核典型关联性分析相关特征提取与核逻辑斯蒂回归域自适应学习
2017-01-10刘建伟孙正康刘泽宇罗雄麟
刘建伟,孙正康,刘泽宇,罗雄麟
(1.中国石油大学(北京)自动化系,北京 102249;2.中国科学院软件研究所基础软件国家工程研究中心,北京 100190)
核典型关联性分析相关特征提取与核逻辑斯蒂回归域自适应学习
刘建伟1,孙正康1,刘泽宇2,罗雄麟1
(1.中国石油大学(北京)自动化系,北京 102249;2.中国科学院软件研究所基础软件国家工程研究中心,北京 100190)
本文提出了一种利用核典型关联性分析提取源域目标域最大相关特征,使用核逻辑斯蒂回归模型进行域自适应学习的算法,该算法称为KCCA-DAML(Kernel Canonical Correlation Analysis for Domain Adaptation Learning).该算法基于特征集关联性分析,有效的减小源域和目标域的概率分布差异性,利用提取的最大相关特征通过核逻辑斯蒂回归模型实现源域到目标域的跨域学习.实验比较源域数据上核逻辑斯蒂学习模型、目标域上核逻辑斯蒂学习模型 、源域和目标域上核逻辑斯蒂学习模型和KCCA-DAML模型,结果显示KCCA-DAML在真实数据集上成功的实现了跨域学习.
域自适应;概率分布差异;相关分析;核逻辑斯蒂回归;正则化模型
1 引言
机器学习任务中,假定训练样例-标签对组成的样本集和测试样例-标签对组成的样本集通常来自同一概率分布,这是保证良好学习性能的基本假设.但在现实应用中,这种假设过于“严苛”,具有很大的局限性.我们经常遇到训练样例-标签对组成的样本集与测试样例-标签对组成的样本集概率分布不一致的情况,例如命名实体识别(Named Entity Recognition,NER)中的文本标注问题就是一种经典的域自适应学习问题.
迁移学习中,假定源域与目标域输入样例的概率分布是一样的,存在多个标签输出预测函数,而域自适应学习做相反的假设,即假定源域与目标域样例标签预测函数相同,源域与目标域输入样例的概率分布不一样.域自适应学习通过已知源域信息对于未知目标域进行信息处理和挖掘.目前关于域自适应学习产生了大量的理论研究成果,例如文献[1]对统计分类中的域自适应学习进行了综述;文献[2~4]对域自适应学习的各种误差界理论进行了讨论;文献[5~7]围绕域自适应核学习方法进行了研究和改进;文献[8~12]对多源域自适应学习问题进行了分析和讨论.
域自适应学习算法形式多样[13~15],如核映射函数法、结构对应学习、维数约简与协同聚类和迁移分量分析.其中核映射函数法应用更为普遍,与域自适应学习正则化技术关联紧密.找到合适的域自适应学习特征表示需要引入跨域数据依赖正则化项对新的特征空间进行约束.域自适应学习研究的重点和热点是提出全新的域分布偏差度量判据和高效的域自适应学习算法.基于特征表示的域自适应学习是当前使用最为广泛的域自适应学习方法,通过将源域和目标域数据映射到新的特征空间中,使源域与目标域的概率分布在新的特征空间下足够接近.
本文提出的核典型关联性分析域自适应学习 (Kernel Canonical Correlation Analysis for Domain Adaptation Learning,KCCA-DAML)的主要观点是将源域和目标域的样本映射到再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS)中,保证源域和目标域在新的特征空间下线性可分,同时引入KCCA约束,使核空间下源域分布和目标域分布的相关性最大化,域自适应学习场景下,若两领域相关,则两域分布足够靠近,进而实现源域学习模型适应于目标域学习模型.
在Reuters 20 Newsgroups数据集、MNIST手写数字识别数据集和UCI Dermatology数据集上进行了实验.针对四种不同分类模型,比较分析了影响域自适应学习任务有效实现的各种因素和参数选择问题.实验结果表明KCCA-DAML通过对源域学习模型进行分布偏差修正,使源域学习模型逐渐迁移为目标域学习模型,能够通过最大化源域和目标域的特征相关性,保证了源域概率分布和目标域概率分布的差异性足够小,实现跨域学习.
2 基本学习模型
源域样本集DS={(xS,1,yS,1),…,(xS,n,yS,n)},由源域样例集XS={xS,1,…,xS,n}⊂Rn×d和源域类标签集YS={yS,1,…,yS,n}⊂Rn×1组成,其中每个样例包含d维特征xS,i∈Rd,对应类标签yS,i∈{+1,-1}.目标域样本集分为少量已标识样本DLT={(xT,1,yT,1),…,(xT,m,yT,m)}和大量未标识样例DUT={(xT,m+1,?),…,(xT,n,?)},其中每个样例包含d维特征xT,i∈Rd,对应未知类标签为yT,i∈{+1,-1}.
域自适应分类任务的目的是利用源域已标识样本DS,目标域少量已标识样本DLT和大量未标识样例XUT,学习一个模型能够准确地对目标域未标识样例集DUT分配类标签.即学习判别函数f=sign(wTxi):X→Y,预测每个目标域未标识样例XUT的类标签YUT,其中非线性映射函数φ:X→H将样例映射到特定特征空间,增广权向量w=(w1,…,wd)T∈Rd是确定分类平面的特征空间向量.
逻辑斯蒂模型为机器学习中常用的分类模型,逻辑斯蒂分类模型为如下无约束优化问题:
(1)
其中σ(z)=ln(1+exp(-z)),对于给定的样例xi∈Rd,使用相应的逻辑斯蒂模型,能够得到如下的逻辑斯蒂分类器:
yi=sign(wTxi)
(2)
其中定义符号函数:
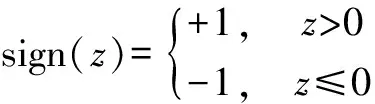
(3)
逻辑斯蒂模型置信度为:
(4)
域自适应学习的基本观点在于充分利用源域大量先验信息,并通过源域和目标域的偏差度量判据约束解空间,使学习得到的分类判别函数f(x,y;w)由源域判别函数fS(x,y;wS)逐步转变为目标域判别函数fT(x,y;w).
定义核矩阵:
(5)
核映射:
φ:XS={xS,1,…,xS,n}→φ(XS)=[φ(xS,1),…,φ(xS,n)]
(6)
学习判别函数:
f=sign(wTφ(xi)):X→Y
(7)
源域核逻辑斯蒂分类模型为:
(8)
其中kS,i=[k(xS,i,xS,1),…,k(xS,i,xS,n)]=[kS,i,1,…,kS,i,n].
目标域核逻辑斯蒂分类模型为:
(9)
其中kT,i=[k(xT,i,xT,1),…,k(xT,i,xT,n)]=[kT,i,1,…,kT,i,n].
3 KCCA-DAML模型
源域和目标域之间存在差异性导致源域逻辑斯蒂分类模型并不能很好的适用于目标域学习任务.需要引入跨域数据依赖正则化项约束逻辑斯蒂分类模型的解空间,将数据嵌入到再生核希尔伯特核空间中,通过最小化源域和目标域的最大分布偏差,保证源域和目标域足够邻近,使源域和目标域在RKHS中具有相近的概率分布,解决跨领域学习问题.
当前域自适应学习常用的分布偏差度量为基于均值的偏差度量判据(Maximum Mean Discrepancy,MMD),是一种较为简单直观的度量判据.但是,仅从均值特征来描述变量差异性并不能充分挖掘特征变量的差异性.典型相关分析(Canonical Correlation Analysis,CCA)是一种分析多变量相关性的有效方法.典型相关分析由Hotelling首次提出[16],并研究了两组变量之间的相关系数.用单变量Pearson系数难以从整体描述两组多变量之间的关联程度,而CCA很好的解决了这一问题.
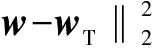
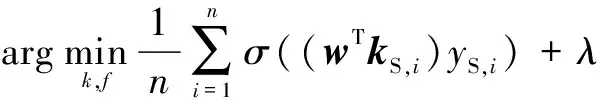
(10)
(11)
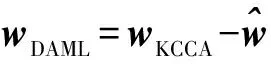
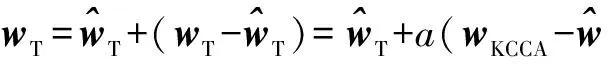
KCCA数据依赖正则化项为:
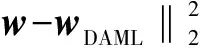
(12)
得到KCCA-DMAL学习模型:
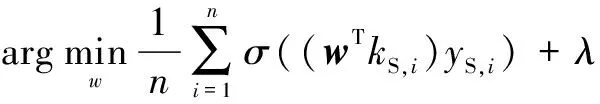
(13)
4 KCCA偏差度量判据
经过核映射后源域判别函数fS=φ(wS)Tφ(XS)和目标域判别函数fT=φ(wT)Tφ(XT)相关性较高,则能实现源域到目标域的迁移学习,fS与fT相关性越高,迁移学习效果越好.
使用标准CCA[16]对源域和目标域进行关联性分析,对域的样本进行归一化,其中源域样本:
DS={(xS,1,yS,1),…,(xS,n,yS,n)}
(14)
目标域样本:
DT=({xT,1,yT,1),…,(xT,m,yT,m),(xT,m+1,?),…,(xT,n,?)}
(15)
定义如下向量运算:
(16)
(17)
最大化源域和目标域关联性:
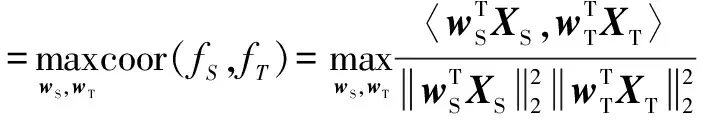
(18)
其中,w1,w2为d×1维列向量,XS,XT分别为源域和目标域的d×n维样例矩阵,〈xS,xT〉表示向量内积运算,CST表示源域样例xS与目标域样例xT的协方差矩阵,CSS为源域样例xS的方差矩阵,CTT为目标域样例xT的方差矩阵.
定义核函数:K(xS,xT)=〈φ(xS),φ(xT)〉,则式(18)变为:
(19)
其中KS为源域样本数据核矩阵,KT为目标域样本数据核矩阵.
通过求解式(8)得到核空间下源域分类向量wS,故域自适应的KCCA求解与普通KCCA求解稍有不同,即wS已知.
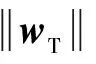
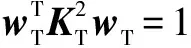
(20)
引入a≥0,式(20)表示为无约束形式:
(21)
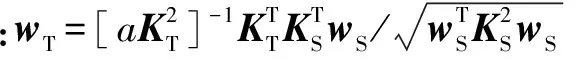
5 KCCA-DAML模型求解
KCCA-DAML模型的优化问题为:
(22)
该问题为带正则化的L2范数逻辑斯蒂分类问题,优化求解如下:
令
更新迭代公式:
w(t+1)=w(t)+a(t)d(t)
(23)
其中a(t)为第t次迭代的步长,d(t)为第t次迭代的搜索方向,▽L(w)为L(w)关于w的导数:
(24)
其中:
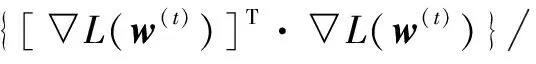
(25)
由于:
σ(a)=ln(1+exp(-a))
(26)
(27)
故:
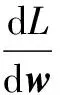
(28)
其中A=[y1x1,…,ynxn]T∈Rn×d,p(Y|X;w) =[p(y1|x1;w),…,p(yn|xn;w)]T∈Rn.
由等式(25)、式(28)可以确定搜索方向,式(23)中的步长可以通过如下优化问题得到:
(29)
式(29)为单变量优化问题,使用Carl Edward Rasmussen软件包minFun求解.通过逐步迭代更新,可以求解上述问题.最后给出基于关联性分析的域自适应学习算法.
算法1 KCCA-DAML域自适应学习算法
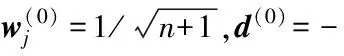
计算d(t)=-▽L(w(t))+g(t-1)w(t-1);
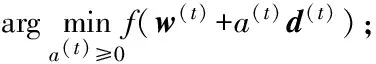
输出:目标域权向量w.
6 实验结果及分析
本节通过实验对KCCA-DAML在分类方面的性能进行研究.目前广泛使用的域自适应数据集有Reuters 20 Newsgroups数据集、Amazon reviews benchmark数据集和Wall Street Journal语料库数据集等,这些数据集最先应用于自然语言处理方面的研究,随后被广泛用于跨域学习问题的研究当中,此外数据特征“飘移”导致的数据分布差异也是目前常见的域自适应学习问题.本文选择以下三种广泛使用的真实数据集进行实验:Reuters 20 Newsgroups数据集(http://kdd.ics.uci.edu/databases/20newsgroups);MNIST手写数字识别数据集(http://yann.lecun.com/exdb/mnist);UCI Dermatology数据集(http://archive.ics.uci.edu/ml/datasets.html);为讨论跨域学习的影响因素,实验按源域数据逻辑斯蒂学习模型(S-KLLM,Source-Kernel Logistic Model)、目标域逻辑斯蒂学习模型(T-KLLM,Target-Kernel Logistic Model)、源域+目标域逻辑斯蒂学习模型(ST-KLLM,Source and Target-Kernel Logistic Model)、KCCA-DAML模型进行训练与测试,并给出KCCA-DAML在三种数据集上的实验结果和参数选择方案.
待调节参数设定为λ∈[2-4,…,2-1,1,2,…,210]和p∈[0.5,0.6,0.7,…,1.4,1.5],为简化计算复杂度,实验中使用网格搜索过程确定每组数据集参数.对于每组参数取值,执行算法1中的过程.
6.1 Reuters 20 Newsgroups数据集
Reuters 20 Newsgroups报文数据集具有层次结构,包含7个大类:共20个小类,实验选择comp和rec两大类数据,使用comp的4个小类:comp.windows.x、comp.os.ms-windows、comp.sys.ibm.pc.hardware和comp.sys.mac.hardware.路透社报文数据集的基本信息如表1所示.
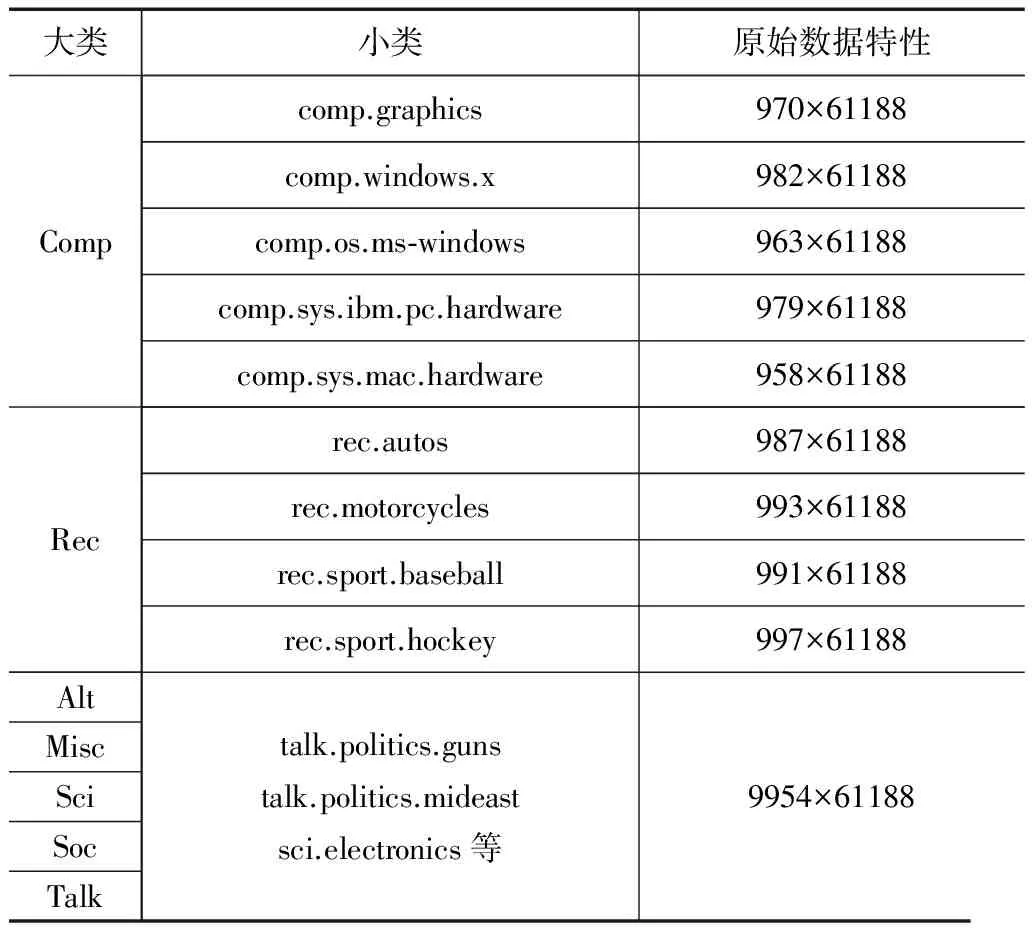
表1 Reuters 20 Newsgroups报文数据集
按照如下方式构造源域和目标域数据.包含comp域迁移学习rec域的两类任务.
任务1:comp.windows.x作为源域中的正类、rec.autos作为源域中的负类;comp.os.ms-windows作为目标域中的正类、rec.motorcycles作为目标域中的负类.
任务2:comp.sys.ibm.pc.hardware作为源域中的正
mac.hardware作为目标域中的正类、rec.sport.hockey作为目标域中的负类.源域和目标域数据构成如图1所示.
20Newsgroups数据集为18774×61188的词频矩阵,选用comp和rec词频数据大于30次的特征作为样本特征,并使用TI-IDF软件对数据进行处理,得到数据信息如表2所示:


表2 源域数据集和目标域数据集构成
表3是跨域学习任务Task1和Task2上的分类误差率.从表中跨域学习任务Task1上的分类误差率结果可以看出,在a=1.1处得到了最小分类误差率8.31,此时参数λ=4,wKCCA与wT的相关性较大.说明在两个域相关性较高的情况下,源域数据对目标域数据具有较好的迁移效果.此外当源域数据的迁移效果较好时,即当已知源域和目标域关联性较高时,参数a的值可在0.8~1.2范围内选择.从表中Task2上的分类误差率结果可以看出,在a=1.1处得到了最小分类误差率9.07,此时参数λ=2,此时两个域相关性较不高,源域数据对目标域数据具有较弱的迁移效果,如果过多考虑源域信息,会产生负迁移,使迁移学习退化为源域的学习.
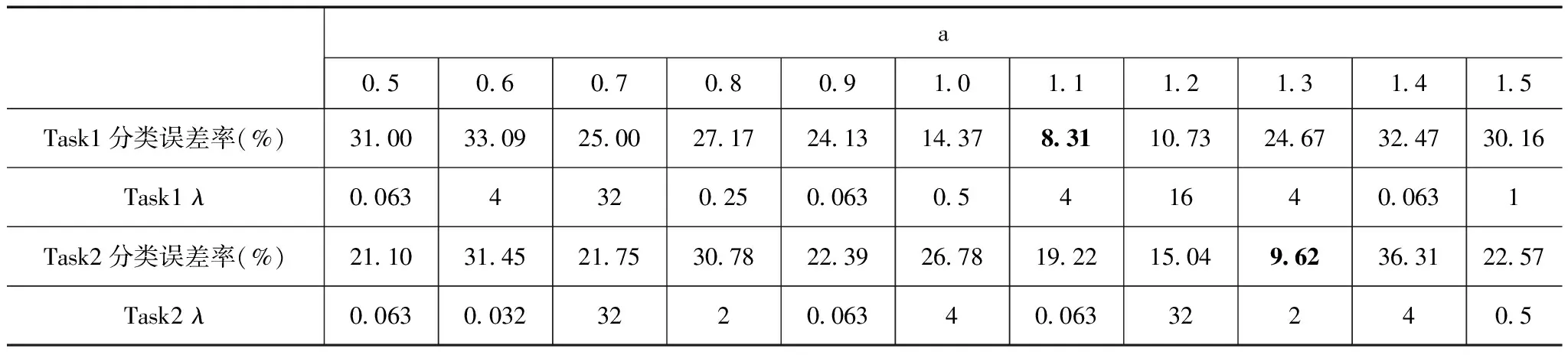
表3 Task1和Task2上的误差率
表4是模型S-KLLM,T-KLLM,ST-KLLM及KCCA-DAML在跨域学习任务Task1和Task2上的分类误差率,其中T-KLLM训练样本数目为150.从表中结果可以看出,任务Task1的源域与目标域的相关性高于Task2,对应的KCCA-DAML的Task1分类误差率也小于Task2.此外样本的迁移学习效果越差,源域的跨域学习性能越受限,跨域学习机的学习效果也会受到影响.当源域和目标域分布偏差足够大,甚至源域和目标域无显著关联时,实现跨域学习仍是十分困难的.
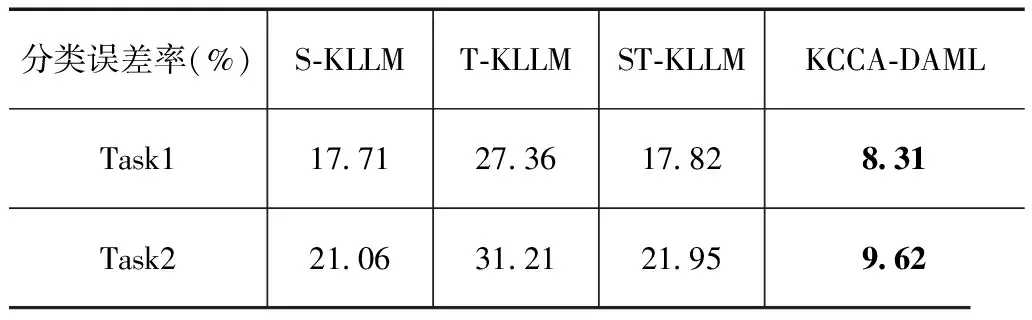
表4 不同模型下任务1和任务2的误差率
目标域训练样本不足导致T-KLLM学习误差较大,此外ST-KLLM的分类误差与S-KLLM的分类误差相接近,即将源域与目标域合并训练,跨域学习误差不一定减小,原因在于混合训练样本中源域样本在数量上占优,起到了主导作用.只有在充分考虑源域信息和域关联信息的前提下,域自适应学习机才能实现良好的跨域学习.6.2 MNIST手写数字识别数据集
MNIST手写数字识别数据集由500个训练样本和300个测试样例组成,每个样例的维数是784,采用构造特征偏差(feature bias)数据集的方法构造源域和目标域数据集,使源域和目标域分布不同,方法为:随机选择训练样本的375个属性列,按数值大小选各属性值最大的375个训练样本作为源域训练样本,剩余样本为目标域样本集,从中随机选择100个训练样本构成目标域训练样本集,剩余样例作为目标域测试.由于源域样本偏差特征值为各样本最大值,不能准确反映目标域特征的真实情况,导致源域判别函数不能准确预测目标域.同时,目标域数已标识样本数据样本数目太少,包含目标域信息不完全,也不能准确预测目标域真实分布.
表5是MNIST数据集的分类误差率.从表中结果可以看出,参数a在范围0.6~1.4范围内变化时,对分类误差率没有产生明显影响,但跨域数据依赖正则化项的引入能够保证跨域学习分类误差得以改善并不产生恶化.

表5 MNIST数据集误差率
表6是模型S-KLLM,T-KLLM,ST-KLLM及KCCA-DAML在MNIST数据集上的分类误差率.
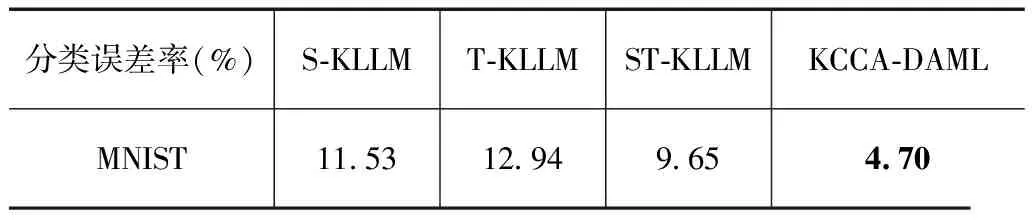
表6 不同模型下MNIST数据集误差率
MNIST数据集实验中,将源域与目标域合并训练,跨域学习误差减小,这受益于数据集特性以及构造源域和目标域的方法.和Reuters 20 Newsgroups数据集实验相比较,构造特征偏差数据集的方法引起的域分布差异性要小于Reuters 20 Newsgroups数据集子类差异.
6.3 UCI Dermatology数据集
本节使用UCI Dermatology据集进行实验,数据集由366个样本数据,每个样例的维数是33,同MNIST数据一样,采用构造特征偏差数据集的方法对源域和目标域数据进行构造,使源域和目标域分布不同.
选择acanthosis,hyperkeratosis,parakeratosis,clubbing of the rete ridges,elongation of the rete ridges,exocytosis,PNL infiltrate,spongiosis,follicular horn plug这9个特征作为偏差特征.选择每个偏差特征值中最大的十个样本(样本大小为9×10)作为源域训练样本,剩余样本为目标域样本集,从中随机选择30个样本构成目标域训练样本集,选择剩余240个样例作为目标域测试.
KCCA-DAML在Dermatology数据集上的类误差率如表7所示.
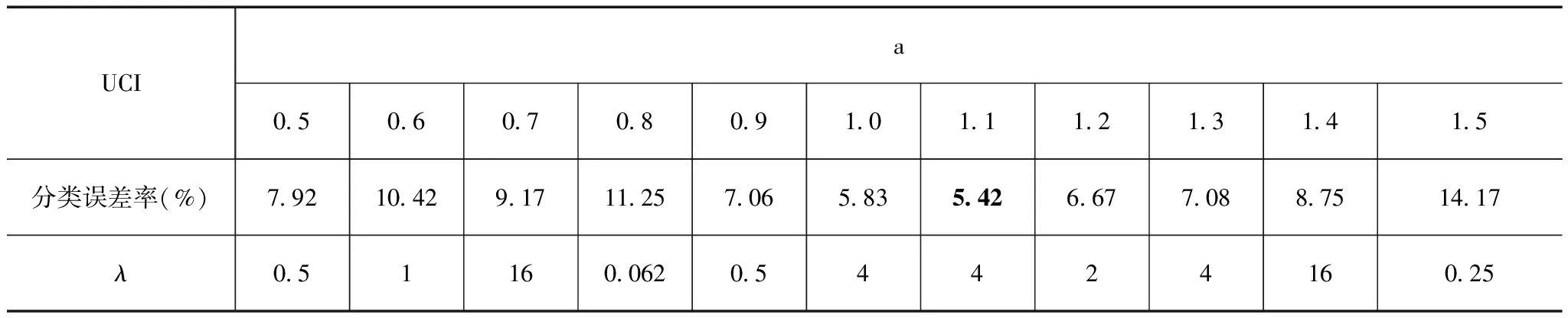
表7 UCI Dermatology数据集误差率
UCI Dermatology数据集实验在a=1.1处得到了最小分类误差率5.42,此时参数λ=0.0625.表8是模型S-KLLM,T-KLLM,ST-KLLM及KCCA-DAML在UCI Dermatology数据集上进行跨域学习的分类误差率.
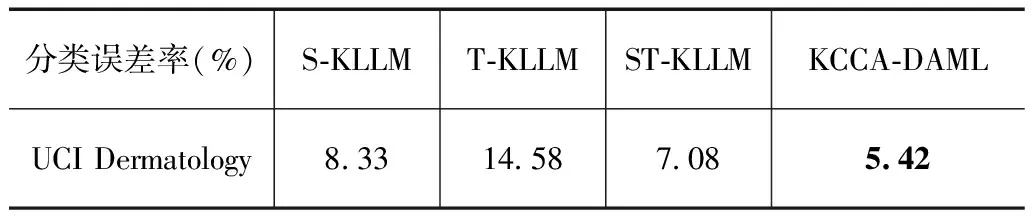
表8 不同模型下UCI Dermatology数据集误差率
7 结论
本文提出的域自适应学习算法KCCA-DAML及KCCA域自适应度量判据能够有效的揭示源域特征与目标域特征变的潜在关联性,从而对不同领域的差异性进行度量.通过对源域模型进行增量修正,使源域模型逐渐迁移至目标域模型,实现跨域学习.KCCA-DAML模型在跨域学习任务中具有可行性且学习性能良好.此外利用跨域学习中的已知先验信息,合适的选择模型参数,可使KCCA-DAML获得更好的迁移效果,实现更为精确的跨域学习任务.逻辑斯蒂模型适用于多类学习,因而KCCA-DAML可应用于多域自适应学习场景,这是我们下一步要做的工作.
[1]刘建伟,孙正康,罗雄麟.域自适应学习研究进展[J].自动化学报,2014,40(8):1576-1600. Liu Jianwei,SUN Zhengkang,LUO Xionglin.Review and research development on domain adaptation learning[J].Acta Automatica Sinica,2014,40(8):1576-1600.(in Chinese)
[2]Mansour Y,Mohri M,Rostamizadeh A.Multiple source adaptation and the Rényi divergence[A].Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence[C].Montreal,Canada:AUAI Press,2009.367-374.
[3]Blitzer J,Crammer K,Kulesza.A.Learning bounds for domain adaptation[A].Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems[C].Vancouver,British Columbia,Canada:Curran Associates,2007.129-136.
[4]Cortes C,Mansour Y,Mohri M.Learning bounds for importance weighting[A].Proceedings of the Twenty-Four Annual Conference on Neural Information Processing Systems[C].Vancouver,Canada:Curran Associates,2010.442-450.
[5]Tao Jianwen,Chung Fulai,Wang Shitong.A kernel learning framework for domain adaptation learning[J].Science China Information Sciences,2012,55(9):1983-2007.
[6]Malandrakis N,Potamianos A,Iosif E.Kernel models for affective lexicon creation[A].12th Annual Conference of the International Speech Communication Association[C].Florence,Italy:International Speech Communication Association,2011.2977-2980.
[7]Kulis B,Saenko K,Darrell T.What you saw is not what you get:Domain adaptation using asymmetric kernel transforms[A].Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR)[C].Colorado,USA:Springs,2011.1785-1792.
[8]Ben-David S,Blitzer J,Crammer K.A theory of learning from different domains[J].Machine Learning,2010,79(1-2):151-175.
[9]Joshi M,Cohen W W,Dredze M.Multi-domain learning:when do domains matter?[A].Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning[C].Jeju,Island,Korea:Association for Computational Linguistics,2012.1302-1312.
[10]Joshi M,Dredze M,Cohen W W.What’s in a domain? Multi-domain learning for multi-attribute data[A].Proceedings of the NAACL-HLT[C].Atlanta,Georgia,USA:Association for Computational Linguistics,2013.685-690.
[11]Mansour Y,Mohri M,Rostamizadeh A.Domain adaptation with multiple sources[A].Proceedings of the Twenty-Second Annual Conference on Neural Information Processing Systems[C].Vancouver,British Columbia,Canada:Curran Associates,2008.1041-1048.
[12]Chapelle O,Shivaswamy P,Vadrevu S.Boosted multi-task learning[J].Machine Learning,2011,85(1-2):149-173.
[13]Duan L,Xu D,Tsang I W.Domain adaptation from multiple sources:A domain-dependent regularization approach[J].IEEE Transactions on Neural Networks and Learning Systems,2012,23(3):504-518
[14]Schölkopf B,Smola A J,Williamson R C.New support vector algorithms[J].Neural Computation,2000,12(5):1207-1245.
[15]Joachims T.Transductive inference for text classification using support vector machines[A].Proceedings of the Sixteenth International Conference on Machine Learning[C].Bled,Slovenia:Morgan Kaufmann,1999.200-209.
[16]H Hotelling.Relations between two sets of variates[J].Biometrika,1936,28(3):312-377.

刘建伟(通信作者) 男,1966年出生.博士,中国石油大学(北京)副研究员,主要研究方向包括智能信息处理,机器学习,非线性分析与控制,算法分析与设计等.
E-mail:liujw@cup.edu.cn

孙正康 男,硕士,1990 年出生.中国石油大学(北京)地球物理与信息工程学院硕士研究生,研究方向为机器学习.
E-mail:sunzhengkang@126.com
Domain Adaptation Learning with Kernel Logistic Regression and Kernel Canonical Correlation Analysis
LIU Jian-wei1,SUN Zheng-kang1,LIU Ze-yu2,LUO Xiong-lin1
(1.DepartmentofAutomation,ChinaUniversityofPetroleum,Beijing102249,China; 2.NationalEngineeringResearchCenterforFundamentalSoftware,InstituteofSoftware,ChineseAcademyofSciences,Beijing100190,China)
The domain adaptive learning algorithm using kernel logistic regression model is proposed.The proposed approach use kernel canonical correlation analysis to extract the maximum relevant features of the source and target domain.We dub it as KCCA-DAML(Kernel Canonical Correlation Analysis for Domain Adaptation Learning,KCCA-DAML).Our algorithm is based on canonical correlation analysis,which simultaneously minimizes the incompatibility among source features,target features and instance labels,extract maximum relevant features from source features,target features and instance labels,and use kernel logistic regression domain adaptation learning.In experimental comparison of the kernel logistic model and KCCA-DAML model on source domain data,the target domain data,source and the target domain data,we demonstrate the power of our techniques with the following real-world data sets:Reuters 20 Newsgroups,MNIST handwritten-digits and UCI Dermatology.
domain adaptation;distribution discrepancy;correlation analysis;kernel logistic regression;regularization model
2015-05-25;
2015-11-18;责任编辑:覃怀银
国家重点基础研究发展规划(973计划)项目(No.2012CB720500)
TP181
A
0372-2112 (2016)12-2908-08
��学报URL:http://www.ejournal.org.cn
10.3969/j.issn.0372-2112.2016.12.014
