基于异构平台的自适应图像去马赛克的OpenCL加速
2016-11-28田旭文朱茂华
田旭文,朱茂华
(超威半导体产品(中国)有限公司,北京 100190)
基于异构平台的自适应图像去马赛克的OpenCL加速
田旭文,朱茂华
(超威半导体产品(中国)有限公司,北京 100190)
基于异构计算概念,使用GPU和OpenCL加速了一个高复杂度的自适应图像去马赛克算法,并在AMD Bald Eagle和FirePro W8100组成的异构计算平台上完成了功能和性能测试。实验结果表明,该异构平台能取得良好的图像重建效果,W8100处理图像的速率超过了100 f/s,每帧图像有 1 920×1 080个像素,证明异构计算平台及 OpenCL可满足医疗、网络监控等应用领域对高帧率、高清图像影像的需求。
异构系统架构;异构计算;OpenCL;AMD;自适应去马赛克
0 引言
随着高清影像与手持数码产品的普及,数字影像技术受到了产业界的重视,因数字影像携带大容量信息且引起丰富的创造潜能。高清、高帧率影像不仅能展现更高的画面质量,还能提升画面的连续性,在网络监控、医疗等领域有广阔的前景。通常,数字影像采集设备用成像芯片将光学图像转换为电荷,成像芯片决定影像质量,占相机成本的10%~25%。考虑到成本、体积及硬件工艺,多数影像采集设备使用覆盖有一层色彩滤镜阵列的单个成像芯片。每个感光单元只能取样一种色彩,其余两种颜色值需用相邻单元的取样值进行插值计算得到。这种色彩插值就是去马赛克,是数字影像采集流水线的一个关键环节,在高帧率、高清图像处理应用中有重要价值。
本设计基于异构计算实现了一个自适应去马赛克算法的OpenCL代码,并在AMD Bald Eagle和AMD FirePro W8100(或ES8950 MXM)GPU组成的异构计算平台上进行了测试。据了解,目前还没有异构平台的去马赛克并行代码。深度优化的代码充分发挥了异构平台的架构优势以及 FirePro W8100的浮点运算能力和高 GFLOPS/J特点。整个系统具有低的计算耗时,处理图像的速率超过了100 f/s,每帧的像素数量是1 920×1 080。实验数据证明该方案能满足医疗、安监等领域对高帧率和高清数字影像的需求。
1 图像插值算法和异构计算
1.1图像去马赛克算法
图像去马赛克算法是数码影像产品里的一项关键技术,其性能优劣直接影响着图像质量,性能不好的算法会使重建图像有彩色马赛克或拉链失真等畸变。按是否利用空间相关性,文献[1]将现有的算法分为两类——非自适应插值法(如最近邻域复制、双线性插值和三次样条插值)和利用相关性的插值法。前一类算法易于实现,可以在图像的平滑区域得到满意的插值效果,但在目标边缘等高频区域易引起插值畸变。后一类方法利用相关性实现插值,相关性包括每个色彩通道内像素间的空间相关性和多通道间的色彩值相关性。第二类算法能得到高质量的重建图像,但是计算复杂度高。没有专用加速计算芯片的支持,数字影像采集设备很难实时运行后一类算法。本文采用的Adaptive Homogeneity-Directed De-Mosaicking(AHDDM)属于利用相关性的插值算法[2]。该算法适于处理以Bayer色彩滤波阵列模式采集到的图像,图1是该算法的主要计算步骤流程。虽然这些步骤需要大量的浮点运算和复杂的数值计算,但是适于用并行计算代码实现加速。
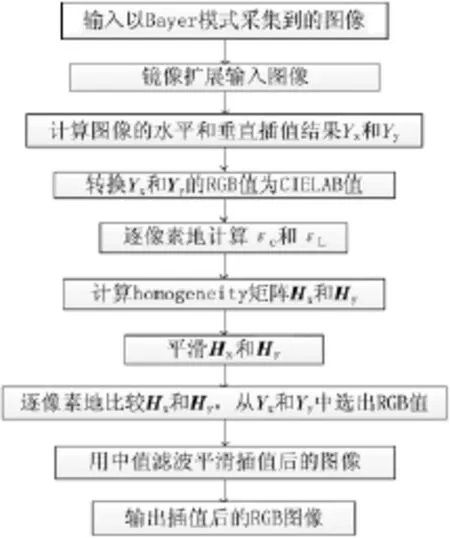
图1 Adaptive Homogeneity-Directed De-Mosaicking的主要步骤
1.2异构计算
传统的图像处理平台用CPU,系统运算能力的提升受限于因提高CPU工作频率引起的功耗的显著增加。虽然CPU的同构并行和分布系统能提升运算能力,但其提升幅度不能随着处理器数量线性增长。在这些系统上,即便得到成熟的开发经验、编程语言、算法和调试工具等手段的协助,开发图像处理软件也是一项困难的工作。异构计算技术产生于80年代中期,主要指使用不同类型指令集、体系架构的计算单元组成混合系统的一种计算方式。常见的计算单元包括兼容X86指令集的多核CPU、GPU、FPGA、DSP、音频/视频处理等专用集成电路(ASIC)[3-4]。由于异构计算能经济、有效地配置计算资源,提升资源利用率和可扩展性,该技术已成为并行/分布计算领域中的一个研究热点。异构平台通常由多核CPU和GPU组成。
1.3AMD GPU
在2012年以前,AMD的GPU架构采用VLIW4作为计算单元的指令格式,这使GPU适用于图像渲染和3D图形运算。通常,通用计算的数据有复杂的结构,这些数据结构很难被归并到有限的类型之中,因此旧架构的GPU芯片难以高效地完成通用并行计算或合理地配置资源。从2012年开始,AMD发布的GPU芯片采用了新架构GCN[5],如图2所示。GCN架构不仅支持渲染和3D图形计算,还支持通用计算和OpenCL 1.2标准。
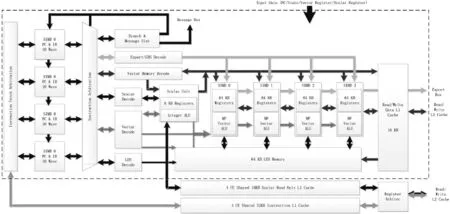
图2 AMD GPU GCN计算单元
GCN架构的核心特点表现在两个方面。首先,该架构用了新的CU结构和指令集。每个CU有4个独立的SIMD向量处理器和向量寄存器,还有一个标量处理器和8 KB寄存器,用于减少向量计算的冗余计算。除了私有资源,4个SIMD共享前端、分支单元和数据缓存。这些设计使得一个CU能支持多达2 560个线程。其次,GCN架构还将改变扩展到整个系统,如GCN架构采用分级缓存。由一个向量数据读取指令引发的64个存储访问会被合并成一个访问。合并机制将读取同一个cache line里的数据合并为一次访问,这能显著地降低片外存储器的读取次数。数据存储采用了不同于读取的合并方式。在合并存储器读取请求之后,数据将被送至一级数据缓存,即分级缓存的第一级。如果CU需要的数据不在一级缓存,那么CU将通过开关矩阵访问二级缓存。二级缓存有多个bank,采用交织寻址方式,各bank通过一个64位双通道存储控制器连接到片外存储器。GCN分级存储是一个合并读写的缓存系统,支持虚拟内存和原子操作,进而支持GPU和CPU间的数据零拷贝。
1.4OpenCL
通常,硬件厂商仅提供支持自身芯片的编程模型和工具,所以难用一种风格的编程语言实现异构编程。此外,将不同设备作为统一的计算单元来处理是非常困难的。为解决该问题,OpenCL通过一套机制实现独立于硬件的软件开发环境,还能支持多级别的并行计算和不同设备的并行特性,将高级语言的代码有效地映射到由CPU、GPU和其他芯片组成的系统上[6]。OpenCL定义了运行时系统管理资源,将不同类型的硬件结合在同种执行环境中,用来支持动态平衡计算、功耗及其他资源[7]。图3示意了平台模型和执行模型间的关系。
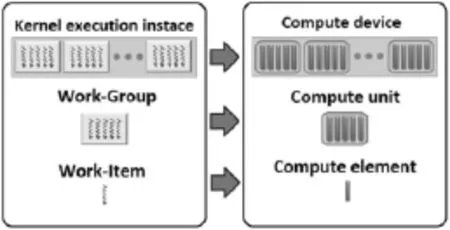
图3 OpenCL平台模型和执行模型
2 OpenCL代码设计及优化
本文用 OpenCL 1.2标准设计 GPU代码,实现一个高复杂度的自适应去马赛克算法。因为该算法对每个像素进行多次插值、滤波和非线性映射等操作,所以这个算法需要大量的浮点运算以及数值计算,属于数据密集型应用,适合于GPU实现。为高速实现该算法,OpenCL代码必须充分利用GPU的计算资源,如高速浮点运算能力。目标异构平台以CPU为核心,包含一个或多个OpenCL设备,这要求不同架构的微处理器同时运行不同性质和内容的计算任务,因此代码应同时进行数据传输和计算,以利于整个系统高速地处理数据帧序列。
OpenCL代码的主要技术特点如下所述。在代码加速方面,优化了中值滤波和线性滤波的计算流程,优化了片外存储数据的访问。设备代码还采用OpenCL内建函数,加速了立方根等数值计算函数,这显著地降低了处理器时间。软件优化了数据的存储布局,降低了读写数据次数。部分优化方法的说明可参考文献[7-8]。在异构加速方面,软件创建了两个命令队列,分别控制OpenCL设备完成图像处理和主机与设备间的数据传输。相比于单命令队列控制OpenCL设备的计算和通信,新做法隐藏了数据传输,进一步提高了每帧数据的处理速度。软件采用了两个事件对象同步两个命令队列。这种方式通过交替地创建和释放事件对象,有效地避免了不同队列里的命令在任一个时刻处理同一帧数据,保证了数据一致性。下面分别介绍这些代码部分的设计。
2.1软件流程设计和描述
按照OpenCL 1.2标准,采用主机和OpenCL设备协作实现AHDDM算法。主机代码按照一个指定顺序启动设备执行设备代码,完成平台和设备信息的获取、设备选择、各种对象创建、主机和设备间通信、设备代码的输入参数配置和资源释放。设备完成图像处理计算,对输入数据进行插值和滤波,得到重建结果。在图像处理中,水平/竖直方向插值、homogeneity计算、中值滤波和色彩空间转换需要大量运算。下面概略地介绍这些算法步骤。
2.1.1插值
对于一幅输入图像,AHDDM算法用一个像素的周边像素值分布估计出该点缺失的信息,对水平插值和竖直插值结果进行了选择性组合。水平插值过程是:(1)求像素RGB值的和,存于矩阵X中;(2)在处理G通道时,对应于G Mask的像素取矩阵X的值,对应于R/B Mask的像素取矩阵X水平方向的邻近4个值的加权平均;(3)在处理R和B通道时,输出像素取以其为中心的3×3窗口内所有R/B Mask像素的平均值。竖直插值过程是:除G通道R/B Mask下的像素取矩阵X竖直方向的最近4个值的计算结果以外,其余与水平插值相同。
2.1.2计算Homogeneity矩阵
该算法将水平插值和竖直插值得到的图像转换成LAB格式,并求出这两张 LAB图像的亮度差和色彩差。随后根据这两个差值矩阵,OpenCL设备计算出水平插值和竖直插值的同质矩阵Hx和Hy;接着对这两个矩阵里的数据进行平滑处理。根据平滑结果,OpenCL设备合并水平插值图像和竖直插值图像,每个像素的取值判据是选择其在Hx/Hy较大的像素值。
2.1.3中值滤波
合并后的插值图像需要进行中值滤波,以保证重建质量。在R和B通道,每个像素取其相邻的8个像素的中值滤波结果;在G通道里,每个像素取其上下左右4个相邻的像素的中值滤波结果。中值计算需先将输入的数据按照升序或降序排列,再输出中间位置上的那个数值。当输入奇数个数据时,计算结果将是排序后的序列中间的数据;当输入偶数个数据时,计算结果将是排序后的序列中间的两个数据的平均值。自适应算法用两次中值滤波,以得到较好的滤波效果。
2.1.4色彩空间转换
RGB和CIELAB是常用的颜色空间。RGB便于建模物理设备的输出,但不适合描述人类视觉感知。CIELAB具有视觉上的均匀性,接近于人类的视觉感知,即色彩值的变化和视觉感知到的变化程度是一致的[9]。RGB和CIELAB之间的色彩值转换需要分两步进行,即先规范化RGB值到0~1之间,用XYZ颜色空间作中间层;再用一组非线性变换得到CIELAB值[10]。
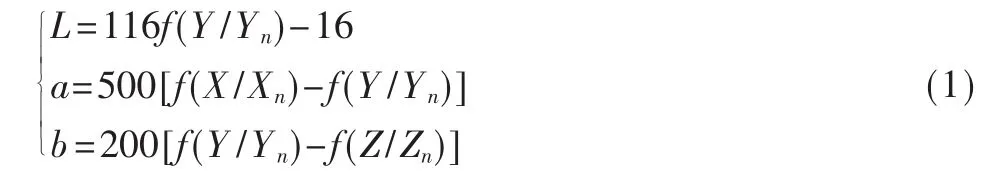
其中:

转换公式显示CIELAB转换需要浮点型运算,虽然可截取浮点计算结果的整数部分换取计算速度的增加,但是损失了计算精度。因为RGB转换CIELAB需要较多的数值计算,所以快速转换是OpenCL代码设计的一个重点。本文用一个3×3矩阵和一个1×3向量的浮点乘法实现规范化计算,用 OpenCL 1.2标准的内建立方根等函数实现非线性数值计算,用三元运算符而不是条件指令加快非线性转换中的流程控制。
2.2并行图像处理和数据通信
本文用单个命令队列实现单幅图像的插值处理,用两个命令队列处理一个帧序列,隐藏了数据传输时间。代码采用任务并行的方式,同步地完成图像处理和数据通信。主机代码用一个命令队列里的命令启动 OpenCL设备执行设备代码,用另一个命令队列中的命令去控制设备内存和主机内存之间的数据通信。系统使用两个事件对象同步两个命令队列的命令,通过交替地监测两个事件对象建立和释放的返回值,安排两个命令队列中的命令读写不同的存储位置,免除了两个队列里的命令读写相同的存储位置。
2.3存储空间配置
根据算法流程,在开始插值计算前,需镜像扩展原始图像的边缘部分。其次,一些计算步骤访问多个相邻的像素,这需要条件指令限定并行线程的处理范围,否则边缘像素的重建结果将会有明显偏差。软件采取了图像补零法,填补宽度是各步骤的最大补零长度,这利于合并掉一些条件指令,减少计算时间。如果原始图像的尺寸是M×N,镜像扩展图像的尺寸是H×W,则输入和输出图像的尺寸是 M×N,中间结果的尺寸均是(H+2×P)× (W+2×P),其中 P是补零宽度,取 2和 delta(homogeneity函数的参数)的最大值。在本文的实验中,delta默认取值为 3,所以 P取delta值。最后,代码将扩展图像的宽度和高度取为16的整数倍,以提高数据访问效率。在实验中,原始图像和重建图像的尺寸是1 920×1 080像素,中间结果是1 952×1 104像素。
3 实验及讨论
本文的异构计算平台的配置如下:硬件平台由AMD Bald Eagle和 AMD FirePro W8100[11](或 ES8950 MXM)组成,软件开发环境是Win7、AMD Catalyst 13.11以上版本和 AMD APP SDK 2.8[12],编程语言及版本号是 VC2010和OpenCL 1.2 C。图4是原始RGB图像、模拟数据和插值重建图像。三幅图像的尺寸均为1 920×1 080像素,有3个图像通道。按照Bayer模式,对原始图进行采样得到模拟图,模拟图偏绿。对比原始图像和重建结果,可看出重建结果非常接近于原始图像,而且差别很小。该异构平台的重建图像与CPU代码的计算结果不存在明显差异,区域交界处的虚假色块和拉链等失真被抑制和消除,细节得到了保留。
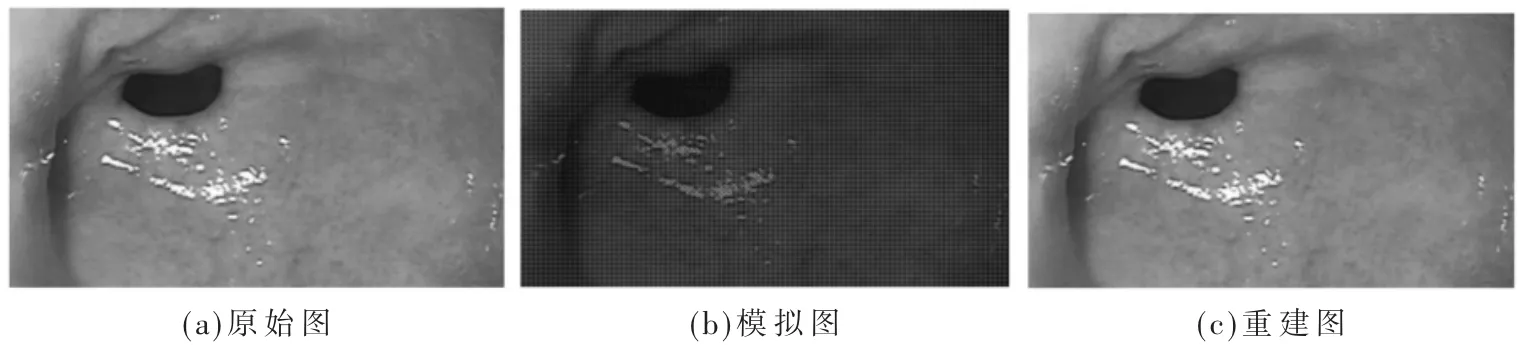
图4 图像重建
在Intel i7平台上,该算法的 MATLAB代码的运行时间约为7 s。图5是 FirePro W8100的一段工作时序,显示了两个命令队列的运行情况,其中Queue0和Queue1分别对应于数据处理命令队列和通信命令队列。该图显示出交叠的数据通信和数据处理命令节省了GPU计算时间。AMD Bald Eagle APU处理器集成有X86 CPU内核和GPU内核,但其GPU核的计算单元数量远小于W8100的计算单元数量。因为用一个命令队列完成数据通信和执行处理算法,所以该GPU核大约用67 ms完成单幅图像的去马赛克处理,如图6所示。表1列出了W8100处理各步骤的耗时,总和约为 6.22 ms,因为设备启动命令需要时间,所以每一幅图像的插值处理大约用8.6 ms。两种工作时序的对比显示出多命令队列方式能更高效地使用OpenCL设备的计算资源。
除了上述的代码优化方法以外,OpenCL代码仍有进一步提升性能的方式,如使用三维查找表插值法提高RGB值转换为CIELAB值的速度。
4 小结
按照OpenCL 1.2标准,本文开发了自适应去马赛克并行代码,在AMD Bald Eagle和AMD FirePro W8100 GPU组成的异构系统上进行了验证。AMD FirePro W8100能满足100 f/s的图像处理,图像尺寸达到了 1 920×1 080像素,每个像素有RGB值。本文的实验证明异构计算是一种适于高清影像和大尺幅图像处理的有效方案。
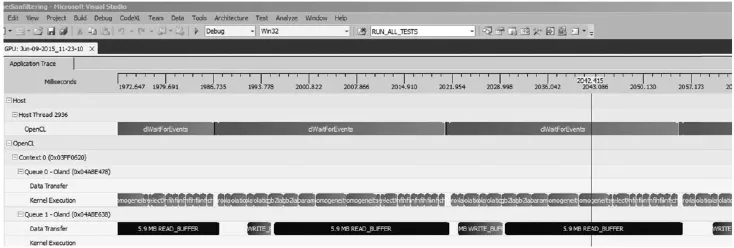
图5 AMD FirePro W8100用多个命令队列处理多幅图像的时序

图6 AMD Bald Eagle APU处理器用单个命令队列处理单幅图像的时序
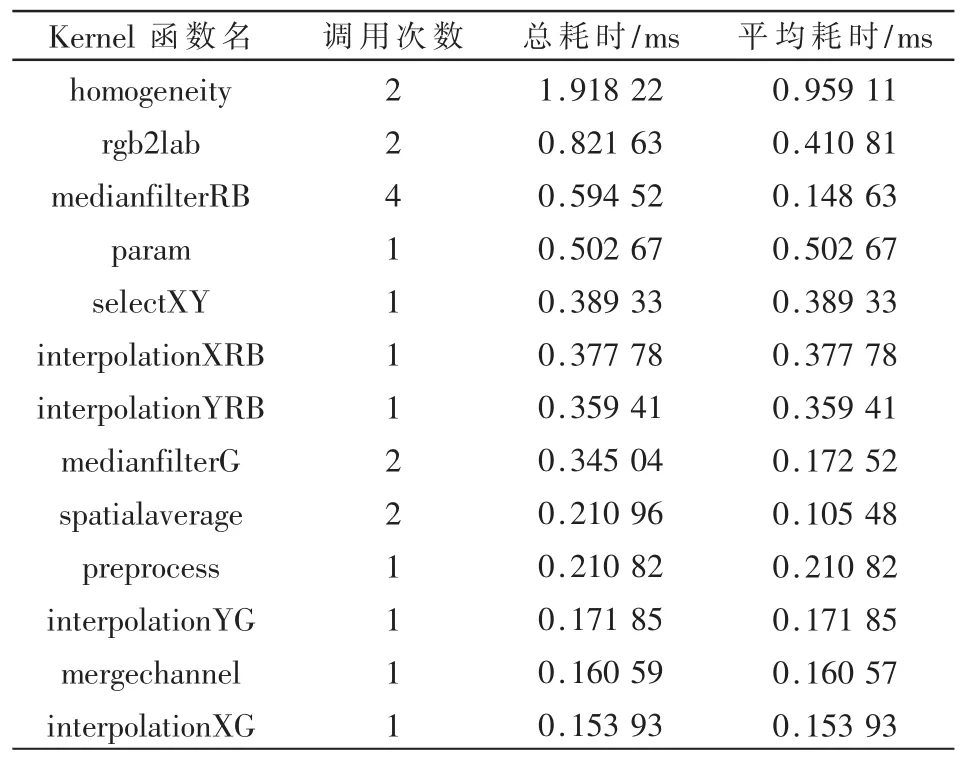
表1 Kernel函数执行时间
[1]LI X.Image demosaicking:a systematic survey[C].Proc.of SPIE Electronic Imaging Conference,2008.
[2]HIRAKAWA K.Adaptive homogeneity-directed demosaicing algorithm[J].IEEE Trans.on Image Processing,2005,14(3):360-369.
[3]HSA Foundation.Heterogeneous system architecture:A technical review presentation[EB/OL].(2012)[2015].Available:http://www.slideshare.net/hsafoundation/hsa10-whitepaper.
[4]AMD Inc.AMD and HSA:A new era of vivid digital experiences website[EB/OL].(2013)[2016].Available:http://www.amd.com/us/products/technologies/hsa/Pages/hsa.aspx#1.
[5]AMD Inc.AMD Graphics Cores Next(GCN)architecture[EB/OL].(2012)[2016].Available:http://www.amd.com/jp/Documents/GCNArchitecturewhitepaper.pdf.
[6]Khronos OpenCL Working Group.The OpenCL specification 1.2[EB/OL].(2011)[2016].Available:http://www.khronos.org/registry/cl/specs/opencl-1.2.pdf.
[7]MUNSHI A.OpenCL programming guide for optimization techniques[M].Addison-Wesley Professional,2011.
[8]AMD Inc.ATI streaming SDK OpenCL programming guide 4.2[EB/OL].(2013)[2016].Available:http://developer.amd.com/wordpress/media/2013/07/AMD_Accelerated_Parallel_Processing_OCL_Programming_Guide-2013-06-21.pdf.
[9]BILLMEYER F W,SALTZMAN J M.Principles of color technology[M].2nd ed.,John Wiley&Sons,Inc.,New York,1981.
[10]SCHALLER N C.Color conversion algorithms[EB/OL].(2015)[2016].Available:http://www.cs.rit.edu/~ncs/color/t_convert.html.
[11]AMD Inc.FirePro datasheet[EB/OL].(2015)[2016].Available:http://www.amd.com/Documents/FirePro-W8100-Data-Sheet.pdf.
[12]AMD Inc.AMD accelerated parallel processing software development Kit[EB/OL].(2016)[2016].Available:http://developer.amd.com/sdks/amdappsdk/.
An OpenCL implementation of an image de-mosaicking algorithm on a hybrid platform of heterogeneous system architecture
Tian Xuwen,Zhu Maohua
(AMD Products(China)CO.,Ltd.,Beijing 100190,China)
This paper describes a GPU-accelerated implementation of adaptive image de-mosaicking(a common digital image processing application)to demonstrate massive computation power of the many-core architecture.Acceleration strategies are briefly described to properly map the real-world applications to the GPU for high performance computing.Experimental results show that the developed OpenCL implementation can leverage the AMD FirePro W8100,which achieves a high throughput rate up to 100 frames/s,each having 1920-by-1080 pixels with RGB values.This research work integrates this GPU processor and the AMD Bald Eagle (an embedded APU processor)to form a heterogeneous computing platform,and uses this acceleration example as a case study to demonstrate that heterogeneous system architecture is well-suited for high-throughput,high-definition applications in many fields, such as security and medical imaging.
heterogeneous system architecture;heterogeneous computing;OpenCL;AMD;adaptive de-mosaicking
TP37
A
10.16157/j.issn.0258-7998.2016.04.031
2016-01-21)
田旭文(1977-),男,博士,主要研究方向:异构计算、人工智能、深度学习。
朱茂华(1989-),男,博士研究生,主要研究方向:计算机体系结构、深度学习。
中文引用格式:田旭文,朱茂华.基于异构平台的自适应图像去马赛克的 OpenCL加速[J].电子技术应用,2016,42(4):111-115.
英文引用格式:Tian Xuwen,Zhu Maohua.An OpenCL implementation of an image de-mosaicking algorithm on a hybrid platform of heterogeneous system architecture[J].Application of Electronic Technique,2016,42(4):111-115.
