基于FPGA 的图像超分辨率算法的实现
2015-09-19邓亚斌方志宏高志勇
邓亚斌,陈 立,方志宏,高志勇
(上海交通大学 图像通信与网络工程研究所,上海200240)
目前在消费电子领域,随着视频技术的发展,人们对于视频图像的清晰度要求越来越高,从以前的标清到现在的高清、超高清。为用户提供越来越好的观看体验时,对于视频的传输和处理技术提出了更高的要求。近些年来流行的4K 超高清电视给予人们非常震撼的体验,然而包括互联网和传统媒体中仍然存在着大量的高清视频,高清视频就要转化成超高清4K 视频进行播放。所以,为解决这一问题,可以在接收端对视频进行超分辨率处理。
目前的图像超分辨率算法有很多种,比较经典的有基于插值的领域插值,bilinear 插值和bicubic 插值[1]。现在主流的图像超分辨率算法主要是基于机器学习类的算法,即基于图像间的相似性来进行放大。但是基于外部数据库的机器学习类的算法对于训练数据库的依赖性较强,算法的鲁棒性不足。例如,在进行文字的超分辨的过程中,放置大量的文字的数据库得到的效果比用大量的人脸的数据库要好得多。目前流行的算法的数据来自于图像本身,利用图像的自相似性训练的可靠性强并且效果明显。
自相似性算法[2]可以产生边缘清晰的图像,有比较出色的效果。该算法的中心思想是:采用传统双线性插值(bilinear)方法,对原始图像进行小倍数放大得到初步放大图像,对原始图像进行下采样和上采样后得到原始图像的低频图像和高频图像;然后根据图像的自相似性通过块匹配添加相应的高频信息到初步放大图像中,改善视觉效果,完成一次超分辨率。
1 基于自相似性的超分辨率算法
图像自相似性的假设认为单帧图像的不同位置,同内容的不同分辨率的图像之间存在着相似性。超分辨率放大的倍数不同会导致图像相似性存在着差异,经过大量的实验表明,图像相似性的误差和图像超分辨率放大倍数之间并不是简单的线性的关系,在进行1.25 倍超分辨率放大的时候,图像相似性的误差接近于0,表明超分辨率前后存在着很强的自相似性。随着超分辨率放大倍数的增加,图像自相似性也会相应的减弱,放大过程丢失了更多的图像信息。实验证明,对于较大倍数的超分辨率过程,多次逐步地进行超分辨率相比于一次一步的放大会取得更好的效果。笔者基于自相似的超分辨率算法采用小倍数、多次超分辨、每次超分辨率的结果作为输入,进行下一次超分辨率,最终得到需要的超分辨率放大图像。下面以将图像进行2 倍超分辨率为例说明算法具体实现过程(见图1)。
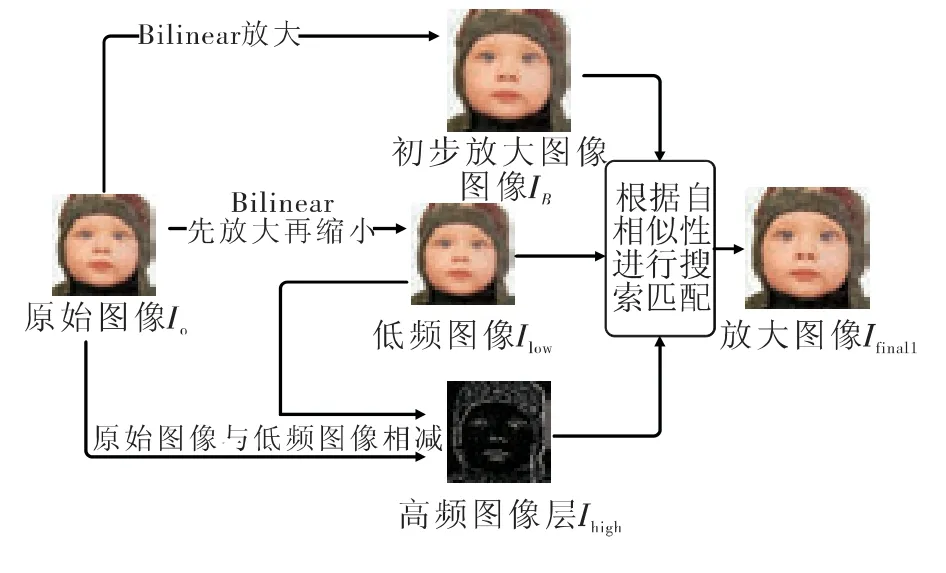
图1 基于自相似超分辨率算法流程图
算法流程[3]为:
1)用双线性插值对原始的图像I0超分辨率得到1.25 倍的放大的图像IB,IB=upsample(I0,1.25),其中upsample 表示采用bilinear 放大;I0表示原始图像,IB表示经过1.25 倍超分辨率后的图像。
2)对原始图像采用双线性插值得到0.8 倍的图像,然后进行双线性插值放大1.25 倍得到与原始图像IB相同图幅的低频图像Ilow,然后由原始图像I0与低频图像Ilow得到高频图像Ihigh=I0-Ilow;其中Ilow表示原始图像的低频层,I0为原始图像,Ihigh表示原始图像的高频层。
3)根据局部自相似的假设,Ilow和IB都含有低频信息,有很强的自相似性。在Ilow中寻找与IB匹配的块,匹配准则为SAD(绝对误差和)最小,找到后确定该匹配块在Ilow中的位置,并将Ihigh中相应位置的高频分量加到IB中。
4)对IB中所有的像素点对应的块进行操作后得到第一次超分辨率的图像Ifinal1。
5)将Ifinal1作为输入I0,重复步骤1)~4),可以得到再次放大的图像Ifinal2。如此循环迭代,直到达到相应的超分辨率倍数,最终得到经超分辨率后的图像。
2 硬件设计方案
2.1 总体框架
基于自相似性的超分辨率算法实现的总体硬件框架如图2 所示。
本设计基于模块化处理,每个模块的大小为16×16 像素,处理开始时根据外部的系统总线配置图像大小和超分辨率倍数的参数,同时接收视频数据并通过AXI(Advanced eXtensible Interface)总线存储到外存DDR3 中,启动超分辨率引擎内核,从外部读取一个图像块(16×16)的像素信息,根据自相似性超分辨率算法原理得到放大图像的数据信息并将其像素信息存储到外部存储器中。最后将数据进行输出显示。
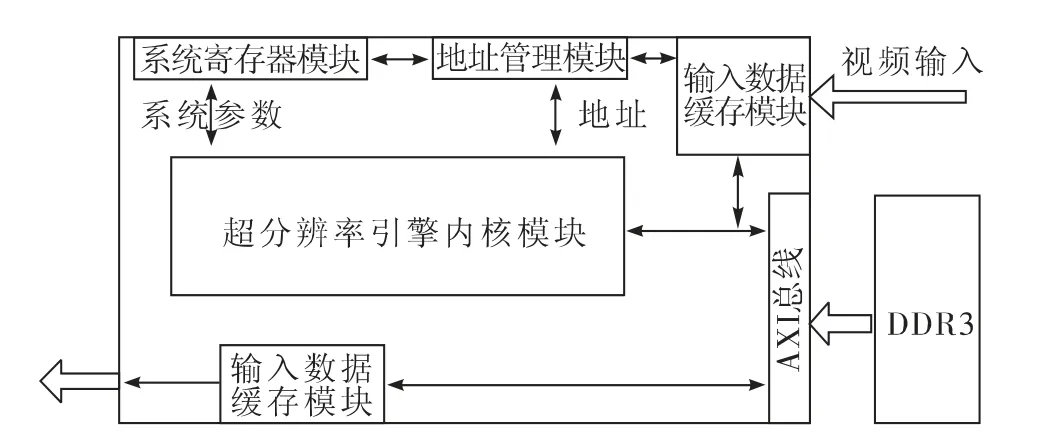
图2 算法实现硬件总体框架
硬件框架各模块的设计功能如下:
1)输入数据缓存模块。作为视频流入的主要通道,主要功能是将输入的数据信息处理成为AXI 总线可接受的格式,将视频数据存储到外存DDR3 中,带宽要求较高。
2)地址管理模块。地址管理模块主要功能是管理输入的视频数据在DDR3 中的存储地址、超分辨率引擎内核模块读取原始视频数据的基址和向外部DDR3 中写入超分辨率后视频数据的基址。
3)系统寄存器模块。作为超分辨率引擎内核和外部通讯的媒介,主要用于对超分辨率引擎内核进行配置及运行控制。可将超分辨率引擎内核配置成1.5 倍或者2.0 倍两种超分辨率比例,可应用于将720p 超分辨率成1 080p(1.5 倍),1 080p超分辨率成4K(2.0 倍)或者720p 超分辨率成4K(1.5倍+2.0 倍)等。
4)超分辨率引擎内核。作为本设计的主要运行单元,由寄存器控制启动,通过AXI 总线从外部存储器读取图像块数据,根据自相似算法对图像块进行递归超分辨率,控制数据流向,并控制超分辨率结果写回到DDR3 中。
5)输出数据缓存模块。主要负责将超分辨率后的数据从DDR3 中读取并组织成输出接口的时序输出到显示器中显示超分辨率后的视频。
2.2 超分辨率引擎内核
超分辨率引擎内核是一个递归超分辨率内核,每次超分辨率都调用同一个超分辨率内核scale core,通过多次调用实现超分辨率的目的。对于不同的超分辨率比例,递归次数和每一次递归的超分辨率比例都不一样,例如,对于2 倍超分辨率,3 次递归把16×16 图像放大到32×32。对于1.5 倍放大,需要两次递归把16×16 图像放大到24×24。但是输入尺寸和输出尺寸都一致,为32×32 的像素块,输出模块需要通过系统配置判断输出图像中哪部分是有效的,无效部分不输出到内存。
超分辨率引擎内核在接收到寄存器模块的start 信号后,外存请求管理模块计算外存数据的地址,并且向外存发送数据请求,超分辨率引擎内核接收到数据后开始处理第一个色彩分量,从源地址处一行一行的读取像素,当一个模块的像素都读取完后启动scale core 开始第一轮超分辨率运算。由于运算对外缘数据的需求,实际输入图像是以实际须放大的16×16 图像为核心,4 方向外延8 像素得到的32×32 图像区块。所以需要用块数据缓存模块对于输入的数据进行缓存和重新的组织。
每次递归需要把运算结果缓存到内核数据缓存模块,此模块将作为下一次递归运算的数据源。所以递归的第一次运算,数据源来自于外部内存,之后的递归运算,数据源都来自于内核数据缓存模块,而递归运算的结果,除了最后一次运算输出到外部内存外,其他都直接输出到内核数据缓存模块。
当3 个色彩分量全部依次处理完毕后,超分辨率引擎内核返回待命状态,超分辨率引擎内核结构如图3 所示。
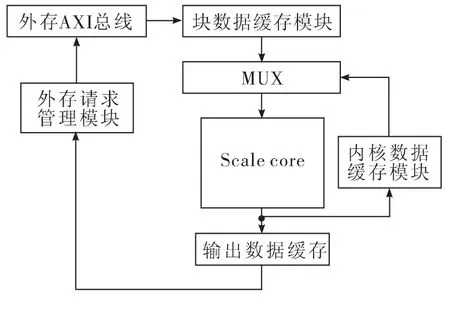
图3 超分辨率引擎内核结构图
2.2.1 Scale core
Scale core 是图像超分辨率设计的核心模块,该模块接收32×32 的10 bit 图像块(16×16 的图像块经过4 方向外延得到)数据经过基于自相似性超分辨率得到32×32 的图像块数据并且存入RAM 中。如图4 为Scale core 的结构图。

图4 Scale core 结构图
图像块经过下采样上采样得到低频图像块L1 存放在RAM 中,I1 经bilinear 放大得到的图像块L2 也放入RAM 中,逐点扫描L2 中像素数据,设当前点为IL2(i,j),确定3×3 的待匹配块match,计算在RAM 中的地址从RAM 中读取出数据。
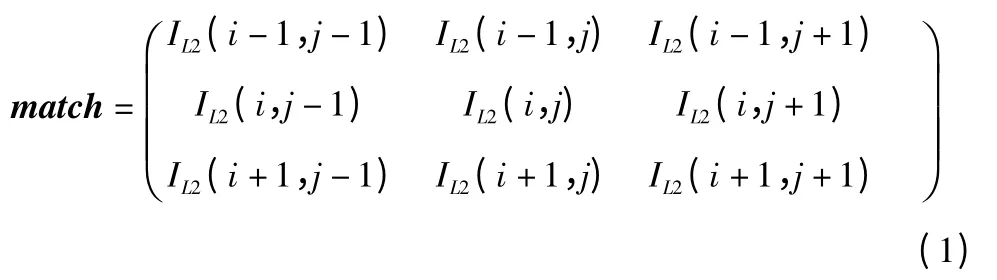
与此同时地址映射模块根据图像的映射关系计算出L1中对应图像块的中心点坐标IL2(e,f),在L1 对应坐标中心点周围4×4 的搜索窗内对每一点进行3×3 的块的SAD 计算寻找匹配块,取其中的SAD 值最小的(e,f)作为匹配块的中心位置。然后计算H1RAM 中的匹配块的地址取出H1 中对应的高频分量数据。重复以上过程得到超分辨率图像的高频图像数据。将放大图像L2 的数据与超分辨率图像高频数据H2 相加得到超分辨率图像块I2 的数据并且存入RAM 中,完成一次超分辨率。
2.3 带宽分析
整个设计将图像分为16×16 的块,对于不同的视频图像带宽也会不一样,下面分析将1 080p 放大到4K 图像的带宽。对于每一个16×16 的块,每个块每一轮运算约耗费100个clk。
1 080p 放大到4k×2k@60 Hz,YUV422,block 总数为

总时钟频率为

内存读取带宽(10 bit 视频)为
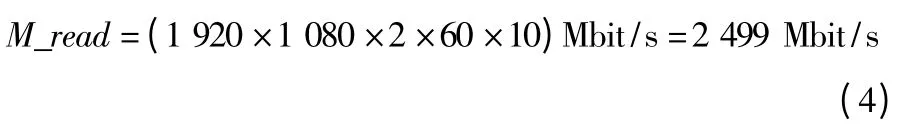
内存写入带宽(10 bit 视频)为

3 FPGA 实现及验证
采用Kintex7-325T 芯片,使用Verilog[4]语言实现,使用ISE 对于整个验证系统综合得到资源使用情况如表2 所示,完成了设计的实现和验证。验证系统经HDMI 接口实时输入1 080p@25 Hz,YUV422 的视频,经过视频超分辨率引擎后通过HDMI 接口实时输出4K@25 Hz,YUV422 的视频到显示器端进行显示。
内核的时钟频率为111.375 MHz,DDR3 的时钟频率为200 MHz。对于每一个16×16 的块,每一轮的超分辨率运算约耗费100 个clk。对于1 080p@25 Hz,YUV422 的视频,block 总数为

表2 系统FPGA 资源使用情况
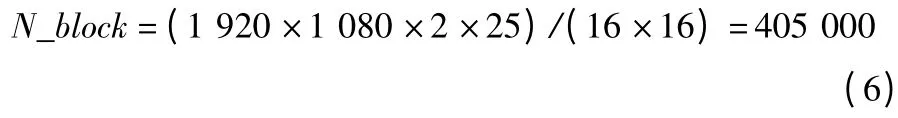
为达到实时处理的要求,理论上需要的时钟频率ftheory为

这表明现在的设计能够满足实习处理的要求。
对于内存读取带宽(10 bit 视频)为
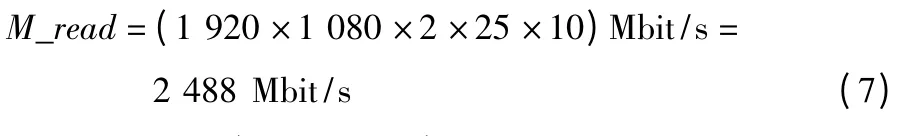
内存写入带宽(10 bit 视频)为
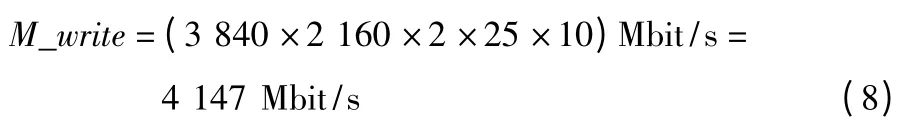
对于本设计的DDR3,在频率为200 MHz 情况下的理论带宽Bandwidth 为
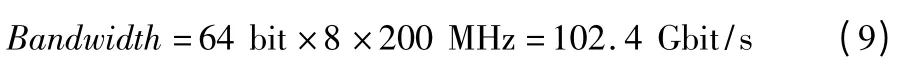
系统验证平台及结果见图6。

图5 FPGA 验证系统(照片)
4 小结
本文给出了基于自相似性原理的超分辨率算法的FPGA实现,对于视频图像进行分块的处理,给出了硬件设计的整体框架,并详细地叙述了各模块的功能和设计,最后在Xilinx 的K7 FPGA 进行了硬件验证。在现有的设计下实现了1 080p@25 Hz,YUV422 视频到4K@25 Hz,YUV422 视频的实时超分辨率。
该算法在FPGA 上实现了从高清到超高清的实时超分辨率处理,并且取得了很好的主观效果,并且该设计有很大的灵活性,根据不同的视频图像超分辨率需求进行配置;缺点是对于低质量的视频图像的超分辨率可能会强化图像的噪点,可以考虑在处理完之后再进行去噪处理。
[1]KEYS R G. Cubic convolution interpolation for digital image processing[J].IEEE Trans. Acoustics Speech&Signal Processing,1981,29(6):1153-1160.
[2]FREEDMAN G,FATTAL R.Image and video upscaling from local self-examples[J].ACM Trans.Graphics,2011,30(2):474-484.
[3]JIANG H,CONG Z,GAO Z,et al.Image super-resolution with facet improvement and detail enhancement based on local self examples[C]//Proc.2013 International Conference on Wireless Communications& Signal Processing (WCSP).[S. l.]:IEEE Press,2013:1-6.
[4]PALNITKAR S. Verilog HDL 数字设计与综合[M].2 版.夏闻宇,译.北京:电子工业出版社,2009.
