基于CSS模板的职位信息并行抽取系统设计
2016-11-14薛安荣黄祖卫
薛安荣,王 丹,黄祖卫
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
基于CSS模板的职位信息并行抽取系统设计
薛安荣,王 丹,黄祖卫
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
针对现有职位信息抽取方法由于缺乏自适应性和并行性,存在冗余度高和抽取效率低的问题,提出了基于CSS模板的方式并行职位信息抽取方法。该方法根据职位信息页面特点使用CSS路径抽取方法,并制定抽取模板解决抽取的准确性和自适应性,使用了MapReduce编程模型实现职位信息的并行化抽取。使用MD5算法计算已抽取得到的职位信息的MD5值,结合MapReduce并行计算编程模型的特性实现职位信息去重,最终将去重后的职位信息存储在分布式数据库HBase。实验测试结果表明,并行计算与传统的非并行编程模型相比在处理的时间效率和采集的职位信息量上都有明显的提高。
信息抽取;MapReduce;CSS模板;MD5算法;分布式数据库HBase
XUE Anrong, WANG Dan, HUANG Zuwei
(School of Computer Science and Communication Engineering, Jiangsu University, Zhenjiang 212013, China)
当下网络求职已成为当下趋势,招聘网站的不断增多,使求职者可选择的求职路径增多,但同时也给求职者带来一定的困扰。求职者在不同的招聘网站查找适合的职位信息以后,每个招聘网站都要求求职者注册个人信息以及填写求职简历。与此同时,职位信息发布者可将同一职位信息发布在不同的招聘网站上,造成了职位信息的冗余问题,使求职者在求职过程中不断鉴别职位信息的重复性。
为解决以上问题,使用了Web信息抽取技术。Web信息抽取技术是从网页中抽取出用户感兴趣的内容,去除一些不必要的信息包括广告、不相关的内容等。目前,主要有以下几种抽取方法:(1)基于包装器(Wrapper)归纳方式抽取网页内容[1-2],使用归纳方法学习用户提供的样本得到抽取规则,该方法可重用性差、可扩展性差;(2)基于机器学习(Machine Learning)或数据挖掘(Data Mining)的方法抽取网页内容,使用数据挖掘、聚类(Clustering)、隐马尔科夫模型(Hidden Markov Model)等[3],但是该方法将简单问题复杂化、扩展性差;(3)基于网页分块方法抽取内容[4-5],该方法是根据网页布局对网页划分不同的区域,提取目标模块的内容,该方法适用性差,因网页布局不同,每次都要重新划分;(4)基于DOM树方法的抽取内容[6-7],该方法将网页解析成一个树结构,查找要抽取的节点,该方法对HTML结构要求比较高,树的建立和遍历复杂度高。本文在研究这些方法的基础上,结合实际职位信息页面布局,提出基于CSS模板的并行化职位信息抽取方法。
网页中职位信息具有以下特点:同一个网站的页面相同的职位信息页面布局相同,在源码中坐落的位置相同,利用这一特征本文使用基于CSS路径的方法抽取职位信息,使用HTMLParser[8]解析网页制作职位信息抽取模板,确保职位信息抽取准确率。同时,为提高职位信息抽取速率,本文使用Hadoop分布式平台[9]中的MapReduce[10]并行计算模型实现职位信息的并行化抽取。因职位信息来自多个网站,所以抽取到的职位信息存在冗余问题,本文在基于MapReduce计算模型上使用MD5算法[10]实现职位信息去重,将职位信息去重后存储到HBase[12]数据库中。
1 职位抽取系统框架结构
为方便求职者快速、准确地寻找到想要的信息,系统采用并行计算模型并建立统一的职位信息知识库。系统搭建在Hadoop分布式平台上,以满足处理海量职位页面信息的需求。同时系统使用基于模板的抽取方法解决以往只能一次固定抽取特定站点的问题。
职位信息抽取系统框架图如图1所示,职位信息系统主要包括职位爬取功能、职位抽取功能、职位信息去重功能。使用Nutch从招聘网站爬取职位信息的URL,爬取所得到的URL与制定的基于CSS路径的职位信息模板匹配,匹配得到相对应的抽取模板,根据抽取模板对URL所对应的职位信息页面进行职位信息抽取,同时根据所得到的职位名称、公司名称和工作地点利用MD5算法计算职位信息的MD5值。在抽取的过程中使用MapReduce实现并行化职位抽取,Map阶段将获得的职位信息的MD5值作为Key的输出值,抽取得到的职位信息作为Value的输出值,在Reduce阶段Key值相同的职位信息将合并形成一个Value-list实现职位信息的去重。从Value-list中读取一条职位信息,存入到HBase数据库中,并将职位信息的MD5值作为数据库的行值。
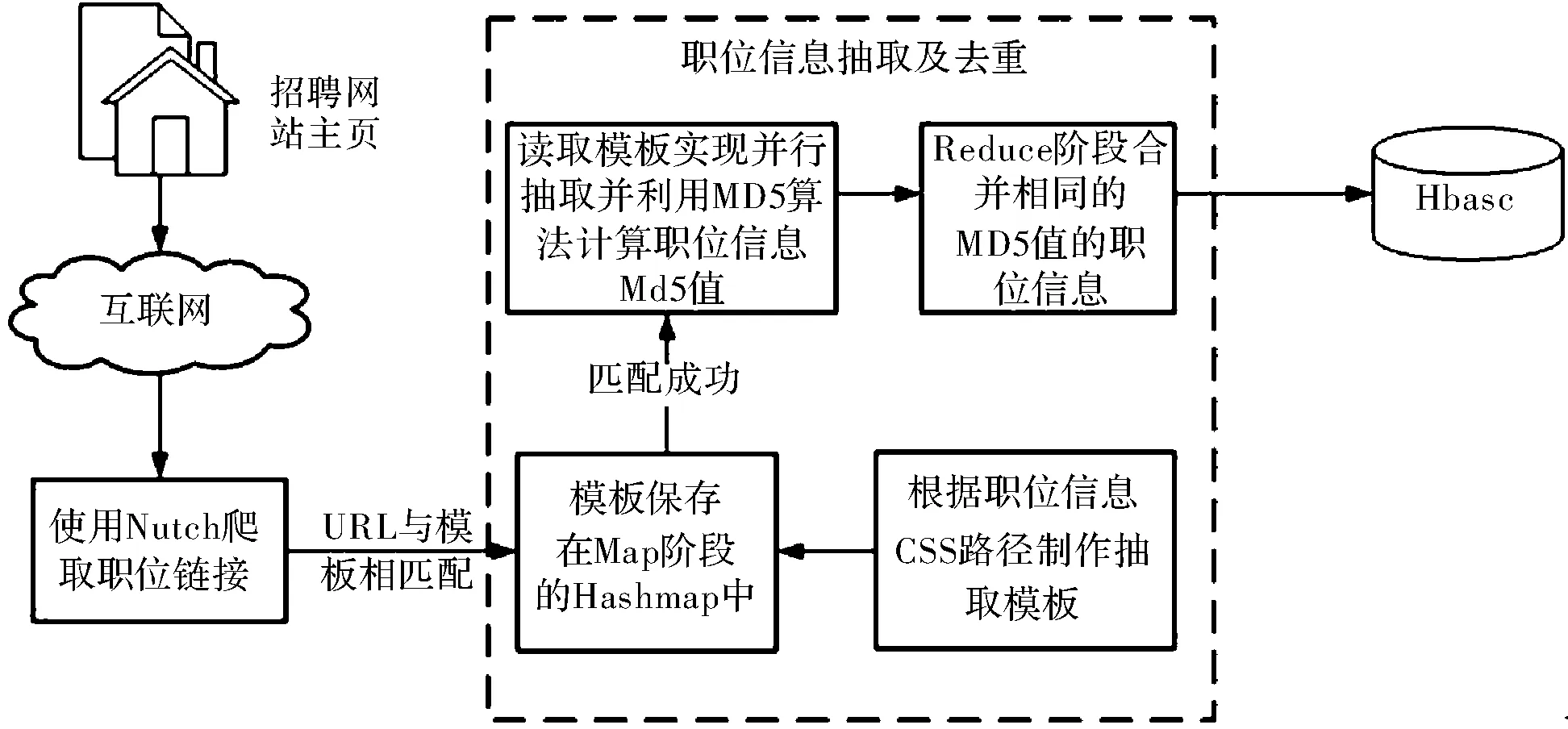
图1 职位信息抽取系统体系结构
2 职位信息抽取系统设计与实现
2.1 职位详情页面特征链接的过滤
在开源项目Nutch上进行二次开发实现对各大招聘数据源职位信息页面链接的采集,采集后会在当前目录下产生Crawldb、Segments、linkdb这3个文件夹,其中Crawldb中存放了所有解析过的页面链接。为了能够更加方便有效地抽取职位信息,本文提出了特征链接的概念。所谓特征链接是指在招聘站点内部描述特定招聘职位详情的链接。例如,对于智联招聘网站中职位详情链接的正则模式是:http://jobs.zhaopin.com/[0-9]*.htm,前程无忧招聘网站职位详情链接的正则模式是:http://search.51job.com/job/[0-9]*,c.html。从crawldb中遍历读取链接,和对应站点的正则模式匹配,如果匹配成功,则该链接就是特征招聘链接,流程如图2所示。该模块的主要工作是从crawldb当中筛选出不同站点的特征链接,得到一系列的针对不同站点的特征链接,利用这些文本作为下一个并行抽取模块的数据输入源进行职位信息抽取。
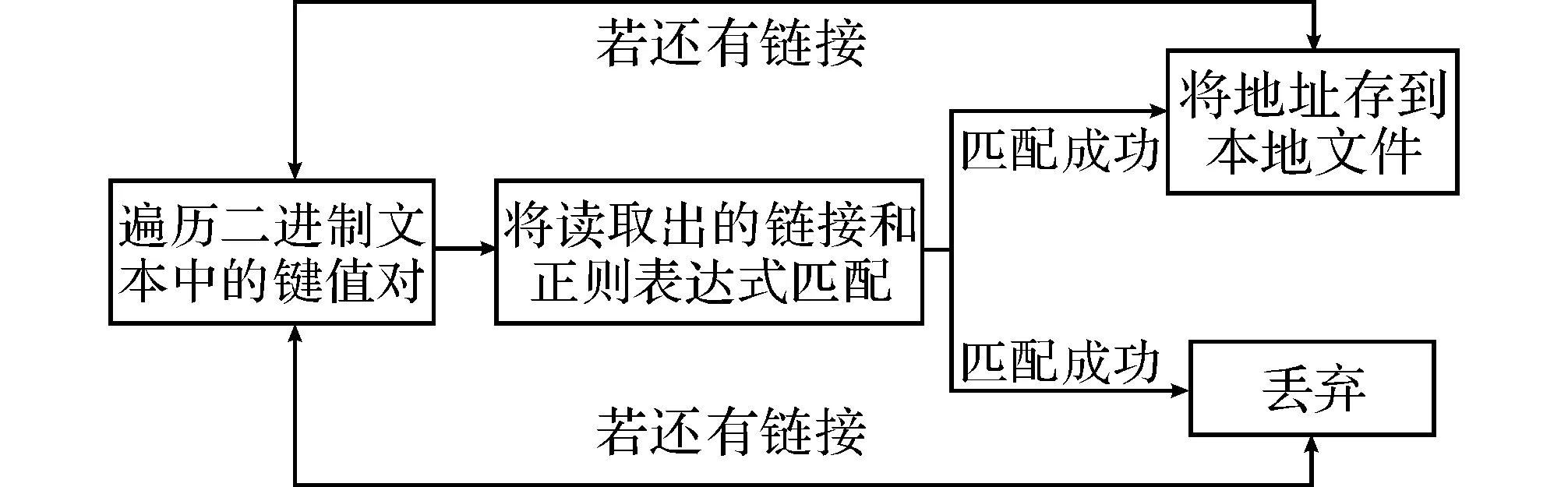
图2 特征招聘链接提取流程图
由于Crawldb当中的数据格式均为二进制数据,所以在提取过程中需要利用Hadoop I/O流中的相关类进行读取转换成字符串类型进行匹配。
2.2 定制异构站点的页面结构模板
在抽取职位信息页面前,需要确定抽取页面当中哪几部分信息,比如针对智联招聘网站的职位页面需要解析出职位名称、公司名称、工作地点、发布时间等信息。查看页面的源代码会发现每一项信息都包含在某个具体的标签块当中。对于任何非结构化的Web文档而言,每一个标签都会对应各自的属性值对。例如,,该职位名称所属的div标签就具有class="grayline"这样的属性值对。当要抽取Java工程师这个职位名称时就必须根据该属性进行定位标签(前提是该标签属性在Web文档中是唯一的)。如果出现多个具有该属性对的标签,还需要在已有的规则下探寻下一层的属性对或标签名,直至能够唯一确定某个具体的叶子节点,进而得到所关注的信息。CSS路径可以被定义为:在Web文档中确定某个唯一具体的叶子节点过程中需要标记出来的所有属性对或标签名按顺序组合起来的规则。图3显示了部分智联招聘职位信息的页面信息。

图3 职位招聘信息页面
图3部分展开后的HTML代码如下:
从中可以分别抽取出职位名称和公司名称对应两条CSS路径规则:
规则1
规则1
类推任何一条CSS路径规则表示为
2.3 基于MapReduce框架的并行抽取
并行抽取模块是整个系统的核心部分,采用基于MapReduce的分布式计算编程模型实现。并行抽取算法如下。
算法1 基于MapReduce的并行抽取算法。
输入 存储在HDFS上的特征链接文本。
输出 包含职位信息的文本文件
步骤 (1)匹配当前读取的特征链接所属的招聘网站;(2)获取网站对应抽取模板,利用模板抽取信息;(3)如果还有特征链接则返回(1),否则结束。
算法的具体实现是基于MapReduce框架进行并行抽取,利用HTMLParser工具对网页内容进行解析。其中,Map函数会接收一个
2.4 基于MD5的职位信息去重
由于基于CSS模板机制并行抽取得到的职位信息来自不同的招聘网站,而同一条职位信息很可能会在不同站点以不同的格式展现,从而造成上述并行抽取得到的职位信息存在冗余,需要解决海量职位信息去重问题。
主要思想:根据职位名称、公司名称以及工作地点判断一个职位信息是否已存在,在信息抽取之后,使用MD5算法计算职位名称、公司名称以及工作地点的MD5值,MD5算法具有如果计算内容是唯一的则计算出来的结果具有唯一性,所以当职位名称、公司名称以及工作地点相同时,则所计算出的MD5值相同。将职位信息计算出的MD5值作为Map阶段Key的输出值,抽取出的职位信息作为Value值的输出。利用MapReduce中的Reduce阶段的Shuffle功能,将相同的Key值进行合并,Value值进行合并,所以抽取出相同职位信息利用Reduce阶段的特性实现了第一次去重功能。将MD5值作为职位信息存储在HBase中的行值,如果新的职位信息与已存在HBase数据库中的职位信息相同,则HBase中的时间戳会记录最新存入的职位信息,在查询时只需设置输出最新时间戳记录的职位信息,以此确保查询职位信息时不存在冗余问题。
3 实验测试与分析
本文选取5个招聘信息网站,使用Nutch爬取每个网站取得链接,因为每个网站的结构和网站链接的数量不同,爬取网站的链接数不同。为证明MapReduce并行抽取的有效性,通过串行抽取和MapReduce并行抽取的时间对比出其性能,串行抽取是每次只对一个职位信息进行抽取。
表1展示了基于CSS路径并行化职位抽取的精确度和召回率的结果,精确度P和召回率R作为评价标准。从表1的实验结果可以看出,尽管抽取职位信息网站结构不同但是抽取的准确度高于95%,由此证明基于CSS路径模板的并行化职位信息抽取是有效的。

表1 职位抽取精确度结果
图4展示了对5个招聘站爬取的职位信息使用串行和并行化职位信息抽取的结果对比,从实验结果可以看出,随着职位信息量的增加,串行和并行信息抽取在时间上的差距增大。因为并行化职位抽取是在MapReduce分布式并行化框架上实现,实现了职位信息的并行化抽取,有效提高职位信息的速率。
图5展示的是基于CSS路径和基于DOM方法的职位信息抽取,从实验结果看出,基于CSS路径的职位信息抽取方法的准确率高于DOM方法,因为基于CSS路径的方法是根据职位信息标签所对应的属性进行定制职位信息抽取规则,该方法可以有效定位职位信息的抽取位置,从而提高职位信息抽取的准确性。因为DOM方法对HTML结构要求比较严格,从而影响了信息抽取的准确性。
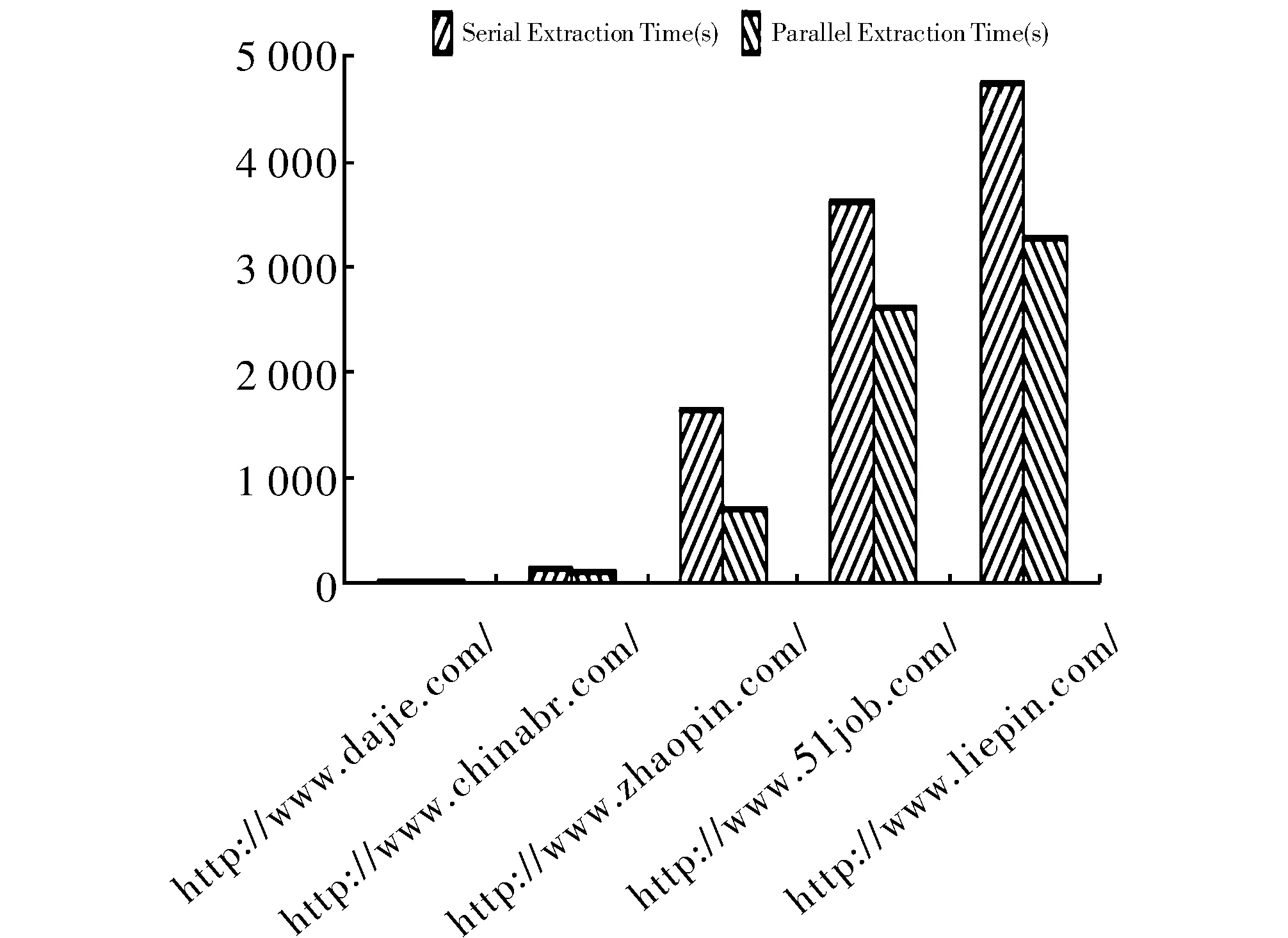
图4 串行和并行化职位抽取结果
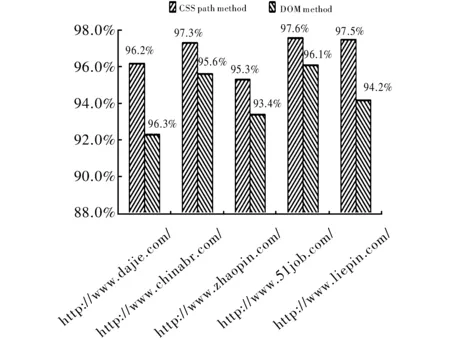
图5 职位信息抽取方法对比
4 结束语
本文提出了针对海量异构职位页面的信息抽取方法。利用网页模板的方法对异构站点职位页面进行信息抽取,实现了同时对多个不同结构的网站进行信息抽取,提高了信息抽取效率;采用基于MapReduce分布式计算框架对网页信息进行抽取,解决了针对大数据量处理速度缓慢的问题;采用MD5算法基于MapReduce的去重算法,并将职位信息存储到HBase数据库中解决了职位信息的冗余问题。实验结果表明,本文所提出的方法在抽取职位信息的正确率和抽取效率上有明显提高。
[1] Gkotsis G, Stepanyan K, Cristea A I, et al. Self-supervised automated wrapper generation for weblog data extraction[J]. Lecture Notes in Computer Science, 2013, 79(4):292-302.
[2] 安增文,王超,徐杰锋.基于机器学习的网页正文提取方法[J].微型机与应用,2010(12):4-6.
[3] 祝伟华,卢熠,刘斌斌.基于HMM的Web信息抽取算法的研究与应用[J]. 计算机科学, 2010, 37(2):203-206.
[4] Giuseppe Della Penna,Daniele Magazzeni,Sergio Orefice.Visual extraction of information from web pages original research article[J]. Journal of Visual Languages & Computing, 2010(21):23-32.
[5] 安增文,徐杰锋.基于视觉特征的网页正文提取方法研究[J].微型机与应用,2010(3): 38-41.
[6] Xu Hongzhen,Li Lihua. A Web information extraction method based on DOM tree structure and information entropy[J]. WIT Transactions on Information and Communication Technologies, 2014(55):477-484.
[7] 常红要,朱征宇,陈烨,等. 基于HTML标记用途分析的网页正文提取技术[J].计算机工程与设计,2010 (24):5187-5191.
[8] 罗刚.自己动手写网络爬虫[M]. 北京: 清华大学出版社,2013.
[9] White T. Hadoop: The Definitive Guide[J]. O’reilly Media Inc Gravenstein Highway North,2010,215(11):1-4.
[10] Andrew Taggart. Hadoop mapreduce[EB/OL]. (2011-07-14)[2015-10-14]http://wiki.apache.org/hadoop/HadoopMapRduce.
[10] Rivest R. The MD5 message-digest algorithm[J]. IETF RFC, 1992, 473(10):492-492.
[11] Lars George. HBase:the definitive guide [M]. 代志远, 刘佳, 蒋杰,译. 北京: 人民邮电出版社,2015.
Research on and Implementation of the Parallel Information Extraction System on Recruitment with CSS Template
A parallel position information extraction method based on CSS template is proposed to address the high redundancy and low efficiency due to the lack of adaptability and parallelism by existing position information extraction method. The information extraction that employs the CSS path builds the extraction template according to the structure of the job web page, thus guaranteeing the accuracy and adaptability. The parallel extraction is based on the MapReduce. The MD5 algorithm is used to compute the value of extracted information, and the values are used in the Reduce function to reduce the duplicate position information. Finally, the position information is saved in HBase, a distributed column-oriented database. Experimental results on a set of data show that the proposed approach offers better extraction efficiency and the speed than the non-parallel extraction programming model.
information extraction; MapReduce; CSS template; MD5 algorithm; HBase
2016- 01- 04
江苏省科技型企业创新基金资助项目(BC2014212);江苏省普通高校研究生科研创新计划基金资助项目(SJLX_0470)
薛安荣(1965-),男,博士,教授,硕士生导师。研究方向:数据库与数据挖掘。王丹(1989-),女,硕士研究生。研究方向:数据挖掘。黄祖卫(1991-),男,硕士研究生。研究方向:数据挖掘。
10.16180/j.cnki.issn1007-7820.2016.10.026
TP391
A
1007-7820(2016)10-093-04
