基于点云模型的低质汉字骨架提取算法
2015-08-05侯显玲
侯显玲
(四川旅游学院信息与工程系,成都610100)
汉字骨架提取是汉字识别领域的一个重要的研究方向[1-4],汉字骨架提取尤其是低质汉字骨架提取仍然是一个困难问题.本文讨论的汉字降质因素主要有五种:稀疏、断裂、模糊、墨迹点以及噪声.其中,被上述一种或几种降质因素同时影响的印刷体或手写体汉字称作低质汉字.大量的信息损失使得正确提取符合人类视觉的“好”的汉字骨架成为一个非常困难的问题.文献[2]中,作者给出了一个“好”的汉字骨架应该满足的条件:1)与原始汉字形状接近;2)符合人类的视觉;3)粗细应是一个像素(或接近一个像素);4)独立于原始形状的大小、位置、质量和辨识度;5)在噪声扰动和可容许的扭曲形变下应是稳定的.此外,“好”的骨架还应该穿过笔画中心.因为骨架是一种在噪声影响下具有稳键性的且信息量较少的汉字替代物,是穿过数据分布中心的像素点集合[1-2].因此,本文中将只有同时满足上述条件的汉字骨架才称为“好”骨架.
过去几十年业内学者提出了众多的汉字骨架提取算法,其中大多数算法都是基于汉字轮廓是可以确定的这一假设之上.基于这种假设的算法可分为三类:对称轴分析算法、细化算法和形状分解算法[3-4].对称轴分析算法的思想是通过寻找汉字轮廓的对称轴来获得骨架[5].这类算法将骨架看作是中轴变换的对称中心点构成的集合.然而,这类算法很难在离散域里准确地寻找出汉字骨架,且骨架通过中轴变化后一般都是断裂的,从而造成算法的性能严重地依赖于轮廓提取的结果.这一类算法常见的有Tang等人提出的利用小波极大模提取汉字骨架方法[6-8].细化算法通过迭代地将目标的边缘点更新成背景点,最后,当目标变成一个由大量单像素宽的弧线和曲线所组成的集合时,也即为汉字的骨架,算法收敛.虽然这些曲线和弧线较完整地保持了目标的拓扑性质[2].但细化算法在处理一些规则汉字时,其提出的骨架中常常会出现许多断裂和分叉.同时,这类算法也很难从间断或稀疏严重的低质汉字中提取出完好的骨架.一些研究者试图用形状分解算法来抑制骨架中人造小分支的产生[9].该类算法将目标分解成一些简单的部分,再分别提取这些简单部分的骨架,以获取最终目标的骨架.例如,Zou等人通过约束的德劳内三角形对形状进行分解[10-12],该算法涉及到形状的三角剖分、规则性分析及区域融合,计算复杂度高.
综上,提取低质汉字的骨架仍然是业内的一大挑战,尤其是在出现断裂和稀疏的情形下,当前大部分骨架提取算法都不能准确的提取出符合人类视觉的“好”骨架.本文建立一种低质汉字的点云模型,同时,将该模型与优化和数理统计方法相结合,从而获得符合人类视觉的“好”骨架.
1 点云模型
由于现有的骨架提取模型并非针对低质汉字,因此本文提出了一种新的模型即点云模型.
本文讨论的汉字降质因素有稀疏、断裂、噪声、模糊和墨迹点(见图1).

图1 汉字降质因素
图1中,(1)~(5)为低质汉字图像,(6)~(10)是与之对应的细化方法得到的骨架.
一般地,汉字笔画在受图1中的降质因素干扰以后会出现如下的问题:1)由一些孤立的像素点和孤立的像素区域构成的稀疏笔画使得大部分中轴算法和细化算法不能准确地提取骨架;2)一些不再联通的笔画片段造成当前骨架提取算法提取的骨架是断裂的;3)在噪声污染的笔画中存在许多不同质的点,从而引起细化算法产生人工分叉或无法运行;4)模糊因素造成笔画边缘提取困难,因此依赖轮廓精确定位的算法无法运行;5)墨迹点使汉字轮廓不规则,对于这类汉字,通过对称轴分析法所提取的骨架是断裂的,而使用细化算法提取的骨架则产生长的人工分叉.

图2 汉字及其轮廓
低质汉字的笔画是由稀疏孤立笔画点和孤立笔画片段构成以及低质汉字的轮廓定位困难,从而造成基于轮廓精定位的骨架提取算法很难获得“好”骨架.而当前的骨架提取算法都是依赖于轮廓的精确定位,因此,本文将该模型称之为轮廓模型.图2中(1)和(2)给出了理想汉字(即没有受到任何降质因素影响的规则汉字)“标”及其轮廓,(3)和(4)是断裂汉字“村”及其轮廓.图2(2)很好的描述了理想汉字“标”的轮廓,基于此理想轮廓,采用现有骨架提取算法可以提取出较好的骨架,但基于图2(4)采用现有算法则很难提取出符合人类视觉的“好”骨架.由于低质汉字受到降质因素影响无法正确提取出理想轮廓,因此轮廓模型不适用于低质汉字.
本文利用点云模型来刻画低质汉字,通过在低质汉字的像素点上直接进行处理,从而消除汉字轮廓的定位准确性带来的影响.点云是在同一空间参考系下表达目标空间分布和目标表面特性的点的集合,点云中的点既可以是孤立的、稀疏的,也可以是成片的.点云模型不仅可以刻画低质汉字及多种降质情况,还可以描述理想汉字;不依赖于轮廓定位结果,直接对汉字的数据点进行处理;该模型对噪声鲁棒,处理点云的相关理论分析也较为成熟.
2 初始骨架提取
在点云模型下,为了提取出一个像素宽且满足对称性要求的初始骨架,本文考虑选择一种统计方法来满足对称性要求,同时能够实现点云数据的降维.对称统计方法中,主成分分析法(PCA)是一种简单而又鲁棒的线性降维方法.假设汉字的骨架是分段线性的,若用适当的标签去标记汉字的点云,那么每类点云的对称线性归纳构成其主成分分量.因此,低质汉字的初始骨架可以看成是由所有类别的主成分构成.然而,点云的类别个数是并不是已知的.为了确定类别个数,本文采用增量聚类方法.因此,本文利用增量广义K均值聚类算法来提取初始骨架.
有研究工作表明均值聚类(KMC)中心可以是单个的点,也可以是主成分线段[13].给定一组观测值(x1,x2,…,xn),广义 K均值聚类指将 n个观测值分成 K 个数组(k< n)S={S1,S2,…,Sk},分组的标准是最小化聚类内部的平方和即:

指中的点的主成分线段.
在KMC中,骨架提取结果的准确性严重依赖于K的取值,而K的取值又随着汉字的变化而变化.基于软K主曲线[14]增量搜索算法,本文寻找K值的方法是逐步地增加汉字点云中主成分线段的数量,直到满足收敛条件为止.最后,通过增量广义K均值聚类方法便可得到由一些主成分线段构成的集合,我们称之为初始骨架.其中,集合中的元素为初始骨架段.具体地,初始骨架提取算法的步骤如下:
1)初始化步骤:基于点云模型,本文将低质汉字看作二维平面点阵图,表示为 X=(x1,x2,…,xn).读入数据点集X,零均值化后计算出第一主成分线,然后截取图像点阵重心左右3σ/2的长度作为初始线段的长度,其中σ2是第一主成分线上投影点的方差.令初始线段为s1,其对应的Voronoi区域为 V1={x1,x2,…,xm},k=1,n=3.
2)添加新线段步骤:首先添加新关键点(关键点按目标函数最大下降的准则选择),新关键点xq需满足line(xi))}
其中:d(xi,xq)= ‖xi- xq‖2,(i=1…m),
则新选取的关键点xq的Voronoi区域为:
Vq={x∈X|‖x -xq‖≤min d(x,sj),j=1,2,…k}
判断更新后的Voronoi区域内的数据点数是否小于n,若是,则程序结束;反之,则依据1)中的方法,求取Vq中的第一主成分线段,k=k+1.
3)调整步骤:调整原有Voronoi区域中的第一主成分线段:
a.设原有 Voronoi区域为;V=(V1,V2,…,Vk);∀si,i=1,…,k,求调整过后的区域 V',其中
b.依次比较 V=(V1,V2,…,Vk)与 V'=[V'1,V'2,…,V'k]每一个区域是否相同,如果不同则计算V'j(j=1,2,…k)的第一主成分线段,完毕后更新 V=(V1,V2,…,Vk),继续第2)步,如果相同则结束调整步骤.
4)重复2)~3),直到Voronoi区域内的数据点的个数小于等于n,最后输出初始骨架.
3 初始骨架的连接
本节考虑如何连接初始骨架,以满足“好”骨架的第1)、2)和4)条件.本文利用高层马可夫模型将初始骨架段连接问题转化为优化问题.考虑到大部分汉字结构都是规则分布的,本文将汉字的这种规则结构作为一种先验信息加入到代价函数中,以获得更加符合人类的视觉的汉字骨架.
本文基于后验信息,利用Bayesian理论与最大后验-马尔可夫随机场框架设计出了一个目标优化函数,以将最大后验概率转化为最小后验势团能量[15].在 MAP-MRF框架下,初始骨架作为地点集合,集合中的每一个元素为初始骨架段.由于地点集合定义在特征层上,因此,我们采用高层的马可夫随机场模型.假设初始骨架由k个初始骨架段构成,则地点集定义为:S={1,…,k}.S中的地点通过邻域系统与其他地点相关,N={Ni-∀i∈S}表示S的一个邻域系统.Ni是邻近地点集的集合.其中,邻域系统是一个所有的初始骨架段都是相邻的全局邻域.通过MAP-MRF理论,原优化问题可以转化为一次标记问题,利用最小化势团能量来获取最优标记f*(f*=arg minfU(f|d),U(f)为能量函数).设L为标签集,则一个标签假定为由k个标签组成的标签集L中的一个离散值,即L={1,…,k}.集合f={f1,…,fk}表示标签集L在地点集S里的一次标记.这里,能量被描述成几个项之和,每项由确定大小的势能团来描述,即:
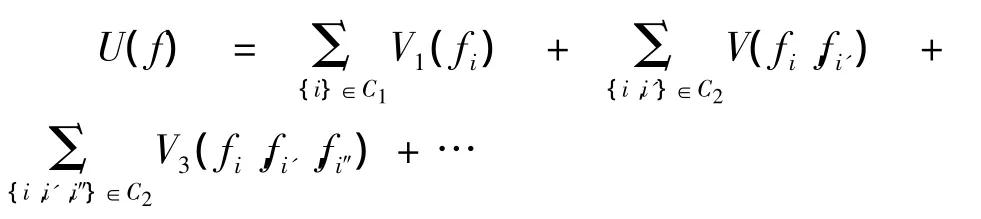
这里,把不希望得到的结果的势团能量定义得较大,同时将期望得到的结果的势团能量定义得较小.因此,这样可以方便地加入先验信息.在初始骨架的接连时,我们将较小能量的两个线段连接起来,而能量值大的两个线段不予连接.其中,两线段间的势能团能量可以描述为:
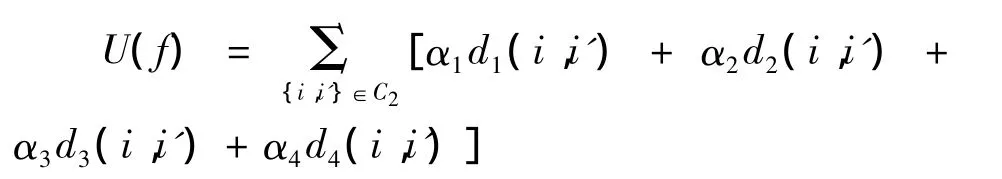
这里 αi=1,…,4 是超参数,d1(i,i')是线段 i和它邻居线i'段间的最短距离,定义为:
d1(i,i')=inf{d(x,y)| ∀x∈ i,∀y∈ i';{i,i'}∈C2}
d2(i,i')线段i与它相邻线段i'之间的夹角.d3(i,i')为线段和笔画趋势的角差.其中笔画趋势定义为:
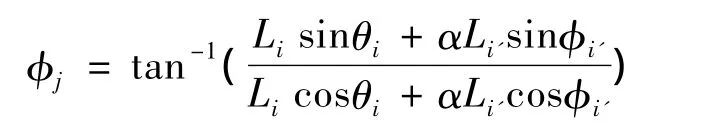
Li表示线段 i的长,α 是常数,tan θi表示线段的斜率,tan φi'为线段 i'的斜率.d4(i,i')为线段 i与i'的连接线上白点的数目(假定笔画点为黑点,白点不是笔画点).
本文初始骨架连接算法的思路是用贪婪算法去迭代地更新地点集与标签集,直到所有初始骨架线段被连接.算法步骤为:首先初始化,假设初始骨架由 m 条线段组成,S={1,…,m},f={f1,…,fm},定义阀值为T(依据先验信息,一般人工的设为7到10个像素距离).接着,计算任意两初始骨架段间的能量U(f),连接满足U(f)<T条件的线段,为了判断连接方式,先延长其中一条线段,然后用线段连接两线段端点.然后,更新S和f.最后,重复上一步,计算所有线段对之间的势能团能量,以遍历完任意线段,且任意两线段间的势能团能量U(f)>T为止,最后输出骨架.
4 实验
本文提出的新方法提取低质汉字骨架框架见图3.

图3 本文算法整体框架
初始骨架的提取和连接是提出算法的两大核心步骤.在此框架下所提取的低质汉字骨架满足“好”骨架的要求.

图4 CDT方法、轴对称方法及本文方法提取结果对比
为了更好地描述本文所提出的低质汉字骨架提取新方法性能,我们将CDT方法、轴对称方法与新方法的提取骨架结果进行了比较.在图4中,第一列是低质汉字.第二列是CDT方法骨架提取的结果,提取的骨架存在人工小分支和断裂,,不满足保持拓扑性和与人类视觉吻合的要求,不是“好”骨架,从图4(2)中可以看出CDT并不适用于稀疏汉字情况.第三列是轴对称方法获得的骨架结果,同样存在稀疏断裂的情况,且无法对受噪声点影响的汉字提取骨架,第四列是我们的方法提取的结果.其中,为了显示最终骨架与低质汉字的吻合度,绿色的最终骨架被叠放在黑色的低质汉字上.很明显最终骨架与汉字有很高的吻合度,这说明我们方法提取的骨架很好地修正和保持了低质汉字的拓扑特性.很显然,最后一列骨架满足本文第一节所提出的“好”骨架的要求.
5 结语
本文提出了一个新的适合低质汉字骨架提取的模型即点云模型.在点云模型基础上,本文的新方法分两步实现骨架提取:首先获取初始骨架,本文利用增量广义均值聚类方法;然后在高层马可夫模型下连接初始骨架,最终得到的骨架满足“好”骨架要求.本文方法是基于概率统计和优化理论,因此在很多降质因素影响的情形下也具有高鲁棒性.
[1]LAM L,LEE S W,SUEN C Y.Thinning methodologies:A comprehensive survey[J].IEEE Trans.Pattern and Machine Intelligence,1992,14(9):869-885.
[2]廖志武.2-D骨架提取算法研究进展[J].四川师范大学学报:自然科学版,2009,32(5):5676-5688.
[3]KLETTE G.A comparative discussion of distance transforms and simple deformations in digital image processing(a survey)[J].Machine Graphics and Vision International Journal,2003,12(2):235-256.
[4]CAGRI A.Disconnected skeletons for shape recognition[D].Mph thesis for Middle East Technical University,2005.
[5]H LUM.Biological shape and visual science(Part 1)[J].J Theo Biol,1973,38:205 -287.
[6]TANG Y Y,YOU X G.Skeletonization of ribbon-like shapes based on a new wavelet function[J].IEEE Trans.Pattern and Machine Intelligence,2003,25(9):1118 -1133.
[7]YOU X G,CHEN Q,FANG B,et al.Thinning character using modulus minima of wavelet transform[J].International Journal of Pattern Recognition and Artificial Intelligence,2006,20(3):361-375.
[8]YOU X G,TANG Y Y.Wavelet-based approach to character skeleton[J].IEEE Transactions on Image Processiong,2007,16(5):1220-1231.
[9]SIMON J C.A complemental approach to feature detection[C]//From Pixels to Features,Amsterdam:Elsevier Science,Netherlands,1989:229 -236.
[10]ZOU J J,YAN H.Skeletonization of ribbon-like shapes based on regularity and singularity analyses[J].IEEE Trans Syst Man Cybern,2001,31B(3):401-407.
[11]MORRISON P,ZOU J J.Triangle refinement in a constrained delaunay triangulation skeleton [J]. Pattern Recognition,2007,40(10):2754-2765.
[12]ZOU J J.Efficient skeletonization based on generalized discrete local symmetries[J].Optical Engineering,2006,45(7):1-7.
[13]DING C,HE X.-means clustering via principal component analysis[C]//Proc.of Int’l Conf.Machine Learning(ICML 2004),2004:225-232.
[14]VERBEEK J J,VLASSIS N,KOSE B.A k-segments algorithm for finding Principal Curves[J].Pattern Recognition Letters,2002,23:1009 -1017.
[15]STAN Z L.Markov random field modeling in computer vision[M].3rd.Berlin:Springer,2009.
