图书自动分类技术研究与实现
2016-05-14刘高军陈东河
刘高军 陈东河
摘要:提出使用TF-IDF算法与朴素贝叶斯算法相结合,实现图书的自动分类。首先需从互联网中爬取图书信息,主要包括图书基本信息、图书简介、图书目录等;其次,需要对爬取到的图书信息进行预处理,将同类图书的基本信息聚在一起,并进行分词去噪;然后使用TF-IDF算法对每一类图书进行特征提取,获得每一类图书的特征;最后使用朴素贝叶斯算法,并利用训练好的分类特征,计算某本新书的具体分类。实验结果表明,该方法可以简化复杂的图书自动分类过程,提高分类效率,也能保证图书分类的准确性。
关键词:图书分类;TF-IDF;朴素贝叶斯
DOIDOI:10.11907/rjdk.161108
中图分类号:TP319
文献标识码:A 文章编号:1672-7800(2016)005-0150-03
0 引言
在图书馆工作中,最复杂、重要且耗时最长的工作就是图书分类工作。图书分类工作通常是由人手工进行,但是由于图书分类的复杂性、多样性、模糊性等因素,使图书分类工作更加困难,准确性也不能够得到绝对保证,仅仅提高工作人员的素质是根本不够的。随着科技的迅速发展,使用新的计算机技术来解决图书分类问题是十分必要的,其中一种比较有效的方法是采用专家系统技术对图书进行自动分类[1]。但是专家系统需要一个覆盖面广、内容充足的知识库,以及拥有强大推理能力的系统支撑,还需要逻辑严谨、类别清晰的规则库才能保证系统的正常运行。因此,构建专家系统是十分困难的,建立知识库与规则库也需要耗费大量的人力、物力。
1 图书分类算法介绍
1.1 TF-IDF算法
TF-IDF是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用于评估字词对于一个文件集或一个语料库中一份文件的重要程度。
在一份给定的文件里,词频指某个给定的词语在该文件中出现的频率。该数字是对词数的归一化,以防止其偏向长的文件。逆向文件频率是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语文件的数目,再将得到的商取对数得到。
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见词语,保留重要词语。
1.2 朴素贝叶斯算法
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。朴素贝叶斯分类是一种十分简单的分类算法,被称为朴素贝叶斯分类是因为该方法的思想非常朴素。其思想基础如下:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大则认为此待分类项属于哪个类别。
朴素贝叶斯分类的正式定义如下:①设{a1,a2,…,am}为m个待分类项,而每个a为x的一个特征属性;②有n个类别的集合{y1,y2,…,yn};③计算当x出现时属于y1的概率,x出现时属于y2的概率,…,直到x出现时属于yn的概率;④如果当x出现时属于yk的概率最大,则x属于yk。
2 图书分类设计与实现
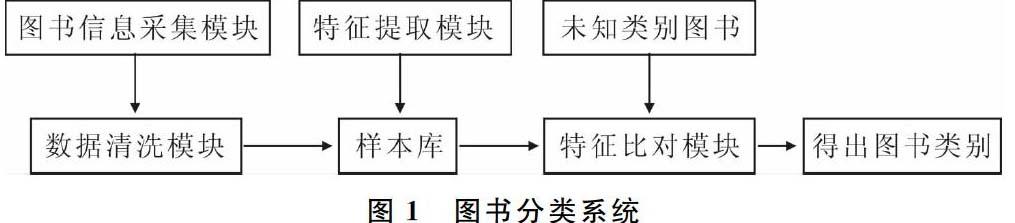
图书分类系统主要分为4大模块,如图1所示。
(1) 图书信息采集模块。图书信息采集模块主要用于图书信息的收集工作。主要功能是从图书电商网站中将图书信息相关页面内容采集到本地,并按照图书电商提供的图书类别将采集到的图书信息聚类在一起。
(2) 图书数据清洗模块。图书数据清洗模块主要功能是将图书信息采集模块收集到的图书网页信息进行分析,去除与图书信息无关的内容,抽取出系统需要的图书信息,并将其存入到样本库中。
(3) 特征提取模块。图书数据清洗模块仅仅是将收集到的图书页面信息中与图书相关的信息抽取出来,而特征提取模块主要功能是从入库后的图书信息中提取出每一类图书的特征,并将相关特征存入数据库。
(4) 特征比对模块。特征比对模块的主要功能是根据样本库中的所有图书类别特征将未知类别的图书进行分类定位,得到该书的类别。
2.1 图书信息采集模块
图书信息采集模块主要是从图书电商中采集图书的基本信息,包括图书名称、作者、出版社、ISBN号、商品编码、出版时间、内容简介、编辑推荐、经典书评、书摘、前言等信息。
图书信息采集模块主要分为4个部分:①选择一个图书网站作为数据源;②将此图书网站中的图书分类采集到本地;③根据采集到的图书分类地址,获取到此类图书的列表,再将图书列表采集到本地;④将每一个图书分类中的图书信息采集到本地。图书信息采集工作不是一次性将一个网站内的图书全部采集完,而是分阶段采集数据,采用这种模式的原因如下:①由于现在各个公司都开始对数据进行保护,很多大型网站都做了防爬取工作,当进行长时间、高频率访问时,将获取不到数据,甚至会封IP,从而达不到数据采集的目的;②由于图书信息采集的数据源多,采集流程较长,各个流程虽有一定联系,但又相对独立,所以采用数据分步落地的方式可以使工作更加安全、有效。
2.2 图书数据清洗模块
图书信息清洗模块主要是将采集到的图书网页信息进行数据清洗,抽取出有意义的图书信息,主要包括图书名称、内容简介、编辑推荐、文摘等。
在图书信息采集模块中,已将图书所在页面采集到本地,并且将同一类图书的页面信息存在同一文件夹下,所以在做数据清洗时,提取结构化信息则变得相对方便。
图书信息清洗模块主要分为3个步骤:①扫描本地图书文件,即扫描爬取到本地的图书网页信息;②分析爬取的图书网页信息,清洗掉与图书无关的信息,将每一本图书的基本信息提取出来;③将抽取出的图书信息存入数据库,作为下一步研究的基本数据。
2.3 特征提取模块
图书结构化信息入库后,需要将每一类的图书特征抽取出来,并且将提取出的特征存入数据库中。
(1) 提取同类图书信息。提取同类图书信息是指将同一类图书的图书名称、内容简介、编辑推荐、文摘信息提取到一个文件中。
(2) 分词、清洗。分词、清洗由两部分组成,即信息分词部分与通用词、停用词清洗部分。其中分词部分是使用NLPIR汉语分词系统进行分词处理,通用词、停用词清洗部分是在分词过程中一并处理的。预先准备通用词和停用词词库,在分词过程中去除出现在通用词和停用词词库中的信息,最终得到确切的图书描述词汇。
(3) TF-IDF算法提取特征。当分词、清洗环节结束时,每一个分类中每一本书的描述信息都已经过处理,得到了更加精炼的描述关键词,再根据每一本图书的关键词,计算出在本类别中出现次数最多,但在其它类别中出现次数最少的词,即可作为本类图书的特征词。其中,由于不同类别包含的图书数量不一致,并不是某一关键词出现在其它类别就不能当作本类图书的关键词,还需要看在本类别中出现的频率是否较高。如在本类图书中与其它图书类别中出现频率都较高,此种情况可视为此关键词既属于本类图书,也可能属于其它类别图书。
2.4 特征比对模块
在特征抽取模块中,已经将每一类图书的特征提取出来,并存入数据库中。在特征比对模块中,需要将某本未知分类的图书进行定位,确认其分类,并将此本图书的关键词加入分类特征中。
(1)获取待分类图书信息。待分类图书信息主要包括图书名称、图书作者、图书简介等,其中图书名称和图书简介信息属于关键信息,图书作者信息属于辅助信息。图书作者信息的主要功能是可以根据作者查询出其在哪些图书类别中发行过哪些图书,从而首先试图在其擅长领域中定位新书,减少处理次数。
(2)待分类图书关键词提取。待分类图书信息是未经处理的原始信息,要通过朴素贝叶斯算法进行图书定位,必须先将图书简介信息进行分词与去噪处理。其中分词部分使用NLPIR汉语分词系统进行处理,去噪部分指去除通用词和停用词。由于图书简介信息内容并不是很丰富,所以在关键词提取阶段应该尽量保留信息,以获得更多图书描述信息。
(3)朴素贝叶斯算法确定分类。根据对朴素贝叶斯算法的介绍,可以知道朴素贝叶斯算法是计算当每一个关键词出现,确认是某一个分类的概率值,然后将每一个关键词在某一个分类中出现的概率值相乘,找出乘积最大的分类,即可以确定此书属于该分类。由于待分类的图书信息有限,而某一个分类的特征词又有很多,再将所求得的概率值相乘,最终会是一个极小的数字,并且当特征词数量在一定的数量级时得到的结果将为0,所以在计算过程中,将每一个关键词出现时确定是某个分类的概率值放大同等倍数,并不会影响计算结果的准确性。
3 实验结果与分析
3.1 实验数据及结果
本文选取从京东商城上爬取的180万本图书信息作为测试样本。根据对样本集的测试,得出每一类图书的特征词抽取个数范围对图书分类的效率和正确性影响最大,具体分析如下:
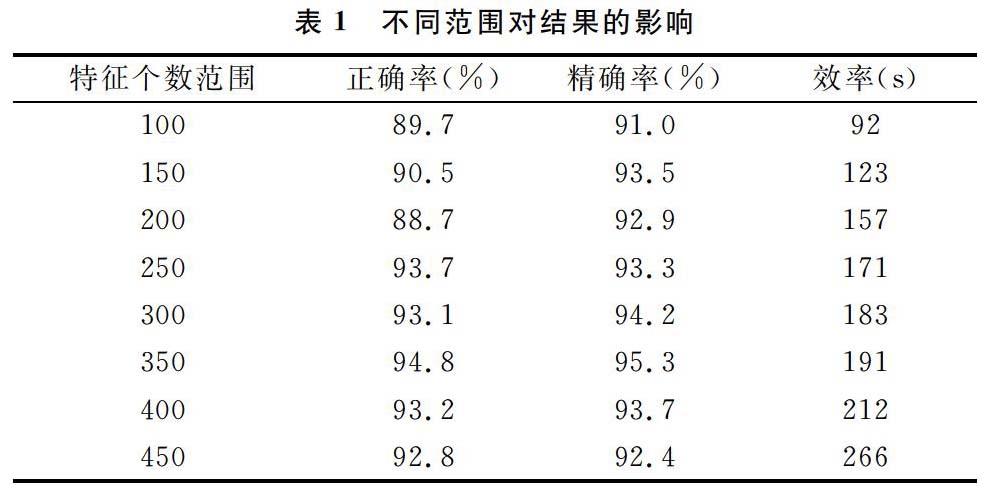
(1) 特征词抽取个数范围对数据结果的影响。在对图书样本集进行训练的过程中,发现在提取不同个数的特征词时,将对最终图书定位产生影响,显示出不同的效率值与准确率。经过不断调整,最终得到了比较理想的效率值和准确率值。图书样本集在选取不同的特征词抽取个数范围时对效率值和准确值的影响如表1所示。
从表1中可以得出,训练数据集中特征词抽取个数对整体结果影响较大。从表中的结果数据不难看出,当特征词抽取个数不够时,虽然效率较高,但是正确性和精确性不高;然而当特征词抽取个数过多时,关键词过多,反而也会使正确性和精确性下降。
(2) 最优值分析。如何确定最优值,是在相同样本训练集情况下、提取特征词个数不同时,产生不同的正确率和精确率以及效率值,再从这些值中选取出正确率、精确率及效率值表现相对较好的结果。
由表1可以判断,当特征词抽取个数为250~400时,正确率、精确率及效率值都相对较好。尤其是当特征词抽取个数为350时,正确率、精确率最高,而效率值波动并不是很大。所以认为当样本信息足够多、数量足够大时,选取350个特征词进行特征比对能得出较为理想的结果。
3.2 实验概述及结果分析
本次实验的目的是希望通过特征提取及特征比对的方法来确定某本未知分类的图书分类。由上述图书分类系统整体结构设计可以看出,实验主要分为3大部分:①图书信息爬取及结构化信息提取;②使用TD-IDF算法提取每一类图书的特征词;③使用朴素贝叶斯算法定位未知图书的分类。由实验结果可知,当特征词抽取个数较多或较少时都会影响最终结果的正确性和精确性。经过反复试验,最终确定出一个较为合理的区间,在该区间中能够得到一个较为准确的结果。
4 结语
在图书馆工作中,图书分类工作十分复杂且耗时,为了解决图书分类问题,已有很多学者开始从事图书自动分类研究工作,并取得了一定成果。本文在这些已有技术的基础上提出了基于TF-IDF及朴素贝叶斯算法来解决图书分类问题。
本文采用互联网图书信息及图书分类作为训练样本进行实验,在图书信息采集过程中遇到了网站防护及数据延迟加载等问题;在数据清洗过程中,分词工具的选择、通用词及停用词词库的构建都十分重要,如果分词工具选择与词库构建不合理,对最终结果正确性的影响将很大;在特征提取阶段,最关键的问题是关键词统计,以及此关键词在其它文档中出现的频率。由于图书种类较多,抽取出的图书关键词也很多,并且未采用分布式系统处理数据,所以在计算和统计时花费了很长时间。在整个系统设计中,特征比对之前的工作都是在做数据集的训练工作。特征比对使用之前训练好的数据来最终确定一本书的分类。由于使用朴素贝叶斯算法进行文本分类处理,并且图书分类较多,每一个分类中的特征关键词也较多,所以最终得到的概率乘积会非常小。当图书分类的特征关键词达到一定数量时,最终得到的结果值会被认为是零,影响结果判断,所以在特征提取时,特征词数量是决定结果正确与否的关键因素。在本文中,经过反复实验,最终得到一个区间,当特征词数量在该区间内时,最终得到相对准确的结果。
综上所述,本文研究针对图书馆情报学图书分类问题,虽然在图书自动分类领域已有一些较为成熟的研究成果,但是本文从另外一种角度,尝试使用不同的技术来分析研究该问题,并且取得了一定成果,对图书馆情报学研究有一定的参考借鉴意义。
参考文献:
[1]张惠.图书自动分类专家系统的研究[J].佛山科学技术学院学报:自然科学版,2001,19(2):37-40.
[2]李静梅,孙丽华,张巧荣,等. 一种文本处理中的朴素贝叶斯分类器[J].哈尔滨工程大学学报,2003,24(1):71-74.
[3]涂茵.图书分类中常见问题探讨[J].河南图书馆学刊,2015(6):62-64.
[4]张笑.图书分类中的问题及对策[J].卷宗,2015(3):21-21.
[5]程克非,张聪.基于特征加权的朴素贝叶斯分类器[J].计算机仿真,2006, 23(10):92-94.
[6]张红蕊,张永,于静雯.云计算环境下基于朴素贝叶斯的数据分类[J].计算机应用与软件,2015(3):27-30.
[7]于秀丽,王阳,齐幸辉.基于朴素贝叶斯的垂直搜索引擎分类器设计[J].无线电工程,2015(11):13-16.
[8]罗欣,夏德麟, 晏蒲柳.基于词频差异的特征选取及改进的TF-IDF公式[J]. 计算机应用,2005,25(9):2031-2033.
[9]韩敏,唐常杰,段磊,等.基于TF-IDF相似度的标签聚类方法[J].计算机科学与探索,2010(3):240-246.
[10]WU H C, LUK R W P, WONG K F,et al.Interpreting TF-IDF term weights as making relevance decisions[J].Acm Transactions on Information Systems, 2008,26(3):55-59.
(责任编辑:黄 健)
