基于BP神经网络的浙北夏季降尺度降水预报方法的应用
2017-05-30黎玥君郭品文
黎玥君 郭品文


摘要利用NCEP提供的全球空间分辨率为2.5°×2.5°、2007-2012年6-8月日平均500 hPa高度场再分析格点资料和浙北地区158个站点观测资料,研究了不同大气环流型下局地降水与大尺度降水场之间的关系,以4种不同环流型下的预报对象和预报因子分别采用BP神经网络方法对观测资料进行逼近,得到4种空间降尺度的预报模型,分析对比4种预报模型158站逐日的降水量的预报。结果表明:神经网络模型的隐层节点数为2时,对降水的拟合效果最好;对降水的极值拟合效果中,环流分型中NW型和c型的效果优于SW型和SE型;从4种分型下的误差空间分布来看,浙北地区沿海的宁波、舟山一带的误差小于浙北其他区域;把雨量分等级后进行预测,发现模型对暴雨的预测能力最好。
关键词降水预报;降尺度;BP神经网络;大气环流分型
降水预测一直是天气预测的重点和难点,也是政府防汛抗旱工作部署的重要参考依据(黄惠镕和郭品文,2014)。降尺度预报即是利用大尺度的数值预报产品生成精细化高分辨率的要素预报场,降尺度方法是精细化气象要素预报的主要方法,主要有嵌套高分辨率数值模式的动力降尺度技术和基于现有大尺度数值产品的统计降尺度技术(刘永和等,2011),多年研究表明,统计降尺度法是一种有效的降尺度方法,其核心就是通过大量的历史观测资料建立大尺度气象要素场与高分辨率气象要素场之间的关系(Wilby,1999)。统计降尺度有以下优点:能够以很高的计算效率由大尺度气象要素得到区域尺度的气象要素,计算量相当小,节省机时(Charles et al.,1999);能输出较高分辨率或站点尺度的气象要素;模型参数可以受区域下垫面特征的控制(矫梅燕等,2006)。统计降尺度能够弥补动力降尺度的一些不足,因而近年来许多气象工作者对统计降尺度技术进行了研究和探索。统计降尺度中应用最多的是多元线性回归(智协飞等,2013)、SVD线性转换法(Oshima et al.,2002;范丽军等,2007)和人工神经网络法(Anandhi et al.,2009)。因此本文研究面向乡镇级别站点的非线性日降水降尺度方法,实现具有地方特色的空间降尺度的业务需求。
降水的分布以及降水的强度变化受风向和天气系统的影响很大,并且神经网络方法不具备挑选预报因子的功能,因此对初选预报因子进行分类在降水预报研究中显得尤为重要。实践经验告诉我们,夏季6-8月副热带高压位置和强度变化对降水的区域分布和强度都会影响,其次,西风带环流型也很重要(朱乾根等,2007)。这些主观分型都是以天气学理论指导,随着科学技术现代化,分类越来越客观化,对于汛期降水的预测,结合环流指数的统计和环流分型的应用是客观分型的基础和途径,环流指数通过全球环流的特征指标或格点场资料得到(贾丽伟等,2006)。Lamb-Jenkinson大气环流分型方法(張炎和朱静静,2009)基于所在区域的格点场资料,它通过定义一些客观的标准把主观的分型方法客观化,可以自动地划分出环流类型,客服主观分型的缺点。实践表明:分型结果的天气意义明确,依据NCEP提供的全球2.5°×2.5°、2007-2012年6-8月日平均500 hPa高度场再分析格点资料,在客观分析的基础上,逐日鉴别定型,做降水天气预报方法是可行的。
1资料和方法
使用2007-2012年浙江省气象台整理的19个县市站的夏季6-8月的逐日降水资料,以及同期的129个中尺度气象站逐日降水资料(站点分布如图1所示)和NCEP提供的全球2.5°×2.5°的2007-2012年6-8月日平均500 hPa高度场再分析格点资料。
1.1降水分型:Lamb-Jenkinson大气环流分型方法
以浙北地区为例,杭州位于120.10°E、30.14°N,地处中国东部,浙江省的北部,以(120°E,30°N)为中心点,在(112.5~127.5°E,25~35°N)的范围内,每隔5个经度、2.5个纬度的网格点上取16个点(图2),用该范围内16个格点资料计算格点(120°E,30°N)的环流指数,并利用环流指数的计算结果进行环流分型。格点(120°E,30°N)的计算结果代表了周边±1.25°经纬度范围的环流状况,该区域涵盖了浙中北范围,在下面的降尺度应用中以杭州站为例。
环流分型的方法和计算公式详见文献张炎和朱静静(2009)。大气环流分型方法划分出4类主要的环流类型,分别为平直气流型、旋转型、混合型和无定义型,4类又可以细分为27种不同的环流类型
对2007-2011年6-8月共460 d的逐日环流指数进行计算,并按上述方法分型。结果显示有5种环流没有出现,10次环流出现的频次在10次以下;其中NW(8.48%)、SE(15.87%)、SW(29.57%)、c(15.43%)4种环流类型出现的频率最高,一共占到了69.35%,这4种环流类型主导了浙北地区夏季的天气(图3)。
1.2 EOF方法
本文用于建立预报模型的因子都是通过与预报量作相关分析取得的,而采用EOF展开的主成分不仅包含了原始降水场的大量信息,同时使降水场随时间变化的信息都集中反映在时间系数的变化上,而且相互正交,这样起到了降维的作用,缩小了神经网络规模,避免网络过度学习。EOF的方法详见文献何慧等(2007)。
1.3人工神经网络方法
人工神经网络以其具有自学习、自组织、较好的容错性和优良的非线性逼近能力为特点而被广泛应用。在实际应用中,80%~90%的人工神经网络模型是采用误差反传算法(BP神经网络)。它是利用输出后的误差来估计输出层的直接前导层的误差,再用这个误差估计更前一层的误差,如此一层一层的反传下去,就获得了所有其他各层的误差估计(金龙,2005)。本文使用的是算法较成熟的前馈三层BP网络模型。有关3层前馈网络模型的算法详见金龙等(2003)。
2预报量和预报因子分析
2.1预报量和预报因子的分组
以浙江2007-2012年6-8月共552 d小尺度降水场的时间系数为预报量,其中前5 a的460 d为训练样本,2012年的92 d为检验样本。取与预报量通过相关性检验的同期大尺度降水场的时间系数作为预报因子,建立BP神经网络预报模型。利用大气环流分析方法把初选预报量和初选预报因子分为4组,4组的训练样本长度分别是SE型共40 d,NW型58 d,C型73 d,SW型193 d。
2.2预报因子的选取
由于人工神经网络不能自动地筛选预报因子,大量的预报因子会降低模型的预报能力,因而在进行建模前,先要对每组预报因子和预报量分别进行EOF分解。初选预报对象(小尺度降水场)中选取累计方差贡献大于90%的时间函数作为预报对象,SE型预报对象有25个,NW型预报对象有35个,c型预报对象有42个,SW型预报对象有48个。分别选取与各个预报对象相关度高(通过a=0.10的显著性检验)且方差贡献大的所有初选预报因子的时间函数(预报因子)用于预报建模(表略)。
3预报模型分析
3.1预报模型的建立
本文使用的是前馈三层BP网络模型,使用newff函数生成一个三层的BP网络模型时,采用tansing作为前两层的传递函数,输出层含有1个神经元,采用purelin传递函数,并将初始权值随机化;同时,以结合了动量梯度下降算法和自适应学习速率梯度下降算法的~aingdx函数作为训练函数,其中学习速率为0.9,动量常数m。为0.5。
3.2预报模型中隐层节点数的确定
合理的网络模型是必须在具有合理隐层节点数、训练时没有发生“过拟合”现象、求得全局极小点和同时考虑网络结构复杂程度和误差大小的综合过程。因此隐层节点数的确定对模型的建立具有重要的影响。隐层单元数的选取见Mirchandani andGao(1989)。
本文a分别取1~6,4组的学习矩阵样本长度为40、58、73、193,对网络进行学习训练。当学习矩阵训练次数达到一定时,误差函数趋于稳定,此时网络模型的各个参数确定,并且取均方根误差最小时对应的a的值(表1)。
对4组预报量的分析,不同隐节点数,3种指标结果都不一样,结果如下(表2)。
由表2可以看到,SE型和SW型中,当a=2时,平均绝对误差(MAE)和均方根误差(MSE)最小,而NW型和c型中,当a=5时,误差值最小,拟合效果最好。
3.3预报模型的拟合结果和预报模型的检验
图4给出了各类型以小尺度累计方差贡献大于90%的时间函数(预报量)和与预报量相关高的大尺度的时间函数(预报因子)作为输出量和输入量的BP神经网络预报模型的拟合结果,对浙北地区2007-2011年夏季各类型小尺度降水量的时间函数的拟合效果(预测值),以及同期的各类型小尺度的时间函数(真实值),由图4可以看到,BP神经网络模型对历史样本有较高的拟合精度,在NW型和c型中,对极大值的拟合精度较高,而在SE型和SW型中,对极大值的拟合没有NW型和C型精度高。
评价一个预测模型的优劣分析其拟合效果是一个方面,更重要的是检验模型预报能力。因此利用2012年6-8月的夏季降水作为检验样本,在选择预测因子时,因为SW型的样本长度和NW型的样本长度最多,分别为23 d和16 d,其余类型的样本长度都不超过10 d,所以本文只分析SW型和NW型的模型检验能力。从图5中可以看到,SW型和NW型的时间系数预测和实况都比较接近,总体趋势较好,其中SW型对极大值的预测效果比NW型的精度更高。
4预报效果评价
为了进行客观定量分析,采用以下3种统计评价指标进行分析(何慧等,2007):
4.1平均絕对误差(MAE指数)的分布
不同的a值(不同的隐层节点数)误差也会不一样,每个类型分别取使得误差值最小的a值,构建网络模型,得到最佳的拟合时间系数。把各类型最佳的时间拟合系数乘以各自的空间函数,就可以还原得到拟合的降水量。为了评价拟合效果,用降水量的实测值和降尺度模型的预报值之间的差值(MAE指数)作为评价标准。分析4种类型下各自的神经网络预报模型的MAE(绝对误差)空间分布(图6),可以看出,降尺度预报模型的误差值均在2-10mm之间,4种类型中,SW型的预报效果最好(MAE指数最小)。SE型和NW型呈相反的趋势,SE型中,MAE的极大值去位于浙江与安徽的交界处,极小值位于浙北和浙中的交界处会稽山附件,NW型中MAE的极大值和极小值分布于SW型恰好相反。说明SW型的边界预报效果差于内部预报效果,NW型中西南部的预报效果差于东北部。由图6可以看出,在浙北这些区域中,靠近沿海的东部,即宁波、余姚、绍兴这些地方的MAE指数都是最小的,说明浙北沿海地区的拟合效果比较好。
4.2相对偏差(MRD指数)的分布
由MAE指数的空间分布,可以看出有些地区的MAE指数很大,甚至会接近整个浙北地区的降水均值,难道是模型预报效果差?整个浙北地区中,有些台站,平均降水量就很小,MAE指数自然不会大,而有些台站,受地形或者天气系统的影响,降水多属于大到暴雨,MAE指数都比较大,所以仅仅用MAE指数可能不是很客观,于是,定义MRD指数(即相对偏差),通过相对偏差来看预报模型的效果,如果这个指数越大,说明绝对误差(MAE指数)相对降水均值越明显即预报效果越差,反之。
由各个类型的MRD指数的空间分布(图7)可以看出,c型的MRD指数普遍是最小的,MRD指数在15%左右的覆盖面最广,且最大值都不超过42%,即预报效果最好,这与MAE指数的预报效果不相符SW型的预报效果最差,MRD指数普遍都在28%以上,MRD指数在37.22%以上的覆盖面也很广。
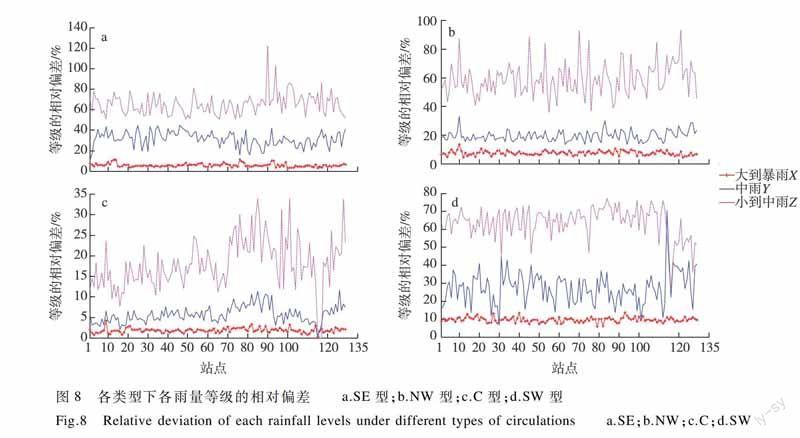
4.3雨量分等级的误差分析
为了进一步研究浙北地区夏季降水预测方法的能力,将浙北地区4个类型的夏季降水分等级进行预测,将雨量分为3个等级(金龙等,2003):小雨(0.1~10 mm/(24 h))、中雨(10-25mm/(24 h))、大到暴雨(25~100 mm/(24 h))。可以看出,不同的雨量大小,模型的预测能力也不一样,依然用相对偏差作为预测指标来评价模型的预报能力。由图8可以看出,4种类型雨量分等级后,都是暴雨的MRD指数(相对偏差)最小,小雨的MRD指数最大,因此可以认为,BP神经网络的降尺度预报模型对大暴雨的预报效果比较好。
5结论
在天气分型的基础上,利用BP神经网络的降尺度方法建立了夏季分型降水预测模型。利用NCEP再分析资料和站点降水资料,通过计算相关系数(小尺度降水场的时间系数分别与大尺度降水场的时间系数求相关,取通过a=0.10的显著性检验的大尺度的时间系数作为预报因子)的方法,得到了BP网络模型的输入层和输出层,进行训练后,结果表明:
1)使用Lamb-Jenkinson法对浙北地区进行环流分型,环流分型的结果有明确的物理意义,有利于挑选出相应的预报因子和预报对象,提高降尺度模型预报的准确率。
2)夏季大小尺度降水场分别采用EOF分解,主成分不仅包含原始大、小尺度降水场的大部分信息,同时各主成分之间相互正交,有效地对初选因子进行降维。选取小尺度降水场中方差贡献超过90%的主成分作为预报对象,相关系数达到0.10信度的显著性水平检验后的大尺度降水场的主成分作为预报因子,这样挑选的预报因子有利于提高预报的准确率。
3)基于BP神经网络的方法进行降尺度预报,模式中不同的隐层节点数影响模式的预测能力,选取使得预测效果最佳的隐层节点数2,拟合得到浙北地区的降水值。
4)为了清楚的看到预测效果,提高夏季降水预测的技巧,在挑选降水预测因子时,把雨量分等级划分,再进行降尺度预报,通过MRD指数(相对偏差)可以看出,BP神经网络模型对暴雨的预报能力是最高的。
