基于云平台的案例检索技术研究
2015-01-08熊聪聪庞朝辉王兰婷耿世洁
熊聪聪,庞朝辉,王兰婷,耿世洁
(天津科技大学计算机科学与信息工程学院,天津 300457)
云计算是一种基于互联网的计算方式.通过这种方式,共享的软硬件资源和信息可以按需求提供给计算机和其他设备[1].云计算是以并行计算为核心技术,同时使用多种计算资源解决计算问题的过程.通过并行计算集群完成数据的处理,再将处理的结果返回给用户,可以减少计算时间,提高系统的使用效率.云计算实现了高效的并行计算与海量数据的管理,无疑是现今大数据时代的热门产业.
目前,无论是政府部门还是企业都将视角转向了云计算领域.美国政府利用云计算技术建立了联邦政府网站,英国政府建立了国家级云计算平台(GCloud).在我国,北京、上海、深圳、杭州、无锡等城市开展了云计算服务创新发展试点示范工作,以促进产业信息化[2].对政府用户而言,云计算能够提高办公效率、节约信息化成本,政府的推动同时也可以促进云计算产业的跨越式发展;对企业用户而言,企业可以利用云计算整合其现有的数据中心,实现对已有IT 资源的充分利用,提高信息系统的效率和性能,加强经营决策的实时性.
CBR(case-based reasoning)技术[3]是通过重用或修改以前解决相似问题的方案来实现的.随着互联网的飞速发展,数据量日益剧增,对于CBR 的研究也要适应这一趋势.CBR 技术的一个典型的求解过程的基本步骤可以归纳为:案例检索(retrieve)、案例重用(reuse)、案例修正(revise)和案例保存(retain).CBR 解决问题的基本流程是利用目标案例的描述信息对案例库进行检索,得到与目标案例相类似的源案例,如果这个解答方案失败将对其进行调整,以获得一个能保存的成功案例,通过案例修正并保存可以获得一个新的源案例.在案例推理过程中,案例表示、案例检索和案例调整是案例推理研究的核心问题.由于CBR 技术对问题的解决是以经验知识为基础的,所以在应急事件处理、事件评估、医疗、企业管理等领域得到了广泛的应用.
常用的案例检索算法有知识引导法、神经网络法、归纳索引法和最近邻法.其中,最近邻法是比较常见的一种检索算法[4].但是,目前对于案例检索算法的研究还停留在单节点检索,随着案例库中案例的增多,不管采用哪种算法都不能高效地对案例进行检索.
本文将案例检索中的最近邻算法与云计算平台进行结合,使得在海量数据的案例库中,可并行地对案例库进行检索,从而提高检索速度.
1 案例检索算法的实现
1.1 案例的存储
1.1.1 案例的表示
CBR 技术中知识的表示偏于半结构化或者非结构化,其知识的表示是一个重要的问题.本文采用本体的知识表示方式,利用构建工具protege 进行本体的构建.采用本体对案例库进行建模,能够为不同领域知识及规则提供描述框架及规范,构建易于扩展的术语词典,实现知识的统一描述和组织.
1.1.2 HDFS 存储
HDFS(Hadoop distributed file system)[5]以容错性好、可伸缩性强、代码开源等优势倍受关注,成为当前主流分布式文件系统之一.HDFS 是被设计成可以在大规模廉价机器上运行的分布式文件系统,其设计思想源自GFS(Google file system).由于Hadoop 平台上从节点可以随时扩充,且案例存储在云平台上,即HDFS 文件系统上,使得案例库具有较好的横向扩展性,便于案例库的扩张与案例的存储.
1.2 案例的检索
1.2.1 案例检索算法
对于基于本体的表示方式,案例库中的案例包括案例的标识及各种属性.本文提出的案例检索算法是根据最近邻的思想计算案例间的属性值的相似度,进行相似匹配[6].
以案例X 和案例Y 为例,它们的属性分别为x1,x2,…,xm和y1,y2,…,ym.根据各属性权值采用式(1)计算X 与Y 的相似度.

式中:ωi为相应属性的权值,根据属性对案例的影响大小确定;sim(xi,yi)是案例X 的第i 个属性与相应Y的第i 个属性的相似度.
根据案例的属性类型不同,相应的相似度计算方法有一定的区别:
对于确定的属性值(例如在农业生产中的温度,不同的温度对农作物产生不同的影响),不同属性间的相似度可由式(2)计算.
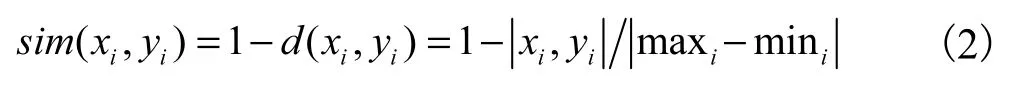
式中:d(xi,yi)是属性值间的相对距离;maxi、mini是属性i 的最大值和最小值.
对于不确定属性,即类型为布尔型的属性(例如天气是否下雨等),可由式(3)计算不同属性间的相似度.

上述是一种基于最近邻算法的案例匹配算法,当案例库不大时可以及时地检索出与所给问题相似的案例的解决办法.但是,当案例不断扩充,案例库增加至几百GB 甚至TB 以上时,这种做法就显得力所不及了.因此,考虑在云平台上对算法进行改进,使得对海量数据的案例库检索仍然可以快速地返回结果.
1.2.2 算法改进
开源云计算平台Hadoop 中的MapReduce 是一个软件框架,基于它写出来的应用程序能够运行在由上千台商用服务器组成的大型集群上,并以一种可靠容错的方式并行处理TB 级别的数据集.MapReduce技术[7]最早由Google 公司提出,是一种通过在大规模的廉价服务器集群上进行大数据处理的技术.MapReduce 是一种并行编程模型,运行在分布式文件系统之上,通过map 和reduce 操作分别进行数据的处理.MapReduce 模型简单,支持系统的扩展和高并发,是现阶段应用最多的大数据处理技术.
MapReduce 在工作时由1 个主节点对集群进行控制,同时由n 个从节点进行实际任务的处理.在案例检索时,先将同一地理位置上的数据进行map 操作,并对中间结果进行combine 操作,将中间结果存储在本地的服务器上,这样就节省了数据传输的耗时.然后,Reduce 节点根据Master 节点提供的地理信息提取中间结果,再对这些中间结果提取进行reduce 操作,完成数据的分析工作,获取数据中的知识,帮助完成决策的生成.MapReduce 的工作流程[8]见图1.

图1 MapReduce的工作流程Fig.1 Process of MapReduce
利用MapReduce 技术改进的案例检索算法,其工作流程如下:
(1)对案例库中的案例进行分片;
(2)Map 过程.每个从节点对本地案例库中的案例进行分片处理.输入的键值对为(Case_ID,Case_Attri),输出的键值对为(Case_ID,Case_Attri);
(3)Combine 过程,即案例间相似度的计算过程.输入的键值对就是map 过程的输出,输出的键值对是(Case_ID,Case_Sim);
(4)Reduce 过程.根据案例的相似度从高到低对案例库中的案例进行排序.输入的键值对为Combine过程的输出,输出的键值对是(Case_Sim,Case_ID);
(5)最后提取出相似性最高的案例,为后续的案例的生成提供方案.
2 实 验
为验证在云平台上进行案例检索的可行性,分别在不同节点数的集群上进行实验.
2.1 实验环境
采用8 台服务器,其中1 台服务器作为主节点,7 台作为从节点.每台服务器的软硬件环境均相同.服务器配置见表1.

表1 集群节点配置Tab.1 Configurations of each node
实验中将8 台服务器的存储空间利用Hadoop的HDFS 进行资源的虚拟,构建成一个大容量的虚拟资源池,将实验数据存储在虚拟资源池中.实验时,分别用不同节点数的服务器对资源池中的数据进行检索计算.
2.2 实验结果
在实验中随机生成2 个简单的数据集,数据量分别为638,GB 和1.31,TB,存储于资源池中.数据集的样式见图2.

图2 部分实验数据集Fig.2 Partial experimental data set
两数据集分别在不同集群节点数量时的案例检索实验结果见图3.

图3 集群节点数量和数据量对案例检索时间的影响Fig.3 Effect of node number and data size on CBR
由图3 可以看出:集群对638,GB 的数据进行检索时,8 个节点比单节点要快50,s;对1.31,TB 的数据量进行检索时,8 个节点比单节点要快71,s.实验表明:集群节点数量对于案例的检索时间有一定的影响,对大数据量的数据进行检索,随着节点的增加,案例的检索速度会加快;同时,需要处理的数据量越大,这种效果表现的越明显.
3 结语
本文提出一种基于云平台上的案例检索技术.在分析现有最近邻法基础上,采用MapReduce 思想对算法进行改进,使得案例的检索过程可以在不同的服务器上并行进行,从而提高检索速度.由于开源的Hadoop 平台将案例库存储在HDFS 文件系统上,减少不同平台间的差异,弱化了物理位置对系统的影响,可以实现资源的均衡调度.同时,由于案例库会在不同的服务器上进行备份,也保证了数据的安全性.
实验表明:对大数据量的数据进行检索时,本文提出的基于云平台的案例检索技术可以明显提高检索速度,随着节点的增加,案例的检索速度加快,且需处理的数据量越大,这种效果表现的越明显.
[1]刘枫.基于Google 云计算的Web 应用与开发[J].电脑开发与应用,2011(5):29-31,34.
[2]罗军舟,金嘉晖,宋爱波,等.云计算:体系架构与关键技术[J].通信学报,2011,32(7):3-21.
[3]倪志伟,李建洋,李锋刚,等.案例决策技术及案例决策支持系统研究综述[J].计算机科学,2009,36(11):18-23,42.
[4]侯玉梅,许成媛.基于案例推理法研究综述[J].燕山大学学报:哲学社会科学版,2011,12(4):102-108.
[5]Venner J.Pro Hadoop[M].New York:Apress,2009.
[6]杨立,左春,王裕国.基于语义距离的K-最近邻分类方法[J].软件学报,2005,16(12):2054-2062.
[7]Dean J,Ghemawat S.MapReduce:simplified data processing on large clusters[J].Communications of the ACM,2008,51(1):107-113.
[8]李成华,张新访,金海,等.MapReduce:新型的分布式并行计算编程模型[J].计算机工程与科学,2011,33(3):129-135.
