基于Hadoop的Web用户识别与新闻智能推荐算法研究
2016-05-14林中明李文敬
林中明 李文敬


摘要:为了解决大数据时代用户阅读时遇到的“信息过载”与“信息迷失”问题,提出了基于Hadoop平台的用户准确识别与新闻推荐算法。首先基于MAC地址识别用户,通过对用户浏览轨迹的离线和在线挖掘,建立用户兴趣模型。然后对新闻关键词进行聚类,结合协同过滤和启发式方法,基于关键词对用户进行新闻的智能推荐。实验结果表明,基于MAC地址的算法比基于IP地址的算法用户识别率提高了30%。
关键词:云计算;新闻推荐;Web日志挖掘;Hadoop;MAC地址
DOIDOI:10.11907/rjdk.161378
中图分类号:TP312
文献标识码:A 文章编号:1672-7800(2016)005-0027-03
0 引言
根据ZDNET《数据中心2013:硬件重构与软件定义》[1]年度技术报告显示,2013年中国产生的数据总量超过0.8ZB,预计到2020年,产生的数据总量将是2013年的10倍。海量的Web信息让人们感觉到信息过载和信息迷失,如何快速精准地识别用户并为其推荐感兴趣的内容成为了当今的研究热点[2]。根据新闻阅读与设备使用情况的调查问卷[3]数据显示,95%的人都是在电脑、手机、平板等电子设备上获取新闻资讯,而且80%的人在阅读新闻时并未处于登录状态,即无法通过用户的登录信息给用户推荐相应内容。面对海量的新闻资讯,文献[4]针对用户识别存在的问题提出了IASR(IP,Agent,Session and Referrer)算法,通过引入会话(Session)来识别用户;文献[5]提出了基于用户浏览行为的建模,提高了同一个IP下用户的识别率;文献[6-8]提出了基于URL相似度的会话识别方法。但这些方法并不能改变IP对于识别用户的限制,所以不能从本质上提高用户识别率。因此,利用Hadoop大数据平台,对无登录信息的用户进行快速身份识别和新闻信息的个性化推荐,相关研究具有重要的现实意义和潜在的经济价值。
1 海量Web日志与用户识别
MAC地址是网卡物理地址,由网络设备制造商生产时写在硬件内部,因此世界上任意一个拥有48位MAC地址的网卡都有唯一标识[9],且MAC地址与网络无关。通过在Web日志中加入MAC地址,可以实现用户的唯一性识别,增加用户识别的准确性。
用户识别是个性化新闻推荐的基础和关键,详细有用的用户数据将决定新闻推荐的效果。由于Web日志中包含了访问主机IP、访问时间、访问页面、请求方式等信息,详细记录了用户的访问轨迹,生成巨大的数据量及数据类型,因此将通过Web日志作为用户识别的数据源。本文将记录分为长期记录和短期记录,一般将10天以前的访问日志作为长期记录,最近10天的访问日志作为短期记录。针对长期记录,通过Hadoop平台进行离线处理。短期记录则在用户使用过程当中,以信息增量的形式补充到推荐算法中来。
2 基于MAC地址的用户识别算法
2.1 算法基本思想
Hadoop的核心是Map/Reduce。Map/Reduce是一个可用于大数据处理的离线计算模型,它将一个任务分成多个细粒度的子任务,并将这些子任务分配到计算节点上进行并行处理,以缩短任务完成时间。将Web日志等份划分后,利用Map/Reduce对Web日志作长期记录处理。
利用Hadoop平台得到用户长期记录下的每个MAC地址对应用户的集合文件,这是一个庞杂的文件,将通过基于URL相似性的用户识别算法对集合文件进行处理,得到此MAC对应用户的100条最感兴趣页面的排序文件。
定义长期记录的日志文件为集合L={l1,l2,……,lm},通过map过程得到每个MAC对应的集合文件K={k1,k2,……,kn},再通过reduce过程,得到对应生成的用户长期访问文件为MAC={MAC1,MAC2,……,MACr},每个文件里包含了此MAC地址对应用户的所有长期访问记录。在K的每个文件中包含有访问时间、IP、URL、访问时长、访问次数字段。针对短期日志文件,根据最近10天该MAC地址用户的所有访问记录,同样生成一个短期的访问记录文件。在用户进入站点后,根据用户的长期和短期记录生成一个综合的用户访问记录文件,与用户未读新闻对比后进行推荐。
2.2 特征标签选择
由于一篇文章中经常存在多个分页形式,且每个分页的访问次数和浏览时间基本相同,所以要将同属一篇文章多个分页的URL记录合并。对ki中URL具有相似性的记录进行合并,cos(URLi,URLj)为两条URL的余弦相似性,Smaxi为合并的记录中访问次数最多的,i为合并的记录中访问时间的平均值,numi为合并的记录条数。
3 基于关键词的协同过滤智能推荐算法
当前有很多种智能推荐算法,主要有基于内容的推荐、协同过滤推荐和基于知识的推荐。基于内容的推荐是提取对象中的特征属性,通过用户信息与待推荐对象的匹配程度进行推荐,但这种算法对特征提取方法的依赖程度很高,无法准确地描述用户特征;协同过滤推荐是通过聚合待推荐用户的相似用户评价的所有对象,计算对象与用户之间的效用值进行推荐,对于新对象和新用户都存在冷启动和稀疏性问题;基于知识的推荐是在特定领域构建规则来进行基于规则和实例的推理,不存在冷启动和稀疏问题,但知识很难建模。
本文结合各推荐算法的优缺点,提出一种基于关键词的协同过滤智能推荐算法。一般地,在系统中的每一篇文章都包含有最能体现这篇文章主题的关键词。通过对关键词的聚类,避免了项目的冷启动问题,并去掉了项目特征提取的步骤。对从用户模型中得到的此MAC用户的100条最感兴趣的记录文件,对关键词进行聚类。得到关键词聚合文件W={(w1,q1),(w2,q2),……,(wn,qn)},其中q为w的出现次数。利用启发式方法,先计算文章关键词之间的相似度,再对所有待推荐文章对此MAC用户的效用值进行计算,得到推荐子集。同时假设待推荐文章的关键词为W'={w1',w2',……,wm'}。
4 实验结果与分析
实验在由5台HP DL380G5服务器组成的集群上进行,其中,一台是主节点,一台是任务调度节点,5台都可以作为计算节点及数据存储节点。同时,采取Xen的虚拟化技术,使同一节点上同时并发执行多个MapReduce操作。5台服务器均安装hadoop-0.20.0和JDK。实验程序是在PHP集成开发环境中开发的。测试数据集来自某地方综合新闻资讯网站的Web服务器日志。为了验证该Web日志分析平台的有效性及高效性,做了以下2个实验。
实验1:在Hadoop平台上对Web日志中的MAC和IP地址数量分别进行统计。通过比较发现,基于MAC地址比基于IP地址辨别用户的算法识别率高出了30%以上,且随着记录时间的变长,用户的识别率还会继续扩大。这表明基于Web日志分析的新闻推荐使用基于MAC地址的用户识别算法能够准确地识别用户,且不依靠用户前台的数据,减轻了前台数据的处理压力。
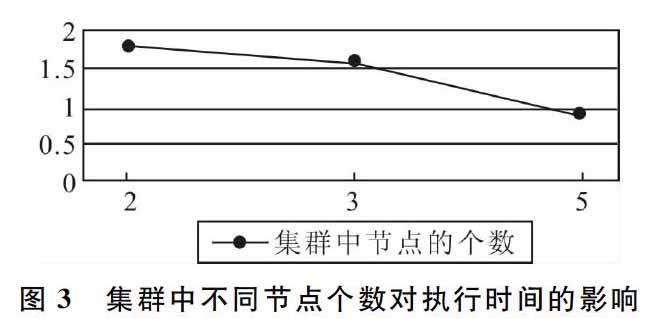
从以上结果可以看出,利用MAC地址的唯一性来识别用户是一个切实可行的方法。当处理的数据量较小时,基于Hadoop的Web日志分析平台由于需要生成及传输中间文件和最终文件,开启Hadoop也需要一定时间,因此并行运算的总时间反而大于单机执行时间。但随着数据量增大,基于Hadoop的并行处理平台将数据分割后分派给多个节点并行处理,使并行运算的总时间小于单机执行时间,且随着输入数据的增加,两者执行效率的差距也越来越大。从图3可以看出,集群中拥有的节点数目越多,基于Hadoop的并行处理平台效率越高。
5 结语
针对目前用户阅读新闻普遍遇到的信息过载问题及用户不登陆浏览的阅读习惯,基于MAC的用户识别算法提高了新闻推荐中的用户识别率。同时针对运行于单机集中平台上的Web日志分析系统不能满足海量数据处理的问题,本文在对云计算的Hadoop集群框架研究的基础上,给出了一种基于Hadoop集群框架的Web日志分析方法。实验结果表明,该平台能够获取隐含的、有实用价值的信息,执行效率高。
参考文献:
[1]张广彬,盘骏,曾智强.数据中心2013:硬件重构与软件定义[R].ZDNet企业解决方案中心,2013.
[2]张诚,郭毅.数据挖掘与云计算——专访中国科学院计算技术研究所何清博士[J].数字通信,2011(3):5-7.
[3]新闻阅读与设备使用情况的调查问卷[EB/OL].http://www.lzm07.com/index.php?file=v.html.
[4]吴永辉,王晓龙,丁宇新,等.基于主题的自适应、在线网络热点发现方法及新闻推荐系统[J].电子学报,2010(11):2620-2624.
[5]何希真.基于用户反馈信息的新闻推荐系统设计与实现[D].济南:山东师范大学,2015.
[6]谢润泉.基于隐式专家的个性化新闻推荐[D].厦门:厦门大学,2014.
[7]宋科. Hadoop平台下基于LDA的新闻推荐算法研究[D].成都:西南石油大学,2015.
[8]周松松,马建红.基于URL相似度的会话识别方法[J].计算机系统应用,2014(12):191-196.
[9]谢俐,何勇,杨乐.网卡MAC地址探究[J].今日科苑,2008(4):190.
(责任编辑:黄 健)
