一种高效的基于初始聚类中心优化的K-means算法
2015-12-07张晓倩曲福恒杨勇才华梁鲜
张晓倩,曲福恒,杨勇,才华,梁鲜
(长春理工大学 计算机科学技术学院,长春 130022)
聚类分析是数据挖掘中常用的无监督学习方法[1]。聚类问题的基本形式被定义为找到给定数据集中的同组数据,每组数据又称为一个簇,并且处于某个簇中的数据对象的密度高于该对象处于其它的簇。目前已有的聚类方法很多,根据基本聚类思想的不同,聚类分析方法大致可以分为划分聚类、层次聚类、密度聚类、网格聚类和模型聚类五大类。
聚类分析旨在将给定的数据集划分为不相干的子集,并且每个子集中的数据对象具有较高的相似度。K-means是一种最常用的迭代划分聚类算法,使用该算法进行聚类时,首先它需要指定集群的数量,然后,提供初始数据集的划分并且这些初始簇的质心是提前计算出来的。在最初的K-means方法中,初始集群通常是随机选择的,显然,这种随机性会导致聚类结果的不稳定。为解决这个问题,许多K-means的初始化方法被提出。如文献[2]提出基于相异度的K-means改进算法,根据由相异度矩阵组成的霍夫曼树选择初始质心。文献[3]提出了一种利用反向最近邻(RNN)搜索方法选取初始质心。文献[4]结合数据密度分布和kd-tree进行选择初始质心。文献[5]根据样本空间分布信息,根据每个数据样本方差的大小以及样本间平均距离选取初始聚类中心。文献[6]提出了基于全局优化的思想选取初始聚类中心,该算法通过多次运行K-means算法得到k个初始聚类中心。但由于选取初始质心的计算代价和时间代价大,该文献中又提出了快速全局K-means聚类算法,对选取初始中心的方法进行了改进,缩短了聚类时间。本文在文献[7]提出算法的基础上,对进一步提高聚类算法的效率问题进行了研究,提出了一种高效的基于初始聚类中心优化的K-means算法,通过存储每次迭代中的一些信息,用于下一次迭代,减少一部分计算量,提高算法执行效率。
1 最小方差优化初始聚类中心的K-均值算法
传统的K-means算法的聚类过程是随机选择k个初始质心,根据最近邻原则,将数据集中的数据样本与最近的初始质心归为一类,重复迭代,直至初始质心不再发生变化或准则函数收敛,得到最终的k个簇。K-means算法的核心计算为计算每个数据对象到k个聚类中心的距离,算法的时间复杂度为O(nkt),其中,n为数据对象个数,t为迭代次数。
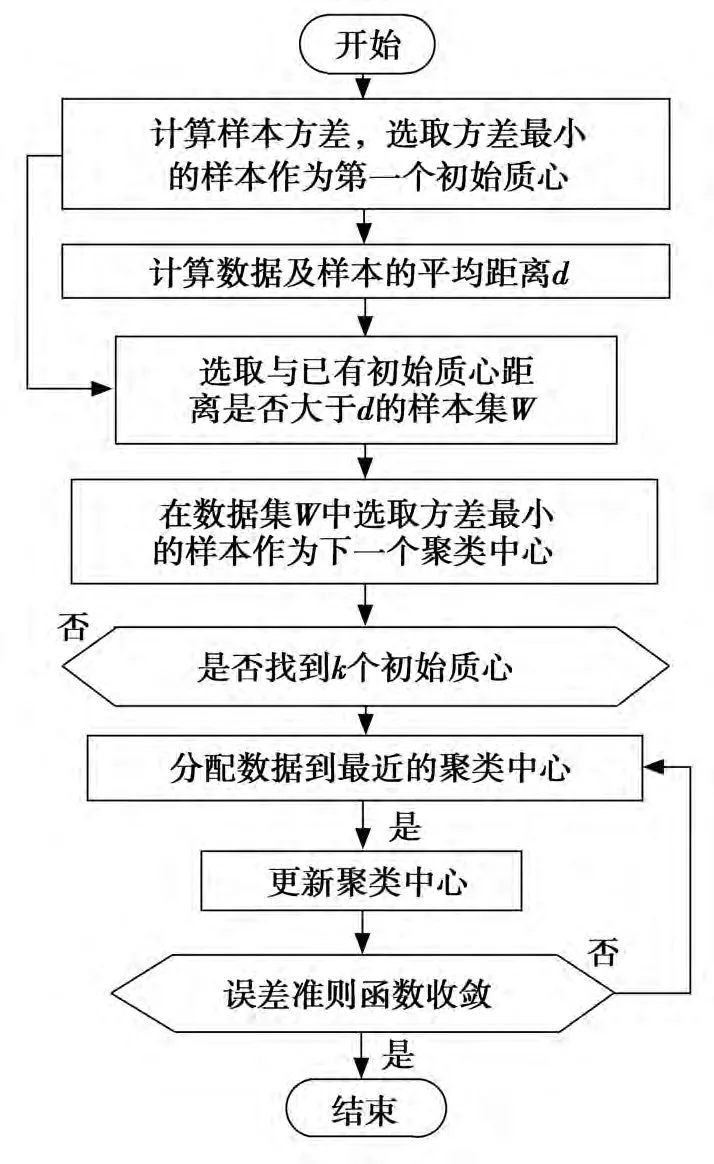
图1 最小方差K均值算法流程图
最小方差优化初始聚类中心的K-means算法[6]根据样本空间分布信息,根据每个数据样本方差的大小以及样本间平均距离选取初始聚类中心。首先选择所有样本中方差最小的那个作为第一个初始聚类中心;然后选取距离第一初始聚类中心距离大于样本间平均距离并且方差最小的样本作为第二个初始中心;重复该过程,直到找到k个初始聚类中心。在选取k个初始质心时,首先计算样本之间的距离矩阵,然后根据距离矩阵中的数据计算每个数据样本方差的大小,总的时间复杂度为O(n2),其中选取初始质心的时间复杂度为O(n2),在对每个数据对象进行归类分配时的时间复杂度为O(nkt1),其中t1为迭代次数。算法流程如图1所示。
2 本文改进算法
在K-means算法聚类过程中,在每次迭代数据点分配的过程中,需要每个计算数据点到所有聚类中心的距离,而在不断迭代过程中,一些样本点所在簇是不发生变化的。文献[7]中提出了一种改进的K-means算法,通过设置简单的数据结构,存储每次迭代中的一些信息用于下一次迭代。主要思想是:设置两个简单的数据结构,保存所有数据点的簇标志和到最近中心点的距离,用于下一次迭代,在计算数据对象到新中心的距离,如果这个距离小于或等于到原来中心的距离,则该数据对象仍在原来簇中。因此,不需要计算到剩余聚类中心的距离,节省了计算到剩余聚类中心距离的时间。本文将该文献中提到的改进算法的思想引入到最小方差优化初始聚类中心K-means算法中,在避免选择初始质心随机选取的同时缩短聚类时间。
2.1 几个相关的基本概念
定义1:样本之间的欧氏距离:
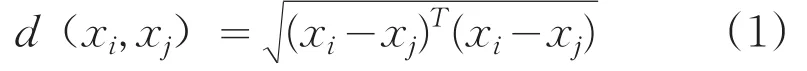
定义2:样本xi到所有样本距离的均值:
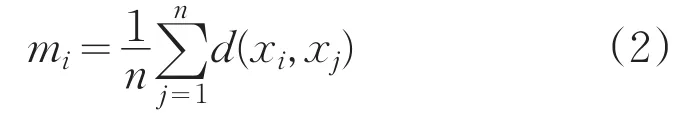
定义3:样本xi的方差:
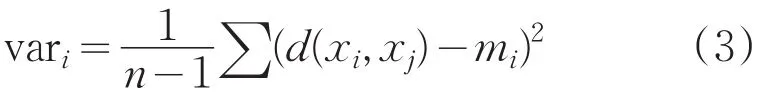
定义4:所有数据样本的平均距离:
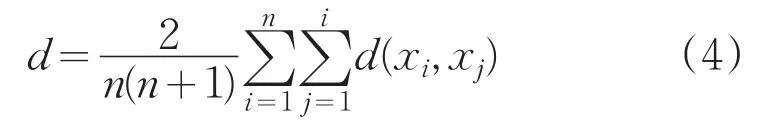
定义5:聚类准则函数:
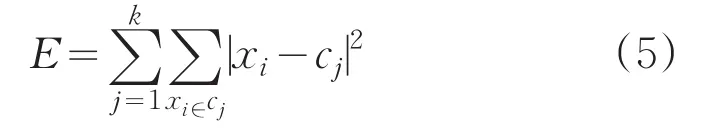
2.2 算法执行过程
改进算法的执行过程描述如下:
(1)选择初始聚类中心
1)根据定义1计算数据对象间距离;
2)根据1)中计算出来的数据对象间距离以及定义4计算平均距离d;
3)计算每个样本方差并选取方差最小的那个样本作为第一个聚类中心;
4)把与已有聚类中心距离大于平均距离d的样本方差置空,在剩余样本方差中选取最小的那个样本作为下一个聚类中心;重复该步,得到k个聚类中心,执行(2);
(2)执行改进后的K-means算法:
1)计算每个数据样本到各个初始聚类中心的距离,按最近离原则将其分到各个簇,存储每个数据对象的类标签和对象到最近中心点的距离到cluster[]和dis[]中;
让cluster[i]=j,j为对象i最近的簇标签;
让dis[i]=d(xi,cj),d(xi,cj)为到最近中心点的距离;
2)按照平均法计算各簇的质心,得到新的簇中心;
3)计算准则函数E;
(3)重复以下过程
1)计算每个数据对象到新聚类中心的距离d;
a)如果 d <=dis[i],则第 i个数据对象仍近似的在原来的簇中,将该数据对象分给原来的簇。
b)否则,计算数据点到所有中心的距离d(xi,ck),分配数据到最近的簇中心;让
cluster[i]=k ,dis[i]=d(xi,ck);
2)更新簇中心
3)计算准则函数E,判断E是否收敛,若收敛,则算法结束,输出最终聚类结果。
由前面对最小方差优化初始聚类中心K-means算法的复杂度分析可知,选取初始质心的复杂度为O(n2),在进行数据分配时,首先将N个数据对象分到k个簇,计算量为O(nk),在后面的迭代计算过程中,一些数据对象仍近似的保留在原来的簇中,而一些数据对象将分配到其它的簇中。如果数据点仍近似的留在原来的簇中,时间复杂度为O(1),否则,为O(k)。随着算法的不断收敛,每个簇中移动的数据点的数量也在不断减少,如果有一半的数据移动,此时的时间复杂度为O(nk/2),因此在进行数据分配时的总的时间复杂度为O(nk t2),其中t2为迭代次数,因此本文算法总的时间复杂度为O(n2)。
3 实验测试及结果分析
本文在UCI数据库中取5个不同的数据集进行测试,给出了数据集描述表以及各个算法的时间复杂度对比表,并对本文算法中的优化方法进行描述。各个算法在数据集运行30次得出实验结果,在聚类准则函数E上对传统K-均值,快速全局K均值、最小方差K均值算法,以及本文改进算法进行实验结果的比较;在运行时间上本文算法首先与前两种方法进行比较;由于本文算法与最小方差K均值选取初始质心的计算方法相同,则选取初始质心的时间上也相同,算法的提速主要是在后续聚类,因此,对两种算法运行时间的比较分两方面:选取初始质心时间T1与数据聚类时间T2,主要是对数据聚类时间进行比较。给出算法本身的迭代次数t,然后对各个算法的时间复杂度进行了对比分析。数据集描述如表1所示,时间复杂度对比如表2所示,实验结果的比较分别如表3、表4、表5所示。
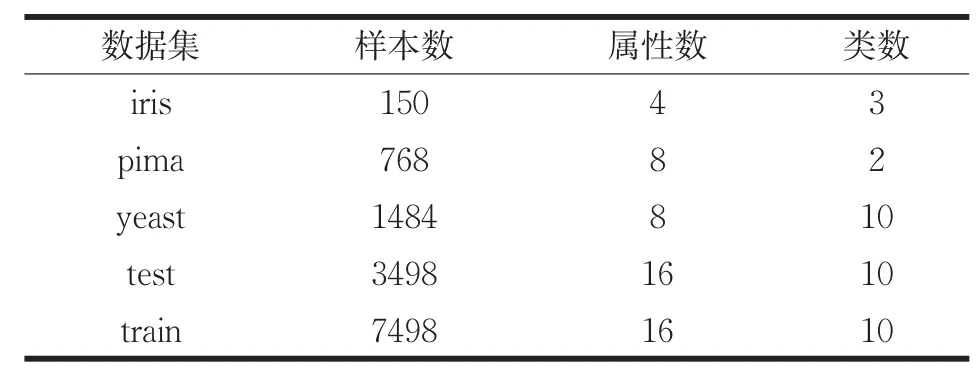
表1 数据集描述表
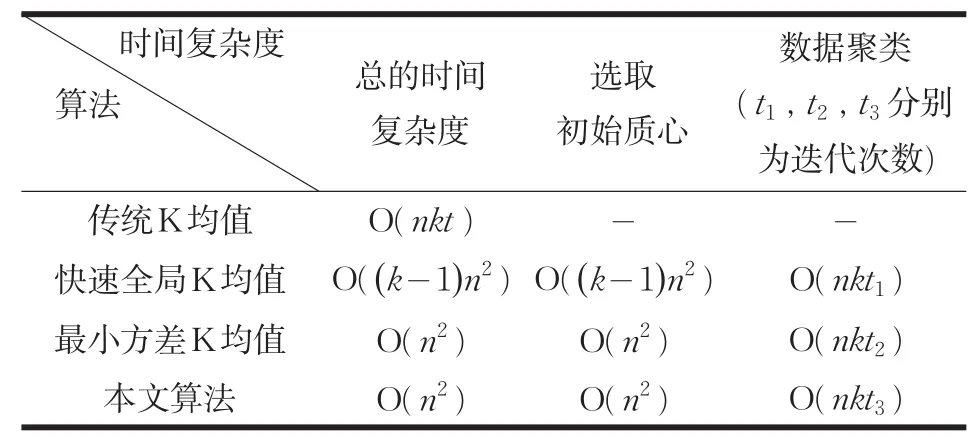
表2 时间复杂度对比
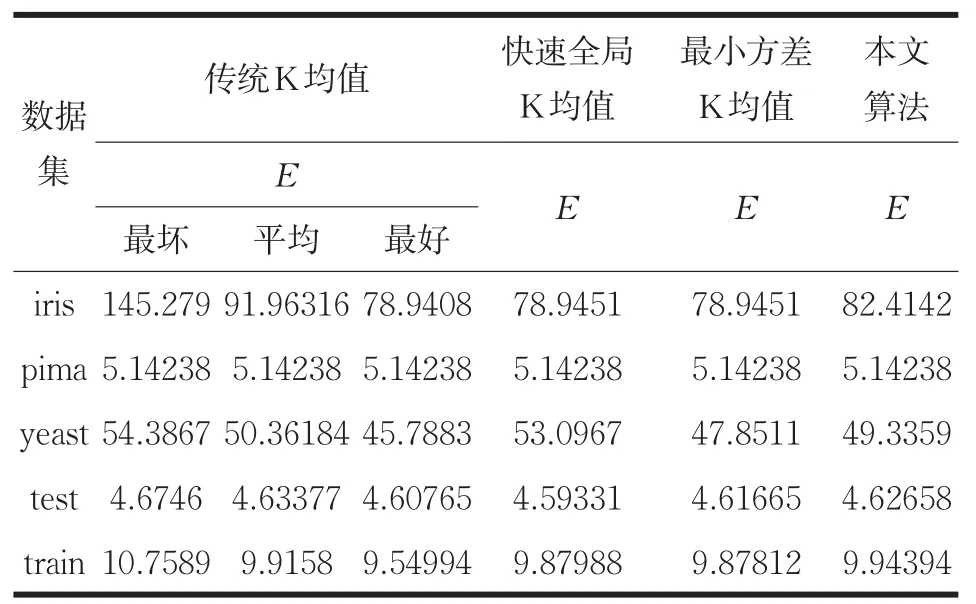
表3 各算法准则函数E上的比较
由表3可知,在pima数据集上,本文算法与最小方差优化初始聚类中心的K-means算法以及快速全局K-means算法保持了聚类结果的一致性。在yeast数据集上,本文算法聚类误差平方和略高于改进前算法,但优于快速全局K-means算法。在其它数据集上与最小方差优化初始聚类中心的K-means算法相比E虽然有所增大,但都接近于传统K-means算法最好或平均聚类误差平方和。由以上分析可知,本文算法基本上没有影响聚类结果,证明了改进后算法的有效性。
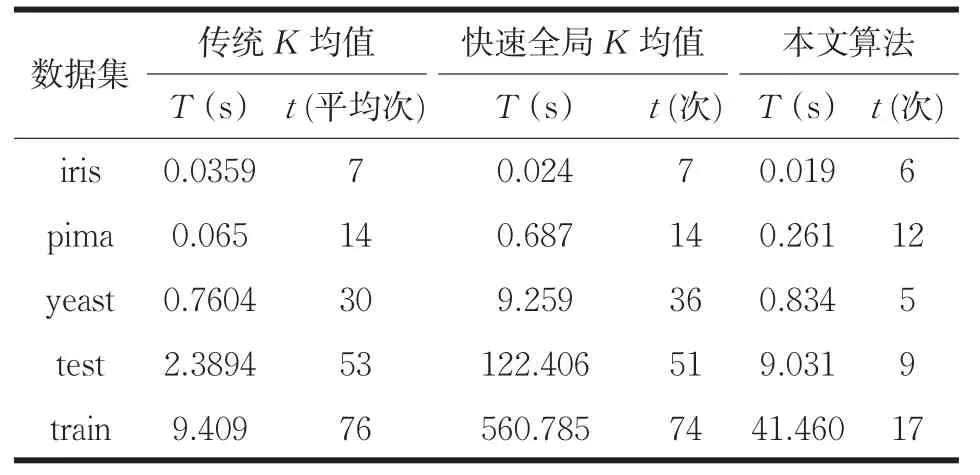
表4 各算法运行时间T上的比较
根据表2和表4的对比,可知本文算法与快速全局K均值的时间复杂度大于传统K均值,本文算法的时间复杂度小于快速全局K均值。由于通过计算的方法选取初始聚类中心相对于随机选取初始质心会消耗一部分运行时间,并且随着数据量的增大,选取初始质心的时间消耗增长,因此就表3中的所有数据集而言,快速全局K均值,以及本文算法不如K-means算法运行时间效率高,但本文算法的运行时间效率高于快速全局K均值。
由表2知本文算法选取初始质心的时间复杂度小于快速全局K均值选取初始质心的时间复杂度。在进行数据分配聚类时,本文算法的优化方法是通过存储每个数据对象的类标签以及与所属类中心的距离,在下一次迭代中,计算数据点与所属类中更新后的聚类中心的距离,若小于与原来聚类中心的距离,则近似的将该数据对象分给原来的簇,减少到其余k-1个中心距离的计算。随着迭代的进行,所需移动的数据点的个数在不断减少,在数据聚类时,需要与所有聚类中心计算距离的计算量减少,并且由于每个簇中数据点的变化减小,使得簇达到稳定所需的迭代次数也相对减少,缩短了算法收敛所需要的时间。
如表4所示,由于iris与pima两个数据集的数据量与簇的数目较少,算法的迭代次数变化不大,在其余三个数据集上,算法收敛的迭代次数都有明显的减少。迭代次数的减少以及本文算法选取初始质心与数据聚类所需的计算量小,使得算法的整体运算效率要明显高于快速全局K均值。
由于本文算法与最小方差k均值选取初始聚类中心的计算方法相同,选取初始质心时间T1相同,算法的提速主要是在后续聚类,因此本文算法主要在数据聚类时间T2上进行比较。根据上面对本文算法进行数据聚类时优化方法的描述可知,本文算法在已选出初始聚类中心的情况下,对数据点进行分配归类时,减少了数据点与聚类中心计算距离的计算量以及算法收敛所需的迭代次数,缩短了数据聚类所需的聚类时间。由表5可以看出,随着数据集的增大,聚簇数目的增多,算法收敛所需的迭代次数明显减少,本文算法相对于最小方差K均值的运算效率也有明显的提高,在iris与pima数据集上,进行数据聚类时的运算速度提高了40%~50%,在剩余的三个数据集上,进行数据分配归类时,进行数据聚类时的运算速度提高了70%~90%,可见,改进后的算法明显缩短了数据分配归类所需的聚类时间,证明了改进后算法在时间性能上的高效性。
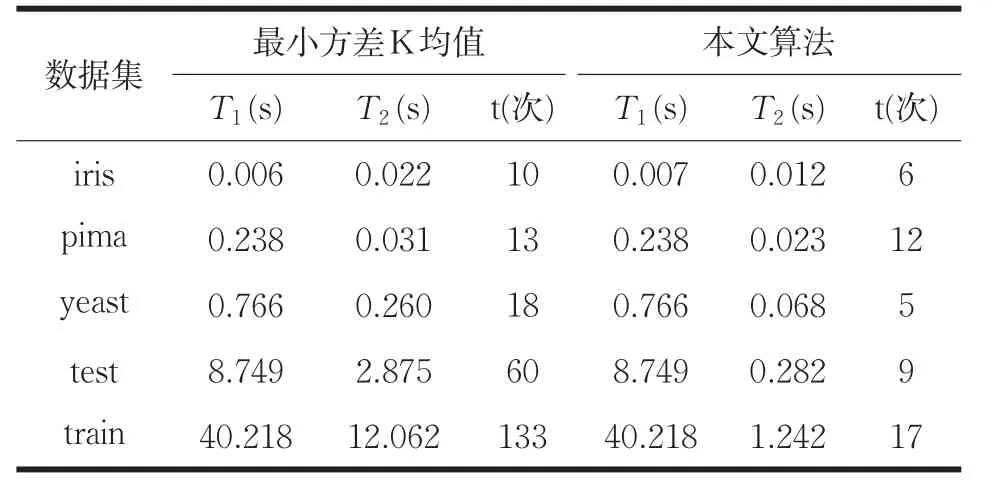
表5 本文算法与最小方差K均值的运行时间比较
综上所述,快速全局K均值,最小方差K均值以及本文算法的时间复杂度大于传统K均值的时间复杂度,但这三种方法都是通过计算来获得稳定的初始质心,由表3可知,这三种算法的聚类结果相对于传统K均值算法的聚类结果,更具有稳定性和准确性。由表2、表4可知,本文算法的时间复杂度优于快速全局K均值,算法的整体运行效率明显高于快算全局K均值。本文算法与最小方差K均值相比,由于两种算法选取初始聚类中心的计算方法相同,选取初始质心的时间相同,主要是对后续的数据聚类进行优化提速,由上面的分析可知,本文算法相对于最小方差K均值算法,减少了后续聚类的计算量以及算法收敛所需的迭代次数(如表5所示),证明了本文算法在时间性能上的高效性。
4 总结
本文通过将一个简单有效的数据聚类方法引入到最小误差优化初始聚类中心的K-means算法中,在避免随机选取初始聚中心导致聚类结果不稳定的基础上,减少了计算量,提高算法的执行效率,并在UCI数据集进行了实验验证,实验结果证明了改进算法在聚类结果上的有效性以及在聚类时间上的高效性。
[1]Han Jiawei,Kamber M.Data mining:concepts and techniques[M].Beijing:China Machine Press,2011.
[2]Shunye W.An improved k-means clustering algorithm based on dissimilarity[C]//Mechatronic Sciences,Electric Engineering and Computer(MEC),Proceedings 2013 International Conference on IEEE,2013:2629-2633.
[3]Xu J,Xu B,Zhang W.Stable initialization scheme for k-means clustering[J].Wuhan University Journal of Natural Sciences,2009,14(1):24-28.
[4]Redmond S J,Heneghan C.A method forinitializing the K-means clustering algorithm using kd-trees[J].Pattern Recognition letters,2007,28(8):965-973.
[5]谢娟英,王艳娥.最小方差优化初始聚类中心的K-means算法[J].计算机工程,2014,40(8):205-211.
[6]Likas A,Vlassis M,Verbeek J.The global K-means clustering algorithm[J].Pattern Recognition,2003,36(2):451-461.
[7]Na S,Xumin L,Yong G.Research on k-means clustering algorithm:An improved k-means clustering algorithm[C]//Intelligent Information Technology and Security Informatics(IITSI),2010 Third International Symposium on IEEE,2010:63-67.
