Cassandra应用研究
2016-05-18秦苻珂
秦苻珂

摘要:该文介绍了NoSQL数据库Cassandra的数据模型和部署方法,介绍了基于java语言和Thrift API的Cassandra应用的开发方法。
关键词:NoSQL;数据库; Cassandra; java; Thrift API
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)09-0014-03
Research on the Application of Cassandra
QIN Fu-ke
(Beijing Jin Rong Wan Chang Technology Co., LTD., Beijing 100081, China)
Abstract: This paper introduces the data model and the deployment method of NoSQL Cassandra database, introduces the development method of Cassandra using Java and based on Thrift API.
Key words: NoSQL;database; Cassandra; java; Thrift API
随着互联网技术的迅猛发展,使传统的关系型数据库在处理海量数据访问时面临巨大的挑战[1],并暴露出了很多难以克服的问题[2],如:海量数据存储能力、高扩展性、高并发读写能力等。从关系型数据库本身来解决这些问题则代价昂贵,从而人们开始把目光转向NoSQL数据库。NoSQL是Not Only SQL的简写,其含义是“不仅是结构化查询”,是不同于传统的关系型数据库的数据库管理系统的统称[3]。
Cassandra则是众多NoSQL数据库中的一种,它属于最近比较流行的NoSQL数据库,最初由Facebook开发,后转变成开源项目,贡献给了Apache。作为一种流行的NoSQL数据库,Cassandra具有扩展能力强、大数据量、高性能、灵活的数据模型、高可用性等优点[4],从而弥补了关系型数据库的不足,极大地节省了开发成本和维护成本[5]。
本文将介绍NoSQL数据库Cassandra的数据模型以及其部署方法,并介绍Cassandra应用的开发方法。
1 Cassandra数据模型
Cassandra的数据模型是一个四维或五维模型(如图1所示),相对应Cluster、Keyspace、ColumnFamily、(SuperColumn)、Column这几个维度。其中某一Column或SuperColumn与一指定的Key相对应,在获取数据的时候,通过这个Key为来获取对应的Column或SuperColumn。Cassandra的数据模型借鉴了Amazon 的 Dynamo 和 Google's BigTable 的数据结构和功能特点,采用 Memtable 和 SSTable 的方式进行存储。在 Cassandra 写入数据之前,需要先记录日志,然后数据开始写入到 Column Family 对应的 Memtable 中。Memtable 是一种按照 key 排序数据的内存结构,在满足一定条件时,再把 Memtable 的数据批量的刷新到磁盘上,存储为 SSTable。
图1 Cassandra模型
1) COLUMN
Column是Cassandra中最小的数据单元。它是一个三元组,包含:name,value和timestamp。这里的name和value都是byte[]类型的,长度不限。
2) SUPERCOLUMN
SuperColumn是一类特列殊的 Column, 它的 Value 值可以包含多个 Column。Column是name、value和timestamp的组合;而SuperColumn是name与value的组合,其本身不包含timestamp。另外,Column的value是单纯的值,而SuperColumn的value是一组Column。
3) COLUMNFAMILY
ColumnFamily是用于存放 Column 的容器,它包含很多Row,和关系型数据库中的Table相类似。Row则类似为关系型数据库中的记录。每一个Row都包含有一个Key以及和该Key相关联的一系列Column。
ColumnFamily可以是Standard类型的,也可以是Super类型的。 它们的区别是:Standard类型的ColumnFamily包含一系列的Column;而
Super类型的ColumnFamily则包含一系列的SuperColumn。
4) KEYSPACE
Keyspace是我们的数据的最外层,相当于关系型数据库的 Schema 或 database,所有的ColumnFamily都属于某一个Keyspace。通常我们的一个应用只会使用一个Keyspace。
5) Cluster
Cassandra 的节点实例,它可以包含多个Keyspace。
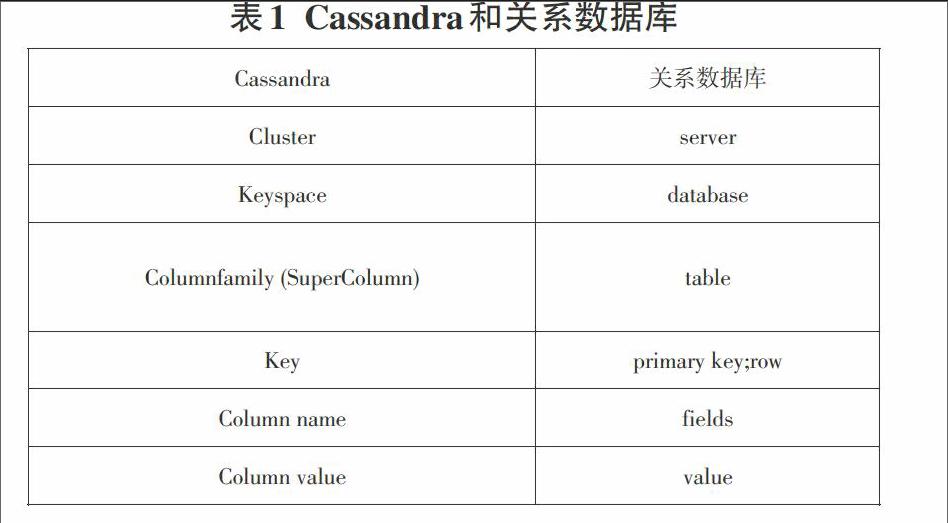
Cassandra和关系型数据库的对比如表1所示:
2 部署Cassandra
2.1 windows下部署
部署步骤如下:
1)在安装之前要确认已经安装好了JDK1.6。
2)下载安装文件并解压。
安装文件可以去http://cassandra.apache.org/下载。下载后将下载的压缩包解压到指定目录,比如解压到D:\apache-cassandra-3.2.1。
3)设置配置文件。
在配置文件conf/cassandra.yaml中存在目录的配置项:data_file_directories、commitlog_directory、saved_caches_directory,要确保配置正确。同样,配置文件conf/log4j.properties也包含log文件的目录,也要确保正确。
4)运行bin目录下的cassandra.bat,启动cassandra服务。
5)运行bin目录下的cassandra-cli.bat。
6)在命令行输入:connect localhost /9160,连接成功后可以看到下面的提示:Connected to:”** Cluster” on localhost /9160。
2.2 Linux下部署
在Linux部署Cassandra的步骤与在Windows上部署的步骤基本类似。
3 应用程序开发
和关系型数据库系统的开发一样,首先要解决的是应用程序和数据库的交互问题。对于Cassandra来说,主要是使用Cassandra自带的API和Cassandra服务器进行交互。其自带的最简单的一类API就是Thrift API。而所有其他更加高级的API都是基于Thrift API来封装的。基于Thrift API是支持多语言开发的,我们可以使用不同的语言开发Cassandra应用程序。本文采用了java语言,基于Thrift API,对Cassandra应用的开发进行了基本的介绍。
Thrift是通过Transport和Protocol两种抽象机制来完成应用程序和数据库服务器之间的通信的。Transport抽象了底层网络通信的接口;Protocol抽象了对象在网络中传输的接口。Transport在传输数据时是不区分所传输数据的类型的,一律以流的形式传输;Protocol类则在Transport类之上实现了按数据类型来传输数据的方法。
Transport抽象类包含open、close、isOpen、read、write和flush六个接口函数。
基于Cassandra的应用的开发和关系型数据库系统开发过程一样:
1) 导入JAR包
我们可以将lib下面的JAR包apache-cassandra-3.2.1.jar和libthrift.jar加入到 Eclipse 的编译路径中。
2) 建立数据库连接
使用TTransport 的open方法建立与Cassandra 服务器端 (IP:192.168.1.212 端口:9160) 的连接。open()函数首先调用isOpen()函数判断链接是否已建立。如果已经建立,则抛出异常;如果没有建立则首先创建Socket对象并调用Socket类的connect()函数连接需要的主机和端口,然后通过Socket类创建输入输出流。
3) 数据库操作
使用 Cassandra.Client创建一个客户端实例。调用Client 实例的insert方法写入数据,调用get或get_slice等方法获取数据。
insert方法插入一个包含name, value, timestamp值的Column,这个Column不是SuperColumn。
get方法通过指定的key和column_path获得Column 或 SuperColumn。如果没有返回值,将会抛出NotFoundException。
get_slice方法通过key和column_parent取得一组column,其中column_parent指ColumnFamily或者ColumnFamily/SuperColumn。
4) 关闭数据库连接
使用TTransport的close方法断开与Cassandra服务器端的连接。close()函数首先调用父类中的close()函数将输入输出流关闭,然后调用Socket类中的close()函数关闭和主机的连接。
下面的程序是一个操作Cassandra数据库的一个例子:
package org.zywx.appdo.txopen.web.cassandra;
import org.apache.struts2.convention.annotation.Action;
import org.apache.struts2.convention.annotation.Namespace;
import org.apache.cassandra.thrift.AuthenticationException;
import org.apache.cassandra.thrift.AuthorizationException;
import org.apache.cassandra.thrift.Cassandra;
import org.apache.cassandra.thrift.Column;
import org.apache.cassandra.thrift.ColumnOrSuperColumn;
import org.apache.cassandra.thrift.ColumnParent;
import org.apache.cassandra.thrift.ConsistencyLevel;
import org.apache.cassandra.thrift.InvalidRequestException;
import org.apache.cassandra.thrift.KeyRange;
import org.apache.cassandra.thrift.KeySlice;
import org.apache.cassandra.thrift.NotFoundException;
import org.apache.cassandra.thrift.SlicePredicate;
import org.apache.cassandra.thrift.SliceRange;
import org.apache.cassandra.thrift.TimedOutException;
import org.apache.cassandra.thrift.UnavailableException;
import org.apache.thrift.transport.TTransport;
import org.apache.thrift.transport.TFramedTransport;
import org.apache.thrift.transport.TSocket;
import org.apache.thrift.protocol.TProtocol;
import org.apache.thrift.protocol.TBinaryProtocol;
import org.apache.thrift.TException;
import org.apache.thrift.transport.TTransportException;
import java.nio.ByteBuffer;
import java.util.Random;
import java.util.List;
import java.io.UnsupportedEncodingException;
import org.zywx.appdo.entity.app.open.WidgetAppSession;
import org.zywx.appdo.service.cassandra.CasControl;
public class Test {
public static void main(String[] args) throws TTransportException,
UnsupportedEncodingException, InvalidRequestException,
NotFoundException, UnavailableException, TimedOutException,
TException, AuthenticationException, AuthorizationException {
TTransport tr = new TFramedTransport(new TSocket("localhost", 9160));
TProtocol proto = new TBinaryProtocol(tr);
Cassandra.Client client = new Cassandra.Client(proto);
tr.open();
String keyspace = "Keyspace2win";
client.set_keyspace(keyspace);
//record id
String key_user_id = "20110101";
String columnFamily = "Standard1";
//insert data
long timestamp = System.currentTimeMillis();
ColumnParent columnParent = new ColumnParent(columnFamily);
//insert name
Column nameColumn = new Column(ByteBuffer.wrap("name".getBytes()));
nameColumn.setValue("Xiao Wang".getBytes());
nameColumn.setTimestamp(timestamp);
client.insert(ByteBuffer.wrap(key_user_id.getBytes()),
columnParent,nameColumn,ConsistencyLevel.ALL) ;
//insert age
Column ageColumn = new Column(ByteBuffer.wrap("age".getBytes()));
ageColumn.setValue("29".getBytes());
ageColumn.setTimestamp(timestamp);
client.insert(ByteBuffer.wrap(key_user_id.getBytes()),
columnParent,ageColumn,ConsistencyLevel.ALL);
//Gets column by key
SlicePredicate predicate = new SlicePredicate();
predicate.setSlice_range(new SliceRange(
ByteBuffer.wrap(new byte[0]),
ByteBuffer.wrap(new byte[0]), false, 100));
List
client.get_slice(ByteBuffer.wrap(key_user_id.getBytes()),
columnParent, predicate, ConsistencyLevel.ALL);
//Print age
System.out.println(
new String(columnsByKey.get(0).getColumn().getValue()));
//Print name
System.out.println(
new String(columnsByKey.get(1).getColumn().getValue()));
tr.close();
}
}
4 结束语
本文将介绍了NoSQL数据库Cassandra的数据模型以及其部署方法,并介绍了Cassandra应用的开发方法。
直接使用Thrift API进行应用开发会比较高效,不过编程接口使用起来相对也比较复杂,也没有提供连接池。我们可以基于Thrift Java API封装自己的应用接口,或者使用更高级的API接口。比如Hector就是一类基于Thrift Java API封装的更高级的Java API,它不但能够提供连接池,编程接口也更容易使用,我们可以对它进行比较深入的研究。
参考文献:
[1] 苏翔宇. Key-Value数据库及其应用研究[J]. 电脑知识与技术,2012,8(5):1009-1011.
[2] 刘欣. Cassandra数据库安全性分析与改进[J]. 电脑知识与技术,2010,6(35):9929-9931.
[3] 陈明. NoSQL数据库系统[J]. 计算机教育,2013(11):107-111.
[4] apache. http://cassandra.apache.org/.
[5] 孙立. NoSQL开篇——为什么要使用NoSQL [OL]. http://www.infoq.com/cn/news/2011/01/nosql-why.
