面向博物馆的个性化推荐系统设计与实现
2016-05-14李晨跃刘克剑孟庆瑞
李晨跃 刘克剑 孟庆瑞
摘要:博物馆网站主要展示馆内藏品,繁多的展品使得用户在访问网站时会花费大量时间。可以通过基于Web日志挖掘的技术分析用户的访问行为,判断其兴趣爱好,使用不同的推荐方法主动向用户推荐其可能感兴趣的博物馆藏品,以提高用户访问体验。主要使用4种推荐方式,即热点推荐、类别推荐、相似推荐、猜猜你喜欢。
关键词:推荐系统;日志挖掘;热点推荐;类别推荐
DOIDOI:10.11907/rjdk.161496
中图分类号:TP319
文献标识码:A 文章编号:1672-7800(2016)005-0066-02
0 引言
随着信息技术和互联网的发展,逐渐从信息匮乏时代步入信息超载时代。消费者不易从大量信息中找到自己感兴趣的信息;对于信息生产者,其产品或服务信息受到广大用户的关注,也是一件非常困难的事情[1]。
推荐系统作为一种信息过滤的重要工具,是当前解决信息超载问题的重要方法[1]。推荐系统的任务就是联结用户和信息,一方面,帮助用户发现有价值的信息;另一方面让信息展现在对它感兴趣的用户面前,从而实现信息消费者和信息生产者的双赢。
目前主流的推荐技术包括以下几种:基于内容的推荐、基于用户统计信息的推荐、基于协同过滤的推荐[2]、基于关联规则的推荐。基于物品的协同过滤算法是目前应用最多的算法,它通过分析用户的历史行为来计算物品间的相似度。算法主要分为两步:①计算物品间的相似度;②根据用户历史行为和物品相似度计算用户的推荐列表[3]。度量物品之间相似性的方法有多种,其中之一为使用余弦相似度定义物品和物品之间的相似度。
1 系统需求与数据库设计
用户通过浏览器访问博物馆藏品时,系统基于Web日志挖掘技术分析用户访问行为,判断其兴趣爱好,并主动推荐用户可能感兴趣的藏品,同时通过对用户访问行为的分析,在用户登录时呈现不同的网页界面。如:通过分析发现,某用户对博物馆中西藏植物有较大兴趣,则当该用户再次访问网站时,显示的主要页面是与西藏植物相关的内容;若用户从未访问过网站,将会给予热点藏品推荐,用户访问藏品后,下次再次登录时,网站将会给予相关推荐。
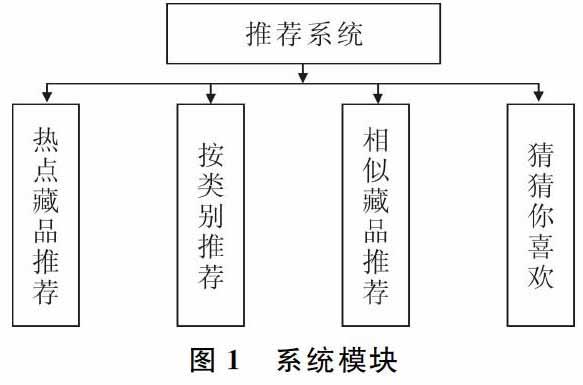
1.1 系统模块
根据用户不同,对于没有登录的游客,系统只使用热点藏品推荐功能;对于已登录游客,如果第一次登录,使用热点藏品推荐;如果是已登录过的会员,系统会调用所有模块进行推荐。模块如图1所示。
1.2 系统功能模块
为了增加推荐系统的多样性,更好服务于用户,设计如下4个推荐功能:热点藏品推荐、按类别推荐、相似藏品推荐、猜猜你喜欢。
(1)热点藏品推荐。从数据库中读取依据点击量排名的藏品,选取点击量前10的藏品推荐给用户,使用基于内容的推荐方法。
(2)按类别推荐。从用户cookie中读取用户浏览过的藏品,获得用户喜好,从用户最近浏览中选出4种类别,然后按类别从数据库中选取该类别的热点藏品推荐给用户,使用基于人口统计的推荐方法。
(3)相似藏品推荐。首先获取最近浏览的前5个藏品,再根据这5个藏品作相似藏品推荐。从相似度表中读取与选出藏品相似的藏品,然后根据相似度排名,选取前4名的藏品作为相似藏品进行推荐,使用基于内容的推荐方法。
(4)猜猜你喜欢。用户点击一个藏品,藏品的关键词就会记录到数据库中,若某藏品也包含该关键词,则这个关键词在数据库中的访问量加1,选出访问量靠前的关键词,这些关键词能代表用户的兴趣爱好。然后从倒排文件中选出包含这些关键词的所有藏品,对这些藏品包含关键词的个数进行排序,选取包含关键词多的藏品推荐给用户,使用基于物品协同过滤的方法。
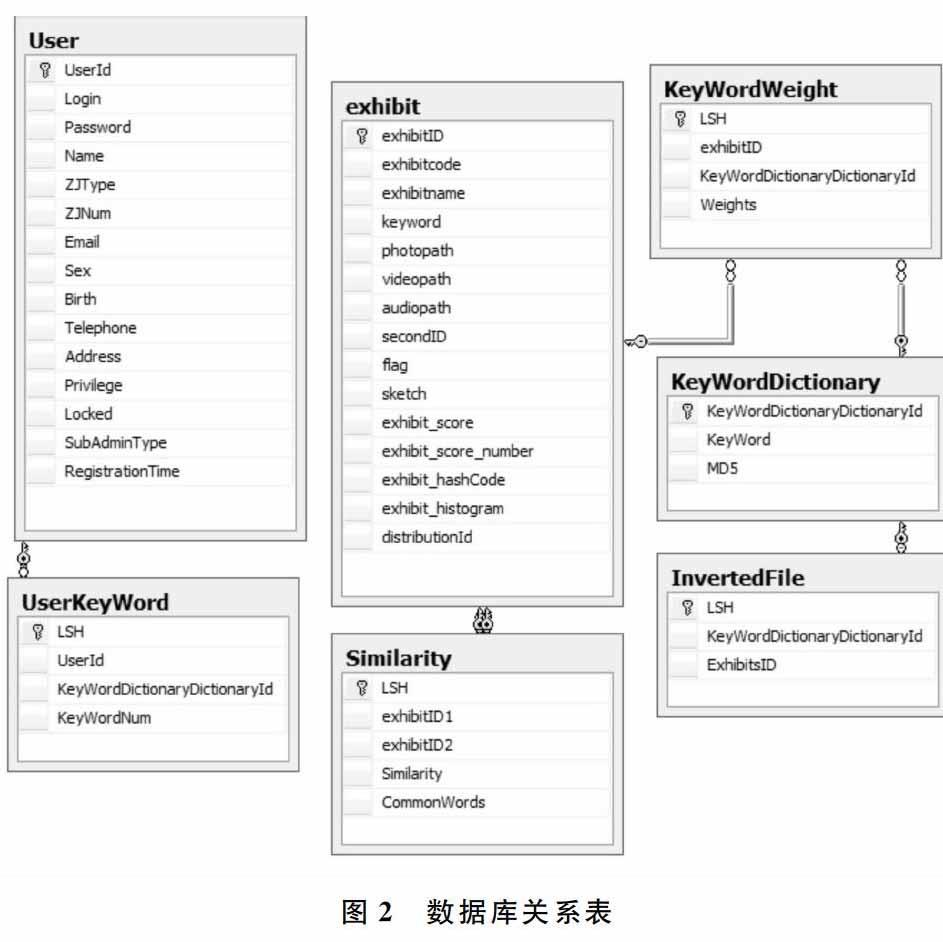
2 数据库设计
除最基本的用户表(User)表和博物馆(exhibit)表之外,设计用户关键字(UserKeyWord)表;相似度(Similarity)表;关键字权重(KeyWordWeight)表;关键字字典(KeyWordDictionary)表;倒排文件(InvertedFile)表。数据库关系表如图2所示。
3 功能实现
系统数据挖掘与推荐时,需要用到自定义函数以进行数据传递和分析。首先从用户的cookie或者数据库中读取用户浏览信息;然后,根据不同的推荐类型,选择不同的函数对数据进行推荐操作;最后,将推荐结果返还给用户。详细步骤如下:
(1)当用户点击某个藏品时,获取藏品关键词,将这些关键字与用户ID放到一张表中(UserKeyWord),同时记录关键字的次数。检查该藏品的关键词是否已经存在数据库中(表keyWordDictionary)。若关键词不在数据库中,将该关键词插入到数据库中,并将该藏品插入到倒排文件中(表InvertedFile);若该关键词已经在数据库中,则直接将该藏品插入到该关键词倒排文件中,最后计算藏品与其它藏品间的相似度。
(2)计算藏品之间的相似度。首先,从展品表(exhibit)获取该藏品的所有关键词,然后从倒排文件中获取与该藏品有相同关键词的所有藏品,计算该藏品与有相同关键词藏品间的相似度。但只与有相同关键词的藏品进行相似度计算,与没有相同关键词的藏品之间的相似度为0,避免与其它所有藏品间计算相似度,从而节约资源。计算的方法为获取藏品的所有关键词权重(表KeyWordWeight),计算两藏品关键词权重组成的向量余弦夹角[4],将两藏品间的余弦夹角保存到数据库中(表Similarity),最后根据相似度选出前4个藏品返还给用户。计算相似度代码如下:
(3)为了提高访问速度,减轻数据库负担。当用户点击藏品时,将该藏品以及点击时间保存到缓存中,若缓存中藏品量达到极限,从缓存中删除点击量少并且保存时间久远的藏品,以便存储新的藏品。当要用到该藏品相似藏品时直接从缓存中读取,加快访问速度,减轻数据库服务器负担。
4 结语
本文将推荐系统引入博物馆网站建设,以提升用户体验。系统基于不同推荐算法提供了4种推荐体验,从多方面考虑用户需求,尽可能为用户推荐到满意的藏品,大大提高用户体验。
参考文献:
[1]许海玲,吴潇,李晓东,阎保平.互联网推荐系统比较研究[J].软件学报, 2009, 20(2):350-362.
[2]GOLDBERG D,NICHOLS D,OKI B M,et al.Using collaborative filtering to weave an information tapestry[J].Communications of the ACM,1992,35(12):61-70.
[3]应毅,刘亚军,陈诚.基于云计算技术的个性化推荐系统[J].计算机工程与应用,2015,51(13):111-117.
[4]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):66-76.
(责任编辑:陈福时)
