存储系统可靠性预测综述*
2017-03-16刘晓光李忠伟
李 静,王 刚,刘晓光,李忠伟+
1.中国民航大学 计算机科学与技术学院,天津 300300
2.南开大学 计算机与控制工程学院,天津 300350
存储系统可靠性预测综述*
李 静1,2,王 刚2,刘晓光2,李忠伟2+
1.中国民航大学 计算机科学与技术学院,天津 300300
2.南开大学 计算机与控制工程学院,天津 300350
对存储系统的可靠性预测,可以用来评估、比较不同容错机制以及评价不同系统参数对存储系统可靠性的作用,有利于创建高可靠的存储系统。因此,存储系统可靠性预测的研究一直是领域热点之一。从硬盘单体和存储系统两种预测对象的角度,对近年来该领域的相关研究进行了介绍和分析。首先从硬盘个体和群体两种对象,主动容错和被动容错两种容错方式,以及纠删码和副本两种冗余机制几个角度分类介绍当前可靠性预测研究现状,然后进一步指明当前该领域研究中尚未解决的一些难题和未来可能的发展方向。分析表明,目前对副本存储系统和主动容错存储系统的可靠性预测研究尚显不足,是未来很有价值的研究方向。
存储系统;可靠性预测;主动容错方式;被动容错方式
1 引言
可靠性描述的是系统或设备能够持续有效提供正确数据服务的能力。存储系统中,由于用户数据的巨大价值,可靠性是与性能和费用等指标重要性相当的一个评价标准。因此,存储系统的可靠性一直以来都是存储领域的研究热点。
在存储系统构建之前或者潜在的数据丢失事件发生之前,可靠性评价(预测)可以帮助系统设计者量化分析不同系统的可靠性水平以及不同策略对系统可靠性的提升效果,能够更好地指导高可靠存储系统的创建。
为了从根本上提高存储系统的可靠性,很多研究者尝试基于硬盘的SMART(self-monitoring,analysis and reporting technology)信息,使用统计学和机器学习的方法创建硬盘故障预测模型,提前预测出潜在硬盘故障,从而主动采取相应处理措施,可大幅度降低故障发生对系统可靠性和可用性的负面影响。
本质上,传统意义的存储系统可靠性评价和故障预测可以统一为一个问题的两面:可靠性评价可视为群体化的“静态预测”,即对特定群体(如某种型号的硬盘、相同配置的一类磁盘阵列),依据故障模型,静态预测群体的期望寿命;反过来,故障预测也可视为一种个体化的“动态评价”,即对特定个体(如某个硬盘、某个系统),依据实时状态信息,动态评价其可靠性(健康还是潜在故障)。两者的最终目的都是比较:“静态评价”比较群体间可靠性,作用是分析系统参数对可靠性的影响,指导系统设计的优化;“动态评价”则是比较系统运行中个体间可靠性(或者说潜在故障的紧迫程度)的高低,作用是指导人们利用有限的资源优先修复系统中可靠性最薄弱之处。
本文拟对近年来存储系统可靠性预测领域的相关研究进行全面综述和分析。第2章简单介绍存储系统可靠性预测领域的相关基础知识;第3、第4章分类综述当前可靠性预测研究的现状;第5章指出当前存储系统可靠性预测研究中尚未解决的难题和未来可能的研究方向。本文将从硬盘单体和存储系统两种预测对象的角度对可靠性预测进行介绍和分析。
2 可靠性预测中的相关知识
下面将介绍可靠性预测领域中的相关基础知识,以帮助读者更好地理解本文内容。
2.1 数据容错方式
为了保护用户数据,存储系统一般都要使用一定的容错技术保证系统可靠性,在硬件设备故障之后(或之前),对故障(或预警)硬盘上的数据进行重构(或迁移),达到数据保护的目的。根据保护数据原理的不同,存储系统采用的容错方式可以分为两类:被动容错方式和主动容错方式。
2.1.1 被动容错方式
利用冗余信息实现故障数据的重构是存储系统应对硬盘故障最常用的传统容错方式:如果发生了硬盘故障,故障盘上的数据可以利用其他健康硬盘上的数据进行恢复。其中,有两类常用的冗余技术:纠删码技术(erasure code)和副本技术(replication)。
纠删码技术[1]通过一定算法将用户数据进行编码得到冗余信息,并将原始数据和冗余信息一起存储到系统中,以此达到容错的目的。纠删码系统具有冗余率低和灵活性高等优点,缺点是重构开销比较大。副本技术为每个数据块创建一定数量的副本,并按照某种规则散布在系统中,以此达到容错的目的。副本系统利用高冗余率换取高容错能力,具有很好的读性能和重构能力。
2.1.2 主动容错方式
随着存储系统规模的逐渐增大,故障事件发生的频率越来越高,被动容错系统只能通过增加冗余来保障系统的可靠性,而这无疑会增加系统成本和降低系统降级模式下的访问性能。面对被动容错模式的困境,一些研究者开始探讨能否在硬盘故障发生前就将其预测出来,提前迁移保护有潜在危险的数据,通过这种主动容错模式从根本上提高存储系统的可靠性。
现代硬盘大都采用了SMART技术,可实时获取硬盘状态信息,并当任意一个属性值超过预设阈值时发出警报。但阈值法只能提前预测出3%~10%的硬盘故障[2],不能满足用户的需求。因此有研究者提出利用统计学和机器学习的方法在硬盘SMART数据集上建立故障预测模型,以此提高预测准确率。
当前主动容错技术的具体研究方法是,预先收集大量硬盘的SMART数据信息和系统事件,并建立硬盘故障预测模型;然后实时监测存储系统中工作硬盘的状态,利用预测模型预测潜在硬盘故障,并对即将到来的故障提前进行处理,消除潜在的故障隐患,以此达到提高系统可靠性的目的。
2.2 可靠性度量指标
存储系统可靠性预测/评价研究首先要解决的问题是设计合理的度量指标。下面将从硬盘单体和存储系统两方面介绍可靠性度量指标的相关研究。
2.2.1 硬盘可靠性度量
硬盘的可靠性是指,在给定的操作环境与条件下,硬盘在一段时间内可以正确读写的能力。硬盘可靠性受到设计、生产和使用环境的影响。把硬盘可靠性度量指标分为两类:第一类是受型号和生产厂商影响的硬盘群体可靠性度量指标;第二类是受使用环境、工作负载和时间等因素影响的硬盘个体可靠性度量指标。
硬盘的群体可靠性度量指标有年故障率(annual failure rate,AFR)和平均无故障时间(mean time to failure,MTTF)[3]。年故障率指一年内硬盘发生故障的期望概率;平均无故障时间是指在规定的环境下,硬盘正常运行至下一次故障的平均时间。
硬盘的个体可靠性度量是预测模型根据硬盘某时刻的SMART信息得出的可靠性预测结果。故障预测模型[2,4-10]一般都是二分类模型,因此对硬盘个体给出的可靠性度量只能是一个二元指标:未来一段时间会发生故障或者不会。对故障预测模型本身,有3个评价指标:准确率或召回率(false discovery rate,FDR)、误报率(false alarm rate,FAR)和提前预测时间(time in advance,TIA)。FDR是故障硬盘中可以被准确预测出的比例;FAR是好盘中被误报为坏盘的比例;TIA描述的是可以提前多长时间预测出即将到来的故障。显然,这3个指标也直接影响了存储系统的可靠性和可用性。
硬盘故障不是突然发生的,而是随着时间流逝慢慢发生的,是一个逐渐老化的过程。这些故障在发生之前,一般都会出现一些异常现象。比如,硬盘主轴马达在使用过程中会慢慢磨损,将引起主轴偏心逐渐增大,从而使得磁道跟踪难度加大,进而可能会引起跟踪偏差而丢失数据。故障预测模型如能刻画这种趋势,不只是定性给出硬盘将要故障与否的二元预测,而是更细致描述硬盘某时刻的“健康度”(预期剩余寿命),就可以更有效地指导后期的预警处理。作者前期工作[11-13]提出创建硬盘“健康度”(health degree)预测模型,对硬盘的可靠性程度(预期剩余寿命)给出细致预测。“健康度”表示硬盘将要发生故障的概率,或硬盘的预期剩余寿命,是根据硬盘当前SMART属性值给出的硬盘个体可靠性度量值。例如,图1是硬盘剩余寿命划分实例[12],剩余寿命被划分到6个“健康度”区间,离故障时刻越近,“健康度”越低,Level1表示硬盘的剩余寿命不足72小时,需要紧急处理。针对硬盘剩余寿命预测模型,目前的评价指标是“accuracy of residual life level assessment”(ACC),表示好/坏样本(硬盘)中可以被预测到正确剩余寿命区间的比例。
2.2.2 存储系统可靠性度量
存储系统发生某些硬件故障之后,可以利用其自身的容错机制恢复故障数据,属于可修复系统。系统级的可靠性度量指标主要有平均修复时间MTTR(mean time to repair)和平均数据丢失时间MTTDL(mean time to data loss)。
如果发生了超出系统最大容错能力的并发故障,导致系统中至少一个数据块的信息发生了永久性丢失,这时认为系统发生了数据丢失事件。系统发生一次数据丢失事件的期望时间作为该系统的MTTDL。
除了MTTDL之外,近年来很多研究者开始使用一段运行期间内发生的数据丢失事件的个数作为系统可靠性评价指标。相对于MTTDL,存储系统实际运行时间很短,MTTDL并不能反映系统的真实可靠性水平,而系统实际运行期间(3年或5年)内发生数据丢失事件的期望个数(概率),可以更好地帮助系统设计者和用户理解存储系统的可靠性。

Fig.1 An example of health degree settings图1“健康度”设置例子
3 硬盘可靠性预测的发展
据统计,硬盘是当前数据中心最主要的故障源[3,14-15],微软数据中心中故障硬盘的替换数量占所有硬件替换的78%[3]。因此,硬盘自身的可靠性对存储系统整体可靠性的影响巨大,有很多研究关注硬盘的可靠性。
对硬盘可靠性预测的研究大体可以分为两类:第一类是通过对大规模真实硬盘数据的分析,预测硬盘群体的可靠性特征;第二类是通过创建硬盘故障预测模型,基于硬盘的SMART数据预测硬盘个体可靠性特征。
3.1 硬盘群体可靠性分析的发展
20世纪90年代初期,Gibson[16]发现硬盘故障率呈现出“浴盆曲线”规律,即初期故障率比较高,一段时间后呈现出较低较稳定的故障率,到最后因为硬件老化,故障率又呈现出上升的趋势。他认为可以用指数分布很好地模拟硬盘的故障时间分布,这为后来学者使用Markov模型预测存储系统可靠性提供了理论指导。
后来,指数分布假设被Schroeder和Gibson[3]以高置信度的结果推翻了,他们发现硬盘故障呈现出显著的早发性磨损退化趋势,而且与硬盘故障时间呈现出明显的相关性和依赖性。因此,他们建议研究者使用真实的故障替换数据,或是双参分布(如韦布分布)模拟硬盘故障时间。
潜在扇区错误是另一种故障类型,硬盘上一个或多个二进制位永久地损坏,不管尝试多少次,都不可能正确地读一个扇区。Ma等人[17]发现工作硬盘上潜在扇区错误的数量会随着时间持续增长,不断增加的扇区错误会导致硬盘可靠性持续降低,从而引发硬盘整体崩溃。另外,Bairavasundaram等人[18-19]通过对大量企业级和近线级硬盘数据的研究,发现潜在扇区错误和静默的数据损坏具有空间局限性和时间局限性等特点,据此他们提出有针对性的“磁盘清洗”策略。
还有一些研究[20-22]观察故障机理的特性以及一些SMART属性对硬盘整体故障率的影响。其中,Shah和Elerath[20]的研究发现污染和磁头稳定性是影响可靠性的重要因素,表明硬盘的可靠性和硬盘的制造商和型号非常相关;Pinheiro等人[21]发现一些SMART属性如扫描错误(scan errors)、重定向数量(reallocation counts)等对硬盘故障有很大影响,而且与之前的研究不同,他们发现高温对硬盘故障没有太多影响,这个发现后来在El-Sayed等人[22]的工作中也得到了证实。
3.2 硬盘个体可靠性预测的发展
早在新世纪初,Hamerly和Elkan[4]就尝试构建基于SMART属性的硬盘故障预测模型,发现有些SMART属性会对预测准确性造成负面影响,使用3个属性的贝叶斯分类方法可达到最好的预测性能——误报率1%和准确率55%。
之后,Hughes博士领导的团队对此问题进行了深入研究。他们发现很多SMART属性是非参分布的,因此使用Wilcoxon秩和检验方法达到了误报率0.5%和准确率60.0%的预测性能[5]。接下来,他们比较了支持向量机(support vector machine,SVM)、无监督聚类、秩和检验与反向安排检验的预测性能,其中秩和检验性能最好,可达到0.5%的误报率和33.2%的准确率[6]。这一工作的另一重要贡献是给出一个包含178块健康硬盘和191块故障硬盘的开放数据集,成为很多后来研究工作的基础。在进一步工作中[2],他们采用反向安排检验等方法进行特征选取,将SVM的预测性能提高到误报率0和准确率50.6%。
近年来,研究者又尝试用其他统计学和机器学习方法解决硬盘故障预测问题。Zhao等人[7]将SMART属性值视为时间序列数据,使用隐马尔可夫模型(hidden Markov model,HMM)和隐半马尔可夫模型(hidden semi-Markov model,HSMM)在Hughes数据集上获得了0的误报率和52%的预测准确率。Wang等人[8]采用马氏距离预测硬盘故障,并提出了一种“故障模式、机制和效果分析”的特征选取方法,使用优选属性获得的预测性能显著优于使用全部属性。在进一步的工作中[9],Wang等人又提出最小冗余最大相关法消除冗余属性,在Hughes数据集上获得了0的误报率和67%的准确率,而且56%的故障可以被提前20小时预测出来。
上述研究工作采用的模型都是“黑盒子”模型,只是给出硬盘是否即将故障的预测,并没有给出预测的规则和标准,从而无法知道导致潜在故障的原因。
作者前期工作中采用了人工神经网络[10]和决策树[11]等预测准确性、稳定性和解释性更佳的机器学习方法。该方法最好预测性能达到0.1%以下的误报率和95%的准确率,且能提前一周以上预测出故障,为预警处理提供了充足时间。而且决策树预测模型可以生成易于理解的规则,能够帮助人们理解硬盘故障的原因,从而采取有针对性的措施降低故障率。
图2是基于决策树[11]创建的硬盘故障预测模型。其中“,POH”“、RUE”、“TC”、“SUT”和“SER”代表某些SMART属性。决策规则清晰地解释了SMART属性值与故障之间的关系。例如,依据开机时间属性(POH)是否小于90将全部样本(根结点)分裂为结点2(叶子)和结点3。这样,决策树模型除了预测故障之外,还能为采取措施并减少故障提供依据。

Fig.2 Asimplified classification tree for hard drive failure prediction图2 基于决策树的硬盘故障预测模型
最近,EMC公司的研究者[17]设计出一种RAID(redundant array of independent disks)系统保护机制——RAIDShield,其中包含PLATE和ARMOR两个模块。PLATE是一种简单的基于RS(reallocated sectors)数量的阈值预测方法,可以达到2.5%的误报率和65.0%的准确率。ARMOR模块使用联合故障概率方法量化每个RAID校验组发生数据丢失的概率。通过设置合适的概率阈值,ARMOR可以检测出80%的脆弱(vulnerability)RAID-6校验组,从而可以消除大部分被PLATE模块漏报的数据丢失事件。
上述研究把硬盘故障预测看成单纯的二元分类问题:一个硬盘是否将要发生故障。实验结果[10-11]显示,预警盘被预测模型检测出来后,一般要经历一段比较长的时间(TIA>300 h)才会真正发生故障,证实了硬盘故障不是突然发生,而是逐渐老化的过程。因此,提出了“健康度”预测模型[11]的概念,并基于回归树(regression trees)构造硬盘健康度预测模型,细致评价硬盘的健康程度(故障概率),为确定后期预警处理的优先级提供量化指导。这样,系统可以在有限的恢复带宽下优先处理最危急(故障概率最大)的硬盘,从而最大限度地保障系统的可靠性和可用性。然而“,故障概率”(健康度)不能直观地指导预警处理。
庞帅等人[13]用硬盘的剩余寿命(故障前剩余的工作时间)表示“健康度”,提出联合贝叶斯网络(combined Bayesian network,CBN)模型。该模型结合4个分类器——人工神经网络、进化神经网络、支持向量机和决策树的预测结果,预测硬盘的剩余寿命。采用一个合适的剩余寿命划分区间后,CBN模型可以达到60%的剩余寿命区间预测准确率。
许畅等人[12]考虑到硬盘健康状态具有长相关依赖特点,基于硬盘SMART属性的时序性特征,采用递归神经网络(recurrent neural network,RNN)模型预测硬盘的健康度,可以达到约40%~60%的剩余寿命区间预测准确率。
3.3 硬盘可靠性预测总结
目前,很多统计学和机器学习方法被用来构建硬盘故障预测模型,表1总结了各种不同预测模型的特点。“二分类”表示模型只能给出硬盘“是/否”将要故障的二分类预测结果;“健康度”表示模型的预测结果可以更细致地刻画硬盘某时刻的健康状况;“可解释性”表示根据模型的预测结果,可以分析导致故障的原因;“时序特点”表示模型利用了硬盘样本具有时序性的特点;“提前预测时间”表示评价了模型的提前预测时间。

Table 1 Overview of hard drive failure prediction models表1 硬盘故障预测模型总结
4 存储系统可靠性预测的发展
存储系统的整体可靠性主要受两个因素的影响:一方面受限于存储介质的可靠性;另一方面取决于系统数据保护策略(主动或被动)以及冗余布局方式。
4.1 被动容错系统可靠性预测的发展
冗余机制的研究贯穿存储技术的发展过程,研究者已经提出了很多高效的纠删码方案和副本策略,对其可靠性的研究也一直是热点方向。
4.1.1 纠删码存储系统的可靠性
20世纪90年代初,Gibson等人[23]基于硬盘故障时间服从指数分布的假设,利用马尔可夫过程构造出RAID-5和RAID-6磁盘阵列的可靠性预测模型,分析了磁盘阵列结构对系统可靠性的影响,并启发后来学者使用马尔可夫模型预测存储系统可靠性。例如,对于具有高并发性、高可扩展性、高性价比等特点的集群存储系统,章宏灿等人[24]提出了一种基于马尔可夫模型的集群RAID-5存储系统的可靠性模型,定量分析了各种系统参数对系统可靠性的影响。经过分析,他们发现多层集群RAID-5的系统可靠性比单层集群RAID-5的要高;提高硬盘/节点的重构速率可以近似等幅度地提升系统可靠性;保证系统可靠性不变的前提下,重构速率10倍的提升可以使系统对节点平均失效时间的需求降低为原来的1/7。
潜在扇区错误和静默的数据损坏是由媒介故障或软件缺陷等原因造成的块级别错误,除非有读操作尝试读取访问,否则块级别错误不会被发现。Venkatesan等人[25]通过概率分析的方式考察了潜在扇区错误对系统可靠性的影响,发现当潜在错误概率比较小时,MTTDL降低的幅度与冗余策略、校验盘格式和系统规模大小没有关系,但是当潜在错误概率比较大时,MTTDL的值类似于少用一个校验盘的无潜在错误系统的可靠性结果。其实早在新世纪初期,IBM的专家们[26]在对非MDS(maximum distance separable)编码的存储系统创建马尔可夫可靠性模型的过程中,就考虑了不可恢复的块级别错误对可靠性的影响。在接下来的工作中[27],他们提出一种硬盘内部的冗余机制IDR(intra-disk redundancy)以消除块级别错误对系统可靠性的负面影响,并使用马尔可夫模型分析了带IDR机制的RAID-5和RAID-6系统的可靠性,结果表明IDR机制可以有效增强RAID系统的可靠性。但是,因为数据存储系统广泛使用低价硬盘,导致块级别的错误数量越来越多,由IDR机制带来的可靠性提升受到不利影响。在进一步工作中[28],他们通过校正IDR机制的参数选择,在付出最小I/O性能代价的前提下,得到存储系统可靠性的最大提升。例如,带IDR的RAID-5系统的可靠性和I/O性能均优于平凡(不带IDR)RAID-6系统的性能。而且,在Thomasian等人[29]的工作中,结果同样显示增加了IDR的RAID-5系统可以达到和平凡RAID-6同等的可靠性水平。
除了IDR机制,“磁盘清洗”过程也可以有效预防块级别错误对系统可靠性的影响。Paris等人[30]研究了运行在RAID-6磁盘阵列的磁盘清洗调度问题。对于RAID-6系统,一个故障发生后,其余硬盘上的若干不可恢复的扇区错误会导致第二个硬盘故障,因此他们建议发生一个硬盘故障后应该立即启动“紧急”(加速)清洗过程。分析结果显示,无论是单独运行,还是与周期清洗结合运行,这些加速清洗都可以大大改进磁盘阵列的平均数据丢失时间。
大量的经验观察值都否定了硬盘故障指数分布的假设,认为硬盘故障和修复时间更符合韦布分布。为了摆脱硬盘故障符合指数分布的假设限制,Thomasian等人[31]使用概率分析的方法比较了不同磁盘镜像(RAID-1)组织结构的可靠性。这些磁盘阵列是由相同故障分布特征的硬盘构成。他们发现相对链式散布(chained declustering,CD)阵列、交叉散布(interleaved declustering,ID)阵列和组旋转散布(group rotate declustering,GRD)阵列,基本镜像(basic mirroring,BM)阵列能够容忍的双盘并发故障的情况最多,具有最高的可靠性。
随着可靠性研究的深入,很多研究者发现以前研究采用的评价指标——平均数据丢失时间(MTTDL),并不能准确表示存储系统的可靠性水平。比如,Paris等人[32-33]在研究硬盘故障率恒定假设对可靠性模型结果的影响时,发现由于存储系统的实际生命周期相对MTTDL短得多,MTTDL方法通常会高估系统的长期可靠性,而明显低估系统短期可靠性,因此他们建议关注存储系统有效生命周期内的可靠性。
Elerath等人[34]构建出N+1 RAID系统的非Markov模型的状态转换图,并用顺序蒙特卡罗方法模拟系统的运行,仿真出不同运行时期内系统发生数据丢失事件的期望次数。其中,硬盘故障时间、故障恢复时间、潜在扇区错误时间和磁盘清理时间都使用韦布分布,结果显示之前MTTDL模型所用的假设导致了不正确的预测结果。在接下来的工作中[35-36],他们设计了两个新的封闭公式,相对于时间开销大的可靠性仿真程序,公式可以更方便快捷地估计出RAID-5和RAID-6磁盘阵列系统发生数据丢失事件的期望次数。同时,他们也建议用其他更合理的评价指标替代MTTDL,然而这个论断遭到Iliadis等人[37]的反驳。
对于采用非MDS编码的异构存储系统,Greenan等人[38]提出了两种基于XOR纠删码的冗余散布算法,并利用他们提出的相对MTTDL估计模型,分析比较了不同冗余散布策略系统对可靠性的影响。在后来的工作[39]中,Greenan等人提出一个新的可靠性评价指标NOMDL(normalized magnitude of data loss)——某个时期内每Terabyte用户数据丢失的Byte数,可以量化单位时间内数据丢失率,相对于MTTDL,NOMDL可以更准确地评价存储系统的可靠性水平。
4.1.2 副本存储系统的可靠性
如Qin等人[40]所说,随着硬盘容量的增加,硬盘修复时间越来越长,在修复期间再次发生硬盘故障的概率会增大,RAID系统已不能提供足够的可靠性,因此近年来副本技术成为提高存储系统可靠性的主流技术之一,也涌现出一些对副本存储系统可靠性预测的研究。
相比单机系统,通过网络存储节点实现的分布式存储系统具有代价低、可扩展等优点,为了获得高可靠性,冗余必须在节点之间和节点内部散布,从而分别容忍节点和硬盘故障。Rao等人[41]分别对节点内部包含和不包含RAID冗余的分布式存储系统创建分层和递归Markov可靠性模型,分析了多种系统参数及潜在扇区错误对系统可靠性的影响。综合节点故障、数据平衡和提前拷贝因素后,Chen等人[42]构造出(brick)存储系统Markov可靠性预测模型。这个模型可以指导存储系统设计者充分利用系统资源,从而既可以减少系统构建和维护开销,又可以提高数据的可靠性。类似的,穆飞等人[43]研究了延迟失效检测对多副本存储系统可靠性的影响;张薇等人[44]使用概率方法对异构分布式存储系统可靠性进行预测;张林峰等人[45]提出基于对象粒度恢复的可靠性分析模型,分别计算了各个系统参数的独立最优值及其组合最优值。
数据副本的散布策略对副本存储系统的性能和可靠性有明显的影响。Leslie等人[46]使用组合概率分析和蒙特卡罗模拟方式评价了多种副本散布策略,包括后继散布(successor placement)、前驱散布(predecessor placement)、指针散布(finger placement)、块散布(block placement)和对称散布(symmetric placement),对系统可靠性的影响,发现块散布策略的可靠性最好。Venkatesan等人[47]通过比较聚集(clustered)和散布(declustered)策略对系统MTTDL的影响,发现聚集系统的MTTDL和节点个数成反比,而散布系统的MTTDL因重构过程的并行性并没有随着节点个数的增加而降低。而Cidon等人[48]提出介于完全聚集和完全散布两种极端策略之间的拷贝集散布(copyset replication)策略,将存储节点划分成多个等量的集合(copysets),每个数据块的所有副本只能存放到一个集合内的节点上,这样只有某个集合的全部节点同时故障才会导致数据丢失的发生。拷贝集散布策略可以降低因并发节点故障而导致的数据丢失事件的概率,从而有效提高副本系统的可靠性。
硬盘故障率呈现出典型的“浴盆曲线”特点,由于大规模存储系统可能会同时替换大量新硬盘,它们很容易引起硬盘早期失效的“群体效应”。Qin等人[49]利用隐马尔可夫模型和离散事件仿真方法研究了硬盘早期失效对大规模存储系统可靠性的影响,发现忽略硬盘早期失效会导致对系统可靠性的过高估计,而且系统规模越大,早期失效的影响越大。为了降低硬盘早期失效的影响,一方面,他们提出了两种硬盘替换策略——基于硬盘使用年限的策略和随机的逐步替换策略;另一方面,他们建议不同使用年限硬盘上的数据采用不同的冗余策略,即“年轻”硬盘上的对象采用三副本冗余,“年老”硬盘上的对象使用纠删码冗余。另外,Venkatesan等人[50]考虑节点故障和修复时间非指数分布的通用情况,使用概率方法推导出副本系统的MTTDL,发现重构分布可变性高的系统具有较低的MTTDL。
4.1.3 特殊存储系统的可靠性
大型归档存储系统中的硬盘长期保持关机状态,多种原因(包含设备级别和块级别的故障)会导致这些系统丢失数据。Schwarz等人[51]建议归档存储系统中运行一个“磁盘清洗”过程,定期访问硬盘以检查硬盘故障。他们分析了磁盘清洗过程对大型归档存储系统的影响,显示清洗对长期数据的保存很重要,而且相对于“随机”(random)和“确定”(deterministic)清洗策略,“伺机”(opportunistic)清洗策略(即只有当硬盘处于开机状态时才对它们进行清洗)效果最好。后来,Paris等人[52]针对归档存储系统设计了一个二维RAID架构,即增加一个超级校验盘存放所有行/列校验盘的异或结果。实验表明,增加超级校验盘可以大大提高系统的MTTDL,而且修复时间越短,可靠性的提升越明显。
另外,针对归档存储系统,Li等人[53]提出一个框架来关联数据生存能力和存储可靠性,并用来测量较少发生但是规模很大的事件对数据长期生存能力的影响,以此定量研究存储在地理位置分散的异构存储系统上数据对象的生存能力。他们发现以前存储模型忽略的一些较少发生事件,比如地震,对数据生存能力具有真正的影响。甚至在一个中等使用年限的系统中,新设备的替换也会对数据的生存能力产生影响。
空间利用率和数据可靠性是当代存储系统关注的两个主要问题,重复数据删除技术(deduplication)实现数据对象或块在文件之间的共享,在节省系统存储空间的同时,对系统可靠性也产生了一定影响。Bhagwat等人[54]提出一个提高重复数据删除系统可靠性的策略,即根据块故障导致丢失的数据量多少确定数据块的副本个数,相比传统的副本和压缩技术组合的方法,该技术可以达到更高的系统稳健性(权衡丢失的数据量),而且还能减少一半的存储开销。Li等人[55]呈现了一个使用纠删码冗余机制保证数据可靠性的重复数据删除存储系统HPKVS。该系统允许每个对象指定自己的可靠性水平,为系统设计者提供了一个可靠性分析方法,能够确定在什么情况下重复数据删除技术,既可以节省存储空间,又不降低可靠性水平。
对于一个在异构存储硬件上存放异构数据的重复数据删除系统,Rozier等人[56]利用离散事件仿真方法定量分析了系统的可靠性,发现大规模重复数据删除系统可靠性受到重复数据删除技术的负面影响。然而在他们的后期工作[57]中,发现在重复引用更均匀散布的系统中,重复数据删除技术反而提高了系统可靠性。
4.2 主动容错系统可靠性预测的发展
相对被动容错技术,主动容错技术发展较晚,2000年后才开始被研究者关注,还没有被广泛应用到实际存储系统中。故障预测模型并不能保证100%的预测准确性,仍然会有一些硬盘漏报或者没有被及时修复,真正发生了故障,因此主动容错技术不能完全避免存储系统的故障,需要结合相应的被动容错技术共同保证系统的可靠性,从而主动容错存储系统的可靠性研究比较复杂。
目前,针对主动容错存储可靠性评价的研究相对较少,Eckart等人[58]利用马尔可夫模型研究了主动容错机制对单硬盘以及RAID-5阵列存储系统可靠性的影响。实验表明,具有50%预测准确率的故障预测模型可以将一个RAID-5系统的MTTDL提高近3倍。作者前期工作将此研究推广到RAID-6阵列系统[11]和副本存储系统[59],实验结果表明,提出的决策树预测模型可以将存储系统的可靠性提高几个数量级。
4.3 存储系统可靠性预测发展总结
为了更清晰地描述存储系统可靠性预测发展状况,表2总结了当前存储系统可靠性预测国内外研究进展。“特殊系统”表示一些有特殊用处(如归档存储系统)或采用特殊技术(如重复数据删除系统)的存储系统。针对各种系统,“指数分布假设”列出基于硬盘故障时间指数分布假设的可靠性研究文献;“块故障影响”列出考察了潜在扇区错误等块级别的故障对系统可靠性影响的文献;“非指数/韦布分布”列出不再受限于硬盘故障指数分布假设限制,或者使用韦布分布等更接近实际的分布描述硬盘故障时间的文献;“新评价指标”列出不再使用MTTDL作为评价可靠性的指标,而是使用一段时间内数据丢失事件期望个数等新评价指标的文献。
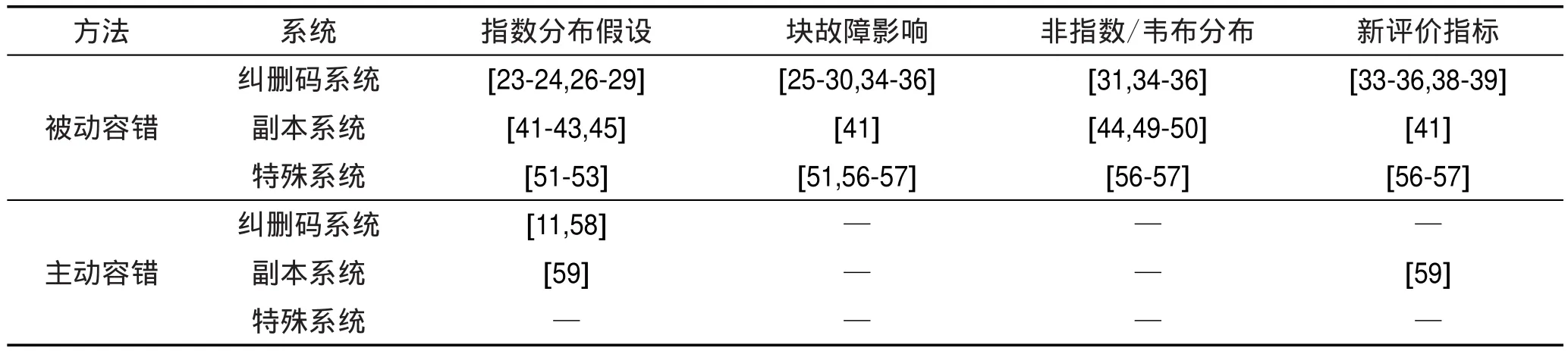
Table 2 Current state of research on storage system reliability prediction表2 国内外存储系统可靠性预测研究现状
5 尚存问题
本章对存储系统可靠性预测领域一些尚未解决的重要科学问题进行分析,并指出未来的研究方向。
5.1 硬盘故障预测模型的评价指标
当前已有的硬盘故障预测模型大都是简单的二元分类器,只能给出是/否的预测结果,对它们的评价指标是基于FDR和FAR的预测准确率。一些最近的研究工作尝试预测硬盘的剩余寿命,预警处理算法就可以根据它们的预测结果,为预警硬盘分配适当的带宽,在保护危险数据的同时,最大限度保证用户的服务质量。对这些模型的评价指标仍是基于分类准确性:将剩余寿命划分为多个区间,用落到准确区间的预测比例评价模型的预测准确率。
总之,目前用于评价硬盘故障预测模型的评价指标都只孤立地关注预测模型本身,而未考虑预测模型和它们实际应用场景——存储系统,尤其是云存储系统之间的关系。这些研究都是假设在其他条件都保持不变的前提下,高的预测准确率可以带来大的收益。但实际上,提高预测准确率一般会导致其他性能的下降,比如提前预警时间(TIA)。例如,可以将一个预测模型的准确率提高到100%,但却要付出TIA减少到1小时的代价。这种情况下,即使所有危险硬盘被提前预测出来,也会由于缺少足够的可用资源而不能将处于危险中的数据及时迁移完毕。因此,预测准确率不能完全反映硬盘故障预测模型的最终目标(保护数据,而不只是预测出硬盘故障)。
硬盘故障预测的根本目的是防止数据丢失,这不仅需要准确预测出哪些硬盘将要故障,还需要在故障真正发生前完成数据迁移。为了创建更实用的硬盘故障预测模型,对它们的评价指标也需要考虑预警迁移的完成情况。另外,目前已有的硬盘剩余寿命预测模型的性能还不理想。因此,更有意义的评价指标和高性能的硬盘剩余寿命预测模型是硬盘个体可靠性预测领域需要解决的问题。
5.2 主动容错存储系统的可靠性评价
目前对主动容错存储系统的可靠性研究很是匮乏,仅限于利用马尔可夫模型,基于硬盘故障泊松分布假设,对RAID-5/6和二/三副本存储系统的可靠性进行预测。这些已有的研究存在以下几个缺陷:
(1)不准确的故障分布假设。现有研究对可靠性的估计都是基于硬盘故障发生和修复服从指数分布的假设,在此假设下硬盘具有恒定不变的故障率和修复率,但是大量领域数据的分析结果以高置信度推翻了指数分布假设。
(2)故障类型考虑不全。现有研究只关注了硬盘整体故障,而忽略了潜在扇区错误等扇区或块级别的错误对系统可靠性的影响。
(3)不准确的可靠性度量指标。现有研究主要是用系统平均数据丢失时间(MTTDL)作为可靠性的评价指标,然而MTTDL相对于系统实际运行时间很长,并不能准确反映存储系统的可靠性水平。
因此,使用更接近实际的硬盘故障分布数据,综合考虑各种故障类型,对主动容错存储系统的可靠性预测也是未来需要重点研究的方向。
5.3 系统级动态故障预测
随着云计算的发展,存储系统的架构已经从传统磁盘阵列演进到云存储,存储组织和冗余布局也从设备(硬盘)视角变为数据(文件、对象)视角。但现有硬盘故障预测方法都只是一种设备视角的可靠性动态评价,即孤立地给出硬盘个体的健康或潜在故障的评级,并未考虑其对系统(数据)可靠性的影响。
例如,对于一个预警硬盘,如果它所属于的某些校验组(RAID校验组或副本散布集合)已经处于降级模式,只要再发生一个故障就会出现数据丢失,那么该预警硬盘的健康状况对系统可靠性的影响非常大;相反,如果它所属于的所有校验组都处于完全健康运行的模式下,可以容忍一个故障发生而不产生数据丢失,那么该预警盘的健康状况对系统可靠性的影响比较小。
因此,有效保障云存储系统数据安全的故障预测,不仅要基于硬盘个体的实时健康度评价,更要结合硬盘在系统冗余布局中的角色,综合评价硬盘潜在故障对系统(亦即数据——文件、对象)可靠性的影响(高低),作为预警处理的量化依据。
6 总结
随着计算机技术以及信息技术的快速发展,数据中心的数据越来越多,因此带来存储系统可靠性和可用性的巨大挑战。为了构建高可靠和高可用的存储系统,系统设计者以及存储领域研究者越来越关注存储系统可靠性预测研究。本文从存储介质和存储系统两种不同预测对象角度,介绍了可靠性预测的度量指标以及当前研究的进展,并根据目前该领域存在的一些问题指出未来研究的方向。
[1]Luo Xianghong,Shu Jiwu.Summary of research for erasure code in storage system[J].Journal of Computer Research and Development,2012,49(1):1-11.
[2]Murray J F,Hughes G F,Kreutz-Delgado K.Machine learning methods for predicting failures in hard drives:a multipleinstance application[J].Journal of Machine Learning Research,2005,6(1):783-816.
[3]Schroeder B,Gibson G A.Disk failures in the real world: what does an MTTF of 1,000,000 hours mean to you?[C]// Proceedings of the 5th USENIX Conference on File and Storage Technologies,San Jose,USA,Feb 13-16,2007.Berkeley,USA:USENIXAssociation,2007:1-16.
[4]Hamerly G,Elkan C.Bayesian approaches to failure prediction for disk drives[C]//Proceedings of the 18th International Conference on Machine Learning,Williamstown,USA,Jun 28-Jul 1,2001.San Mateo,USA:Morgan Kaufmann,2001: 202-209.
[5]Hughes G F,Murray J F,Kreutz-Delgado K,et al.Improved disk-drive failure warnings[J].IEEE Transactions on Reliability,2002,51(3):350-357.
[6]Murray J F,Hughes G F,Kreutz-Delgado K.Hard drive failure prediction using non-parametric statistical methods[C]// Proceedings of the 2003 International Conference of Artificial Neural Networks and Neural Information,Istanbul,Turkey,Jun 26-29,2003.Berlin,Heidelberg:Springer,2003.
[7]Zhao Ying,Liu Xiang,Gan Siqing,et al.Predicting disk failures with HMM-and HSMM-based approaches[M]//Advances in Data Mining Applications and Theoretical Aspects.Berlin,Heidelberg:Springer,2010:390-404.
[8]Wang Yu,Miao Qiang,Pecht M.Health monitoring of hard disk drive based on Mahalanobis distance[C]//Proceedings of the 2011 Prognostics and System Health Management Conference,Shenzhen,China,May 24-25,2011.Washington:IEEE Computer Society,2011:1-8.
[9]Wang Yu,Miao Qiang,Ma E W M,et al.Online anomaly detection for hard disk drives based on Mahalanobis distance[J].IEEE Transactions on Reliability,2013,62(1): 136-145.
[10]Zhu Bingpeng,Wang Gang,Liu Xiaoguang,et al.Proactive drive failure prediction for large scale storage systems[C]// Proceedings of the 29th IEEE Symposium on Mass Storage Systems and Technologies,Lake Arrowhead,USA,May 6-10,2013.Washington:IEEE Computer Society,2013:1-5.
[11]Li Jing,Ji Xinpu,Jia Yuhan,et al.Hard drive failure prediction using cassification and regression trees[C]//Proceedings of the 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks,Atlanta,USA, Jun 23-26,2014.Washington:IEEE Computer Society, 2014:383-394.
[12]Xu Chang,Wang Gang,Liu Xiaoguang,et al.Health status assessment and failure prediction for hard drives with recurrent neural networks[J].IEEE Transactions on Computers, 2016,65(11):3502-3508.
[13]Pang Shuai,Jia Yuhan,Stones R,et al.A combined Bayesian network method for predicting drive failure times from SMART attributes[C]//Proceedings of the 2016 International Joint Conference on Neural Networks,Vancouver,Canada, Jul 24-29,2016.Piscataway,USA:IEEE,2016:4850-4856.
[14]Vishwanath K V,Nagappan N.Characterizing cloud computing hardware reliability[C]//Proceedings of the 1st ACM Symposium on Cloud Computing,Indianapolis,USA,Jun 10-11,2010.New York:ACM,2010:193-204.
[15]Sankar S,Shaw M,Vaid K.Impact of temperature on hard disk drive reliability in large datacenters[C]//Proceedings of the 41st International Conference on Dependable Systems &Networks,Hong Kong,China,Jun 27-30,2011.Washington:IEEE Computer Society,2011:530-537.
[16]Gibson G A.Redundant disk arrays:reliable,parallel secondary storage[M].Cambridge,USA:MTT Press,1992.
[17]Ma Ao,Douglis F,Lu Guanlin,et al.RAIDShield:characterizing,monitoring,and proactively protecting against disk failures[C]//Proceedings of the 13th USENIX Conference on File and Storage Technologies,Santa Clara,USA,Feb 16-19, 2015.Berkeley,USA:USENIXAssociation,2015:241-256.
[18]Bairavasundaram L N,Goodson G R,Pasupathy S,et al. An analysis of latent sector errors in disk drives[J].ACMSIGMETRICS Performance Evaluation Review,2007,35 (1):289-300.
[19]Bairavasundaram L N,Arpaci-Dusseau A C,Arpaci-Dusseau R H,et al.An analysis of data corruption in the storage stack [J].ACM Transactions on Storage,2008,4(3):1-28.
[20]Shah S,Elerath J G.Reliability analysis of disk drive failure mechanisms[C]//Proceedings of the 2005 Annual Symposium on Reliability and Maintainability,Jan 24-27,2005. Piscataway,USA:IEEE,2005:226-231.
[21]Pinheiro E,Weber W D,Barroso L A.Failure trends in a large disk drive population[C]//Proceedings of the 5th USENIX Conference on File and Storage Technologies, San Jose,USA,Feb 13-16,2007.Berkeley,USA:USENIX Association,2007:17-29.
[22]El-Sayed N,Stefanovici I A,Amvrosiadis G,et al.Temperature management in data centers:why some(might)like it hot[J].ACM SIGMETRICS Performance Evaluation Review,2012,40(1):163-174.
[23]Gibson G A,Patterson D A.Designing disk arrays for high data reliability[J].Journal of Parallel and Distributed Computing,1993,17(1):4-27.
[24]Zhang Hongcan,Xue Wei.Reliability analysis of cluster RAID5 storage system[J].Journal of Computer Research and Development,2010,47(4):727-735.
[25]Venkatesan V,Iliadis I.Effect of latent errors on the reliability of data storage systems[C]//Proceedings of the 21st International Symposium on Modeling,Analysis&Simulation of Computer and Telecommunication Systems,San Francisco, USA,Aug 14-16,2013.Washington:IEEE Computer Society,2013:293-297.
[26]Hafner J L,Rao K K.Notes on reliability models for non-MDS erasure codes,RJ10391[R].IBM Research,2006.
[27]Dholakia A,Eleftheriou E,Hu Xiaoyu,et al.A new intradisk redundancy scheme for high-reliability RAID storage systems in the presence of unrecoverable errors[J].ACM Transactions on Storage,2008,4(1):373-374.
[28]Iliadis I,Hu Xiaoyu.Reliability assurance of RAID storage systems for a wide range of latent sector errors[C]//Proceedings of the 2008 International Conference on Networking, Architecture,and Storage,Chongqing,China,Jun 12-14, 2008.Washington:IEEE Computer Society,2008:10-19.
[29]Thomasian A,Blaum M.Higher reliability redundant disk arrays:organization,operation,and coding[J].ACM Transactions on Storage,2009,5(3):7.
[30]Pâris J F,Schwarz S J,Amer A,et al.Improving disk array reliability through expedited scrubbing[C]//Proceedings of the 5th International Conference on Networking,Architecture and Storage,Macau,China,Jul 15-17,2010.Washington:IEEE Computer Society,2010:119-125.
[31]Thomasian A,Blaum M.Mirrored disk organization reliability analysis[J].IEEE Transactions on Computers,2006, 55(12):1640-1644.
[32]Pâris J F,Thomas J E,Schwarz S J.On the possibility of small,service-free disk based storage systems[C]//Proceedings of the 3rd International Conference on Availability, Reliability and Security,Barcelona,Spain,Mar 4-7,2008. Washington:IEEE Computer Society,2008:56-63.
[33]Pâris J F,Schwarz T J E,Long D D E,et al.When MTTDLs are not good enough:providing better estimates of disk array reliability[C]//Proceedings of the 7th International Information and Telecommunication Technologies Symposium,Bahia,Brazil,Dec 26-30,2008.Piscataway,USA:IEEE, 2008:140-145.
[34]Elerath J G,Pecht M.Enhanced reliability modeling of RAID storage systems[C]//Proceedings of the 37th Annual IEEE/ IFIP International Conference on Dependable Systems and Networks,Edinburgh,UK,Jun 25-28,2007.Washington: IEEE Computer Society,2007:175-184.
[35]Elerath J G.A simple equation for estimating reliability of anN+1 redundant array of independent disks(RAID)[C]// Proceedings of the 2009 IEEE/IFIP International Conference on Dependable Systems&Networks,Lisbon,Portugal,Jun 29-Jul 2,2009.Washington:IEEE Computer Society,2009:484-493.
[36]Elerath J G,Schindler J.Beyond MTTDL:a closed-form RAID 6 reliability equation[J].ACM Transactions on Storage,2014,10(2):193-206.
[37]Iliadis I,Venkatesan V.Rebuttal to“beyond MTTDL:aclosedform RAID-6 reliability equation”[J].ACM Transactions on Storage,2015,11(2):1-10.
[38]Greenan K M,Miller E L,Wylie J J.Reliability of flat XOR-based erasure codes on heterogeneous devices[C]// Proceedings of the 2008 IEEE International Conference on Dependable Systems and Networks,Anchorage,USA,Jun 24-27,2008.Washington:IEEE Computer Society,2008: 147-156.
[39]Greenan K M,Plank J S,Wylie J J.Mean time to meaningless:MTTDL,Markov models,and storage system reliability [C]//Proceedings of the 2nd USENIX Workshop on Hot Topics in Storage and File Systems,Boston,USA,Jun 22-25,2010.Berkeley,USA:USENIXAssociation,2010:5.
[40]Qin Xin,Miller E L,Schwarz T,et al.Reliability mechanisms for very large storage systems[C]//Proceedings of the 20th IEEE/11th NASA Goddard Conference on Mass Storage Systems and Technologies,San Diego,USA,Apr 7-10, 2003.Washington:IEEE Computer Society,2003:146-156.
[41]Rao K K,Hafner J L,Golding R.Reliability for networked storage nodes[C]//Proceedings of the 2006 International Conference on Dependable Systems and Networks,Sheraton Society Hill,USA,Jun 25-28,2006.Washington:IEEE Computer Society,2006:237-248.
[42]Chen Ming,Chen Wei,Liu Likun,et al.An analytical framework and its applications for studying brick storage reliability[C]//Proceedings of the 26th IEEE International Symposium on Reliable Distributed Systems,Beijing,Oct 10-12,2007.Washington:IEEE Computer Society,2007: 242-252.
[43]Mu Fei,Xue Wei,Shu Jiwu,et al.An analytical model for large-scale storage system with replicated data[J].Journal of Computer Research and Development,2009,46(5):756-761.
[44]Zhang Wei,Ma Jianfeng,Yang Xiaoyuan.Reliability of distributed storage systems[J].Journal of Xidian University, 2009,36(3):480-485.
[45]Zhang Linfeng,Tan Xiangjian,Du Kai.Optimal reliability analysis for large scale storage systems[J].Computer Engineering andApplications,2013,49(1):112-119.
[46]Leslie M,Davies J,Huffman T.A comparison of replication strategies for reliable decentralised storage[J].Journal of Networks,2006,1(6):36-44.
[47]Venkatesan V,Iliadis I,Fragouli C,et al.Reliability of clustered vs.declustered replica placement in data storage systems[C]//Proceedings of the 19th International Symposium on Modeling,Analysis and Simulation of Computer and Telecommunication Systems,Singapore,Jul 25-27,2011. Washington:IEEE Computer Society,2011:307-317.
[48]Cidon A,Rumble S M,Stutsman R,et al.Copysets:reducing the frequency of data loss in cloud storage[C]//Proceedings of the USENIX Annual Technical Conference,San Jose, USA,Jun 26-28,2013.Berkeley,USA:USENIX Association,2013:37-48.
[49]Qin Xin,Schwarz T J E,Miller E L.Disk infant mortality in large storage systems[C]//Proceedings of the 13th IEEE International Symposium on Modeling,Analysis and Simulation of Computer and Telecommunication Systems,Atlanta,USA,Sep 27-29,2005.Washington:IEEE Computer Society,2005:125-134.
[50]Venkatesan V,Iliadis I.A general reliability model for data storage systems[C]//Proceedings of the 9th International Conference on Quantitative Evaluation of Systems,London,Sep 17-20,2012.Washington:IEEE Computer Society,2012:209-219.
[51]Schwarz T J E,Qin Xin,Miller E L,et al.Disk scrubbing in large archival storage systems[C]//Proceedings of the 12th Annual International Symposium on Modeling,Analysis and Simulation of Computer and Telecommunications Systems,Volendam,The Netherlands,Oct 4-8,2004.Washington:IEEE Computer Society,2004:409-418.
[52]Paris J F,Schwarz S J,Amer A,et al.Highly reliable twodimensional RAID arrays for archival storage[C]//Proceedings of the 31st International Performance Computing and Communications Conference,Austin,USA,Dec 1-3,2012. Washington:IEEE Computer Society,2012:324-331.
[53]Li Yan,Miller E L,Long D D E.Understanding data survivability in archival storage systems[C]//Proceedings of the 5th Annual International Systems and Storage Conference, Haifa,Israel,Jun 4-6,2012.New York:ACM,2012:1-12.
[54]Bhagwat D,Pollack K,Long D D E,et al.Providing high reliability in a minimum redundancy archival storage system[C]//Proceedings of the 14th IEEE International Symposium on Modeling,Analysis and Simulation of Computer and Telecommunication Systems,Monterey,USA,Sep 11-14, 2006.Washington:IEEE Computer Society,2006:413-421.
[55]Li Xiaozhou,Lillibridge M,Uysal M.Reliability analysis of deduplicated and erasure-coded storage[J].ACM SIGMETRICS Performance Evaluation Review,2011,38(3):4-9.
[56]Rozier E W D,Sanders W H,Zhou P,et al.Modeling the fault tolerance consequences of deduplication[C]//Proceedings of the 30th IEEE Symposium on Reliable Distributed Systems,Madrid,Spain,Oct 4-7,2011.Washington:IEEE Computer Society,2011:75-84.
[57]Rozier E W D,Sanders W H.A framework for efficient evaluation of the fault tolerance of deduplicated storage sys-tems[C]//Proceedings of the 42nd Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Boston,USA,Jun 25-28,2012.Washington:IEEE Computer Society,2012:1-12.
[58]Eckart B,Chen Xin,He Xubin,et al.Failure prediction models for proactive fault tolerance within storage systems [C]//Proceedings of the 2008 IEEE International Symposium on Modeling,Analysis and Simulation of Computers and Telecommunication Systems,Baltimore,USA,Sep 8-10,2008.Washington:IEEE Computer Society,2008:1-8.
[59]Li Jing,Li Mingze,Wang Gang,et al.Global reliability evaluation for cloud storage systems with proactive fault tolerance[C]//LNCS 9531:Proceedings of the 15th International Conference on Algorithms and Architectures for Parallel Processing,Zhangjiajie,China,Nov 18-20,2015.Berlin,Heidelberg:Springer,2015:189-203.
附中文参考文献:
[1]罗象宏,舒继武.存储系统中的纠删码研究综述[J].计算机研究与发展,2012,49(1):1-11.
[24]章宏灿,薛巍.集群RAID5存储系统可靠性分析[J].计算机研究与发展,2010,47(4):727-735.
[43]穆飞,薛巍,舒继武,等.一种面向大规模副本存储系统的可靠性模型[J].计算机研究与发展,2009,46(5):756-761.
[44]张薇,马建峰,杨晓元.分布式存储系统的可靠性研究[J].西安电子科技大学学报,2009,36(3):480-485.
[45]张林峰,谭湘键,杜凯.大规模存储系统可靠性参数最优化分析[J].计算机工程与应用,2013,49(1):112-119.

LI Jing was born in 1982.She received the Ph.D.degree from College of Computer and Control Engineering,Nankai University in 2016.Now she is a lecturer at Civil Aviation University of China.Her research interests include mass data storage and machine learning,etc.
李静(1982—),女,山东德州人,2016年于南开大学计算机与控制工程学院获得博士学位,现为中国民航大学讲师,主要研究领域为大规模数据存储,机器学习等。

WANG Gang was born in 1974.He received the Ph.D.degree in computer science from Nankai University in 2002. Now he is a professor and Ph.D.supervisor at Nankai University,and the member of CCF.His research interests include storage systems and parallel computing,etc.
王刚(1974—),男,北京人,2002年于南开大学获得博士学位,现为南开大学教授、博士生导师,CCF会员,主要研究领域为存储系统,并行计算等。

LIU Xiaoguang was born in 1974.He received the Ph.D.degree in computer science from Nankai University in 2002.Now he is a professor and Ph.D.supervisor at Nankai University,and the senior member of CCF.His research interests include parallel computing and storage systems,etc.
刘晓光(1974—),男,河北人,2002年于南开大学获得博士学位,现为南开大学教授、博士生导师,CCF高级会员,主要研究领域为并行计算,存储系统等。

LI Zhongwei was born in 1975.He received the Ph.D.degree in computer science and technology from Harbin Engineering University in 2006.Now he is an associate professor and M.S.supervisor at Nankai University,and the member of CCF.His research interests include machine learning and mass data storage,etc.
李忠伟(1975—),男,甘肃人,2006年于哈尔滨工程大学获得博士学位,现为南开大学副教授、硕士生导师, CCF会员,主要研究领域为机器学习,大规模数据存储等。
Review of Reliability Prediction for Storage System*
LI Jing1,2,WANG Gang2,LIU Xiaoguang2,LI Zhongwei2+
1.College of Computer Science and Technology,CivilAviation University of China,Tianjin 300300,China
2.College of Computer and Control Engineering,Nankai University,Tianjin 300350,China
+Corresponding author:E-mail:lizhongwei@nbjl.nankai.edu.cn
The reliability prediction for storage system,which is useful to assess trade-offs,compare schemes and estimate the effect of several parameters on storage system reliability,can help system designers and administrators to build storage systems with high reliability.So the research on reliability prediction is always one of the research focuses in storage system.This paper makes careful introduction and analysis in the field of reliability prediction for storage system,respectively from two prediction objects—disk and storage system.Firstly,this paper carefully analyzes the current development status of storage system reliability prediction,from the perspectives of two objects—disk individual and disk family,two fault tolerant manners—proactive fault tolerant scheme and reactive fault tolerant scheme,and two redundant mechanisms—erasure code and replication.Then,this paper indicates the unresolved problems and the future trend in this field.From the analysis,this paper finds there are some weaknesses and drawbacks on the reliability prediction for replication storage and proactive fault tolerant systems,and they are the issues needing further study.
10.3778/j.issn.1673-9418.1604049
A
:TP301
*The National Natural Science Foundation of China under Grant Nos.61373018,11301288,11450110409(国家自然科学基金);the New Century Excellent Talent Foundation from MOE of China under Grant No.NCET-13-0301(教育部新世纪优秀人才支持计划);the Fundamental Research Funds for the Central Universities of China under Grant No.65141021(中央高校基本科研业务费专项资金).
Received 2016-04,Accepted 2016-07.
CNKI网络优先出版:2016-07-01,http://www.cnki.net/kcms/detail/11.5602.TP.20160701.1646.010.html
LI Jing,WANG Gang,LIU Xiaoguang,et al.Review of reliability prediction for storage system.Journal of Frontiers of Computer Science and Technology,2017,11(3):341-354.
Key words:storage system;reliability prediction;proactive fault tolerant;reactive fault tolerant
