中文微博自动文摘生成方法
2016-05-14李方馨李成城
李方馨 李成城


摘要:微博已经成为广大用户发布和获取信息的重要渠道之一,微博平台上集聚着大量的用户群体和文本信息资源,如何从大量的微博信息中准确、有效获取微博事件关键内容至关重要。提出一种基于VSM和LDA主题模型相结合的方法,对微博文本生成自动文摘。实验结果表明,该方法能够比较准确地抽取微博文本的文摘内容,从而实现用户对实时消息的搜索。
关键词:LDA主题模型;中文微博;自动文摘;VSM
DOIDOI:10.11907/rjdk.161596
中图分类号:TP319
文献标识码:A 文章编号:1672-7800(2016)005-0160-03
0 引言
随着互联网的普及和计算机信息技术的高速发展,社交网络平台迅速兴起,并逐渐渗透到社会各用户群体,极大提高了人们交流的频率。如今,微博已经成为广大用户发布和获取信息的重要渠道之一,微博平台上集聚着大量的用户群体和文本信息资源。研究如何从大量微博文本中快速、准确找到他们感兴趣的内容具有重要意义[1]。
1 微博的文本特性
本文以新浪微博的文本内容作为背景语料进行话题文摘研究,其主要特征有:①篇幅短小,信息量小。每条微博输入文本的字符数限定在140个字符以内,微博所表达的信息量有限;②数据类型多,包含大量噪声。微博上内容包含文本、图片、视频、表情、网络用语和超链接等,由于用户在平台上的表达以快捷、及时为主,因而文本的精确性不高,包含缩写、不规范词汇、错误词汇等多种噪音数据[2];③传播速度快,实时性强。微博文本的更新速度与传播速度很快,一条有价值的消息被公布之后,往往会在很短的时间内被大量转发。
2 相关工作
2.1 语料获取及预处理
本实验选用新浪微博的文本数据作为实验语料。通过新浪微博开放平台的API接口获取微博文本数据,实现微博数据自动爬取。
由于微博文本字数少,大多微博是一个句子或者一个短语。这就导致文本处理时的数据稀疏问题。所以,在预处理阶段首先去除微博长度小于20字的内容;其次,根据正则表达式,除去内容中含有视频和语音的超链接;最后过滤掉“@”及后面的用户名部分。通过中国科学院的汉语词法分析系统ICTCLAS进行中文分词。按照停用词表中的词语将语料中对文本内容识别意义不大但出现频率很高的词、符号、标点、副词、助词等频度高的词及乱码等去掉。在已有停用词表的基础上,统计微博中出现频率过高且无意义的词语和符号,如“转发”等,构建出适用于中文微博文本的停用词表,对中文分词后的词语进行停用词过滤。
2.2 基于向量空间模型的微博文本建模
3 LDA主题模型介绍
LDA(Latent Dirichlet Allocation)主题模型由Blei提出,是一个针对离散数据集建模的主题生成模型,用一个服从Dirichlet分布的K维隐含随机变量表示文档话题混合比例,模拟文档产生过程,通过变分方法推断话题隐变量[4]。
LDA模型是一个三层贝叶斯网络结构的有向概率图模型,分别为词层、主题层和文档层。它将每个文档表示为一个主题混合,每个主题是固定词汇表上的一个多项式分布。首先,假设文档与文档之间顺序无关,文档中单词与单词之间顺序无关,仅考虑文本的词频,而不考虑单词在文本中出现的先后顺序及其约束关系。然后,根据单词在文档中的分布建立文档单词矩阵,再将该矩阵分解为文档主题与主题单词矩阵,相应的单词即会聚类到特定的主题中去。通过对LDA模型中参数的调节,可以使特定的单词分配到对应的主题[5]。
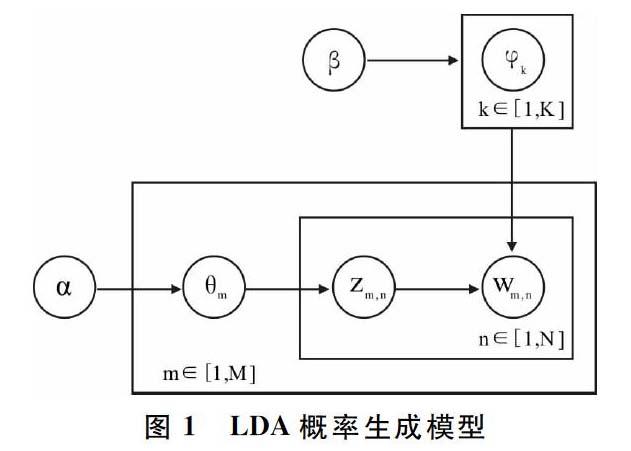
LDA的概率模型图如图1所示。其中,θm表示第m篇文档的主题分布;zm,n表示第m篇文档的第n个单词的主题编号;φk表示主题编号为k时的单词分布;wm,n表示第m篇文档的第n个单词;α和β分别为θm和φk的先验参数;K表示主题个数,M表示文档篇数。
4 微博文摘句抽取
在生成微博文摘时,考虑多种因素衡量句子的权重值,如主题重要度、句子中含有的关键词覆盖度、句子词频、句子长度、评论数和转发数等。
4.1 主题重要度
在微博文本中,叙述一件事或描述一个事物时,都会围绕一个中心主题,同时每一条微博文本会从不同的角度来介绍与主题背景相关方面的内容。根据句子的LDA主题特征,考虑句子主题与抽取到的微博话题的相似度。
4.2 句子中含有的关键词覆盖度
句子中出现关键词的次数越多,则进一步说明该句子的重要性也就越大。所以它也将有一定的优先权被选入到文摘句子当中。
4.3 句子长度
5 实验与结果分析
实验选用新浪微博的文本数据作为实验语料,经过预处理最终得到的中文微博语料,选定5 625条微博数据,分为训练数据3 612条和测试数据1 013条。将VSM和LDA主题模型相结合,对中文微博短文本进行划分类簇。通过对微博的文本分类进行挖掘,构建特征句子中特征词文档和词频文档。设置Gibbs采样的主题数目为6,迭代次数初始值设为100进行反复迭代,得到主题和关键词概率如表1所示。
从实验结果可以看出存在6个潜在主题。根据各个主题的高频关键词可以看出6个主题分别是经济、体育、军事、旅游、健康和教育。由此可见,基于LDA主题模型挖掘得到的主题和关键词不仅准确率较高,而且各个主题之间的独立性强,很容易根据关键词得出相关主题。
模型中存在3个可变量:超参数α和β,以及主题个数K值。令α=50/K,β=0.01,迭代次数均为2 000次。在本实验环境下,经过不同主题数进行多次实验,得出:当主题数K=50时,聚类效果最佳,F值达到最高。抽取到的热门话题语句如表2所示。
实验结果表明,在中文微博语料中生成文摘,相对于单独使用空间向量模型VSM或LDA模型生成微博文摘,VSM和LDA模型的恰当结合可以明显地提高效果。对比空间向量VSM模型,准确率、召回率、F值分别提高了6.9%、11%、9.07%;对比LDA主题模型,分别提高了3.3%、4.1%、3.71%。实验结果如表3所示。
实验证明,VSM和LDA主题模型相结合的方法,能够比较准确地抽取微博文本的文摘内容,进一步挖掘主题和关键词,从而实现用户对实时消息的搜索。
6 结语
本文提出一种中文微博自动文摘方法,在LDA模型的基础上,提出了LDA和VSM结合的自动摘要算法,同时考虑句子特征和由重要主题产生的句子的LDA特征,从而提高摘要的准确率。后续将研究如何利用重要主题自动确定LDA模型的主题个数。
参考文献:
[1]李志清.基于LDA主题特征的微博转发预测[J].情报杂志,2015(9):158-162.
[2]文坤梅,徐帅,李瑞轩.微博及中文微博信息处理研究综述[J].中文信息学报,2012,26(6):27-37.
[3]SHARIFI B,HUTTON M, KALITA J.Experiments in microblog summarization[C].Washington, DC: IEEE Computer Society,2010.
[4]郑影,李大辉.面向微博内容的信息抽取模型研究[J].计算机科学,2014(2):270-275.
[5]姜晓伟,王建民,丁贵广.基于主题模型的微博重要话题发现与排序方法[J].计算机研究与发展,2013(1):179-185.
(责任编辑:陈福时)
