钢铁工业逆向供应链服务模块化方法
2016-06-04熊颖清夏绪辉
熊颖清,夏绪辉,王 蕾,向 红
(武汉科技大学机械自动化学院,湖北 武汉,430081)
钢铁工业逆向供应链服务模块化方法
熊颖清,夏绪辉,王蕾,向红
(武汉科技大学机械自动化学院,湖北 武汉,430081)
摘要:钢铁工业逆向供应链服务系统是一种典型的复杂系统,其各项原子服务的实现涉及大量的服务资源,且原子服务之间以及服务活动与服务资源间存在多重关联关系,为此提出一种基于多维耦合关系的服务模块化方法,将钢铁工业逆向供应链标准服务流程进行分解得到原子服务,从功能、物理和需求等三个维度分析原子服务间的耦合关系,构建综合耦合矩阵及服务模块化测度,采用改进型遗传算法对原子服务进行聚类优化。通过高炉渣回收再利用的案例验证了该服务模块化方法的有效性。
关键词:钢铁工业;逆向供应链;服务;模块化;原子服务;耦合;遗传算法;聚类
钢铁工业是我国国民经济的重要基础产业,其生产过程中产生的废弃物长期处于低水平利用状况。从发展循环经济的角度出发,钢铁工业逆向供应链服务是实现废弃物资源化从而促进钢铁工业科学发展的重要途径[1]。钢铁工业逆向供应链服务是一个复杂的系统运作过程,涉及种类繁杂的服务资源和服务活动,在服务系统管理及服务过程实现中存在着诸多困难。服务模块化作为复杂服务系统运作的关键技术,可进行系统的调整和分割,根据功能、时间等属性特征的不同将连续性服务划分为离散模块组合[2]。服务模块化起源于服务业,之后逐渐扩展到生产性或服务性组织的服务系统之中,人们从不同角度出发对服务模块化进行了研究。例如,吴照云等[3]将服务模块化划分为服务系统的模块化和服务流程的模块化;陶颜等[4]认为服务模块化是合并型多维构念,包含服务产品模块化和服务流程模块化两个子维度;关增产[5]指出,服务模块划分包含服务内容、服务流程、服务资源、服务组织的划分; Li等[6]提出一个三阶段交互式集成服务型产品模块划分方法,给出了物理模块和服务模块的划分原则及交互影响关系;李浩等[7]系统归纳了广义产品的模块化设计方法,讨论了面向服务的产品模块化设计的可能研究方向,如个性化设计、生态化设计、智慧化设计等;Wang等[8]用需求聚类法来识别客户需求价值,提出基于本体模型的产品服务配置方法,构建了基于产品服务本体的产品服务模块化系统;董明等[9]提出一种基于本体的模块化建模和配置方式,在产品建模中对服务要素采用可达矩阵方法进行模块划分。
以上文献主要从服务模块化的概念、划分准则以及产品服务模块化系统等方面进行了研究,而涉及服务模块的模型构建、定量计算及优化方法的研究较少。为此,本文将钢铁工业逆向供应链服务流程分解为原子服务活动(atomic service,AS),从功能、物理和需求等三个维度分析原子服务活动间的关联耦合性,建立原子服务综合耦合矩阵模型,并构建服务模块化测度,然后运用矩阵编码的改进型遗传算法进行聚类优化,最终获取标准服务模块,以期有利于提高后续服务模块配置效率,提升钢铁工业逆向供应链服务系统的需求响应能力和服务运作效率。
1钢铁工业逆向供应链服务模块化过程
钢铁工业逆向供应链服务模块化是将标准服务流程分解后再聚类为一系列的服务模块。依据钢铁工业废弃物资源化标准服务流程,从功能角度将标准服务流程分解为独立的原子服务,并根据多维耦合关系将原子服务聚类成通用服务模块,使得服务模块内部的内聚度尽可能高,服务模块之间的耦合度尽可能低。该通用服务模块可与钢铁工业逆向供应链上的服务提供商可提供的服务模块进行自适应匹配,筛选出满足通用服务模块需求的服务资源,钢铁工业逆向供应链服务模块化过程如图1所示。
2原子服务的多维耦合关联分析

图1 钢铁工业逆向供应链服务模块化过程
Fig.1 Modularizing process of reverse supply chain service for iron and steel industry
耦合关联分析是从一个或多个角度来度量两个或多个实物间的相似度或关系紧密度。结合钢铁工业逆向供应链服务流程特点及原子服务的属性特征,从功能耦合、物理耦合和需求耦合三个维度分析原子服务的关联关系。
(1)功能耦合关联,主要考虑钢铁工业逆向供应链服务过程中各个服务活动在服务功能方面的连接紧密度,即实现功能的相似度。
(2)物理耦合关联,包括时间、地域、服务资源三方面。时间耦合关联是考虑原子服务之间的时间相继性;地域耦合关联表示两个原子服务是否发生在邻近地理区域;服务资源耦合关联表示两个原子服务在服务资源上的共用性,包括对人员的工作类型及能力、服务设备、服务技术以及服务知识等的共用性。
(3)需求耦合关联,表示服务活动在满足服务需求方面的相似程度。
三种耦合关系的分解如图2所示,其中{ω1,ω2,ω3}分别表示功能、物理、需求耦合的权重,{ω21,ω22,ω23}分别表示物理耦合中时间、地域、资源耦合的权重,所有权重均在[0, 1]区间取值。
设有n项原子服务,Afij表示原子服务i、j在功能上的相似度,Aptij表示原子服务i、j在时间上的相继程度,Aplij表示原子服务i、j在地域上的邻近程度,Apsij表示原子服务i、j在服务资源上的相似程度,Apij表示原子服务i、j对物理信息的关联程度,Arij为原子服务i、j对需求信息的关联程度。原子服务之间的耦合关联程度根据表1进行量化处理。
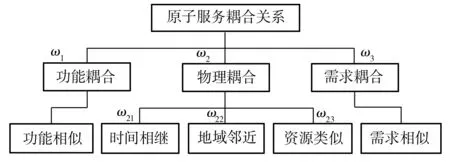
图2 原子服务耦合关系的分解
Fig.2 Decomposition of coupling relationship between atomic services
表1原子服务耦合关联程度的量化
Table 1 Quantification of coupling degree between atomic services

耦合关系量化值描述无关联0两个原子服务间没有连接或相似度弱关联1两个原子服务间连接或相似度较弱中等关联5两个原子服务间连接或相似度中等强关联9两个原子服务间连接或相似度较强
令服务过程中任意两个原子服务i、j的综合耦合度为Cij,则有:
(1)
(2)
(3)
(4)
3服务模块的聚类优化
本文采用基于目标函数值的聚类优化方法,通过改进型遗传算法对原子服务模块进行聚类优化。
3.1服务模块化测度
服务模块粒度的大小直接影响后序与服务提供商所提供的服务资源模块的匹配效率以及服务方案的优越性。服务模块粒度较大,则包含较多的服务活动,能够提供较多的服务功能,涉及的服务资源复杂,服务模块内的内聚度较高,服务模块间的耦合程度较低。反之,服务模块粒度较小,则包含的服务活动、提供的服务功能较少,涉及的服务资源较简单,服务模块内的内聚度较低,服务模块间的耦合程度较高。可根据服务模块松散耦合性构建一种服务模块化测度,对服务模块进行划分。本文采用文献[10]中的模块度作为服务模块聚类优化函数,其由平均聚合度和平均耦合度之差构成。
服务模块内原子服务间的平均聚合度计算方法为:
(5)
服务模块之间的平均耦合度计算方法为:
(6)
服务模块度优化函数为:
(7)
约束条件为:

(8)
(9)
式(5)~式(9)中:nk为第k个模块中第一个原子服务在聚类后的原子服务序列中的序号;mk为第k个模块中最后一个原子服务在聚类后的原子服务序列中的序号;rij为聚类后的综合矩阵中第i行和第j列的元素;F为模块化方案的模块度;D为原子服务聚类后的服务模块数量。
3.2改进型遗传算法
3.2.1染色体编码方式
采用矩阵编码方法根据原子服务综合耦合度矩阵进行服务模块化方案编码。对于一个由n个原子服务构成的综合耦合分析矩阵,假设综合矩阵的最大聚类模块数为m,则最后得到的综合耦合矩阵为m×n矩阵。矩阵中行元素表示聚类模块,列元素表示原子服务。矩阵中每个单元格的值取0或1,值为1表示该列对应的原子服务在该行对应的聚类模块中,值为0则表示其不在对应的聚类模块中,且每一列元素中有且仅有一个单元格的值为1。矩阵编码示例见图3,设有原子服务{N1,N2,N3,N4,N5,N6},最大聚类数为4,服务模块为{D1,D2,D3,D4},所得到的编码矩阵为4×6矩阵。其中,服务模块D1中有{N1,N2,N5}对应的三个元素值为1,其它元素值为0,说明原子服务{N1,N2,N5}被划分到模块D1中;而服务模块D4的所有元素值为0,说明该行为冗余行,没有对应的服务模块。

N1N2N3N4N5N6服务模块D1110010服务模块D2001100服务模块D3000001服务模块D4000000
图3矩阵编码示例
Fig.3 Example of matrix coding
编码后生成初始化种群,方法如下:对于一条染色体(m×n矩阵),在每一个列向量的第1行到第m行的所有单元格中任取一个单元格,将其值取为1,其余单元格都为0,这样就得到了一条已经完成编码的染色体;反复执行可生成不同的染色体,直到获取足够的染色体为止。
3.2.2选择、交叉和变异算子
选择算子采用锦标赛选择方法,以模块度作为适应度值,每次选取个体中适应度最高的几个个体遗传到下一代群体中。该方法的优点是对个体适应度取正负值无要求,随机性较强,有较高概率保证最优个体被选择、最差个体被淘汰。
交叉算子采用两点交叉法,从当前种群中选择出两个父染色体,在父染色体的列中随机选择两个整数作为交叉点,将两条染色体中位于交叉点之间的列相互交换,其余列保持不变。
变异算子在基本变异法[11]的基础上进行了改进。基本变异法是在一条父染色体矩阵中任意选择两列进行交换,其余列保持不变。在选择出的两列属于同一聚类模块时,该方法虽然对这两列进行了位置交换,但得到的子染色体与父染色体仍然是相同的,导致变异没有产生新的个体,降低了种群的多样性,容易陷入局部最优。改进后的变异方法为:选择出一个父染色体矩阵,从矩阵中随机选择出两列作为变异点,分别将其数值为1的行变为0,再从其余行中随机选择一行,使其中的数值变为1。这样就可以保证变异产生的子染色体与父染色体不一样。图4所示为基本变异和改进变异的操作过程。
3.3服务模块数

4应用案例
4.1案例介绍与综合耦合矩阵的建立
以某钢铁公司炼铁厂产生的高炉渣的回收再利用为例。该厂一个季度预计产生高炉渣10万吨,要求将作业现场的高炉渣及时运走。高炉渣的标准回收再处理流程包含的原子服务有{高炉渣过水服务、装车服务1、矿渣运输服务、卸车服务1、矿渣滤液服务、矿渣配料服务、散装服务、装车服务2、运输服务、卸车服务2、玻璃加工服务、水泥加工服务、砖窑加工服务}。各原子服务的属性特征分析如表2所示。
根据表1 及表2构建原子服务的功能耦合矩阵[Afij]n×n、需求耦合矩阵[Arij]n×n、时间耦合矩阵[Aptij]n×n、地域耦合矩阵[Aplij]n×n和服务资源耦合矩阵[Apsij]n×n等,其中功能耦合矩阵如下:
Fig.4 Schematic diagram of the basic and improved variation methods

表2 高炉渣回收再利用的原子服务属性特征
权重取ω1=0.33、ω21=0.11、ω22=0.12、ω23=0.11、ω3=0.33,根据式(1)~式(4)可得原子服务综合耦合矩阵[Cij]n×n如下:
4.2优化结果与对比分析
采用Matlab软件实现矩阵编码的改进型遗传算法。为了对比分析,本文还同样采用Matlab软件并选择应用较多的FCM算法对高炉渣回收再利用流程包含的原子服务进行模块划分。
4.2.1改进型遗传算法聚类优化结果
设种群数为50,最大进化次数为200,交叉概率为0.95,变异概率为0.1,待聚类原子服务数n=13,最大聚类模块数m=6。运用相关参数进行聚类优化,获得改进型遗传算法的进化收敛过程如图5所示。
由图5可见,最优个体的适应度值为2.83,其染色体编码矩阵为:

根据最优个体的染色体编码矩阵共生成4个服务模块:D1={1,2,3,4}、D2={5,6,7}、D3={8,9,10}、D4={11,12,13},矩阵中还有2行的元素均为0,表示该模块为空。这些服务模块表示:服务模块1包含高炉渣过水服务、装车服务1、矿渣运输服务和卸车服务1;服务模块2包含矿渣滤液服务、矿渣配料服务和散装服务;服务模块3包含装车服务2、运输服务、卸车服务2;服务模块4包含玻璃加工服务、水泥加工服务和砖窑加工服务;服务模块5及6则不含任何原子服务。
4.2.2FCM算法聚类优化结果
在FCM算法中指定模块数为6,则随机生成6个初始聚类中心,计算各样本与初始聚类中心的欧氏距离,共迭代162次,其目标函数值的变化曲线如图6所示。

图5 改进型遗传算法优化历程
Fig.5 Optimization history of improved genetic algorithm
运用FCM算法共产生了6个服务模块:D1={1,2,4}、D2={3}、D3={5,6,7}、D4={8}、D5={9}、D6={10,11,12,13}。服务模块1包含高炉渣过水服务、装车服务1、卸车服务1;服务模块2包含矿渣运输服务;服务模块3包含矿渣滤液服务、矿渣配料服务和散装服务;服务模块4包含装车服务2;服务模块5包含运输服务;服务模块6包含卸车服务2、玻璃加工服务、水泥加工服务以及砖窑加工服务。
4.2.3优化结果对比
采用改进型遗传算法进行服务模块划分时,只需指定最大模块数,最后的聚类结果则根据适应度函数值可进行自适应调整;采用FCM算法时需指定具体的模块数,如果模块数指定不合适,则会出现不合理的服务模块。例如:在上述两种算法中均指定初始分类模块数为6,改进型遗传算法根据适应度函数值通过遗传操作最终生成4个服务模块;而FCM算法随机生成6个初始聚类中心,并根据目标函数值聚类生成6个服务模块。在FCM算法的聚类结果中,服务模块D2、D4、D5中均只含有一个原子服务。D2服务模块中的原子服务为矿渣运输服务,发生在炼铁厂和矿渣厂之间。D1服务模块中的高炉渣过水服务(原子服务1)和装车服务1(原子服务2)发生在炼铁厂,卸车服务1(原子服务4)发生在矿渣厂。很明显需要有矿渣运输服务才能将装车服务1和卸车服务1划分在一个服务模块。因此,将原子服务1、2、3和4划分在同一服务模块中更合适,即改进型遗传算法的划分结果更合理。同时,FCM算法聚类后产生的模块数指定为6,生成的模块数较多,将对后续服务模块的匹配效率及服务方案的合理性产生不利影响。因此,在实际应用中改进型遗传算法比FCM算法更适用于钢铁工业逆向供应链服务模块的划分。
5结语
本文提出了一种基于多维耦合关系的钢铁工业逆向供应链服务模块化方法。从功能、物理以及需求三个维度来分析钢铁工业逆向供应链原子服务间的耦合关系,构建了原子服务综合耦合矩阵及服务模块化测度,采用改进型遗传算法对原子服务模块进行聚类优化,并将优化结果与指定聚类模块数的模糊C均值聚类方法得出的结果进行了对比分析,验证了改进型遗传算法的可行性及有效性。钢铁工业逆向供应链服务模块的合理划分可提高服务模块匹配效率,使服务系统能够更快速地响应客户个性化的服务需求,同时又发挥了服务生产的规模经济和范围经济效应。

图6 FCM算法优化历程
Fig.6 Optimization history of FCM algorithm
参考文献
[1]王蕾,夏绪辉,熊颖清,等.钢铁工业逆向供应链服务过程模型[J].工程科学学报,2015,37(6):812-821.
[2]Stremersch S, Weiss A M, Dellaert B G C, et al. Buying modular systems in technology-intensive markets[J]. Journal of Marketing Research,2003, 40(3): 337-348.
[3]吴照云,余长春,尹懿.服务模块化的研究现状及发展趋向[J].商业经济与管理,2012(3):36-42.
[4]陶颜,孔小磊.服务模块化评价指标体系的构建[J].技术经济,2015,34(6):7-11.
[5]关增产.面向大规模定制的服务模块化研究[J].价值工程,2009(11):99-103.
[6]Li Hao, Ji Yangjian, Gu Xinjian, et a1. Module partition process model and method of integrated service product[J].Computers in Industry, 2012, 63(4): 298-308.
[7]李浩,祁国宁,纪杨建,等.面向服务的产品模块化设计方法及其展望[J].中国机械工程, 2013,24(12):1687-1694.
[8]Wang P P, Ming X G, Wu Z Y, et al. Research on industrial product-service configuration driven by value demands based on ontology modeling[J].Computers in Industry, 2014, 65(2):247-257.
[9]董明,苏立悦.大规模定制下基于本体的产品服务系统配置[J].计算机集成制造系统,2011,17(3):653-661.
[10]洪城.绿色产品模块化与供应链联合设计方法[D].杭州:浙江大学,2014.
[11]唐敦兵, 钱晓明, 刘建刚. 基于设计结构矩阵DSM的产品设计与开发[M].北京:科学出版社,2009.
[12]Tseng Hwai-En, Chang Chien-Chen, Li Jia-Diann. Modular design to support green life-cycle engineering[J].Expert Systems with Applications,2008, 34: 2524-2537.
[13]Kreng V B, Lee T-P. Modular product design with grouping genetic algorithm—a case study[J].Computers and Industrial Engineering, 2004, 46: 443-460.
[14]田夏. 基于种群遗传算法的产品全生命周期模块化设计方法[D]. 上海:上海交通大学,2009.
[责任编辑尚晶]
Modularization of reverse supply chain service for iron and steel industry
XiongYingqing,XiaXuhui,WangLei,XiangHong
(College of Machinery and Automation, Wuhan University of Science and Technology, Wuhan 430081, China)
Abstract:Reverse supply chain service system for the iron and steel industry is a typical complex one, and the implementation of its atomic services involves a lot of service resources. There are multiple relationships among the atomic services, and between the service activities and resources, so this paper presents a service modularizing method based on multi-dimensional coupling relationship. The standard service process of reverse supply chain for the iron and steel industry is decomposed into multiple atomic services whose coupling relationships are analyzed from the functional, physical and demand dimensions. Then the comprehensive coupling matrix and the measure of service modularization are built. An improved genetic algorithm is used to cluster the atomic services optimally. The effectiveness of the proposed service modularizing method is verified by the case of blast furnace slag recycling.
Key words:iron and steel industry; reverse supply chain; service; modularization; atomic service; coupling; genetic algorithm; cluster
收稿日期:2015-10-20
基金项目:国家自然科学基金资助项目(71471143);武汉科技大学冶金工业过程系统科学湖北省重点实验室开放基金资助项目(Y201501).
作者简介:熊颖清(1984-),女,武汉科技大学博士生.E-mail: yingqingxiong@163.com 通讯作者:夏绪辉(1966-),男,武汉科技大学教授,博士生导师.E-mail: xiaxuhui@wust.edu.cn
中图分类号:F406
文献标志码:A
文章编号:1674-3644(2016)01-0041-07
