一种新的联合Turbo译码算法
2015-03-13茹玉年李建平
茹玉年,李建平
(中国传媒大学信息工程学院,北京 100024)
1 引言
1993年,一个新的前向纠错码Turbo码由Berrou,Glavieux和 Thitimajashima 提出[1]。Turbo码通过交织器和迭代译码使得译码性能非常接近香农限。但是Turbo码迭代译码算法计算量大、耗时长,因此,研究和探求一种性能良好而且高效率的Turbo译码算法具有重要的现实意义。
公开发表的Turbo码译码算法主要有三种,一种是Turbo码发明者 Berrou最早给出的改进型BCJR迭代算法,一般称为标准MAP(最大后验概率)算法[2];第二种是基于对数域的 BCJR迭代算法,即 Log-MAP算法[3];第三种是软输出 Viterbi算法(SOVA)算法[4]。
由于MAP算法译码复杂度高,SOVA算法译码性能差,所以算法中Log-MAP算法最为常用,它又分为线性近似 Log - MAP[5]、常数 Log - MAP[6]和Max-Log-MAP三种。这三种Log-MAP的简化算法通过不同的逼近函数,减少了Log-MAP中的指数和对数运算,因此译码效率比Log-MAP算法有了较大提高,但是带来了译码正确率的下降。
本文在研究以上Turbo码译码算法的基础上,结合实验观测现象,提出了一种新的联合译码算法,这种算法联合了常数Log-MAP译码算法和Log-MAP译码算法:译码初始阶段使用算法复杂度较低的常数译码算法;第二个阶段对常数译码算法达到最大迭代次数时依然未能满足停止迭代准则的数据帧使用译码性能更好但是复杂度更高的Log-MAP算法,以提高译码正确率。
新的联合译码方法的到了较好的性能和效率的折中。只增加了较少的计算量,使得常数 Log-MAP达到了近似Log-MAP的纠错性能。
2 Turbo译码介绍
迭代译码是Turbo码具有接近香农限的性能的一个重要因素,可以将其视为一种动态反馈系统。若要在Turbo码中使用其最优的译码方法最大似然译码,那么计算复杂度将非常的大难以实现,所以C.Berrou等人将其译码简化成次优译码算法(最大后验概率译码)的迭代过程。因此分量码译码必须采用SISO(soft-input soft-output)软信息输入输出算法,从而实现迭代译码过程中软信息在分量译码器之间的交换。图1是Turbo译码器的结构,Turbo码译码过程如下:第一个分量译码器SISO1产生软判决信息L1(u)和外部信息Le1(u),Le1(u)再经过交织器进行交织后传给第二个译码器,作为第二个译码器的先验信息。第二个分量译码器也产生软判决信息L2(u)和外部信息Le2(u)。Le2(u)通过解交织器解交织后传给SISO1,作为第一个译码器的先验信息。第一个译码器的先验信息初始值为0。如上所述外部信息在两个分量译码器之间传递来提高译码性能直到满足迭代停止准则,停止译码。最后再对L2(u)进行硬判决得到译码输出,即逐个对信息序列u=(u1,u2,…,uN)的 L(u)值进行判定,如公式(1)所示。
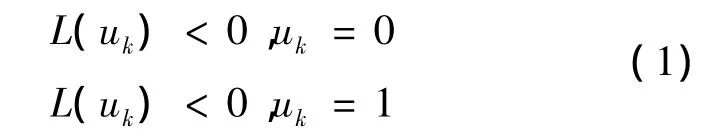
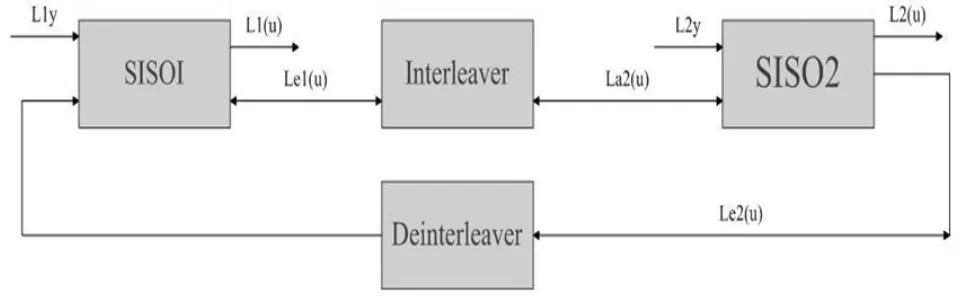
图1 Turbo码译码结构框图
Turbo码的分量译码器采用了逐比特最大后验概率似然比译码算法计算L(u)。下面将简要介绍Log-MAP算法以及其计算是重要的三个变量:前向度量、分支度量、后向度量的计算方法。
时刻k,计算接收比特uk的对数似然比(loglikelihood ratio)如公式(2)所示[1]。
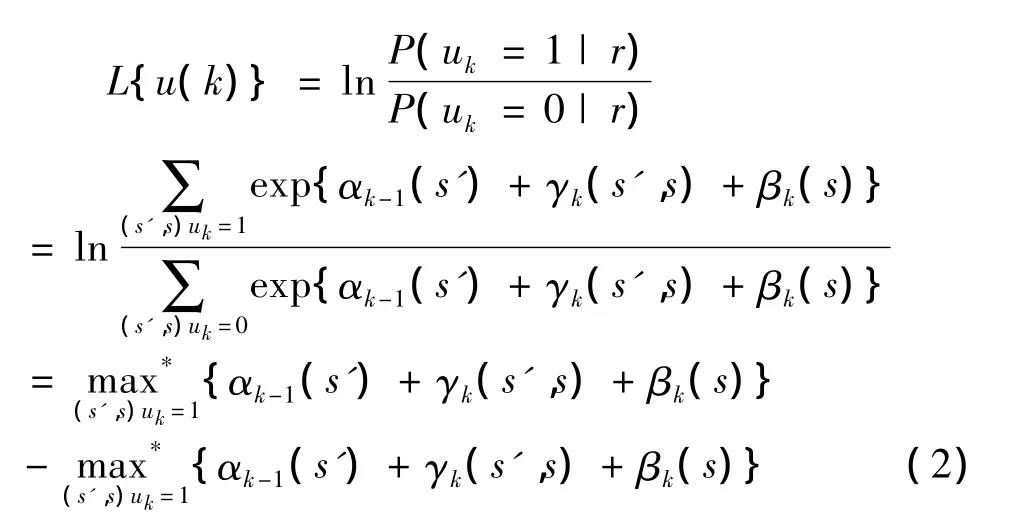
其中s’表示示存储器前—状态,s表示存储器下—状态。前向度量αk(s)和后向度量βk(s)可以通过下面的递推公式(3)(4)计算:
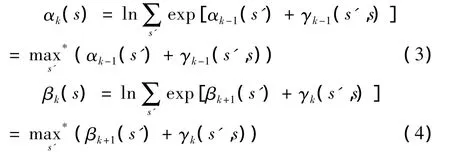
分支度量和编码器的状态转移概率以及信道的转移概率有关:
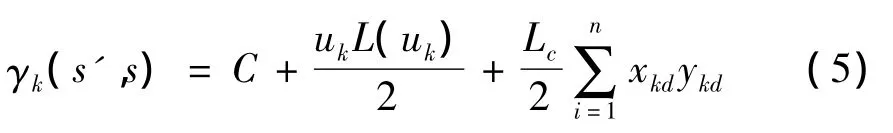
公式(5)中Lc是信道置信度,表示信道干扰下接收到的可信度,L(uk)是先验信息,C可以认为是一个常数,x是系统信息,y是校验信息。Max*是雅可比变换式。
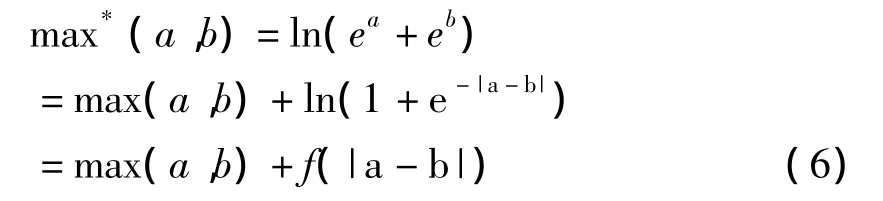
其中称f(|a-b|)为校正函数。
根据对校正函数的不同逼近方式的选择Log-MAP算法又可以简化成以下复杂度较低的算法[7]。
Max-Log-MAP算法,它忽略校正函数,所以仅仅做了求最大值运算。这样就使得计算复杂度有了大幅的减小,但是因为没有计算校正函数将会对其译码性能造成较大影响。常数Log-MAP算法:在区间(0,2)内校正函数的值取0.375,其他区域的值取零,这样明显减少了运算复杂度。线性Log-MAP算法:使用了线性函数对原来的校正函数进行了逼近,取了麦克劳林展开式的常数项和一次项。
Log-MAP算法的性能几乎接近香浓理论极限,但译码过程中需要计算校正函数,存在指数和对数运算,复杂度较高。Max-Log-MAP算法线性逼近、常数逼近Log-MAP等方法使用了复杂度较低的算法代替,这样使得计算复杂度大幅减小,但是也带来了性能上的损失,见表1。
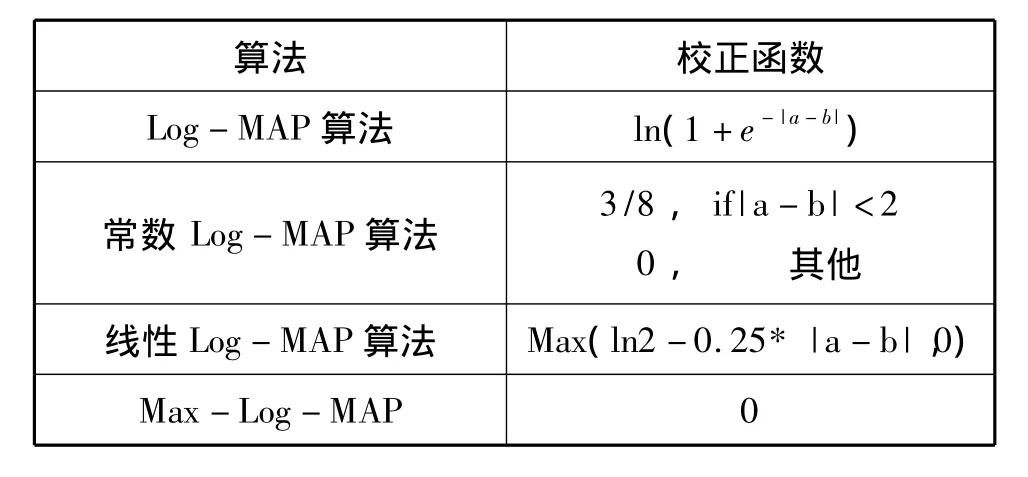
表1 不同译码算法使用的校正函数
Turbo码采用迭代译码来提高译码性能。通过观测译码性能、迭代次数和外部信息的收敛,可以将Turbo码的 BER性能曲线划分成三个典型的区域[8]。
(1)BER区域 I(BER≥10-2)
对应较低的信噪比;在这个区域误码率几乎不随迭代次数的增加而降低。对于这样的误比特率,一般的通信系统都是难以接受的。
(2)BER 区域 II(10-5≤BER ≤10-2),
对应中信噪比;在这个区域误码率随迭代次数的增加而降低,所以译码收敛到较低的误码率是可能的,但是收敛速度较慢。这个区间又被称作瀑布区(Waterfall Region)。在这个区域Turbo码的性能远远优于其它纠错码。
(3)BER区域 III(BER≤10-5)
对应较高的信噪比;在这个区域误码率随迭代次数的增加迅速降低,而软判决信息也能迅速收敛。一般迭代2-3次后趋于收敛,继续进行迭代性能无改善,这个区间也被称作错误平层区(BER Floor Region),可以认为是近似无差错的数据传输。
Turbo码译码对于绝大多数的帧信息,经过很少的几次迭代后,就会很快收敛到平稳状态,若采用预设一个迭代次数,会产生不必要的延时;若信息比特几次迭代收敛,但更多迭代时,似然比将会下降呈振荡形式,信息比特的译码将出现误码。因此译码过程中,在不降低译码性能情况下,运用迭代停止判决,可以降低译码的延时,并且防止由于振荡时所带来不必要的性能下降。所以在迭代译码时需要使用停止判决方法,来动态的控制迭代译码的次数,即在满足一定条件后就停止译码。这样既能减少译码所需的计算量,还能降低译码延时,同时还能保证译码的性能。下面介绍了一些典型的迭代停止准则。
2 迭代停止准则介绍
(1)交叉熵最小化CE(Cross Entropy)迭代停止准则[9]
两个分布之间的交叉熵是大于零的,当他们同分布时,交叉熵等于零。根据Turbo码迭代译码的特性可知:两个分量译码器的输出概率分布随着译码迭代次数的增加而趋近于相近。所以,两个分量译码器输出的交叉熵值将随着迭代次数的增加而趋近于零。所以可以使用交叉熵来表征译码的程度。
两个分量译码器的输出对数似然比的概率分布PDEC1(u|y)和PDEC2(u|y),则二者之间的交叉熵可以表示为:
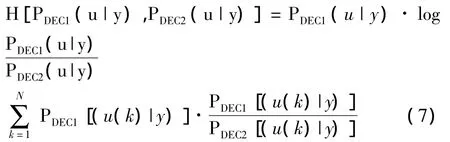
随着迭代次数的增加,PDEC1(u|y)和PDEC2(u|y)之间的交叉熵逐渐减小,当交叉熵达到最小值时,就实现了最佳译码,迭代即可停止。
(2)符号改变率SCR(Sign Change Ratio)迭代停止准则[10]
由于连续两次迭代进程里中各元素符号正负的改变个数直接与两次迭代输出间的交叉熵有关,由此由这种关系引出了另外一种停止准则:SCR准则。在迭代进程中,当改变个数满足u(i)≤(0.005-0.03)N时,停止迭代。所以门限值值越小,迭代次数越多,性能下降越小。SCR准则并不需要CE准则中的指数运算,也无需计算交叉熵,只需要储存每个外信息值的符号并作比较即可。可见SCR准则相对以CE准则只需更少的存储空间和计算复杂度。
(3)辅助硬判决法HDA(Hard Decision Aided)
HDA准则是一种比较简单的硬比特判决准则。通过观察迭代译码过程可以发现:迭代次数的增加,译码器输出的信息比特对数似然比值不断增大,成功译码的情况下数据帧中的每个比特的软值都达到收敛。但最终的译码判决都是根据每个比特似然比值的正负符号来进行判决的。它是基于在第k次与第k-1次迭代时硬判决相比较,又因为迭代译码收敛时,第k次与第k-1次迭代时的硬判决是一致的,所以在HDA准则中,我们只需存储前一次迭代中对信息比特的硬判决输出,然后用它与本次迭代中的信息比特的硬判决输出相比较,假若在整个数据帧中两次的硬判决输出完全相同,则停止迭代。
即在
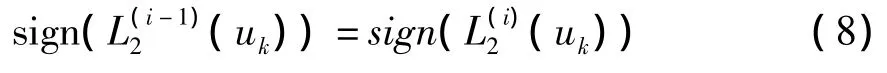
时停止迭代。
3 新的联合译码算法
经过大量的实验和观察发现:在中高信噪比(1db-3db)时,数据的软判决信息值会随着迭代次数的增加而呈现出如下的三种状况:
大量的数据帧只需要使用复杂度较低的常数Log-MAP译码算法,经过迭代之后,软判决信息的值就可以很快收敛且正负号固定不变,译码成功。
少量的数据帧在常数Log-MAP译码算法下经过多次迭代依然无法成功译码,软判决信息处于震荡状态很难收敛,正负号也不断地跳变。但是使用复杂度较高的Log-MAP算法经过有限次迭代就可以成功译码。
还有一少部分数据帧,在常数Log-MAP译码算法下经过多次迭代无法成功译码,即使使用Log-MAP算法依然无法成功译码。
本文根据上述实验观察,结合常数Log-MAP译码算法和Log-MAP算法和停止迭代准则,提出了一种新的联合译码算法:
步骤一:译码开始时使用复杂度较低的常数Log-MAP译码算法,使用停止判决准则HDA准则判决。
步骤二:对达到最大迭代次数时依然未能满足停止迭代准则的数据帧使用译码性能更好但是复杂度更高的Log-MAP算法。
4 仿真环境和结果
仿真环境:仿真是在AWGN信道上采用BPSK调制。交织器采用交织长度N=512的伪随机交织器,Turbo码的生成多项式为(7,5),码率为 1/3,HDA的最大迭代次数设定为10次,每个信噪比下用10000帧数据帧。
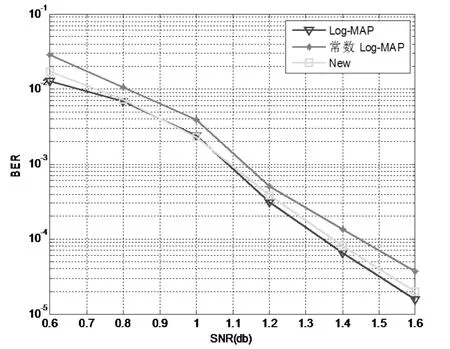
图2 三种译码算法的BER性能
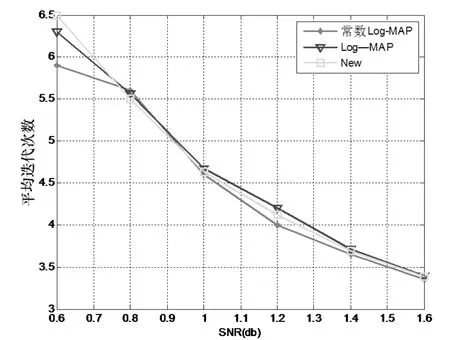
图3 三种译码算法平均迭代次数
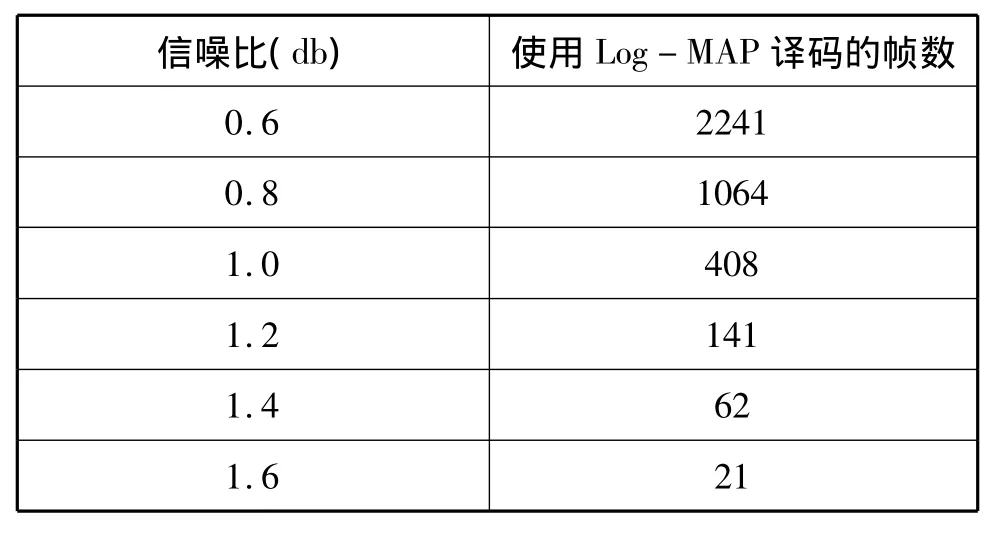
表2 不同信噪比下需使用Log-MAP译码的数据帧数
从图2、3可以得出:
在信噪比为0.6db到0.9db时,新的译码算法在译码性能上非常接近Log-MAP算法,好于常数Log-MAP算法。但是平均迭代次数大于常数法。
在信噪比为0.9db到1.6db时,新的译码算法不仅译码性能上非常接近Log-MAP算法,明显好于常数Log-MAP算法;而且平均迭代次数和常数Log-MAP算法几乎相同。可以达到几乎使用常数法的复杂度就可以达到Log-MAP的译码性能。
表2中为不同信噪比下需使用Log-MAP译码的数据帧数(实验中总的数据帧数为10000)。可见在瀑布区内,只需要对少量的数据帧进行性能更优的Log-MAP算法译码就可以有效的提高译码的性能,同时,相对于10000帧的数据,少量帧使用Log-MAP译码所带来的运算量可以忽略不计,所以新方法的平均迭代次数几乎和常数法的相同。
5 结论
本文提出了一种新的Turbo译码算法,并且将它和常数Log-MAP和Log-MAP算法和做了对比。经过仿真可以得到:
在BER 区域 I(0.6dB -0.9dB),即低信噪比下:新的方法不能很好地适应,主要是因为在低信噪比的条件下,常数法真确译码的数据帧少,数据还需经过Log-MAP算法继续译码,所以导致平均迭代次数高于常数法和Log-MAP译码算法。
在BER 区域 II(0.9dB-1.6dB),即在瀑布区,新的方法几乎与常数法的迭代次数相同。这也说明了,在瀑布区较多的数据帧只需要使用常数Log-MAP算法,就可以通过停止迭代准则在10次迭代之内成功译码,因此也只有少量的数据帧10次迭代之后任未成功译码,需要用译码准确度更高的Log-MAP算法继续译码,这样就可以将其性能提高到采用Log-MAP译码算法的性能。
总体来说,新的方法在瀑布区可以用几乎和常数法相同的复杂度来达到Log-MAP译码算法的精度。
新的译码算法还可使用不同的停止准则来判定哪些数据帧需要继续采用Log-MAP算法来进一步准确译码,因此也会产生不同的对性能和效率的折中,以适应不同的实际译码需求。
[1]Berrou C,Glavieux A.Near-optimum error- correcting coding and decoding:Turbo - codes[J].IEEE Trans Commun,1996,44:1261 -1271.
[2]Berrou C,Glavieux A,Thitimajstiima P.Near Shannon limit error-correcting coding and decoding[C].IEEE Int Conf on Communications 1993,Geneva,1993:1064 -1070.
[3]Obertson P,Villebrnn E,Hoecher P.A comparison of optimal and sub-optimal MAP decoding algorithms operation in the Log Domain[C].Int Conf Oil Communications 1995,Seattle,Gateway to Globalization,1995:1009 -1013.
[4]Francisco Blanquez- Casado,F Javier Martin -Vega,David Morales - Jimenez,et al.Adaptive SOVA for 3GPP -LTE Receivers[J].IEEE communications letters,2014,18(6).
[5]Cheng J F,Ottosson T.Linearly approximated Log- MAP algorithms for turbo decoding[C].IEEE Vehic Techn Conf(VTC),Tokyo,Japan,May 2000:2252-2256.
[6]Gross W J,Gulak P G.Simplified MAP algorithm suitable for implementation of turbo decoders[J].IEEE lectron Lett,1998,34(16):1577 -1578.
[7]Stylianos Papaharalabos,Takis Mathiopoulos P,Guido Masera,Maurizio Martina.On Optimal and Near-Optimal Turbo Decoding Using Generalized max*Operator[J].IEEE communication letters,2009,13(7).
[8]许可.Turbo均衡关键技术研究[D].长沙:国防科技大学,2011.
[9]Moher M.Decoding via cross entropy minimization[C].IEEE Globecom Conf,Houston,TX,Dec 1993:809-813.
[10]Shao R Y,Lin Shu,Fossorier M C.Two Simple Stopping Criterion for Turbo Decoding[J].IEEE Trans on Comnaunication,1999,47(8):1117 -1120.
[11]Yuejun Wei,Yuhang Yang,Lili Wei,Wen Chen.A New Parity-Check Stopping Criterion for Turbo Decoding[J].IEEE communications letters,2012,16(10).
