基于全文索引与余弦公式医学文本相似性分析
2014-08-07谢翠萍陈家益白金山
谢翠萍,陈家益,白金山
基于全文索引与余弦公式医学文本相似性分析
谢翠萍,陈家益,白金山
医学文本相似性问题是医学文本挖掘中的重要内容,如何能够快速计算出大数据量下的医学文本的相似性情况是医学文本相似性计算的重点。针对基于传统余弦公式医学文本相似性分析算法在性能上的缺陷,提出了一种基于全文索引技术与余弦公式医学文本相似性分析算法,对医学文本相似性进行分析。采用全文索引技术对医学文本数据相关关键词进行索引,并根据若干关键词在索引中检索出部分数据,从而减少计算复杂度,提高效率。实验表明,该方法比基于传统余弦公式医学文本相似性分析算法具有更优的性能。
医学文本相似性;余弦公式;全文索引;文本挖掘;向量空间模型
0 引言
随着信息时代的发展,各个行业都将产生大量的各种各样的数据。其中文本数据是较重要的一种数据。同样,随着医学的不断进步,各种医学文本数据也大量充斥在信息流中。如何快速准确地分析出这些文本数据的规律,获取有价值的信息是文本数据处理的一个难点问题。文本挖掘主要是指从相对较大文本数据中挖掘出一些有价值的信息和内容。
医学文本挖掘主要是指对医学相关数据的挖掘和分析,从而得出一些有价值的医学信息。目前国内外众多学者对医学文本挖掘相关知识做了一定的研究[1-6]。王浩畅等研究和概括了生物医学文本挖掘技术的研究与进展[1]。郑强等研究了生物医学命名实体识别的研究与进展[2]。顾钧等提出一种新的文本聚类算法,结合引文信息的生物医学文本聚类研究[5]。医学文本相似性是医学文本挖掘的一种,主要是通过比较医学文本数据之间的相似性,从而能够确定各个医学文本之间的相似程度。目前主要用来对医学文本数据进行相似搜索,对相似信息过滤等。赵国光对医学文献相似性进行了相关研究,并利用后缀树和向量空间模型计算相似度[7]。吴飞珍等通过对基因相似性的研究,一种新的基因注释语义相似度计算方法[8]。传统的医学文本相似性分析算法一般是基于传统余弦公式,性能较低,本文提出一种基于全文索引技术与余弦公式的医学文本相似性分析算法,对医学文本相似性进行分析。
1基于传统余弦公式医学文本相似性分析
下述过程都是在文本分词之后进行的,因为目前文本分词技术比较成熟,这里也不是本文的重点。
1.1向量空间模型
向量间空模型[9](VSM:Vector Space Model) 由Salton等人于20世纪70年代提出,并成功地应用于著名的SMART文本检索系统。在这个模型中,文本空间被看作是由词语向量组成的向量空间。每个文本d将被表示为一个文本向量,其中是文本分词后的各个词语,是中的权值,这个权值通常在文本是各个词语的词频或者词频的函数。这样文本数据就转换为文本向量空间,其中代表文档数,代表词语个数。行表示文档,列表示文档中出现的词。
1.2 余弦公式
文本相似性分析主要是希望能够在大量文本中快速找到内容相似的文章。故在相似性分析过程中,待计算文本数据需要依次与被比较文本进行比较。根据1.1节中的描述可知,文本数据已转换为文本向量空间了。计算文本之间的距离就转换为计算文本向量空间的距离。计算向量空间距离的方法比较多,例如欧式距离法,皮尔逊相关系统法以及余弦公式。本文采用余弦公式[10]来计算相似度,即公式:

1.3 算法流程
步骤3:采用余弦公式计算待计算文本数据d与待比较文本数据D的相似度大小;
步骤4:根据所设的相似度阈值s将步骤3计算出的相似度大小大于阈值的文本数据显示出来;
步骤6:按照步骤2至步骤5将计算出其它文本数据的相似文本数据。
2 基于全文索引技术与余弦公式医学文本相似性分析
采用传统余弦公式的医学文本相似性分析在算法思路上比较清晰,简单,实现上也很简单。但是,该算法在性能上比较差,因为对每篇文本数据,算法均需要比较待计算文本与待比较文本的数据,比较次数会比较多。特别是在文本数据量比较大时更是如此,算法的性能会使算法的实用价值大打折扣。为此,本文提出一种基于全文索引技术与余弦公式相结合的文本相似性计算方法。
2.1全文索引技术
全文索引技术[11,12]是目前搜索引擎中比较关键的一项技术。试想在大小的文件中搜索一个词,可能需要几秒,在的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
原理主要是先定义一个词库,然后在文章中查找每个词出现的频率和位置,并将这样的频率和相关位置信息按照一定的顺序进行归纳,这样就相当于对文件建立了一个以词库为目录的索引,在这样的情况下查找词语的话就可以比较快的了。
在全文索引技术中,在处理英文文档的时候显然这样的方式是非常好的,因为英文自然的被空格分成若干词,只要我们有足够大的词汇库就能很好的处理。但是亚洲文字因为没有空格作为断词标志,所以就很难判断一个词,而且人们使用的词汇在不断的变化,而维护一个可扩展的词汇库的成本是很高的,所以问题出现了。
解决出现这样的问题使“分词”成为全文索引的关键技术。目前有两种基本的方法:
词库法使用词库中的词作为切分的标准,这样也出现了词库跟不上词汇发展的问题,除非你维护词库。
实际上现在很多著名的搜索引擎都使用了多种分词的办法,比如“正向最大匹配”+“逆向最大匹配”,基于统计学的新词识别、自动维护词库等技术,但是,显然这样的技术还没有做到完美。
本文主要采用的是lucene索引技术,Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础,建立起完整的全文检索引擎。
2.2 算法流程
步骤7:按照步骤2至步骤5将计算出其它文本数据的相似文本数据。
3实验分析
本文医学文本数据来源于相关医学论文数据。数据处理中,选取医学文本数据中的标题和内容分别分词处理,并将标题的权重设置大一些,因为标题显然比内容重要一点。在计算分词后词语词频时,为了使计算保持在一个数量级上,对数据进行归一化处理,即通过数据归一化处理将数据映射到[0,1]。便于比较和处理方便,本文依次选择1000篇、2000篇、5000篇、10000篇文本数据作为测试数据,分别采用基于传统余弦公式医学文本相似性分析算法和基于全文索引技术与余弦公式医学文本相似性分析算法对它们进行计算和分析。其计算结果如表1所示:
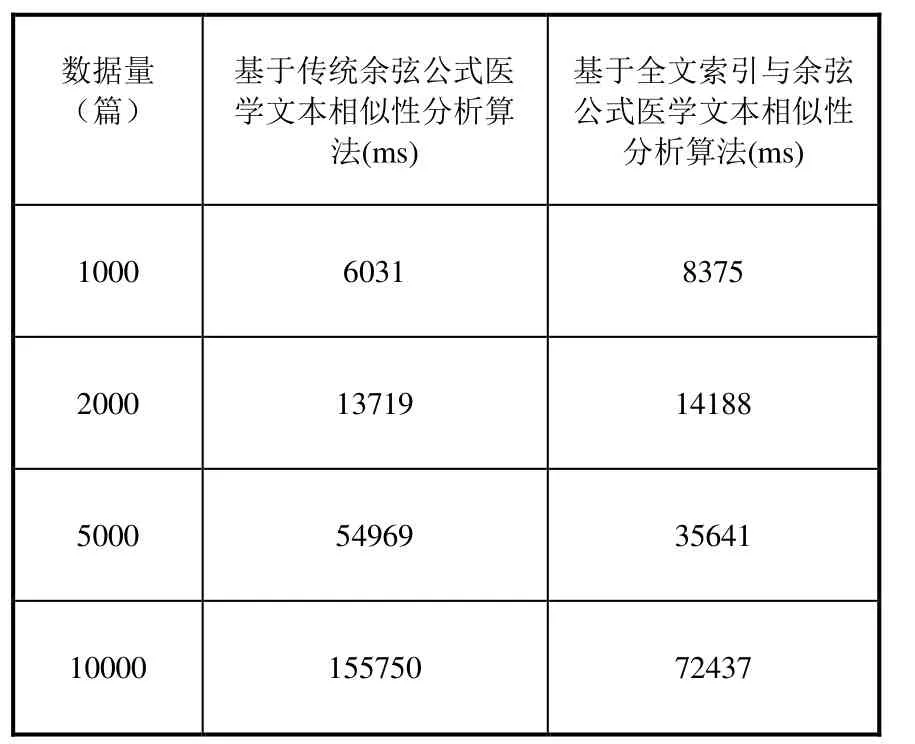
表1 算法效率比较表
从表1中可以看出,基于传统余弦公式医学文本相似性分析算法在1000篇、2000篇等小数据量时算法速度是可以的,因为需要匹配的数据量较小。但是,在数据量相对较大时,比如5000篇、10000篇甚至更大量的数据,算法则明显比基于全文索引技术与余弦公式医学文本相似性分析算法要慢很多了。数据量越大,相对于传统算法而言,本文提出的算法性能优势越明显。
4 总结
采用传统余弦公式对医学文本数据进行相似性分析,算法比较简单,思路也比较清晰、便于理解。但是在数据量较大情况下,算法的运行效率比较低,难以满足实际需求。针对该问题,本文采用全文索引技术与余弦公式结合的方式对医学文本数据进行相似性分析。该算法采用全文索引技术对医学文本数据相关关键词进行索引,这样算法在相似性计算时,可以先根据若干关键词在索引中检索出部分数据。这样能够大大减少算法计算的量,从而提高效率。实验表明,该方法比基于传统余弦公式医学文本相似性分析算法运算效率更高,性能更优。
[1] 王浩畅,赵铁军.生物医学文本挖掘技术的研究与进展[J].中文信息学报,2008,22(3):89-97.
[2] 郑强, 刘齐军, 王正华, 朱云平. 生物医学命名实体识别的研究与进展[J].计算机应用研究,2010,27(3):811-832.
[3] 豆增发,高琳.利用膜粒子群优化和信息熵的医学文本特征选择[J].西安交通大学学报,2012,4:45-51.
[4] 米晓芳,秦 洋,王立宏,宋宜斌.基于潜在语义差异的医学网页聚类[J].计算机工程,2008,34(19):64-66.
[5] 顾钧,郑晓东,张连明.结合引文信息的生物医学文本聚类研究[J].计算机应用与软件,2012,29(10):5-7.
[6] XUEZHONG ZHOU, YONGHONG PENG,BAOYAN LOU.Text mining for traditional Chinese medical knowledge discovery: A survey[J].Journal of Biomedical Informatics,2010,43 : 650–660.
[7] 赵国光.医学文献相似性研究[D].首都师范大学,2009.
[8] 吴飞珍,马文丽,王旺迪,陈启龙,郑文岭.一种新的基因注释语义相似度计算方法[J].生物信息学,2010,1:23-29.
[9] 郝文宁,冯波,陈刚,靳大尉,赵水宁.基于领域本体的文档向量空间模型构建[J].计算机应用研究,2013,3:764-767.
[10] 郭庆琳,李艳梅,唐琦.基于VSM 的文本相似度计算的研究[J].计算机应用研究,2008,25(11):3256-3258.
[11] 苏潭英,郭宪勇,金鑫.一种基于 Lucene 的中文全文检索系统[J].计 算 机 工 程,2007,33(23):94-96.
[12] 刘小珠, 彭智勇.全文索引技术时空效率分析[J].软件学报,2009,20(7):1768-178.4.
Similarity Analysis of Medical Text Based on Full-text Indexing Technology and Cosine Formul
Xie Cuiping, Chen Jiayi, Bai Jinshan
( School of Information Engineering, Guangdong Medical College, Dongguan 523808, China )
Medical text similarity is an important content of medical text mining, how to quickly calculate the similarity from a large number of medical text data is a key problem of medical text similarity calculation.For medical text similarity analysis based on traditional cosine formula algorithm on the performance of defects, this paper proposes a algorithm of medical text similarity analysis which based on full-text index and cosine formula, It can be analyzed in the similarity of medical text. It uses full-text indexing technology to index medical text data relevant keywords, and according to the number of keywords retrieve part of the data from the index , so as to reduce the computational complexity and improve efficiency. Experiments show that, the method of similarity analysis algorithm has better performance than the traditional medical text based on the cosine formula.
Medical Text Similarity;Cosine Formula;Full-text Indexing;Text Mining;Vector Space Model
TP393
A
1007-757X(2014)01-0025-03
2013.12.16)
湛江市科技计划项目(编号:2012C3102009)广东医学院青年基金项目(编号:XQ1353)
谢翠萍(1980-),女,湖南省安仁人,广东医学院讲师,硕士,研究方向:数据库、医院信息系统,东莞,523808陈家益(1983-),男,广东省湛江市人,广东医学院,讲师,硕士,研究方向:计算机网络与通信,东莞,523808白金山(1972-),男,黑龙江齐齐哈尔人,广东医学院,讲师,博士,研究方向:并发模型检,东莞,523808
