基于格子Boltzmann方法的多孔介质流动模拟GPU加速
2015-11-30朱炼华郭照立
朱炼华,郭照立
(华中科技大学煤燃烧国家重点实验室,武汉 430074)
文章编号:1001⁃246X(2015)01⁃0020⁃07
基于格子Boltzmann方法的多孔介质流动模拟GPU加速
朱炼华,郭照立
(华中科技大学煤燃烧国家重点实验室,武汉 430074)
利用NVIDIA CUDA平台,在GPU上结合稀疏存贮算法实现基于格子Boltzmann方法的孔隙尺度多孔介质流动模拟加速,测试该算法相对基本算法的性能.比较该算法在不同GPU上使用LBGK和MRT两种碰撞模型及单、双精度计算时的性能差异.测试结果表明在GPU环境下采用稀疏存贮算法相对基本算法能大幅提高计算速度并节省显存,相对于串行CPU程序加速比达到两个量级.使用较新构架的GPU时,MRT和LBGK碰撞模型在单、双浮点数精度下计算速度相同.而在较上一代的GPU上,计算精度对MRT碰撞模型计算速度影响较大.
多孔介质;GPU;格子Boltzmann方法;并行计算
0 引言
多孔介质内的流动现象广泛存在于自然界及油气藏开采、化工过程、环境保护等诸多工业领域.多孔介质流动是一类典型的跨尺度现象,在孔隙尺度上利用计算流体力学方法对这类现象进行直接模拟是研究其微观流动机理的重要手段.由于多孔介质的孔隙结构十分复杂,使用常规的基于直接离散求解Navier⁃Stoke方程的方法(有限体积法、有限差分法、有限元法)在孔隙尺度模拟时流固边界难以处理.格子Boltzmann方法(LBM)作为一类基于微观分子动力学的介观数值方法,复杂流固边界容易处理,并且并行效率高,十分适合孔隙尺度多孔介质流动的并行数值模拟[1-2].
模拟孔隙尺度多孔介质流动时,刻画高度非规则的流固边界需要很高网格分辨率,因此计算量很大,通常需要采用并行计算加速.最近几年流行起来的通用GPU(GPGPU)高性能技术是一种非常有潜力的并行计算技术.现代GPU提供的计算能力和存储带宽远远超过同期主流的CPU.NVIDIA公司于2007年推出CUDA GPU计算构架后,GPGPU编程难度降低,诸多科学计算应用被移植到GPU平台[3-4].LBM算法空间局部性优良并且计算瓶颈在访存带宽,因此特别适合于GPU并行计算.Tölke等人最早实现了LBM的CUDA程序,在单块GPU加速比达到一个量级以上[5].国内黄昌盛等人系统分析了LBM的GPU优化方法[6],李博等人做了关于多GPU的LBM实现方面的工作[7].
目前关于GPU加速LBM计算的文章中,流场大多为较规则的空腔体,而LBM的典型应用领域则是具有复杂流固边界的流动模拟.针对规则流场的常规LBM GPU算法在模拟多孔介质这种高度非规则流场时,存在显存浪费、GPU执行效率不高等问题.另一方面,在CPU平台,Pan等人在2004年提出了一种针对多孔介质流动的稀疏存贮LBM算法,可以大幅降低内存耗用[8],但该工作使用的是传统的基于消息传递接口(MPI)的并行方式.鉴于目前GPU上搭载的显存容量非常有限,在GPU上应用该算法显得尤为必要.由于GPU构架与CPU相差较大,该算法的GPU版本性能受更多因素影响.本文将上述稀疏存贮算法应用于多孔介质流动模拟的GPU LBM程序,测试并分析该算法相对基本算法的性能优势,然后比较两种常见碰撞模型(MRT、LBGK)以及所使用的浮点数精度对该算法性能的影响.
1 计算模型
模拟外力驱动下多孔介质流动问题,使用标准D3Q19模型,其分布函数(DF)fi的演化方程为

其中下标i表示离散速度方向,x为空间位置,t为时间,δt为时间步长,ci为格子离散速度,其各分量为(2)
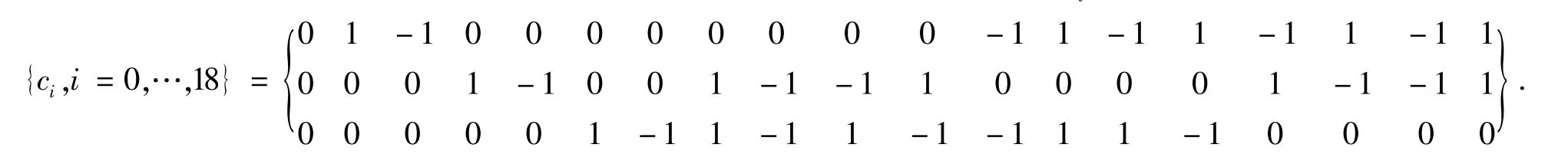
方程(1)右端第一项Ωi为碰撞算子,第二项Fi为离散外力项.本文使用的He[9]等人提出的外力离散格式,即
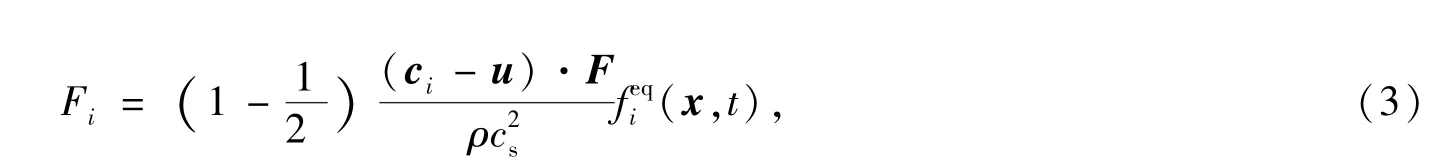
其中cs=1/3为格子声速, 是无量纲松弛时间,与运动学粘性ν有关,ν=c2s(-0.5)δt,F为外力大小,ρ和u分别为宏观密度和速度,(x,t)为平衡态分布函数,其定义为
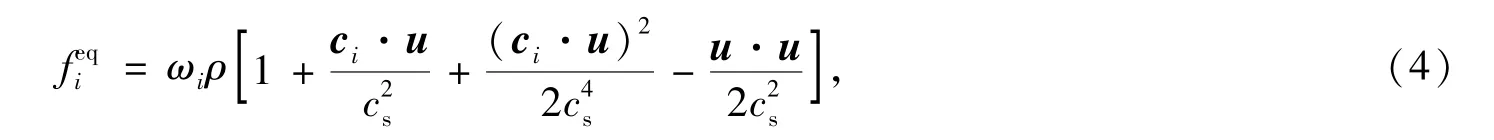
其中ωi为权系数,ω0=1/3,ω1,…,6=1/18,ω7,…,18=1/36.流体宏观密度ρ和速度u由密度分布函数得到
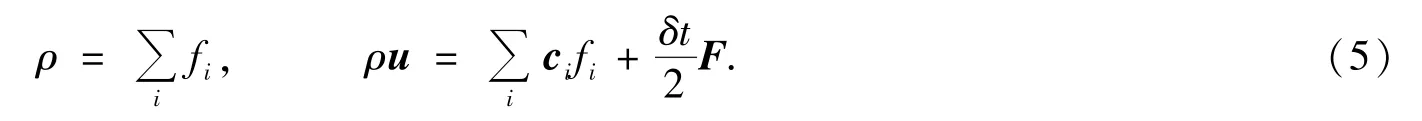
使用两种碰撞算子模型,即单松弛时间(LBGK)模型和多松弛时间(MRT)模型.LBGK模型碰撞算子形式为

MRT模型的碰撞过程在密度分布函数的速度矩空间完成,其碰撞算子形式为

其中M是变换矩阵,向量meq是速度矩的平衡态,M和meq的具体形式可参考文献[10].矩阵S为对角矩阵,其对角元素分别为各个矩的松弛因子,即
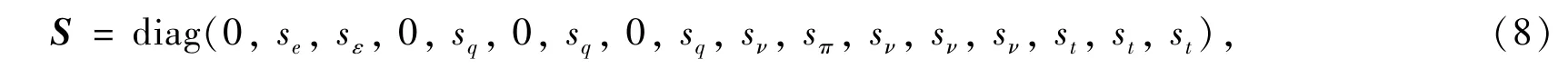
其中sν和sε与运动学粘度ν和体粘度ζ相关:

sν由运动学粘度ν控制,其它松弛因子按Ginzburg等人提出的双松弛时间(TRT)模型[11]取值,即

2 LBM算法的GPU实现及分析
2.1 CUDA构架
CUDA构架通过一种Grid⁃Block⁃Thread的三层次结构将计算任务按数据并行的方式映射到GPU上的大量处理单元上并行执行,同一个Block中的Thread之间可以通过共享内存通信.并行计算任务被编写为称之为Kernel的函数.为充分利用GPU提供的带宽,访问显存时需要满足连续、合并访问.为高效利用GPU上的大量处理单元,需要合理选择Block大小并控制Kernel函数中使用的寄存器个数,并且要避免Kernel函数中出现分支判断语句.
2.2 基本LBM算法的GPU实现
LBM算法是一种显式时间推进算法,在每个时间步内,依次执行碰撞、迁移和边界处理三个步骤.多孔介质中有大量不参与计算的固体区域,可以用一个三维Flag数组来标记格子中格点类型,演化时只有对流体格点执行碰撞和迁移步骤.为减少全局显存访问次数,碰撞和迁移可以放在一步执行.为了实现连续、合并访问全局显存,应保证相邻格点的同一离散速度的DF在显存中的位置是连续的.以C语言为例,开辟的DF数组形式应为f[Q][NZ][NY][NX],这里Q表示离散速度个数,NX、NY、NZ表示格子大小.由于迁移步每个格点需要访问周围格点DF,当迁移的速度方向有X方向分量时会出现内存访问不对齐的情况,Tölke最早提出利用GPU上的共享内存辅助迁移过程来克服这个问题[5].随后Obrecht[12]等人指出这种方式在实现复杂Kernel函数时会因共享内存数量不足而限制GPU执行效率,而且在较新的GPU上,对显存访问地址对齐的要求大为降低.本文在实现时采用Obrecht的方法,即直接访问周围格点DF.
在本文所考虑的多孔介质流动模拟中,所有外边界都是用周期边界条件,而孔隙壁面则用标准反弹格式处理,这两种边界条件都可以在迁移过程中隐式处理,不需要增加单独的Kernel函数来特殊处理.总结以上讨论,基本算法在每其一个演化步的计算流程为
1)通过Flag数组判断当前格点类型,若当前为固体格点,则不作任何处理,否则进入下一步;
2)读取周围格点DF,若某一方向相邻格点为固体格点,则从当前格点反方向读取DF;
3)统计宏观量;
4)执行碰撞操作,将新的DF写入显存.
2.3 稀疏存储算法
上一小节描述的通过Flag数组来刻画流场结构的方法虽然实现简单,但在GPU上实现时存在一些问题.首先,在开辟DF数组时,不需要演化固体格点也占据了存储空间和带宽.自然界中的多孔介质孔隙率通常在0.3~0.4之间[8],相当于有多达70%的显存被浪费了.目前主流的GPU所搭载的显存容量有限,并且其存储带宽是其性能瓶颈,所以在GPU上这一问题也更突出;其次,由于演化时对固体格点和流体格点处理方式不同,导致线程执行过程分支,GPU执行效率大为降低.
为解决上述问题,可以借鉴稀疏矩阵存贮方法.稀疏矩阵中大量元素都是0,存贮时可以只储非零元素及其位置.同样,在处理多孔介质时可以只存贮流体格点的DF,即事先将流体格点从多孔介质结构中提取出来,然后开辟形式为F[fluid_num][Q]的数组存储其DF,其中fluid_num为多孔结构中流体格点的个数.采用这种存储方案时,格点之间的相对位置关系丢失了,所以还需要构造一个辅助数组node_map[fluid_num][Q-1]来记录每个格点的相邻Q-1个格点在数组F中的索引位置.在格点i执行k方向迁移操作前,先通过这个辅助数组查询其k方向的相邻格点在数组F中的位置(node_map[i][k]),再执行写入操作,完成迁移过程.最后,在模拟计算结束并统计出宏观量后,再将其还原到原始的三维矩阵结构用于后处理.
可以分析对比基本算法和稀疏存贮算法的显存耗用情况.假设计算区域流固格点总数为N,多孔结构的孔隙率为ε,DF使用单精度浮点数.node_map元素使4字节无符号整形变量存储.若不采用稀疏存储模式,忽略Flag数组所占空间,则需要消耗显存

若采用稀疏存储模式,则需要消耗显存
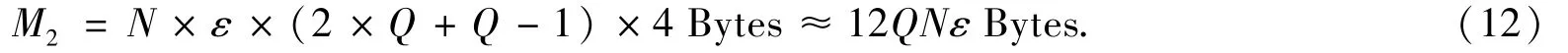
可以发现当孔隙率ε<0.75时,M2<M1.因此在大部分情况下,采用稀疏存贮均能节省显存开销.
采用稀疏存储方案时,格点之间的拓扑关系已经存储在node_map数组里面了,在构造这个数组时,周期边界格点和孔壁处反弹格点的迁移规则均可反映在这个数组里,即不用显式判断并分别处理外边界格点和孔隙壁面反弹格点,演化的Kernel函数里面不会出现判断分支语句.因此,可以预测采用稀疏存贮方案后GPU执行效率会有显著提高.
3 数值算例
3.1 验证算例
本节先通过模拟计算得出一种理想多孔介质模型的绝对渗透率并与解析解对比来验证GPU程序实现的正确性,然后在此基础上,测试稀疏存储算法与基本算法的计算速度,最后测试分析影响计算性能的其它因素,如LBGK/MRT模型、单/双精度.
计算使用的多孔介质模型——体心立方(BCC)结构的最小单元如图1所示,位于中心的球体和立方体顶点上的1/8半球体半径均为r,立方体边长为L.固体区域所占比例和孔隙率分别为
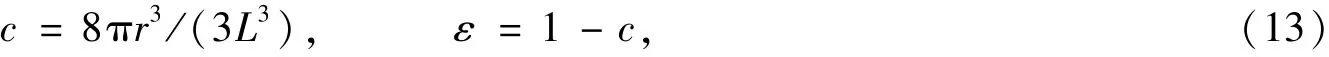
其中c的最大值为cmax=3π/8.BCC结构的绝对渗透率近似解析解形式为

其中d∗为单个球体所受的无量纲阻力,在Re<1的时,其级数解析解为


图1 BCC多孔介质模型Fig.1 BCC porousmediamodel
数值模拟时,通过给定外力g,在流场达到稳定后,统计流场平均流速ud,通过达西渗流定律可确定多孔介质的渗透率

其中ud为流场平均流速,▽pz和ρg分别为压力梯度和外力大小.
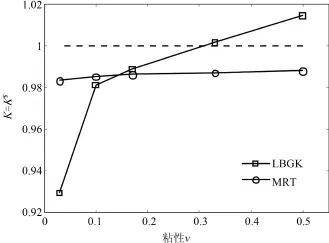
图2 使用不同碰撞模型的计算结果Fig.2 LBGK and MRT results
Pan等人指出LBGK模型结合标准反弹格式模拟多孔介质流动时,计算所得的渗透率与流体运动粘度相关联,这是非物理的现象,而若使用MRT模型,则可显著改善这一问题[10].本文分别使用MRT和LBGK模型计算了χ=0.8在不同粘性时对应的渗透率.计算区域格点数为1283,根据解析解确定外力大小使得流动雷诺数Re固定为0.1.计算使用双精度浮点数,收敛标准为相邻1 000个演化步计算所得渗透率相对变化小于10-5.使用LBGK和MRT模型的计算结果与解析解得比值如图2所示.从图中可以看出,在同一孔隙率情况下使用不同松弛时间(即不同的运动粘度ν),LBGK模型模拟的结果与解析解相差明显,而使用MRT模型则结果较理想.由此可见,本文模拟结果验证了Pan等人结论,验证了GPU程序的正确性.
为考察GPU浮点数精度对计算结果的影响,测试了χ=0.8,=1.0时,使用单精度和双精度计算时K/K∗的收敛过程,结果如图3所示,单精度计算演化9 300步后渗透率收敛到0.986 2,而双精度计算演化9 400步收敛到0.986 4,单精度相对于双精度误差为0.02%.说明在GPU上使用单精度浮点数计算渗流问题,由于计算精度引起的误差较小.下文计算性能测试中如无单独说明,均使用单精度计算.
3.2 性能测试
性能测试计算环境为Intex Xeor X5550 CPU,如无特殊说明,GPU均使用Nvida Tesla C1060.CUDA toolkit版本为3.2,操作系统为 CentOS 5.8 64bit版,程序使用CUDA扩展的C语言.计算速度衡量标准为每秒百万格点更新速率(MFLUPS),其计算方法为

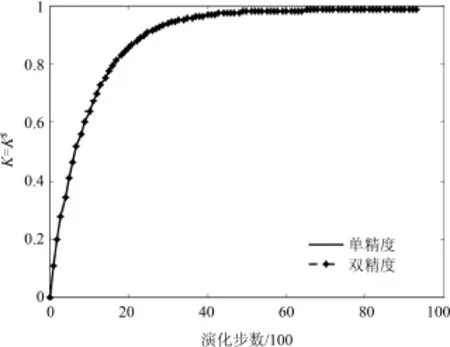
图3 使用不同浮点数精度计算的收敛过程Fig.3 Convergence processwith different float precisions
其中Tevol为演化步数,在本工作中,Tevol均取10 000步,Nf为流体格点个数,tcomp为总的计算时间.
图4所示为采用基本算法(完全存贮算法)和稀疏存贮算法在不同孔隙率下的计算速度对比,两种算法均使用LBGK模型,网格规模为1283.从图中可以发现,基本算法计算速度随孔隙率的减小近似线性下降,当孔隙率从0.95减为0.3左右时,计算速度从180 MFLUPS降到了80 MFLUPS以下,与第二节中的分析相符,即这是由于无效的固体格点占据了GPU流处理单元的执行时间.而作为对比,稀疏存贮算法计算速度基本不受孔隙率影响,在所考察的孔隙率范围内基本能维持在200MFLUPS以上.另外可以发现在孔隙率接近1即计算区域几乎不含固体格点时,稀疏存贮算法计算速度仍比基本算法高,这是因为在这种情况下,虽然基本算法的Kernel中判断语句几乎没有分支,但是其总体指令数量较稀疏存贮算法大得多,并且需要显式处理流场外边界.后文分析影响性能的其它因素均使用稀疏存储算法.
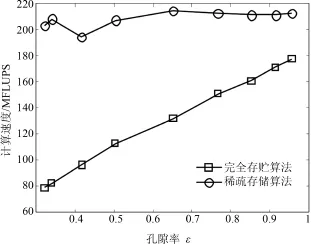
图4 稀疏存贮算法与基本算法的计算速度Fig.4 Performance of different algorithms
值得指出的是,同样使用稀疏存贮算法的CPU串行程序,用4.6版本的gcc编译器结合O2级优化选项编译时,在各种孔隙率下计算速度均低于2MFLUPS.可见使用GPU加速的稀疏存储算法相对于CPU平台加速比能达到两个量级.
为分析碰撞模型(LBGK/MRT)和浮点数精度对计算速度的影响,测试了在不同网格规模下,使用不同碰撞模型和浮点数精度时的计算速度.测试时,孔隙率固定为0.32(BCC结果所能达到的最小孔隙率),计算网格规模从403变化到3203.为使性能规律更具一般性,在更新一代的Tesla K20 GPU也做了相同测试.两种GPU上的测试结果如图5和图6所示.
从图5和图6中均可发现当Nf较小时,计算速度随Nf增大而增大,而当Nf增大到一定程度时,计算速度基本保持不变.从图中还可发现在某些特定的网格规模时,计算速度呈现突然的降低(图中曲线的V字形区域).在使用单精度浮点数或C1060 GPU计算时,这一现象更为明显.文献[14]也观察到了这一现象,尽管该文没有采用本文使用的稀疏存贮算法.出现该现象是因为每个格点读取周围格点DF时不满足合并访问条件,这会导致GPU流处理器效率在某些特殊的计算规模处出现很大幅度的下降[14],相比较而言,在较新构架的K20 GPU上,由于非合并访问造成的的性能下降较小,所以上述现象相对不明显.
对比图5和图6可以发现,K20 GPU计算速度约为Tesla C1060的2.5到3倍,这是因为LBM算法的性能瓶颈正是存储带宽,而K20显存带宽为C1060显存带宽的2.8倍.
从图5和图6中还可以看出,对于同一种碰撞模型,双精度(DP)浮点数计算比单精度(SP)计算大约慢50%,这是因为是采用双精度浮点数计算时显存数据传输量增大,并且寄存器文件使用增多导致GPU执行效率降低.从图中还可发现,在K20 GPU上,MRT和LBGK碰撞模型的计算速度几乎相同,而在C1060 GPU上,使用双单精度时,MRT模型计算速度明显比LBGK慢.理论上,MRT模型计算量只比LBGK模型多15%~20%[1],而访存量没有变化,按照LBM算法的性能瓶颈在显存带宽这一点来看,两种碰撞模型的计算速度应该没有显著差异.但由于MRT模型的Kernel函数中需要的寄存器文件比LBGK多,在C1060 GPU上寄存器容量较为有限,使用双精度浮点数时,寄存器容量限制了其运行效率.而在构架较新的K20 GPU上,寄存器容量相对充裕,所以无论是单精度还是双精度,LBGK和MRT模型计算速度几乎相同.

图5 Tesla C1060 GPU计算速度Fig.5 Computing speed with Tesla C1060 GPU
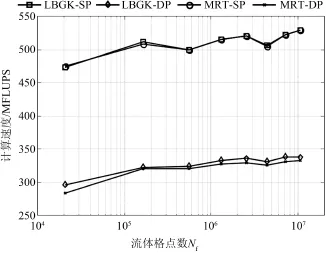
图6 Tesla K20 GPU计算速度Fig.6 Computing speed with Tesla K20 GPU
最后,对于稀疏存储算法,流体格点存贮顺序可能会影响对计算速度.在上文计算中,提取三维孔隙结构中流体格点构造稀疏存贮数组时,均是依次按照Z、Y、X的顺序遍历.这里我们测试了按其他遍历次序时的计算性能,但发现计算速度没有显著差别.如果相应地重新排布离散速度顺序,则遍历次序可能会对计算速度有明显影响[15],这一问题还有待进一步研究.
4 结论
将Pan等人[8]提出的稀疏存贮LBM算法运用到了GPU加速的多孔介质孔隙尺度模拟.性能测试结果表明,在GPU上,使用这种算法能大幅提高加速比并节省显存,并且孔隙率越低,效果越明显.测试了GPU浮点数精度对渗透率计算结果的影响,结果表明单双计算精度计算结果相差极小,满足工程应用要求.分析了在C1060和较新的K20 GPU上,碰撞模型、浮点数精度以及计算规模对该算法计算速度的影响,测试结果表明,使用双精度浮点数要比单精度性能下降约一倍.在较新的K20 GPU上,无论使用单精度还是双精度浮点数,MRT和LBGK碰撞模型性能相同,而在上一代的C1060 GPU上,使用单精度浮点数时两种碰撞模型计算速度相同,但使用双精度浮点数时,MRT模型明显比LBGK模型慢.值得指出的是,以上工作都是基于标准均匀格子的并行化方法,在下一步的研究中,我们将考虑在非常规网格如树形网格[16]上结合GPU实现并行化.
[1] Guo Z L,Zheng C G.Theory and application of lattice Boltzmann method[M].Beijing:Science Press,2009:202-204.
[2] Deng Y Q,Tang Z,Dong Y H.Lattice Boltzmann method for simulating propagating acoustic waves[J].Chinese Journal of Computational Physics,2013,30(6):808-814.
[3] Kirk D B,Hu W M.Programmingmassively parallel processors[M].Beijing:Tsinghua University Press,2010:31-32.
[4] Huang S,Xiao JY,Hu Y C,et al.GPU⁃accelerated boundary elementmethod for Burton⁃Miller equation in acoustics[J]. Chinese Journal of Computational Physics,2011,28(4):481-487.
[5] Jonas T.Implementation of a lattice Boltzmann kernel using the compute unified device architecture developed by nVIDIA [J].Computing and Visualization in Science,2010,13(1):29-39.
[6] Huang C S,Zhang W H,Hou ZM,et al.CUDA based lattice Boltzmann method:Algorithm design and program optimization [J].Chinese Science Bulletin,2011,56(28):2434-2444.
[7] Xiong Q G,Li B,Xu J,et al.Efficient parallel implementation of the lattice Boltzmann method on large clusters of graphic processing units[J].Chinese Science Bulletin,2012,57(7):707-715.
[8] Pan C X,Prins J F,Miller C T.A high⁃performance lattice Boltzmann implementation to model flow in porous media[J]. Computer Physics Communications,2004,158:89-105.
[9] He X Y,Shan XW,Doolen G D.Discrete Boltzmann equation model for nonideal gases[J].Physical Review E,1998,57 (1):13.
[10] Pan C X,Luo L S,Miller C T.An evaluation of lattice Boltzmann schemes for porousmedium flow simulaion[J].Computers &Fluids,35(8-9):898-909.
[11] Ginzburg I,Carlier JP,Kao C.Lattice Boltzmann approach to Richards'equation[C]∥Proceedings of the XVth International Conference on Computational Methods in Water Resources,Chapel Hill:Elsevier,2004:15-23.
[12] Obrecht C,Kuznik F,Tourancheau B,etal.A new approach to the lattice Boltzmannmethod for graphics processing units[J]. Computers&Mathematicswith Applications,2011,61(12):3628-3638.
[13] Sangani A S,Acrivos A.Slow flow through a periodic array of spheres[J].International Journal of Multihase Flow,1982,8 (4):343-360.
[14] McClure JE,Prinsy JF,Miller C T.Comparison of CPU and GPU implementations of the lattice Boltzmann method[C]∥XVIIth International Conference on Computational Methods in Water Resources,Barelona:CIMNE,2010:1-8.
[15] Mattila K,Hyväluoma J,Timonen,et al.Comparison of implementations of the lattice⁃Boltzmann method[J].Computers&Mathematics with Applications,2007,55(7):1514-1524.
[16] Chen Y,Xia Z H,Cai Q D.Lattice Boltzmann method with tree⁃structured mesh and treatment of curved boundaries[J]. Chinese Journal of Computational Physics,2010,27(1):23-30.
GPU Accelerated Lattice Boltzmann Simulation of Flow in Porous M edia
ZHU Lianhua,GUO Zhaoli (State Key Laboratory ofCoal Combustion,Huazhong Uniersity of Science and Technology,Wuhan 430074,China)
A sparse lattice representation lattice Boltzmannmethod algorithm is implemented on Graphics Processing Units(GPU)to accelerate pore scale flow simuation.Prefomance testing shows that sparse lattice representation approach grately reduces memory requirement and maintains performance under low porosity compared with basic algorithm.Overall speedup reaches two orders of magnitude compared with serial code.Various factors including collisionmodel,floatnumber precision,and GPU thataffect computing speed of the algorithm are invesgated independently.It indicates that MRT model runs as fast as LBGK model on new generation of GPU cards.While on old GPU cards,MRTmodel's computing speed matchs LBGK only when using single precision float.
porousmedia;GPU;lattice Boltzmannmethod;parallel computing
TQ021.1
A
2013-12-10;
2014-04-02
国家自然科学基金(51125024)资助项目
朱炼华(1992-),男,湖北孝感,硕士生,主要从事多相渗流数值模拟研究,Email:lhzhu@hust.edu.cn
Received date: 2013-12-10;Revised date: 2014-04-02
