两种新的计算机化自适应测验在线标定方法*
2016-02-01陈平
陈 平
(北京师范大学中国基础教育质量监测协同创新中心, 北京 100875)
1 引言
在传统纸笔测验(Paper-and-Pencil, P&P)中,所有被试不论能力高低都作答相同的一批题目, 所以P&P中题目的难度分布较广, 一般覆盖整个能力范围。于是, 题目对高能力被试而言大多比较容易、对低能力被试来说大多比较难, 不利于对被试能力的准确估计(漆书青, 戴海琦, 丁树良, 2002)。计算机化自适应测验(Computerized Adaptive Testing,CAT)的基本思路是让计算机自动模仿聪明主试的做法, 每次都呈现最适合被试作答的题目(Wainer et al., 1990)。因此, 相对于P&P, CAT使用更少的题目就能达到相同的能力估计精度(如Weiss, 1982),大大提高了测验效率。CAT还有很多其他优点, 比如:(1)随着计算机硬件的不断升级, 可以在短时间内完成越来越复杂的计算; (2)与多媒体技术结合可以提供包括音频与视频在内的新颖题目类型(如短时记忆题和空间记忆题)。如果有语音合成器, 还可进行听力与口语测试; (3)与认知诊断相结合可以测量新的技能类型(如知识状态); (4)与多级项目反应理论(Polytomous Item Response Theory, PIRT)结合可以提供基于表现的题目类型(如开放题); (5)与多维IRT (Multidimensional IRT, MIRT)相结合可以提供被试在多个分维度上的精细信息; (6)主试如果感兴趣还可以记录被试在每个题目上的反应时, 以作为评价被试能力的辅助指标(Wang, 2012); (7)当题库得到良好维护时, 测验可以全年提供, 被试可以选择方便的时间参加测验(Cheng, 2008)。上述优点使得国内外很多大规模的选拔性与资格性考试都推出CAT版本的测验, 例如美国商学院研究生入学考试与美国医生护士资格考试(Chang, 2012, 2015),还有我国第四军医大学对应征公民进行的图形智力测验(田健全, 苗丹民, 杨业兵, 何宁, 肖玮, 2009)等。
题库是CAT的重要组成部分, 也是CAT顺利实施的重要前提。构建CAT题库一般包括“明确题库大小”、“确定题库结构”、“开发题目”以及“标定题目参数”等核心步骤(陈平, 2011; Flaugher, 2000),每个步骤的完成质量都会影响题库质量, 进而影响在后续评分过程中对被试能力进行估计的准确性。而且CAT在使用一段时间后, 对题库的维护与管理就显得尤为重要, 因为题库中的某些题目会因为过度曝光、过时等原因不再适合被继续使用(Wainer& Mislevy, 1990)。对此, 游晓锋、丁树良和刘红云(2010)建议暂时“休眠”过度曝光的题目, 同时淘汰过时的题目; Guo和Wang (2003)建议不断开发新题对存在问题的题目进行替代, 并标定其参数, 然后将其增补到题库当中。在整个题目增补过程中, 对新题的标定是技术难点, 题库管理者需要尽可能准确地标定新题, 因为标定不准的题目会产生有偏的能力估计值(陈平, 辛涛, 2011a, 2011b)。为了实现这个目标, 在线标定技术被广泛应用于CAT的新题标定中(如Chang & Lu, 2010), 主要是因为它相对于传统的锚题设计的离线标定方法具有诸多优点(详见Chen, Xin, Wang, & Chang, 2012; Parshall, 1998)。
在线标定是指在被试自适应作答旧题的过程中将新题以随机或自适应的方式分配给被试作答,并在线收集被试在新题上的作答反应, 然后估计新题参数的过程(Wainer & Mislevy, 1990)。经过在线标定后的新题参数自然而然地与旧题参数在同一量尺上, 不再需要进行等值(Ban, Hanson, Wang, Yi, &Harris, 2001; 陈平, 辛涛, 张佳慧, 2013)。考虑到CAT本身的性质以及实际中每名被试作答的新题数一般少于新题总数(Ban, Hanson, Yi, & Harris, 2002),被试在旧题和新题上的作答反应均构成稀疏矩阵而非全矩阵, 因此IRT中传统的适用于全矩阵情形的题目参数估计方法就不能直接应用于在线标定情境, 而需要进行相应的调整。为了解决在线标定中的数据稀疏问题, 研究者在过去30年里提出多种在线标定方法/设计, 比如Stocking (1988)的Method A和Method B, Wainer和Mislevy (1990)的“只有一个EM循环”方法(OEM), Ban等人(2001)的“有多个EM循环”方法(MEM)以及BILOG/Prior方法。Ban等人(2001)在3种样本量(300、1000和3000)下对上述5种方法的题目参数返真性进行比较, 结果表明:(1) Method A由于存在理论缺陷(即将能力估计值视为能力真值), 具有最大的标定误差; (2) MEM在所有样本下都有最小的标定误差, 因此表现最优;(3) MEM的表现优于OEM, 但是当部分新题质量较差时, OEM的表现也有可能优于MEM。其他的方法/设计还包括游晓锋等人(2010)的双参数条件极大似然估计(Conditional Maximum Likelihood Estimation, CMLE)与多重迭代CMLE方法(这两种方法类似于Method A)、Chang和Lu (2010)的序贯设计以及van der Linden和Ren (2015)的最优贝叶斯自适应设计等。
在已有的在线标定方法中, Method A无论是在思路层面还是在具体实施层面都是最简单、最直接的方法, 它可简述为3个步骤:(1)基于被试在旧题上的作答采用CMLE估计被试能力; (2)将被试能力估计值视为能力真值; (3)基于被试在新题上的作答并结合能力“真值”再次使用CMLE估计新题参数。注意第2步的关键假设使得Method A在标定新题的过程中忽略了能力的估计误差。可以预见的是,当能力估计误差较大时, Method A的表现势必会受到较大影响。为了克服Method A的理论缺陷, 本文提出两种新的CAT在线标定方法:第一种方法将全功能极大似然估计量(Full Functional MLE, FFMLE)(Jones & Jin, 1994; Stefanski & Carroll, 1985)与Method A相结合(记为FFMLE-Method A), 具体是采用FFMLE能力估计量代替Method A中的CMLE能力估计量以校正能力的估计误差; 第二种方法将Stefanski和Carroll (1985)提出的另一个估计量——“利用充分性结果”的估计量(an Estimator which Exploits the Consequences of Sufficiency, 简记为ECSE)与Method A相结合(记为ECSE-Method A),并用于替换Method A中的CMLE能力估计量。本文采用蒙特卡洛模拟方法在多种测验情境下将两种新方法与Method A进行全面比较, 并将Ban等人(2001)认为表现最好的MEM作为标杆进行参照。
本文的剩余部分按如下方式进行组织:下一节将详细描述方法部分(包括IRT模型、FFMLE方法、ECSE方法以及新提出的FFMLE-Method A和ECSE-Method A)。接下来在第3节详细介绍模拟研究设计, 并在第4节呈现研究结果与结论。最后一节呈现讨论部分以及今后的研究方向。
2 方法
2.1 IRT模型
由于本文提出的两种新方法是基于FFMLE和ECSE而构建, 而FFMLE和ECSE是基于标准形式的逻辑斯蒂克回归(Logistic Regression, LR)框架而开发, 又因为两参数逻辑斯蒂克模型(Two- Parameter Logistic Model, 2PLM) (Birnbaum, 1968)可视为包含潜变量θ的标准形式LR模型, 所以本文选择2PLM作为IRT模型1这里暂未考虑3PLM的原因是:3PLM的项目特征函数 (ICF) 是在2PLM的ICF的基础上乘以 (1-c) 再加上c而得到 (c代表猜测参数)。对于这种在标准形式LR模型的基础上进行简单变换而得到的模型, FFMLE与ECSE是否仍具有优良的统计特性还有待进一步的考证。。2PLM的项目特征函数为
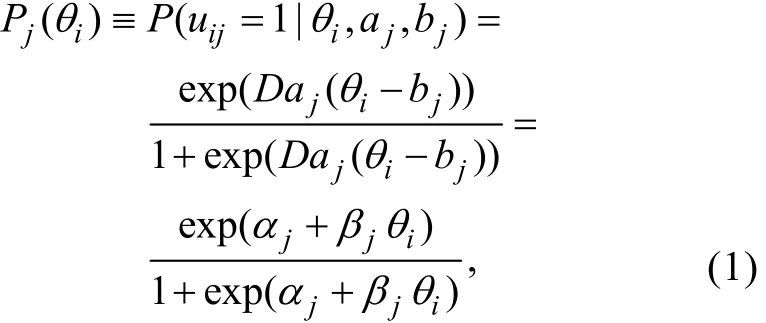
其中uij表示被试i在题目j上的作答,θi表示被试i的能力参数,aj和bj分别是题目j的区分度与难度参数;是以LR模型的标准形式表达的题目参数向量, 其中αj=−Daj bj、βj=Daj;Pj(θi)表示能力为θi的被试i正确作答题目j的概率。上式中的D是量表因子,D=1表示使用逻辑斯蒂克量尺,D=1.702表示使用正态量尺。本文取D=1.702。
2.2 FFMLE与ECSE方法
步骤1:定义测量误差模型

其中εi是对θi进行观测时得到的误差项。给定θi的情况下, 模型假设εi服从均值为0、方差为σ2的正态分布(εi~N(0,σ2))且εi与uij相互独立(Cov(εi,uij)=0), 于是有, 而且的概率密度函数可表示为
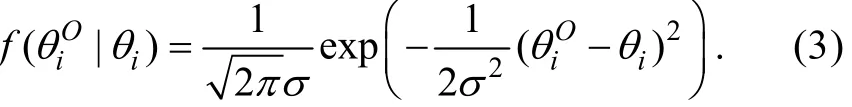
上述测量误差模型中的误差方差σ2不含下标i, 说明该模型假设不同观测的测量误差具有相同的方差。
步骤2:构建未知参数和Δj的全功能对数似然函数l( θ, Δj)
Carroll, Ruppert, Stefanski和Crainiceanu (2006)提到在经典的功能模型中,θi(i=1,2,...,N)可视为未知参数, 而且通过最大化观测数据的联合密度可以得到和Δj的FFMLE估计量。另外, 由步骤1的假设可知,εi与uij相互独立, 进而得到也相互独立。因此,在给定参数特定取值θi和Δj的条件下,的联合密度为
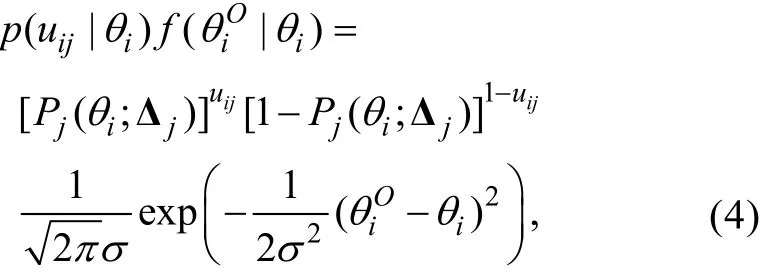
其中Pj(θi;Δj)即公式(1)中的Pj(θi), 表示其是θi和Δj的函数。于是l( θ, Δj)可表示为
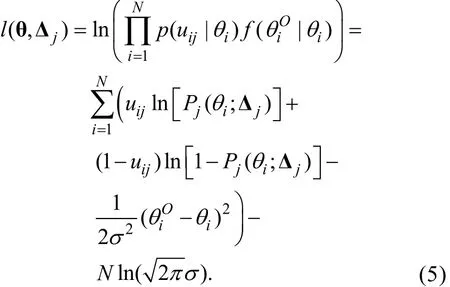
步骤3:将l( θ, Δj)分别对和Δj求偏导后令它们等于0, 可知θi和Δj的MLE估计值满足以下等式组
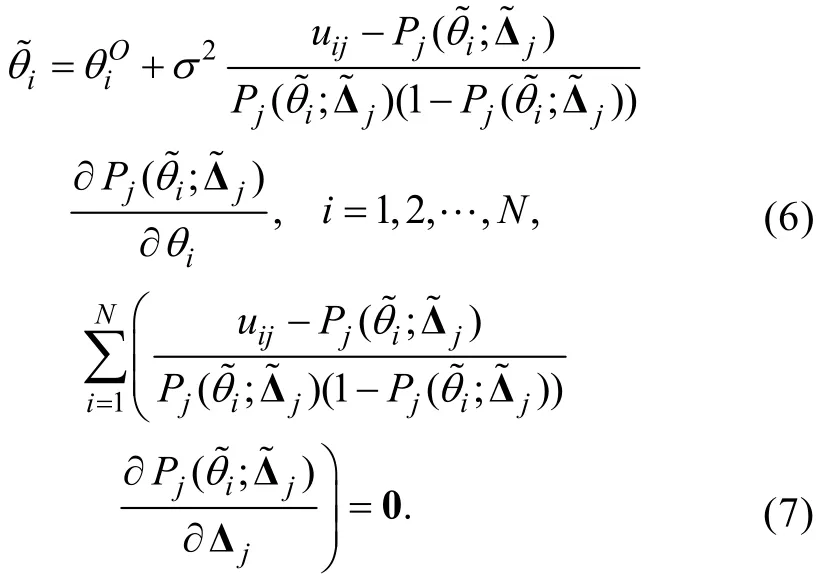
考虑到(6)式中的误差方差2σ未知而且从(6)式和(7)式中求解非常困难, Stefanski和Carroll(1985)建议对(6)式进行如下修改, 以获得的近似版本。
步骤4:将(6)式等号左边的替换为

对比(8)式和(6)式容易发现, 步骤4实际上是分别使用对(6)式等号右边的进行替换, 其中是估计的误差方差, 可以使用MLE的渐近方差公式对其进行估计(Lord, 1980);进行传统LR后得到的MLE估计值;是校正后的估计量, 它从理论上校正蕴含在中的测量误差。对于2PLM,, 于是(8)式可简化为

步骤5:将uij对校正后的进行传统LR后得到的MLE估计量, 即是Δj的FFMLE估计量。
另外, Stefanski和Carroll (1985)在误差正态的假设下还发现:在给定Δj和σ2时, 可以找到θi的充分统计量——, 即uij的条件分布在给定T(Δj)时不依赖于θi。相应地,他们根据充分性的结果给出另一种校正测量误差的方法——ECSE。ECSE与FFMLE的不同之处仅体现在步骤4, ECSE使用下式对测量误差进行校正
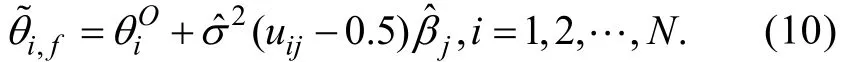
Stefanski和Carroll (1985)的研究表明:当观测数N足够大且无限趋近于σ2时(即当N→∞时,), FFMLE和ECSE估计量都具有一致性而且表现都优于传统的MLE估计量。
2.3 FFMLE-Method A与ECSE-Method A方法
鉴于Method A存在的天然理论缺陷以及FFMLE和ECSE具有的优良性质, 本节将FFMLE和ECSE的误差校正思路融入Method A并得到两种新方法FFMLE-Method A和ECSE-Method A。
在一般正则条件下, 当测验长度t→∞时, CAT的MLE能力估计值渐近服从正态分布是对能力真值θ进行估计i的误差方差,I(θi)是θi处的费舍测验信息量,与θi的接近程度由I(θi)或φi的大小决定(Chang &Stout, 1993)。值得注意的是, 在CAT测验情境中,不同被试可能会得到不同的误差方差φi(与下标i有关), 这与FFMLE和ECSE中测量误差模型的假设稍有不同。但是, 如果将2.2节步骤1中的测量误差模型修改为, 关于FFMLE和ECSE的主要结论会保持不变。相应地,当t→∞时, 能力估计误差也渐近服从正态分布N(0,φi)。由于ξi具有渐近正态性, 满足FFMLE和ECSE的前提假设, 所以在CAT新题标定过程中也可以借鉴FFMLE和ECSE的思路对ξi进行校正, 然后再基于校正后的能力估计量采用Method A标定新题。对于新题j, FFMLE-Method A和ECSE-Method A可描述为以下6个步骤(两者的差异仅体现在步骤5):
步骤1:CAT结束后, 采用CMLE可以得到作答新题j的所有被试的能力估计值及相对应的能力估计误差方差。即可得到,其中nj表示作答新题j的被试数,分别表示作答新题j的第i名被试的能力估计值及估计误差方差。对于2PLM,可通过下式计算
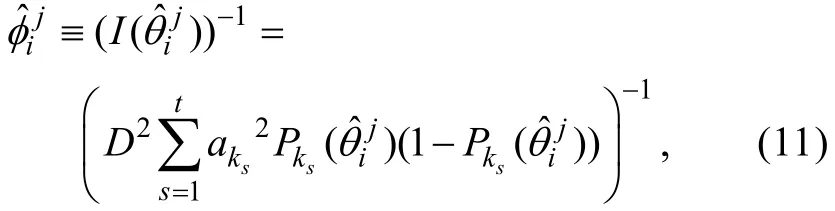
其中k为作答新题j的第i名被试的被试编号,表示被试k作答的t个旧题的题目编号。在CAT过程中, 还可收集被试在所有新题上的作答, 其中T表示转置运算,m表示新题总数。另外, 当t→∞时,, 其中都表示参数真值而且。
步骤2:将上一步得到的视为能力真值, 结合xj采用Method A估计新题j的题目参数向量, 得到(为步骤5做准备)。
步骤3:构建未知参数和γ的
j全功能对数似然函数
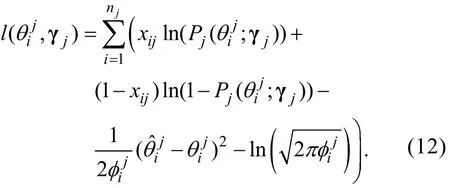
步骤4:将分别对和γj求偏导, 并令它们等于0, 可得知的MLE估计值满足以下等式组
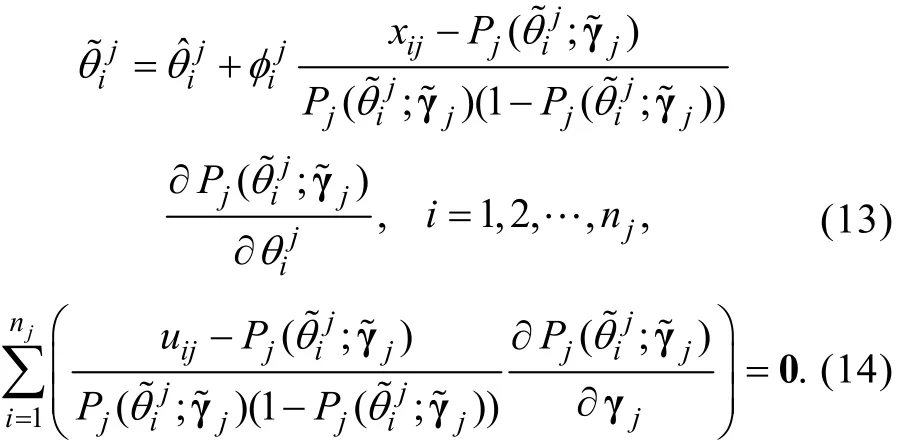
步骤5:对(13)式进行修改如下
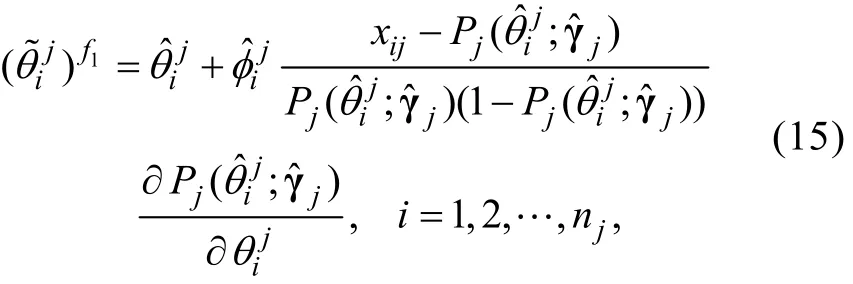
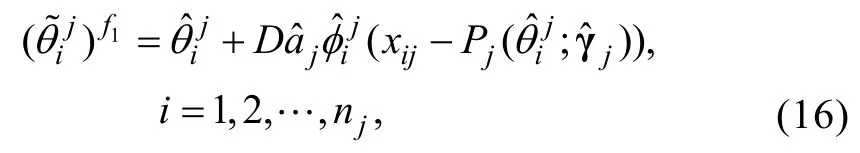
类似于公式(10), 这里的ξi也满足渐近正态性,也可采用ECSE方法对能力估计误差进行校正
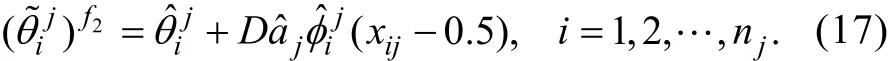
步骤6:基于上一步得到的以及xj, 再次采用Method A估计γj,得到的估计量即是FFMLE-Method A或ECSE-Method A估计量。
对每个新题都执行上述6个步骤后即可实现对所有新题的标定。一方面估计了所有新题的题目参数,另一方面将所有新题参数都置于旧题的参数量尺上。
3 实验
本研究的主要目的是在多种测验情境下考察新提出的FFMLE-Method A和ECSE-Method A较原始的Method A [记为Method A (Original)]和MEM能否改进标定精度。另外, 考虑到Method A的表现在很大程度上依赖于能力估计值与能力真值的距离远近, 因此本文还想知道:如果被试的能力真值已知, Method A的标定精度能够得到多大程度的提高。这在模拟研究中可以实现, 即在Method A中使用真实的能力值, 这种方法可作为比较的基准[记为Method A (True)]。所以, 本研究采用模拟方法对Method A (True)、Method A (Original)、FFMLEMethod A、ECSE-Method A以及MEM等5种CAT在线标定方法进行全面比较。
为了探讨样本大小对标定精度的影响, 本研究考虑3种样本大小(N=1000,2000和3000)。考虑到CAT测验长度会影响能力的估计精度, 本研究还采用3种测验长度(t=10,20和30), 旨在讨论不同测验长度对标定精度的影响。因此, 本研究采用3× 3× 5的实验设计, 共产生45种实验条件、9种CAT测验情境(即在样本大小与测验长度组合的每种CAT测验情境下, 都采用5种方法标定新题)。本文采用Matlab R2013a编写计算机模拟程序, 并将9个模拟程序(1种测验情境对应1个程序)部署在9台虚拟机上分别运行, 以节省程序运行时间。另外, 尽管本文不比较不同样本量或不同测验长度对在线标定方法运行时间的影响, 但还是将9台虚拟机设为相同配置, 即64位的操作系统、2.60 GHz的处理器(双核)以及8GB的内存2值得注意的是, 实验表明:即使在配置完全相同的多台虚拟机上运行同一个程序, 也不会得到完全相同的运行时间结果。所以从严格意义上讲, 本文不能准确考查不同样本量或不同测验长度对在线标定方法运行时间的影响, 但可比较同一CAT测验情境内不同方法的运行时间。。
3.1 被试与题库生成
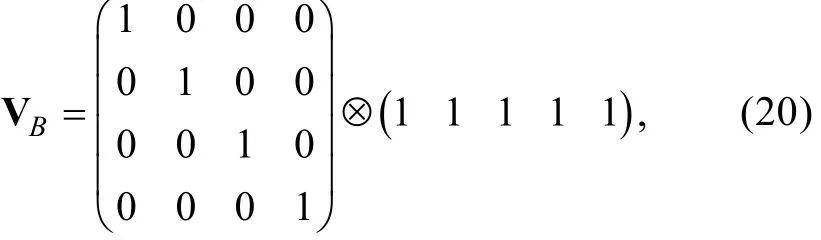
本研究模拟3个被试样本(对应于3种样本大小), 每个被试样本的能力真值都随机抽取自标准正态分布。对于所有9种测验情境, 模拟1000个题目构成CAT题库, 题库中题目的参数向量γ=(a,b)T随机抽取自均值向量为μγ、协方差矩阵为Σγ的多变量正态分布MVN( μγ,Σγ), 其中。为了使得生成的题目参数尽可能与真实情境相符, 借鉴Chen和Xin (2014)的方法确定μγ和Σγ中的参数:(1)假设b随机抽取自标准正态分布, 于是μb=0、var(b)=1; (2)一般情况下a和b存在一定程度的正相关(Chang, Qian, & Ying, 2001), 这里假设a和b间的相关系数ρa,b=0.25; (3) Baker和Kim (2004)认为a一般服从对数标准正态分布(lna~N(u,σ2),其中u=0、σ=1)并且a的取值一般落在某个范围(如a∈(LBa,UBa))。于是想知道, 在a取值范围被截取的情况下,a的均值μa和方差var(a)会是多少。根据Lien (1985)的研究结果, 可知截取的对数正态分布的r次矩可描述为

表1 模拟的被试样本与题库的描述统计量

其中E(ar)=exp(ru+(r2σ2/2)), Φ(•)是标准正态分布的累积分布函数。这里假设LBa=0.2、UBa=2.0,容易得到E(a|0.2 另外, 将模拟生成的θ和b截取在−3至3之间,a介于0.2至2.0之间。模拟的3个被试样本以及题库的描述统计量如表1所示。模拟生成的a与b之间的相关系数等于0.2507, 与预设的真值0.25非常接近。 对每种测验情境, 都模拟生成20个新题(m=20)。为了减少随机误差, 对包括生成新题、模拟被试在新题上的作答以及标定新题的整个过程重复100次(rep=100)。另外, 模拟新题参数的方法与模拟旧题参数的方法相同, 也是从(19)式所示的先验分布中随机抽取。同样, 新题的a介于0.2至2.0之间,b介于−3至3之间。 从初始题的选择方法、选题策略、能力估计方法以及终止规则等方面对CAT全过程的模拟进行描述:(1)一开始对被试能力一无所知, 所以将每名被试的能力值初始化为0 (即=0); (2)基于被试的能力估计值, 采用最大费舍信息量方法从题库或剩余题库中选择第一个或下一个最适合被试作答的题目施测被试; (3)根据当前被试的能力真值以及当前题目的参数真值基于2PLM计算正确作答概率P, 然后将P与从均匀分布U(0,1)中随机抽取的小数z进行比较。如果P≥z, 模拟作答为1; 否则, 模拟作答为0; (4)被试完成对每个题目的作答后, 对被试能力的更新分为两种情况:当测验长度较短(比如小于5)或出现全0或全1的作答模式时, 采用后验期望法(Expected A Posteriori, EAP)更新被试的能力估计值; 否则, 采用MLE方法对进行更新; (5)采用固定长度的终止规则, 并且预设测验长度分别为t=10,20和30。也即上述的题目选择、作答模拟以及能力估计等过程不断重复, 直至测验长度达到t为止, 结束测验。 在模拟CAT时还有一些重要细节值得强调:(1)在实现EAP时, 假设能力的先验分布为标准正态分布, 并且在[−3, 3] 上均匀抽取61个积分结点3选取61个积分结点的理由是:在预研究中, 我们考查了3种不同积分结点数 (分别为21个、41个和61个) 对EAP估计精度的影响。结果发现, 使用21个积分结点的精度最差, 采用41个结点已经可以得到较高的估计精度, 但为了保险起见, 还是选取61个结点。(S=61), 于是步长step=6(S−1)=0.1, 积分结点qs=(−3)+(s−1)×step以及与之相伴随的权重; (2)在实现MLE时, 采用牛顿−拉夫逊方法(Newton-Raphson, N-R)与二分法相结合的方式求解非线性方程。而且在具体编程时, 一般先采用速度较慢的二分法寻找包括零点的区间, 待找到后再换用迭代速度较快的N-R (迭代精度设为0.001); (3)不管是采用EAP还是MLE, 都将最终的能力估计值截取在[−3, 3] 之间。也即, 当能力估计值大于3时, 将其赋值为3; 当能力估计值小于−3时, 将其赋值为−3。 由于在线标定包括在线标定设计与在线标定方法两个重要环节(陈平等, 2013), 所以接下来分别对两者的实施细节进行描述。 考虑到随机在线标定设计实施起来非常方便而且能够提供准确稳定的标定结果(比如Ban et al.,2001; Chen et al., 2012), 本研究在CAT测验过程中采用随机在线标定设计将新题分配给被试作答。具体而言, 首先从由20个新题组成的新题集中随机选择5个新题(即C=5), 然后将它们置于被试CAT的随机位置。另外, 由于参与作答每个新题的被试数会影响新题的标定精度, 因此参照Chen等人(2012)的做法, 本研究也将作答每个新题的被试数都控制在平均水平——(N×C)m, 也即对于3种样本大小, 作答每个新题的被试数分别控制在250((1000× 5)20)、500((2000× 5)20)和750((3000× 5)/20)。这可以通过预先构建一个行和都等于C、列和都等于(N×C)m的随机矩阵V=(vij)N×m来实现,其中vij用于标识被试i是否会作答新题j。vij=1表示被试i会作答新题j, 否则vij=0。以3000的样本大小为例, 简单说明V的构建方法:首先构建大小为(m C)×m(即4× 20)的基本矩阵单元VB 其中⊗表示克罗内克积(kronecker product)符号,易知VB的行和都等于C(即5)、列和都等于1。所以, 如果将(N×C)m(即750)个VB纵向合并(或将⊗右边的行向量换成大小为750× 5且元素全由1组成的矩阵)然后随机调换行的位置、列的位置, 即可得到行和都等于C、列和都等于(N×C)m的矩阵V。对于1000和2000的样本大小, V的构建方法类似。 CAT测验结束后, 计算机已经收集所有被试在旧题上的作答以及在新题上的作答,根据与已知的旧题参数还可计算所有被试的能力估计值以及相对应的能力估计误差方差。接下来, 再使用本文讨论的5种方法对新题进行标定。注意在具体实施不同方法时, 可能会用到上述的不同信息。比如, 对于Method A (True), 只需要被试能力真值就能标定新题; 而对于Method A (Original), 需要用于新题标定; 对于FFMLE- Method A和ECSE-Method A, 则需要用到以及Method A (Original)得到的估计结果等信息; 实施MEM需要用到以及等信息。 本文讨论的5种方法在算法层面都需要使用N-R迭代, 而且预研究(未考虑新题参数的先验分布)还发现:当用于标定新题的被试数较少(比如本文1000的样本大小所对应的250)时, 容易出现迭代不收敛的情况。为了解决此问题, 本研究将贝叶斯众数估计(Bayes Modal Estimation) (Mislevy,1986) 的思路融入到这5种方法中, 即使用贝叶斯版本的在线标定方法, 也即在标定过程中考虑新题参数的贝叶斯先验。虽然以往有些研究(比如Ban et al.,2001)使用固定的贝叶斯先验, 但在在线标定情境下, Wainer和Mislevy (1990)提出更为合理的方案:首先对题库中所有旧题的参数分布进行分析, 然后将其作为新题参数的先验分布。基于此, 本文将(19)式所示的旧题参数先验分布作为新题参数的先验分布, 记为g(γ)。值得注意的是, 贝叶斯版本的在线标定方法较原始版本方法的变化仅在于:在对数似然函数项(对于前4种方法)或对数边际似然函数项(对于MEM)后面都增加了贝叶斯先验项——lng(γ)(详见Baker & Kim, 2004; Zheng, 2014)。 其中函数norminv(•)用于计算标准正态累积分布函数的逆,prj表示作答新题j的所有被试在该题上的通过率,aμ是旧题a参数的先验均值。 对于每种测验情境, 采用均方根误差(Root Mean Squared Error, RMSE)、偏差(Bias)以及皮尔逊相关系数(r)评价CAT的能力估计精度, 使用RMSE、Bias、r以及加权均方误差(Weighted MSE,WMSE)评价各种方法的标定精度。采用最小EM循环数(Min_Cycle)、最大EM循环数(Max_Cycle)、平均EM循环数(Mean_Cycle)评价MEM的标定效率, 使用平均程序运行时间(Mean_Time)评价各种方法的标定时间。 Bias指标中各符号的含义同RMSE指标, 两者都是越小越好。 该指标用于评价题目参数的总体返真性, 具体计算估计的项目特征曲线(Item Characteristic Curves, ICCs)与真实ICCs的平均加权面积差异。 因为MEM一般需要多次EM循环才能满足收敛标准, 所以记录这些指标以评价MEM的标定效率。 其中EM_Cycle(c)是第c次重复时MEM所需的EM循环次数, 函数min(•)、max(•)和round(•)分别用于求取最小值、最大值和四舍五入值。这3个值都是越小越好, 说明效率越高。 该指标用于反映采用每种方法标定所有新题的平均计算时间, 单位是秒。 其中Running_Time(c)表示第c次重复时运行某种在线标定方法程序所用的时间。值越小说明标定效率越高。 另外, 本研究还使用r衡量能力(题目)参数估计值与真值间线性关系的程度大小,r值越高说明能力估计精度或题目标定精度越高。 本文从三个方面对研究结果(如表2至表7所示)进行分析:(1)不同测验情境下CAT的能力估计精度; (2)不同测验情境下各种方法的标定精度; (3)不同测验情境下各种方法的标定效率。 表2描述的是在9种测验情境下模拟的CAT测验的能力估计精度。由表中数据可知, 所有测验情境下得到的Bias都非常接近0, 范围从0.0002到0.0146。而且不管样本量有多大, RMSE都随测验长度的增加而严格单调递减,r都随测验长度的增加而严格单调递增。比如, 对于1000的样本大小, 当测验长度从10增加到30时, RMSE分别为0.3615、0.2635和0.2253; 对于3000的样本大小, 当测验长度从10增加到30时,r从0.9360增加到0.9757。总体来讲, 模拟的CAT能够为被试提供准确的能力估计值。 表3至表5呈现的分别是测验长度为10、20和30时不同样本量下各种方法的标定精度结果。为了描述方便, 分别将Method A (True)、Method A(Original)、FFMLE-Method A、ECSE-Method A以及MEM记为M1至M5。值得强调的是, 对于样本量N=1000、2000和3000, 分别有250、500和750名被试参与每个新题的标定。而且在所有测验情境下的所有100次重复中, 5种方法的迭代程序都正常收敛, 这说明使用贝叶斯版本的在线标定方法可以避免N-R迭代不收敛的问题。 表2 不同测验情境下CAT的能力估计结果 由表3可以看出, 3种样本量下的Bias都非常接近0, 范围从−0.0985到0.0072, 这说明估计的题目参数与真实题目参数间的平均差异较小, 对题目参数的修复能力较强。另外, 将两种新方法M3和M4与M2进行比较, 可以发现:(1)从题目参数的总体返真性来看, M3和M4的WMSE与M5的值相同, 而且都一致小于M2的WMSE, 这说明对能力估计误差进行校正可以改进Method A的标定精度,符合预期假设; (2)当样本量为1000时(nj=250),M3和M4在a上的RMSE (分别为0.1616和0.1678)明显小于M2的值(0.1943), 但在b上的标定精度有微小的降低(相对于M2, M3和M4在a上的RMSE降低16.83%和13.64%、而在b上的RMSE仅增加1.02%和1.36%)。但是当样本量增加到2000和3000时(nj=500和750), M3和M4较M2的优势开始突显, M3和M4在a和b上的RMSE都明显小于M2的相应值。这说明当样本量足够大时, FFMLE和ECSE的优良性质得到充分体现, 这与 Stefanski和Carroll (1985)的研究结果一致; (3)尽管M3与M4的表现比较接近, 但还是可以看出M3总体上优于M4, 这说明使用(16)式对能力估计误差进行校正比使用(17)式进行校正能够获得更准确的标定结果。而且M3的表现已经非常接近于性能最优的M5; (4)样本量越大, RMSE和WMSE都越小、r越大, 说明标定精度越高。 当测验长度由10增加到20时, CAT提供的能力估计精度已有较大幅度的提高(详见表2), 留给M3和M4“通过校正能力估计误差改进标定精度”的空间就更小了。于是可以预见M3和M4较M2的改进幅度相对于测验长度为10时会更小一些,这通过观察表4中数据可以得到证实, 具体体现在:(1) M2、M3、M4与M5的WMSE已基本相同(特例是:当样本量为2000时, M2的WMSE稍高一点); (2)在所有3种样本量下, M3和M4在a上的RMSE都比M2的稍低一些, 然而它们在b上的RMSE都要比M2的稍高一些。至于为什么这两种新方法不能像游晓锋等人(2010)的方法一样可同时改进a和b的估计精度, 原因可能是:a本质上是2PLM中θ的回归系数, 非常容易受到θ的测量误差的影响; M3与M4对中蕴含的测量误差进行校正, 从而可提高a的标定精度, 但是并未采取类似于“夹逼平均法” (游晓锋等, 2010)的任何措施以提高b的标定精度。总体而言, M3和M4的表现还是优于M24当样本量为1000时, 相对于M2, M3和M4在a上的RMSE降低4.04%和4.11%、而在b上的RMSE只增加0.78%和0.82%; 当样本量为2000时, 相对于M2, M3和M4在a上的RMSE降低9.59%和9.34%、而在b上的RMSE只增加1.88%和1.94%; 当样本量为3000时, 相对于M2, M3和M4在a上的RMSE降低11.84%和11.93%、而在b上的RMSE只增加3.05%和3.37%。所以, 如果将a和b的标定精度看成同等重要的话, M3和M4的表现在总体上优于M2。; (3) M4的表现与M3和M5的表现已非常接近。一种可能的解释是:M4受测验长度的正面影响(即测验长度越长, M4的相对表现更好)可能较M3更大一些; (4)随着样本量的增大, 标定精度也提高。另外, 3种样本量下的Bias也都非常接近0,范围是从−0.0421到0.0161。 表3 测验长度为10时不同样本量下各种方法的标定结果 表4 测验长度为20时不同样本量下各种方法的标定结果 随着测验长度增加到30, CAT的能力估计精度进一步提高, 留给M3和M4的改进空间进一步减小, 主要表现在以下方面:(1) M2、M3、M4与M5在3种样本量下的WMSE完全相等; (2)当用于标定新题的被试数较少时(nj=250), 相对于M2, M3没有改进标定精度。只有当nj达到500甚至是750时,M3通过校正能力估计误差在a上可以小幅度改进M2的标定精度; (3)注意当测验长度达到30且样本量为2000和3000时, M4已经成为总体上表现最好的方法5当样本量为2000时, 相对于M2, M4在a上的RMSE降低2.85%、而在b上的RMSE增加2.23%; 当样本量为3000时, 相对于M2, M4在a上的RMSE降低3.49%、而在b上的RMSE增加2.94%。同样,如果将a和b的标定精度看成同等重要的话, M4的表现在总体上优于M2。, 这进一步证实M4受测验长度的正面影响较大。另外, 样本量越大, 标定精度也越高。而且3种样本量下的Bias也都非常接近0, 范围从−0.0153到0.0238。 表6描述的是9种测验情境下关于MEM方法EM循环次数的统计结果。从表中可以看出, 在所有测验情境下, MEM的标定效率都比较高, 最多只需要7次EM迭代就能满足收敛标准, 最少只需要3次迭代就能收敛, 平均迭代次数为6次(当测验长度为10时)或4次(当测验长度为20和30时)。而且还可以发现:MEM所需的EM迭代次数受样本量影响不大, 但会受测验长度的影响, 比如当测验长度增加时, 最大迭代次数单调递减(注意有一个特例, 即当测验长度为30且样本量为2000时, 最大迭代次数是5)。这主要是因为如果被试作答更多的旧题, 在MEM的E步中就可以得到更精确的能力后验分布, 从而导致更快的收敛。 表5 测验长度为30时不同样本量下各种方法的标定结果 表6 不同测验情境下MEM的EM循环次数结果 表7呈现的是在9种测验情境下各种方法的平均运行时间。从表中容易看出, 在所有测验情境下,Method A类4种方法(M1、M2、M3和M4)的标定效率都很高, 整个标定过程在瞬间完成, 平均用时不到0.02秒。而且还可以发现:相对于M1和M2,M3和M4所花的时间稍多一点, 这主要是因为M3和M4首先在M2的基础上对能力ˆθ中包含的测量误差进行校正, 然后再基于M2标定新题。相比之下, MEM的算法更复杂, 所需的平均运行时间明显更多(范围在6.0827秒与21.0330秒之间), 所花时间约为其他4种方法的544倍至1618倍之间。尽管如此, MEM这种运行时间上的增加并不具有显著的实际意义, 因为即使采用算法最复杂的MEM也只需22秒不到的时间即可完成标定任务。但是当将这些方法推广到多维CAT情境时, Method A类4种方法较MEM的时间优势就开始突显。在一项预研究中发现:Method A类4种方法的多维版本只需2秒以内的时间即可完成标定, 而MEM的多维版本则需要长达1至2个小时的运行时间, 这在实践中可能难以接受。 表7 不同测验情境下各种方法的平均运行时间 基于上述研究结果, 可以得出以下结论: (1)当CAT测验长度较短或中等时(比如t=10或t=20), MEM总体上表现最优。新方法FFMLE-Method A和ECSE-Method A较Method A总体上可以改进标定精度(t=10时的改进幅度最大), 而且与MEM的表现非常接近6其实在标定新题的过程中, MEM也和两种新方法一样对能力估计误差进行了控制。具体表现在:MEM在M步中是通过最大化对数边际似然函数来估计新题参数, 而边际似然函数是在联合似然函数的基础上通过积分把能力θ积掉而得到。所以从本质上讲, MEM通过积掉θ来控制能力的估计误差。。所以, 在实践中如果对运行时间有较高要求的话, 强烈建议选择两种新方法中表现相对更好的FFMLE-Method A作为在线标定方法; 否则, 建议使用MEM。 (2) 当CAT测验长度较长(比如t=30)且样本量较大(比如N=2000和3000)时, 建议使用总体表现最好且标定效率较高的ECSE-Method A; (3) 在CAT新题标定过程中融入新题参数的先验信息, 能够避免迭代算法不收敛的问题; (4) MEM的标定效率较高, 在不同条件下只需3至7次EM迭代就能满足收敛标准; (5) 模拟的CAT可为被试提供准确的能力估计值。 Quellmalz和Pellegrino (2009)着重强调在线测验在大规模评价项目中的重要作用, 比如国际学生评价项目(PISA)以及美国教育进展评估(NAEP)都计划使用计算机施测或已经使用计算机呈现阅读材料。目前美国已有超过27个州(包括Maryland、North Carolina和Oregon等)在州范围或学期末的测验中使用在线测验形式。另外, 作为2001年美国小布什政府“不让一个小孩掉队” (No Child Left Behind)法案的扩展, 2009年奥巴马政府颁布的“力争上游” (Race to the Top)法案要求美国基础教育阶段(K-12)的州测评必须是计算机化的而且应该使用创新的题型。因此, 由23个州组成的共同体——“大学与职业准备测评联盟” (Partnership for Assessment of Readiness for College and Career,PARCC)正在紧锣密鼓地准备他们的在线州测评,而由另外25个州组成的“智能均衡测评联盟”(Smarter Balanced Assessment Consortium, SBAC)也正在积极合作为其州测评设计CAT (Zheng,2014)。这些都为CAT中的在线标定技术提供了良好的发展前景。 Method A是最早提出的、最简单的CAT在线标定方法。针对Method A的理论缺陷, 本文将FFMLE和ECSE与Method A相结合得到两种新方法——FFMLE-Method A和ECSE-Method A, 它们借鉴FFMLE和ECSE的误差校正思路从理论上对被试的能力估计误差进行校正。为了考察两种新方法的表现, 本研究在多种测验情境下将它们与Method A (True)、Method A (Original)和MEM进行比较, 得到一些有意义的结果, 比如:(1)通过对能力估计误差进行校正, 新方法在大多数实验条件下总体上可以改进Method A的标定精度; (2)当CAT测验长度较短(比如10题)时, 新方法对Method A的改进程度最大7由2.3节对两种新方法的描述可知:当t→∞时, →, 因此当nj足够大时, 两种新方法的统计量具有优良统计特性。然而对于较短的测验长度 (比如t=10), 上述假设会受到某种程度的违背,但这时新方法对Method A的改进程度最大, 一种可能的原因是:测验较短时, CAT提供的能力估计精度较低, 留给改进的空间就比较大, 因此新方法通过校正能力估计误差改进标定精度的幅度也较大;而违背上述假设受到的惩罚可能稍小一些。欢迎在今后的研究中对此有更为严格的解释。; (3)由于考虑新题参数的先验信息, 所有在线标定程序的N-R迭代全部收敛。但是,本文还存在一些不足值得今后进一步探讨: 首先, 从严格意义上讲, 所有在线标定方法(包括Method A)的标定精度都会受到题库中旧题参数的估计误差的影响。换句话说, 在构建CAT题库时, 题库中每个题目的参数都估计自某个标定样本, 因此都存在某种程度的估计误差(Cheng,2008)。这部分的误差除了会传递到接下来的评分过程中, 对评分样本的能力估计产生影响并低估能力估计的标准误(Cheng & Yuan, 2010); 也会传递到MEM中E步和M步的相关计算中。本文提出的新方法(FFMLE-Method A和ECSE-Method A)在标定新题的过程中仅对能力估计误差进行校正, 如果还能够首先校正旧题参数的估计误差(也即对两类误差都进行校正), 意义将不言而喻。另外, 本文讨论的FFMLE和ECSE能否用于对旧题参数的估计误差进行校正, 也有待进一步的研究。 其次, Chen等人(2012)将Method A推广至认知诊断CAT (CD-CAT)领域(记为CD-Method A)。类似于Method A, CD-Method A也具有理论缺陷, 即将被试知识状态(KS)估计值视为KS真值, 这样KS的估计误差也会传递到对新题的标定过程中。因此,今后值得研究的一个新方向是将FFMLE和ECSE应用于CD-Method A, 并对KS的估计误差进行校正。需要指出的是, 不同于CAT中的待估能力是一维的连续变量, CD-CAT中待确定的KS是多维的二分离散变量, 这使得对KS估计误差的校正会更加复杂。而且在DINA等认知诊断模型中, FFMLE和ECSE是否仍具有优良的统计特性也有待进一步的考证。另外, 汪文义、丁树良和游晓锋(2011)讨论在CD-CAT测验过程中植入新题时, 同样考虑了KS的估计误差, 并提出边际MLE (MMLE)方法对属性进行标定。Chen, Liu和Ying (2015)提出的“单个题目标定方法” (SIE)也考虑了KS估计的不确定性, 并成功应用于新题参数和新题属性向量的同时估计。因此, 另一个有趣的问题是探索如何将MMLE和SIE方法应用于KS估计误差的校正中。 再次, 尽管本文提出的两种新方法能够克服Method A的理论缺陷、并改进Method A的标定精度, 但是它们需要在较大样本的前提下才能表现出较好的效果(也即当作答每个新题的被试数量nj=500和750时, 新方法的标定精度才开始突显;与此对应的总被试样本量N=2000和3000, 因为N=nj×(m C)且采用的是随机在线标定设计), 而大样本的收集在真实测验情境中往往会比较困难,所以这是新方法的局限性之一。今后应当重点考虑如何在小样本情境下改进Method A的标定缺陷。 最后, 为了讨论方便本文仅考虑固定长度的CAT终止规则, 今后还可以在变化长度的CAT测验情境中探讨新方法FFMLE-Method A和ECSE-Method A相对于Method A和MEM的表现。另外, 在更为复杂的CAT测验情境下考查FFMLE-Method A和ECSE-Method A的表现也是值得探索的研究方向, 比如能够满足题目曝光控制、内容均衡以及题目类型均衡等非统计约束条件的CAT、允许检查并修改答案的CAT等。 Baker, F. B., & Kim, S. H. (2004).Item response theory: Parameter estimation techniques(2nded.). New York: Dekker. Ban, J.-C., Hanson, B. A., Wang, T. Y., Yi, Q., & Harris, D. J.(2001). A comparative study of on-line pretest item—calibration/scaling methods in computerized adaptive testing.Journal of Educational Measurement, 38(3), 191–212. Ban, J.-C., Hanson, B. A., Yi, Q., & Harris, D. J. (2002). Data sparseness and on-line pretest item calibration-scaling methods in CAT.Journal of Educational Measurement,39(3), 207–218. Birnbaum, A. (1968). Some latent trait models and their use in inferring an examinee’s ability. In F. M. Lord & M. R.Novick (Eds.),Statistical theories of mental test scores(pp.379–479). Reading, MA: Addison-Welsey. Carroll, R. J., Ruppert, D., Stefanski, L. A., & Crainiceanu, C.M. (2006).Measurement error in nonlinear models: A modern perspective(2nded.). London: Chapman and Hall. Chang, H. H. (2012). Making computerized adaptive testing diagnostic tools for schools. In R. W. Lissitz & H. Jiao(Eds.),Computers and their impact on state assessments:Recent history and predictions for the future(pp. 195–226).Charlotte, NC: Information Age. Chang, H. H. (2015). Psychometrics behind computerized adaptive testing.Psychometrika, 80(1), 1–20. Chang, H. H., Qian, J. H., & Ying, Z. L. (2001). a-stratified multistage computerized adaptive testing with b blocking.Applied Psychological Measurement, 25(4), 333–341. Chang, H. H., & Stout, W. (1993). The asymptotic posterior normality of the latent trait in an IRT model.Psychometrika,58(1), 37–52. Chang, Y.-C. I., & Lu, H. Y. (2010). Online calibration via variable length computerized adaptive testing.Psychometrika, 75(1),140–157. Chen, P. (2011).Item replenishing in cognitive diagnostic computerized adaptive testing——Based on DINA model(Unpublished doctorial dissertation). Beijing Normal University. [陈平. (2011).认知诊断计算机化自适应测验的项目增补——以DINA模型为例(博士学位论文). 北京师范大学.] Chen, P., & Xin, T. (2011a). Developing on-line calibration methods for cognitive diagnostic computerized adaptive testing.Acta Psychologica Sinica, 43(6), 710–724. [陈平, 辛涛. (2011a). 认知诊断计算机化自适应测验中在线标定方法的开发.心理学报, 43(6), 710–724.] Chen, P., & Xin, T. (2011b). Item replenishing in cognitive diagnostic computerized adaptive testing.Acta Psychologica Sinica, 43(7), 836–850. [陈平, 辛涛. (2011b). 认知诊断计算机化自适应测验中的项目增补.心理学报, 43(7), 836–850.] Chen, P., & Xin, T. (2014).A new online calibration approach for multidimensional computerized adaptive testing. Paper presented at the National Council on Measurement in Education, Philadelphia, PA. Chen, P., Xin, T., Wang, C., & Chang, H. H. (2012). Online calibration methods for the DINA model with independent attributes in CD-CAT.Psychometrika, 77(2), 201–222. Chen, P., Zhang, J. H., & Xin, T. (2013). Application of online calibration technique in computerized adaptive testing.Advances in Psychological Science, 21(10), 1883–1892. [陈平, 张佳慧, 辛涛. (2013). 在线标定技术在计算机化自适应测验中的应用.心理科学进展, 21(10), 1883–1892.] Chen, Y. X., Liu, Y. C., & Ying, Z. L. (2015). Online item calibration for Q-matrix in CD-CAT.Applied Psychological Measurement, 39(1), 5–15. Cheng, Y. (2008).Computerized adaptive testing – new developments and applications(Unpublished doctorial dissertation). University of Illinois at Urbana-Champaign. Cheng, Y., & Yuan, K. H. (2010). The impact of fallible item parameter estimates on latent trait recovery.Psychometrika,75(2), 280–291. Clark, R. R. (1982).The errors-in-variables problem in the logistic regression model(Unpublished doctorial dissertation).University of North Carolina, Chapel Hill. Flaugher, R. (2000). Item pools. In H. Wainer, N. J. Dorans, R.Flaugher, B. F. Green, & R. J. Mislevy (Eds.),Computerized adaptive testing: A primer(Chap.3, 2nded., pp. 37–59).Mahwah, NJ: Erlabum. Guo, F. M., & Wang, L. (2003).Online calibration and scale stability of a CAT program. Paper presented at the annual meeting of National Council on Measurement in Education,Chicago, IL. Jones, D. H., & Jin, Z. Y. (1994). Optimal sequential designs for on-line item estimation.Psychometrika, 59(1), 59–75. Lien, D.-H. D. (1985). Moments of truncated bivariate lognormal distributions.Economics Letters, 19(3), 243–247. Lord, F. M. (1980).Applications of item response theory to practical testing problems. Hillside, NJ: Erlbaum. Mislevy, R. J. (1986). Bayes modal estimation in item response models.Psychometrika, 51(2), 177–195. Parshall, C. G. (1998).Item development and pretesting in a computer-based testing environment. Paper presented at the colloquium Computer-Based Testing: Building the Foundation for Future Assessments, Philadelphia, PA. Qi, S. Q., Dai, H. Q., & Ding, S. L. (2002).Principles of modern educational and psychological measurement. Beijing,China: Higher Education Press. [漆书青, 戴海琦, 丁树良. (2002).现代教育与心理测量学原理. 北京: 高等教育出版社.] Quellmalz, E. S., & Pellegrino, J. W. (2009). Technology and Testing.Science, 323(5910), 75–79. Stefanski, L. A., & Carroll, R. J. (1985). Covariate measurement error in logistic regression.Annals of Statistics, 13(4),1335–1351. Stocking, M. L. (1988).Scale drift in on-line calibration(Research Rep. 88–28). Princeton, NJ: ETS. Tian, J. Q., Miao, D. M., Yang, Y. B., He, N., & Xiao, W.(2009). The development of computerized adaptive picture assembling test for recruits in China.Acta Psychologica Sinica, 41(2), 167–174. [田健全, 苗丹民, 杨业兵, 何宁, 肖玮. (2009). 应征公民计算机自适应化拼图测验的编制.心理学报, 41(2), 167–174.] van der Linden, W. J., & Ren, H. (2015). Optimal Bayesian adaptive design for test-item calibration.Psychometrika,80(2), 263–288. Wainer, H., Dorans, N. J., Flaugher, R., Green, B. F., Mislevy, R.J., Steinberg, L., & Thissen, D. (1990).Computerized adaptive testing: A primer. Hillsdale, NJ: Lawrence Erlbaum. Wainer, H., & Mislevy, R. J. (1990). Item response theory,item calibration, and proficiency estimation. In H. Wainer,N. J. Dorans, R. Flaugher, B. F. Green, R. J. Mislevy, L.Steinberg, & D. Thissen (Eds.),Computerized adaptive testing: A primer(Chap. 4, pp. 65–102). Hillsdale, NJ:Erlbaum. Wang, C. (2012).Semi-parametric models for response times and response accuracy in computerized testing(Unpublished doctorial dissertation). University of Illinois at Urbana-Champaign. Wang, W. Y., Ding, S. L., & You, X. F. (2011). On-line item attribute identification in cognitive diagnostic computerized adaptive testing.Acta Psychologica Sinica, 43(8), 964–976. [汪文义, 丁树良, 游晓锋. (2011). 计算机化自适应诊断测验中原始题的属性标定.心理学报, 43(8), 964–976.] Weiss, D. J. (1982). Improving measurement quality and efficiency with adaptive testing.Applied Psychological Measurement, 6(4), 473–492. You, X. F., Ding, S. L., & Liu, H. Y. (2010). Parameter estimation of the raw item in computerized adaptive testing.Acta Psychologica Sinica, 42(7), 813–820. [游晓锋, 丁树良, 刘红云. (2010). 计算机化自适应测验中原始题项目参数的估计.心理学报, 42(7), 813–820.] Zheng, Y. (2014).New methods of online calibration for item bank replenishment(Unpublished doctorial dissertation).University of Illinois at Urbana-Champaign.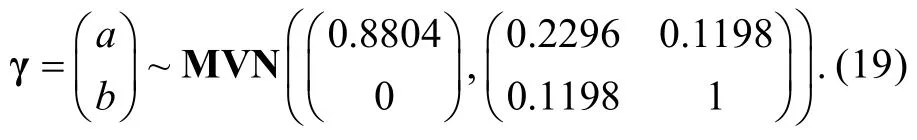
3.2 新题生成
3.3 CAT全过程模拟程序描述
3.4 在线标定实施程序描述
3.4.1 在线标定设计描述
3.4.2 在线标定方法实施程序描述
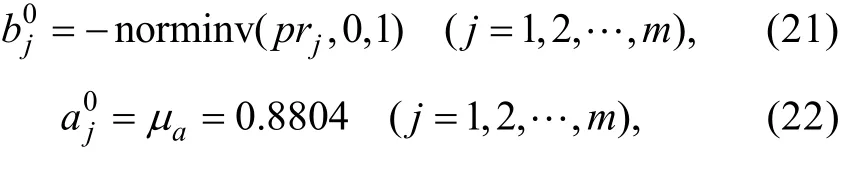
3.5 评价指标
3.5.1 均方根误差
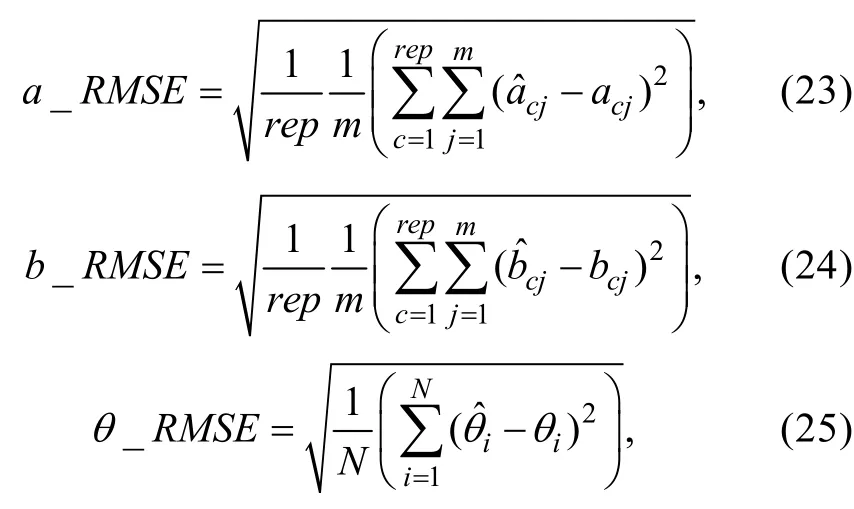
3.5.2 偏差

3.5.3 加权的均方误差
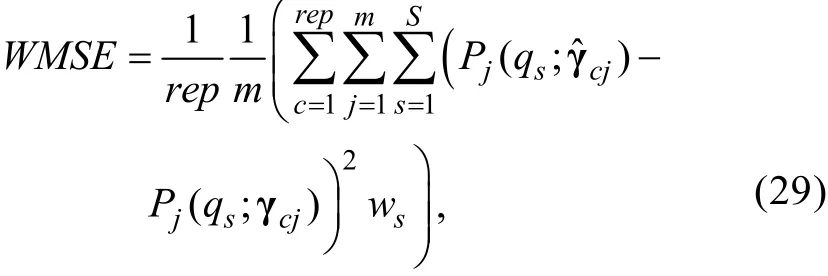
3.5.4 最小/最大/平均EM循环次数
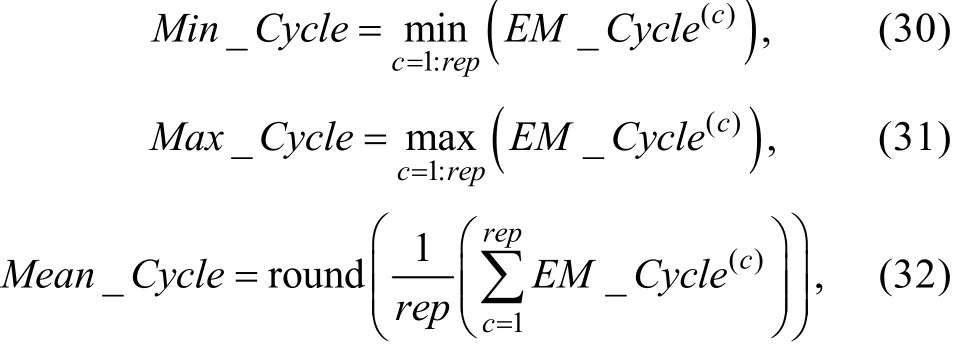
3.5.5 平均程序运行时间

4 结果与结论
4.1 结果
4.1.1 CAT的能力估计精度
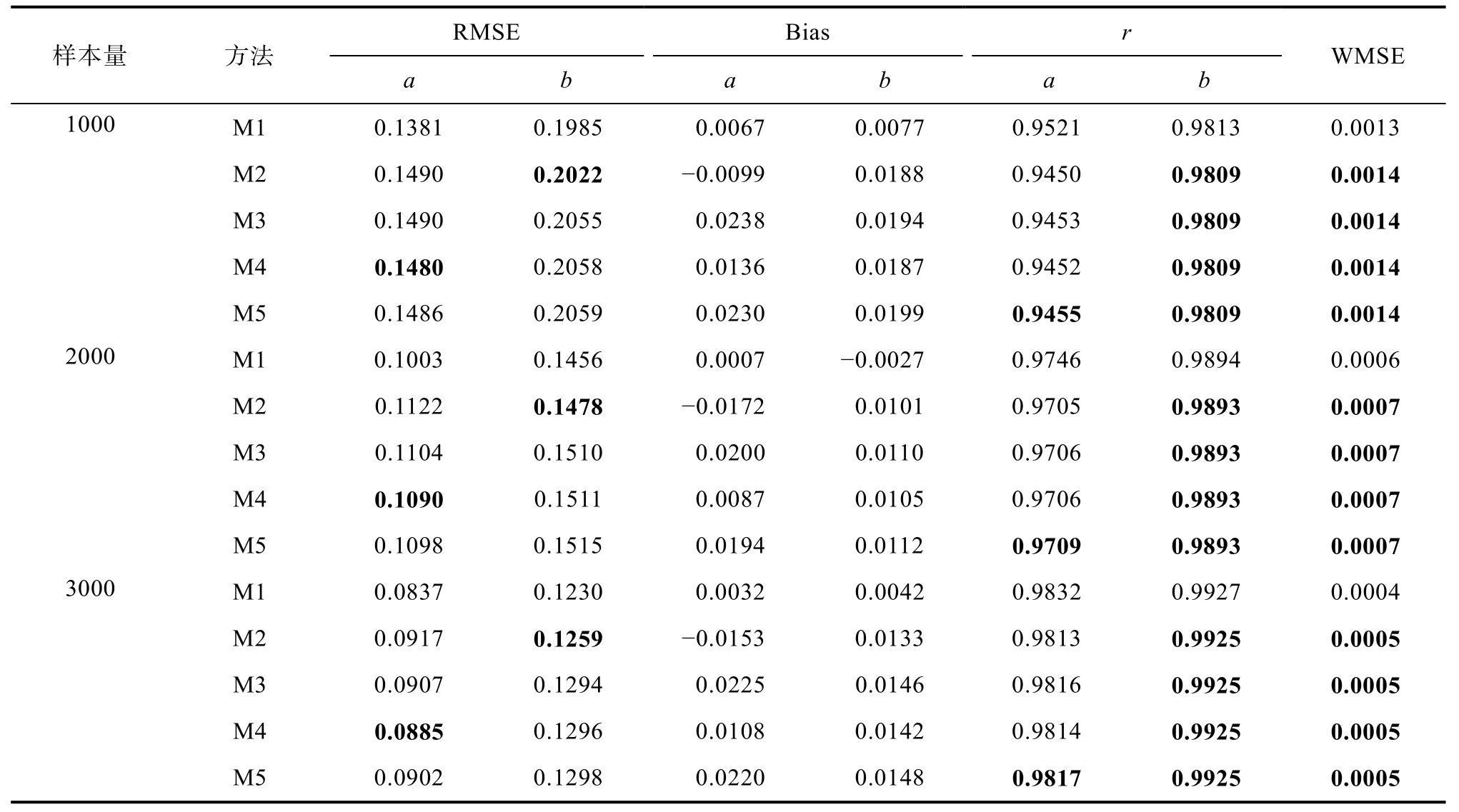
4.1.2 在线标定方法的标定精度
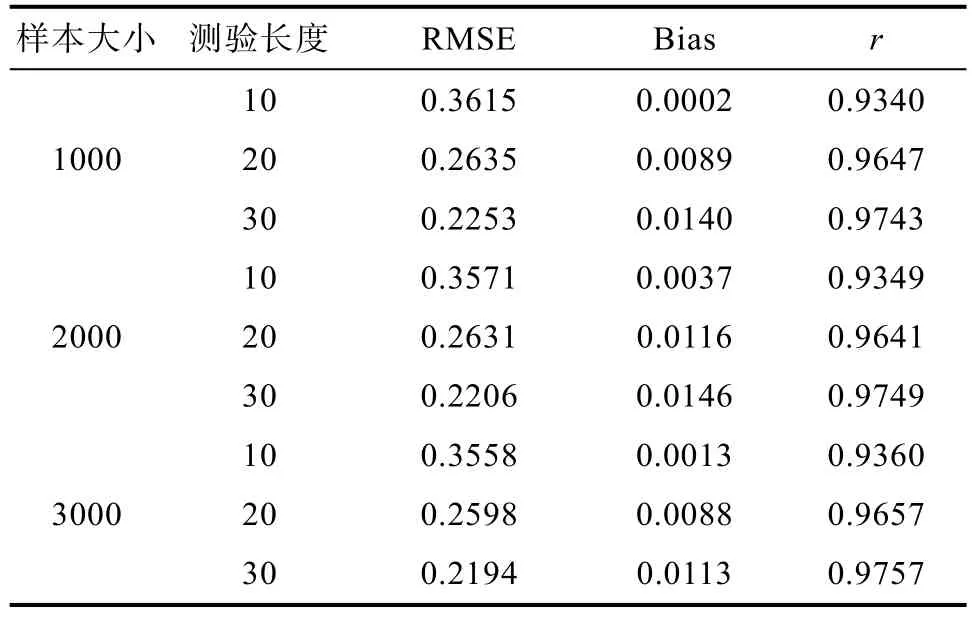


4.1.3 在线标定方法的标定效率


4.2 结论
5 讨论及今后的研究方向
