句子语义向量.这样通过在输入句子上进行多重卷积和池化操作可以获得输入句子中各个短语之间的句法和语义关系.这种特征推导类似于一个句法分析树,但又不是完全的句法关系,而是神经网络的内部结构.因此文中提出的模型可以不依赖人工标记的特征并能应用于多种语言的句子语义模型表示.最后在Sem-Eval-2015 Task1的Twitter释义识别及句子语义相似性计算评测任务数据集[12]上对文中提出的模型进行了实验验证.
1 卷积神经网络
采用卷积神经网络的目的就是把句子映射到一个特征向量中.卷积神经网络主要由卷积、非线性函数和池化操作组成.在网络的输入端,首先把输入的词转化为实值的特征向量,既可以采用one-hot方式也可以采用分布式学习的方法来表示这些词向量,但采用分布式词向量可以充分利用大规模未标注语料的语义信息.下面分别对模型中句子矩阵、卷积、池化方式以及激活函数进行介绍.
1.1 句子矩阵

该矩阵中的每一列i代表词嵌入wi在句子中的位置.为了把句子中由词嵌入表示的低阶特征转换为高阶的语义特征,卷积神经网络需要对给定句子矩阵s进行一系列的卷积、非线性变换和池化操作才能得到更高阶的特征表示.
1.2 卷积
这里以一维卷积为例,卷积就是权重向量m=Rm和一个输入序列向量i的操作.向量m是卷积的过滤器,大小为m,文中把s作为一个输入句子,而si∈R是句子中第i个词对应的单个特征值.其一维卷积的实质是求向量m和句子矩阵s中的m-gram之间的点积,并得到一个新的序列c,
(1)



图1 卷积示意图
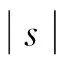

图2 卷积神经网络句子模型
1.3 激活函数
为了让网络学习一个非线性的决策边界,每一个卷积网络层的上面应用了一个非线性的激活函数,该激活函数应用到前一层输出的每一个元素.常见的激活函数有Sigmoid、双曲正切函数Tanh以及ReLU[14],不同的激活函数会影响收敛速率及训练质量.3个激活函数如式(2)-(4)所示.这里x′为输入的变量.
(2)
(3)

(4)
ReLU函数最大的特点就是当x′<0时,ReLU为0,而当x′≥0时,ReLU为输入值x′.由于ReLU通常比Tanh的效果好,且Tanh又优于Sigmoid,因此文中的卷积模型选择ReLU作为激活函数.
1.4 池化
池化的目的是聚集信息并削减表示,常见的池化方式有最小、最大、平均、k-max、动态k-max等几种方式.最大及平均池化操作都是把特征映射矩阵的一行或一个特征区域映射到单个值.平均池化及最大池化均有其不足,在平均池化中,所有的成分均被考虑.这种方式弱化了较强的激活值,对非线性激活函数Tanh影响强烈,因为非常正和负的激活成分会在该函数中相互抵消.尽管最大池化方式没有平均池化方式的缺点,但它会导致训练集的强过拟合,这会在测试数据上有非常差的泛化.
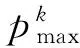
k-max池化操作能够池化序列p中k个最活跃的特征,这些特征可能是与位置分隔的数字,但它保留了特征的阶,尽管不对特定位置敏感,但这种方法能够很好地识别出序列p中高度活跃的特征次数.k-max池化方法常应用于最顶层的卷积层,它保证了到全连接层的输入独立于输入句子长度.
为了能够在卷积网络的中间层平滑地抽取高阶和长范围特征,不适合使用固定的k-max池化操作方式.Kalchbrenner等[1]提出了一种动态k-max池化操作方法,这里的k不是一个固定值,而是句子长度s及网络深度l的函数,则参数k表示如下:
(5)
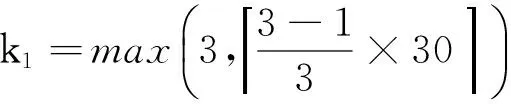
2 语义相似性
给定一个句子对,句子卷积神经网络模型能够并行地计算两个句子的语义表示,一种最直接的方法是把两个句子表示成向量后,利用传统的相似性度量方法计算句子间的相似性.例如用欧氏距离公式(式(6))或余弦公式(式(7))计算相似性:
(6)
(7)
式(6)和(7)中的sx和sy分别表示待计算相似性的两个句子向量,而sxi和syj分别表示sx和sy中的元素.但这些并不是用于计算句子对相似性的最佳方法,因为在进行句子最终的向量表示时,会对生成的二维特征向量进行扁平化表示,不同的扁平化句子表示区域来自下层不同的内容,包括过滤器的宽度、池化的类型等.而扁平化也会丢弃一些有用的用于相似性计算的组合信息.
因此,为了克服语义信息丢失,在文中的语义相似性模型中,考虑了在句子表示过程中的相似性度量.即在文中提出的模型中,不仅采用了先前的句子向量表示,而且还在卷积池化的基础上增加了相似性计算模块.文中提出的模型如图3所示.

图3 句子对相似性模型
文中提出的模型在计算相似性特征表示这一层计算和比较了两个句子在卷积池化后的相似性特征,即相似性特征表示层在句子卷积和池化后比较了两个句子池化后的各个区域块.然而,一个重要的考虑是如何选择这些合适的区域用于相似性比较.虽然有多种用于聚集局部组合区域的方法,但在文中主要考虑了如下3个方面:
(1)是否来自于卷积层相同的窗口大小;
(2)是否来自于下层卷积层相同的过滤器;
(3)是否来自于相同的池化层.
同时,提出的模型不仅计算了两个句子在卷积和池化后的相似性特征,同时保留了传统卷积网络的句子向量表示,这在全连接过程中比He等[15]提出的模型保留了更多的句子语义信息.
由于卷积句子模型针对一个句子采用不同过滤器及池化方法,因此一个句子经过卷积和池化后会产生多个特征映射,如图3中的特征映射.对于一个句子矩阵s,生成特征映射的组块方法如下:
gdef=(Wsm,pool,s)
(8)
式中:Wsm为句子的卷积过滤器的窗口大小;pool为池化类型,pool∈{max,k-max,dk-max};g为生成的特征映射.这里采用了max、k-max及动态k-max(dk-max)3种池化方法.由于对句子进行卷积的特征过滤器采用了不同的类型和窗口大小,这里以filterG表示所有的卷积过滤器的集合,而filterGj表示集合中的第j个过滤器,则在句子经过filterGj后,再经池化后得到输出o[j]:
o[j]=poolt(outFiliterGj)
(9)
式中,outFiliterGj表示句子经过filiterGj的输出,o表示一个经过poolt的各个过滤器向量.由于输出o包含不同的卷积和池化信息,因此文中提出的相似性模型比较了上述3种条件中满足其中至少两种的区域.这里定义比较句子中两个局部区域的方法:
(10)
这里u表示局部区域比较生成的特征,余弦距离按照两个向量之间的角度来度量,而L2欧式距离比较了向量中各个元素之间的不同.
给定两个句子sx和sy,通过设置不同的窗口大小WSm及选择不同的池化类型,生成不同的输出块,这里以ox和oy分别表示句子sx和sy输出块,再经过u(ox,oy)后得到特征fea,对fea进行累加,得到句子ox和oy的结构相似性特征feaxy.经过相似性模型,得到了句子sx和sy的所有相似性特征,feaXY再通过全连接层把特征feaXY及sx和sy的卷积句子向量表示结合起来,形成最终的特征向量feaVec,对于该向量采用log-softmax计算句子对之间的语义相似性分值.
3 实验及分析
3.1 数据集与评估方法
文中采用SemEval-2015 Task 1的数据集进行各项实验.该数据集是由Xu等[12]在2015年提出的一项SemEval评测任务,该任务包含两个子任务:①给定两个推特句子,判断这两个句子是否具有释义,即是否表达了相同或者非常相近的意义;按照常见的释义识别的评测方法,文中采用了准确率、召回率及F1值评估模型的性能;②根据两个推特文本所表达的语义,给定一个介于[0,1]之间的一个数值,用于描述其相似性程度,其中0表示两个句子无关,而1表示语义相同,文中采用皮尔森相关系数来评测模型的语义相似性计算性能.
数据集分为开发集、训练集和测试集3个部分,各个数据集的推特句子数见表1.表中的“释义”表示两个推特句子的语义基本相同,而“非释义”则表示推特句子对表示的语义不同,“争议”则表示两个句子是否有释义关系存在争议.根据任务官方组织推荐,在训练和测试时不采用有争议的句子对.

表1 推特释义语料统计
为了验证模型的性能,对开发集两类关系及多种标注释义类型都进行了评测.在语料释义关系标注中,采用了亚马逊的众包平台,即对于每个句子对有5个人进行是否有释义的判断投票,见表2.

表2 释义与得票数关系
表2括号中的第1个数字是认为句子对具有释义关系的票数,第2个数字是认为句子对不具有释义关系的票数.从表2中可以观察到,具有释义关系的句子对至少需获得3个人的投票,而非释义句子对最多只有一个人认为有释义关系,其余则为争议句子对.
3.2 开发集结果
在现代建筑工程中,电气工程设计的目的是为了满足建筑内部居民的实际需求,因此必须从广大用户的角度出发,将建筑结构和物业管理有机的结合起来。在具体设计过程中,为了保障建筑的各项功能能够达到用户的实际需求,必须要对建筑内部的供电系统、照明系统、通信系统、排水系统等进行跟踪检测和控制,实现信息透明化,这就需要借助智能化技术来实现。例如,在空调器设计中,可以在设备所处的机房内安设信息接收和处理系统,将空调器的输入和输出接口和水位信号进行连接,这样就可以通过智能化技术实现对空调器运行状态的掌握。需要特别注意的是,为了方便后续的维护作业,要在处理器接口的周围留出三倍的空间。
3.2.1 释义识别
由于推特句子非常短,从表1中可以统计得到的语料总共有18 762对句子,而训练集中只有13 063对句子.为了充分利用大规模的未标记语料,在词向量学习时利用了外部的推特语料.在词向量训练之前,爬取了74 471 663条、共803 146 910个词的推特用于词向量学习,并在实验过程中分别验证了大规模未标记语料对实验性能的影响.在训练词向量时采用了两种训练方法:一是仅使用训练语料进行词向量学习,二是采用训练语料加爬取的推特语料进行词向量学习.训练词向量采用了word2vec[16- 17]工具,利用CBOW以及Skip-gram两种方法分别训练了100、200、300、400维的向量进行实验.
首先在开发集上进行二元释义识别实验,实验结果见表3所示.从表3中的实验结果可以观察到基于训练集+推特语料采用CBOW方法进行训练时,在向量选择300维时达到较好的性能.但这里的向量维度可能介于200~400维之间,通过进一步的实验发现当向量维度介于240~280时性能较为稳定,因此笔者在后续实验中选择向量维度为250维,减少了模型训练时间.表中第1列表示训练向量的维度,第1个字母C表示采用CBOW方法,而S表示Skip-gram方法,数字表示向量维度.
表3 语料及向量对释义识别的影响

Table 3 Influence of corpus and vector on paraphrase identification%
为了验证模型的释义识别性能,在二分类的基础上根据表2的关系进行了六分类,即进一步验证模型在释义识别中的细粒度性能.实验结果见表4,其中列为答案标签,行为预测结果.
从表4中可以看出,文中提出的模型在非释义方面效果要比释义句子对的分类效果要好,而释义句在一定的比例上向非释义句子偏移,但每一类在
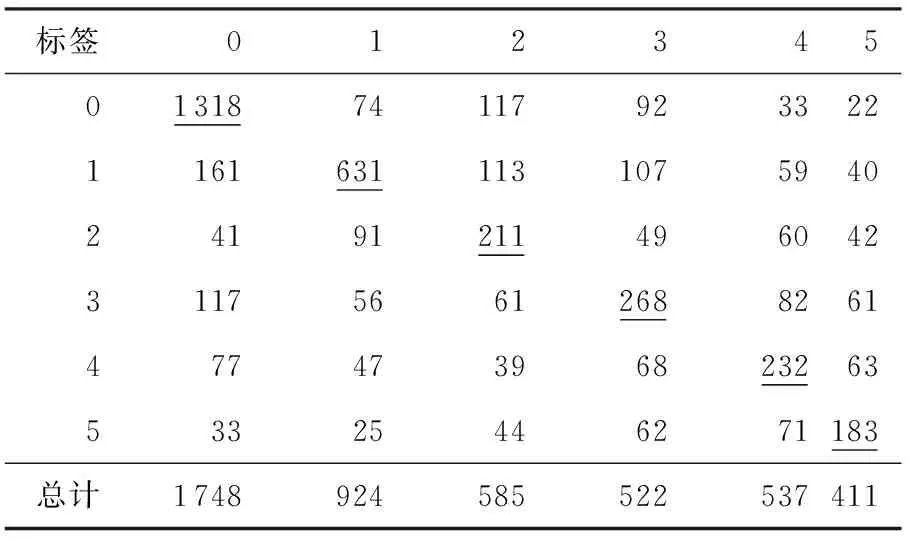
表4 开发集细粒度释义识别
各自的类别中都占有较高的比例,下划线部分表示正确的细粒度识别.从上表中也可以看出,数据在非释义的比例上要远高于释义句子对的比例,这会在训练时由于数据比例的不平衡性导致释义句子对会被识别为非释义.通过上述开发集实验,文中基于开发语料的模型参数选择为向量维度为250维,向量训练模型为CBOW,宽卷积过滤器窗口选定为2、3、4,mini-batch大小为50,迭代次数为30.
在测试时,选择了4种基准实验用于比较论文模型的性能,包括随机打分方法,一种有监督和一种无监督方法以及一种神经网络方法.
(1)随机赋值方法,即对每个句子对的语义关系随机给定一个[0,1]之间的一个实数值,并以0.5为阈值进行二元释义判断.
(2)第2种基准实验方法是监督的逻辑回归,这种方法采用简单的n-gram重叠特征,但在微软释义语料上取得了非常好的效果[18].
(3)第3种为无监督方法,利用加权文本矩阵分解进行句子表示,该方法基于词是否出现在句子的特性对句子建模,主要用于短文本[19].
(4)第4种为标准的两层神经网络分类器,主要利用翻译、词汇、句法和语义等特征[20].
基于上述4种基准实验,采用文中提出的模型得到最终的释义识别实验结果,如表5所示.

表5 释义识别实验结果
从表5可以观察到文中提出的模型能够取得较好的实验效果,尤其是单独使用feaXY特征时比采用联合sx和sy的方法能取得更好的效果.当联合3种特征向量时,与逻辑回归方法相比,F1值提高了7.4个百分点;和无监督方法相比,F1值提高了12.7个百分点;与标准的神经网络模型相比,F1值提高了1.2个百分点.
3.2.2 语义相似性
由于文中采用的语料在训练集和开发集中只标注了具有释义的投票数,因此无法直接量化句子间的语义相似性.而在任务的测试语料中又给出了每个句子对的语义相似性分值,即语义相同的句子对标记为1,语义完全无关的句子对分值标记为0,并按照步长为0.2的方式进行逐级打分.因此参照测试集语义分值标记的方法,在实验中,把不同级别的句子对所对应的语义量化为分值,但采用的方法与测试集的方法不同的是没有用一个固定值,而是随机选择了一个区间分值.因此,对于训练和开发集语料中的句子对选择了表6中语义值区间的一个随机分值来表示其语义相似性.表6中的语义分值区间的策略为表示释义和非释义关系越明显的句子对其语义值越靠近1和0,且区间范围为0.1,其他句子对区间跨度为0.2.表中除1.0外,其余分值的取值范围可取区间左边值,但小于区间右边值.这种分值区间定义方法尽可能与语料偏向非释义保持一致.

表6 投票数与对应的语义分值
按照表6对句子对的语义相似性打分,文中首先在开发集上采用皮尔森相关系数来进行模型语义相似性评测.采用了CBOW及Skip-gram模型训练词向量,向量维度进一步细粒度设置为50、100、150、200、250、300、350、400、450、500维,得到的开发集实验结果如图4所示.
从图4中可以看出,当采用CBOW方法训练维度为250维的向量时,文中提出的模型在开发集上

图4 开发集语义相似性结果
获得最佳的语义相似性性能.因此模型选择该维度向量进行测试集实验,其他参数与释义识别保持一致.根据选择的开发集参数,在测试集上的实验结果见表7,采用的基准实验与释义识别相同.

表7 语义相似性实验结果
从上表中可观察到文中提出的方法在语义相似性上feaXY的效果比联合sx和sy更好,当联合3种特征向量时,比任务的最佳基准方法(逻辑回归法)提高了7.1个百分点,与标准的神经网络模型相比,性能提升了1.9个百分点.
3.3 错误分析
对释义识别及语义相似性两部分实验的结果进行分析,主要发现如下两类错误:
(1)推特中存在较多的非规范词,例如“u”表示“you”,“4”表示“for”等,这会影响释义识别及语义相似性判断,这些词将进行规范化处理[21].
(2)模型对句子中的缩写词语义识别还需提高,例如表示第一季度的“Q1”与“inthefirstquarterofthisyear”由于长度相差较大,利用卷积模型不能有效地获取上下文信息,下一步可以考虑探索循环神经网络与卷积网络相结合的方法来解决该问题.
4 结语
文中提出了一种基于卷积神经网络的句子语义相似性计算模型,该模型不仅能够获得句子对中单个句子的语义表示,还能对每个句子对在经卷积和池化后的特征区域计算相似性.这样既获得了单个句子的向量表示,又得到了句子对之间的相似性特征,在全连接层后,能够得到句子对的向量表示.实验结果表明,文中提出的模型能够使释义识别及语义相似性任务在基准方法上有较大的性能提升.鉴于推特语料的非规范词比例较大及卷积网络在上下文信息获取方面的不足,对社会媒体内容规范化及探索更好的上下文信息表示模型将是下一步研究的重要方向.
[1] KALCHBRENNER N,GREFENSTETTE E,BLUNSOM P.A convolutional neural network for modelling sentences [C]∥Proceedings of the 52ndAnnual Meeting of the Association for Computational Linguistics.Baltimor: ACL,2014:655- 665.
[2] JEFF M,MIRELLA L.Composition in distributional mo-dels of semantics [J].Cognitive Science,2010,34(8):1388- 1429.
[3] WILLIAM B,MIRELLA L.A comparison of vector-based representations for semantic composition [C] ∥ Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning.Jeju Island: ACL,2012:546- 556.
[4] FABIO M Z,IOANNIS K,FRANCESCA F,et al.Estimating linear models for compositional distributional semantics [C]∥Proceedings of the 23rdInternational Confe-rence on Computational Linguistics.Beijing:COLING,2010:1263- 1271.
[5] DIMITRI K,MEHRNOOSH S.Prior disambiguation of word tensor for constructing sentence vectors [C]∥Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing.Seattle:ACL,2013:1590- 1601.
[6] YOON K.Convolutional neural networks for sentence classification [C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing.Doha:ACL,2014:1746- 1751.
[7] YOSHUA B,REJEAN D,PASCAL V,et al.A neural probabilistic language model [J].Journal of Machine Learning Research,2003,3(6):1137- 1155.
[8] RICHARD S,CLIFF C-Y L,ANDREW Y N,et al.Parsing natural scenes and natural language with recursive neural networks [C]∥Proceedings of the 28thInternational Conference on Machine Learning.Washington:ICML,2011.
[9] RICHARD S,Eric H H,JEFFREY P,et al.Dynamic pooling and unfolding recursive autoencoders for paraphrase detection [C]∥Proceedings of the Advances in Neural Information Processing Systems.Granada:NIPS,2011:801- 809.
[10] KAI S T,RICHARD S,CHRISTOPHER D M.Improved semantic representations from tree- structured long short- term memory networks [C]∥Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics.Beijing:ACL,2015:1556- 1566.
[11] CHO K,van Merrienboer B,Gulcehre C,et al.Learning phrase representations using RNN encoder-decoder for statistic machine translation [C]∥Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing.Doha:ACL,2014:1724- 1734.
[12] XU W,CHRIS C-B,BILL D,et al.SemEval- 2015 task 1:paraphrase and semantic similarity in Twitter [C]∥Proceedings of the 9thInternational Workshop on Semantic Evaluation.Denver:ACL,2015:1- 11.
[13] SEVERYN A,MOSCHITTI A.Learning to rank short text pairs with convolutional deep neural networks [C]∥Proceedings of the 38thInternational ACM SIGIR Confe-rence on Information Retrieval.Santiago:ACM,2015:373- 382.
[14] ALEX K,ILYA S,Geoffrey E H.ImageNet classification with deep convolutional neural networks [C]∥Proceedings of the Advances in Neural Information Processing System.Lake Tahoe:NIPS 2012:1097- 1105.
[15] HE H,KEVIN G,JIMMY L.Multi- perspective sentence similarity modeling with convolutional neural networks [C]∥Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Doha:ACL,2015:1576- 1586.
[16] MIKOLOV T,SUTSKEVER I,CHEN K,et al.Distributed representations of words and phrases and their compositionality [C]∥Proceedings of the Advances in Neural Information Processing System.Tahoe:NIPS,2013:3111- 3119.
[17] MIKOLOV T,YIH W-T,ZWEIG G.Linguistic regularities in continuous space word representations [C]∥Proceedings of the 2013 Conference of NAACL.Atlanta:ACL,2013:746- 751.
[18] DAS D,SMITH N A.Paraphrase identification as probabilistic quasi-synchronous recognition [C]∥Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th IJCNLP of the AFNLP.Suntec:ACL,2009:468- 476.
[19] GUO W,DIAB M.Modeling sentences in the latent space [C]∥Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics.Jeju Island:ACL,2012:864- 872.
[20] BERTERO D,FUNG P.HLTC- HKUST:a neural network paraphrase classifier using translation metrics,semantic roles and lexical similarity features [C]∥Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015).Denver:ACL,2015:23- 28.
[21] QIAN T,ZHANG Y,ZHANG M,et al.A transition- based model for joint segmentation,POS- tagging and Normalization [C]∥Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing.Doha:ACL,2015:1837- 1846.
Convolutional Network-Based Semantic Similarity Model of Sentences
HUANGJiang-pingJIDong-hong
(Computer School, Wuhan University, Wuhan 430072,Hubei,China)
Computing the semantic similarity between two sentences is an important research issue in natural language processing field, and, constructing an effective semantic model of sentences is the core task of natural language processing for paraphrase identification, textual similarity computation, question/answer and textual entailment.In this paper, a parallel convolutional neural network model is proposed to represent sentences with fixed-length vectors, and a similarity layer is used to measure the similarity of sentence pairs.Then, two tasks, namely paraphrase identification and textual similarity test, are used to evaluate the performance of the proposed model.Experimental results show that the proposed model can capture sentence’s semantic information effectively; and that, in comparison with the state-of-the-art baseline, the proposed model improves theF1-score in paraphrase identification by 7.4 percentage points, while in comparison with the logistic regression method, it improves the Pearson correlation coefficient in semantic similarity by 7.1 percentage points.
convolutional network; paraphrase identification; sentence model; semantic similarity
2016- 06- 12
国家自然科学基金重点项目(61133012);国家自然科学基金资助项目(61173062,61373108);国家社会科学基金重点项目(11&ZD189) Foundation items: Supported by the Key Program of National Natural Science Foundation of China(61133012),the National Natural Science Foundation of China(61173062,61373108) and the National Planning Office of Philosophy and Social Science(11&ZD189)
黄江平(1985-),男,博士生,主要从事自然语言处理、机器学习研究.E-mail:hjp@whu.edu.cn
1000- 565X(2017)03- 0068- 08
TP 391
10.3969/j.issn.1000-565X.2017.03.010
