基于用户兴趣度的PageRank改进算法
2014-06-27黄贤英陈红阳
黄贤英,陈红阳
(重庆理工大学计算机科学与工程学院,重庆 400054)
基于用户兴趣度的PageRank改进算法
黄贤英,陈红阳
(重庆理工大学计算机科学与工程学院,重庆 400054)
传统的PageRank算法容易导致主题漂移、偏重旧网页、用户对搜索结果的主观选择被忽略等问题。针对PageRank算法存在的上述缺陷,提出了一种基于用户兴趣度的网页排序算法——PRUI算法。该算法主要从网页自身的客观特性和用户兴趣的主观特性两方面对网页的PR值进行重新估算,并依据估算后的网页PR值对网页做重排序。相比传统的PageRank算法,改进的PRUI算法进一步提高了系统检索的准确率和首页命中率。
搜索引擎;PageRank算法;主题漂移;用户兴趣度;页面排序
目前,搜索引擎是人们获取网络信息的主要工具。面对互联网信息爆炸式的增长和日益复杂的用户信息需求[1],基于关键字查询的传统网页排序算法已经愈加显露出自身的不足。如何快速、高效、准确地从信息海洋中找到符合用户需求的信息资源是搜索引擎网页排序算法亟待解决的问题[2]。
针对PageRank算法中存在的主题漂移问题,王春花等[3]提出了一种改进的非平均权值传递PageRank算法。该算法考虑了源网页与其出链网页之间的相关度,对网页的权值采取非平均分配方式;缺点是未能考虑目标网页与用户查询词的主题相关度。王德广等[4]考虑网页的时间因素,认为网页发布时间和被检索时间之差与其PR值呈负相关,引入了时间函数,使内容较新颖且对用户具有吸引力的新网页PR值得到提高。郭庆宝等[5]提出了融合反馈信息和内容相关度的PageR-ank改进算法,考虑了用户对搜索结果页面的反馈信息,但仅将用户对网页的点击量作为衡量指标,未对用户的反馈行为进行深入分析以及探究用户对网页的兴趣度。黄华东[6]提出了基于用户模型的个性化搜索研究,引入了用户兴趣模型的概念,从而为网页排序算法的改进提供了一种新的思路——构建完善的用户兴趣模型,并将其融入到搜索引擎的网页排序中;算法的不足之处是用户兴趣模型的构建并不完善。
本文从网页自身的客观特性和用户兴趣的主观特性两个角度出发,提出了一种改进的网页排序算法——PRUI算法(PageRank algorithm based on user interest degree)。首先针对PageRank算法存在的主题漂移、偏重旧网页问题,引入了源网页与目标网页、用户查询词之间的主题相关度,并结合网页的驻留时间对PR值重新估算;其次从用户的角度出发,构建用户兴趣模型,重新定义了用户对页面的兴趣度。估算后的PR值和用户兴趣度两部分加权得到页面最终的PR值。
1 传统PageRank算法
PageRank算法[7-8]基于万维网超链接关系对网页的质量进行评估,进而实现网页排序。该算法采用随机游走模型来模拟网络用户的浏览行为,估算每个页面的被访问概率。随机游走模型假设用户主要使用两种方式访问网页:其一,用户从给定的页面集合中随机挑选某页面进行访问;其二,用户根据初始页面中存在的超链接递归跟踪访问感兴趣的页面。因此,每个页面的被访问概率(简称网页的PR值)可通过式(1)计算获得。
式(1)中:PR(A)表示目标网页A的PR值,用以表征网页的重要程度;λ是介于0和1之间的衰减系数(一般取值为0.85左右);Ti表示链向目标网页A的入链网页(1≤i≤n);Count(Ti)表示网页Ti的出链网页总数。
2 改进的PRUI算法
PRUI算法主要从以下两个方面着手对网页PR值的计算公式进行改进:一是基于网页内容和链接结构的客观特性,解决PageRank算法存在的主题漂移、偏重旧网页问题;二是基于用户兴趣度的主观特性,通过分析用户与系统交互过程中的浏览行为,构建完善的用户兴趣度;综合考虑网页自身的特性和用户的主观选择行为,为用户提供更为合理的检索结果。
2.1 基于网页内容和链接结构的客观特性改进PageRank算法
1)主题漂移。将网页权值平均分配给出链网页忽略了网页与其出链网页及查询词间的相关度,以致某些网页凭借较高的PR值在搜索结果中排在靠前的位置,却与用户查询主题相关度甚小。以往改进的PageRank算法在解决主题漂移问题时,未能综合考虑网页内容与用户查询词、其出链网页之间的主题相关度对网页PR值的影响[3]。实际上,这两种主题相关度均与该网页所获得的PR值呈正相关。假设目标页面为A,链向它的源网页集合T={T1,T2,…,Tn},用户提交给系统的查询词为Q,将页面A、用户查询词Q及源网页Ti(1≤i≤n)分别向量化后可表示为:A=(a1,a2,…,an),Q=(q1,q2,…,qn),Ti=(Ti1,Ti2,…,Tin)。采用余弦相似度度量页面A与用户查询词Q之间的相似度,如式(2)所示。
源网页Ti和目标页面A之间的相似度为

综合式(2)、(3)改进PR值计算公式,如式(4)所示。
2)偏重旧网页。新旧网页被其他网页链向的机会、所获的权值及在结果页面中所排位置正比于其在网络上存在的时间,以致出现旧网页上浮、新网页下沉的现象,从而使用户可能感兴趣的新网页排在搜索结果尾部。因此,为降低网页在网络上的时间对其PR值的影响,引入时间衰减因子(网页存在时间与其PR值呈反比例关系)改进PR值计算公式,具体如式(5)所示。
2.2 基于用户兴趣度的主观特性改进PageRank算法
融入用户对搜索结果的主观选择能较为全面、准确地刻画用户对网页的兴趣度,从而更好地衡量网页的质量,提高网页的排序效果[9]。本算法主要通过以下几个方面对用户兴趣度进行描述与衡量。
1)用户搜索历史记录。囊括了用户对网页的各种浏览行为,在一定程度上反映了用户的兴趣偏好。通过分析用户以往搜索的关键词、统计各个关键词被搜索的次数,可将用户的历史兴趣[10]用向量表示为HInterest=(HIw1,HIw2,…,HIwn),当前网页A经过向量化后表示为A=(a1,a2,…,an)。因此,基于用户历史兴趣衡量用户对当前网页的兴趣度,如式(6)所示。
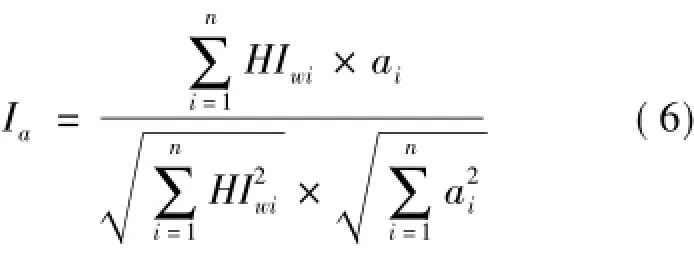
其中:ai为网页A的第i个特征词的权重;HIwi为用户搜索第i个关键词的次数。
2)用户浏览网页的时间。一般情况下,如果用户对某一网页内容感兴趣,会点击、浏览并在页面中停留一定时间。在特定的时间范围内,用户的兴趣浓度较高;超出此范围,用户的兴趣度则大幅衰减[11]。通过观察用户浏览网页的时间与其对网页兴趣度的关系,构建正态分布模型,并基于页面浏览时间改进用户兴趣度,如式(7)所示。
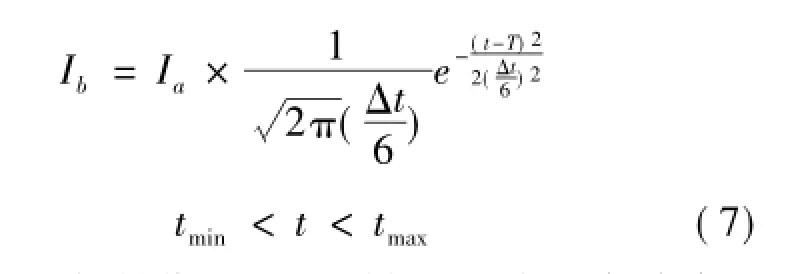
其中:t为用户浏览网页的时间,服从正态分布N (T,(Δt/6)2);T为正常情况下用户浏览一个页面所需的平均时间;Δt为特定时间范围,Δt= tmax-tmin。
3)同类用户的协同过滤。协同过滤推荐[12]是指通过分析用户兴趣偏好,寻找与其具有类似兴趣的用户,然后根据同类用户对某一信息的兴趣度,推测该用户对此信息也具有同样的兴趣度,并推荐符合用户需求的信息。
基于上述思想,提出了一种同类用户的协同过滤方法。当前用户对某网页的兴趣度可用群体用户的兴趣度量,即借助同类用户的兴趣偏好过滤无关信息。同类用户兴趣用其历史兴趣向量表示为CInterest=(CIw1,CIw2,…,CIwn),当前网页A向量化为A=(a1,a2,…,an),那么通过协同过滤后,用户对当前网页的兴趣度如式(8)所示。
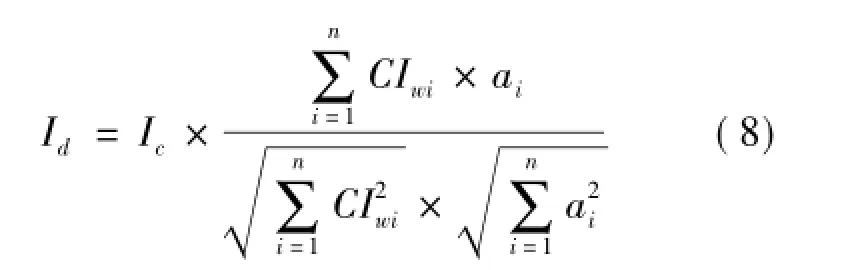
其中:ai为网页A的第i个特征词的权重;CIwi为用户搜索第i个关键词的次数。
2.3 利用改进的PRUI算法计算网页的PR值
综上所述,一个网页的质量融合了网页自身的客观特性与用户兴趣度的主观特性,网页最终的PR值用式(9)表示。
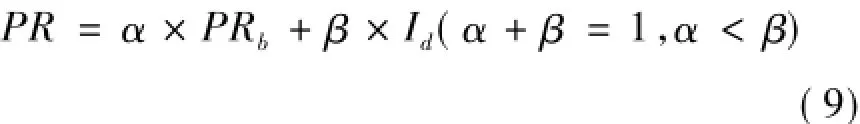
其中:α与β为控制影响网页重要性的客观因素与主观因素的权重参数。
3 实验结果及分析
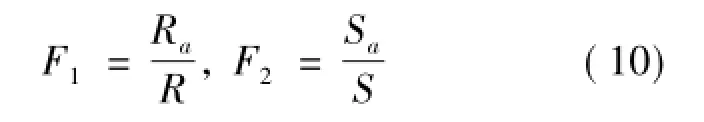
其中:F1为查准率;Ra为系统根据用户查询词检索出的相关文档总数;R为系统检索出的文档总数;F2为首页命中率;Sa为在首页检索结果中满足用户需求的相关文档总数;S为首页检索结果中文档的总数。
本文使用Java语言在Galago开源平台上集成PRUI算法,并采用开源的Heritrix爬虫框架将搜狐主页作为爬取时的起始网页,以增量式爬取方式对网页进行动态抓取。网页的抓取数量设定为50万,同时随机选取来自不同专业的20名学生作为测试人员,每位测试人员代表一种查询请求。各种查询请求如表1所示。
本文采用查准率和首页命中率作为系统检索性能的衡量指标。具体计算如式(10)所示。

表1 测试人员查询请求表
为了确定式(9)中α与β的取值,分别针对α+β=1,且β>α>0的4种可能取值情况(精度为0.1,考虑到网页的PR值计算受用户兴趣度的主观影响因素较大,选取β>α)测试其在PRUI算法下的查询准确率。当α与β分别为0.4和0.6时,查询准确率取得最大值0.75,最终确定α与β的取值分别为0.4和0.6。
根据表1中每个用户的查询请求进行检索,选取前10页结果页面进行统计,其中每一页包含10条记录。比较每个查询请求在改进的PRUI与传统PageRank算法下的检索效果(如图1所示)。
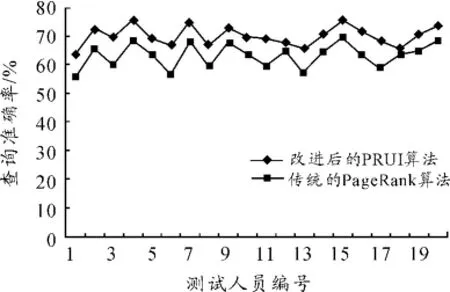
图1 传统的PageRank算法与改进的PRUI算法准确率比较
观察图1中数据的变化趋势可以发现:在PRUI算法下,用户查询的准确率有了进一步提高,说明融入用户对网页的兴趣度有效改善了网页的排序效果,可为用户提供更好的检索体验以满足用户个性化的检索请求。
系统采用2种算法针对20种不同的查询请求返回对应的相关结果集,从中选取首页10条记录,统计首页命中率,对比结果如图2所示。
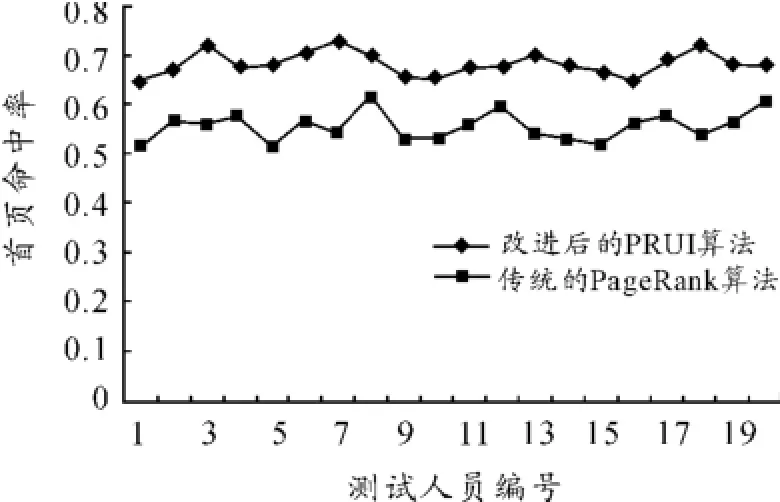
图22 种不同算法下的首页命中率
观察图2中的数据可知:在2种不同算法下,针对不同的用户查询请求,其首页命中率有着明显的差异。采用PRUI算法,首页命中率相对有所提高,稳定在0.68附近。这间接表明满足用户需求的网页在搜索结果中排在了相对靠前的位置。
本文引入页面与查询词及出链网页的相关度、网页存在的时间因素,解决了主题漂移和偏重旧网页的问题。用户对检索结果的满意度某种程度上还取决于其主观选择行为,因此本文提出的算法融入用户兴趣度,考虑了用户的主观感受。最后,结合两者有效改善了网页的排序效果,使得满足用户需求的网页尽量排在靠前的位置。
4 结束语
本文主要针对传统PageRank算法存在的主题漂移、偏重旧网页以及用户对搜索结果的主观选择被忽略问题,提出了一种改进的PRUI算法。该算法从网页内容和链接结构角度出发解决主题漂移、偏重旧网页问题;引入用户兴趣度以解决用户对搜索结果的主观选择被忽略问题,最后综合二者对网页的PR值进行重新估算。实验结果表明:PRUI算法提高了系统检索的准确率、改善了用户的检索体验。
算法存在的不足包括:基于向量空间模型表示网页文本与用户查询词,采用余弦相似度衡量二者之间的相似度时,未挖掘出文本内容蕴含的深层含义,相似性的准确度量需进一步改善;在本算法实施过程中,需要搜集、存储及处理与用户兴趣度相关的数据,这在一定程度上增加了算法的时间复杂度。在今后的研究工作中,需不断优化算法,提高搜索匹配的范围与准确度,从而将最符合用户需求的页面排在搜索结果的最前端。例如,可对语义相似度模型[13]进行深入研究,以精确衡量网页文本与查询词间的相似度。
[1]Luiz C M,Miranda,Carlos A S,et al.Trends and cycles of the internet evolution and worldwide impacts[J].Technological Forecasting and Social Change,2012,79 (4):744-765.
[2]Rashid Ali,Sufyan Beg M M.An overview of Web search evaluation methods[J].Computers and Electrical Engineering,2011:835-848.
[3]王春花,朱俊平.改进的非平均传递权值PageRank算法[J].计算机工程与设计,2010,31(10):216-217.
[4]王德广,周志刚,梁旭.PageRank算法的分析及其改进[J].计算机工程,2010(11):291-293.
[5]郭庆宝,贾代平.融合反馈信息与内容相关度的PageRank改进算法[J].计算机工程与设计,2011,32 (12):4072-4074.
[6]黄华东.基于用户模型的个性化搜索研究[D].上海:华东理工大学,2013.
[7]贺志明,王丽宏,张刚,等.一种抵抗链接作弊的PageRank改进算法[J].中文信息学报,2012,26(5):102-106.
[8]谢月.网页排序中PageRank算法和HITS算法的研究[D].成都:电子科技大学,2012.
[9]Ling ZHENG,Shuo CUI,Dong YUE,et al.User Interest ModelingBased on Browsing Behavior[C]//2010 3rd International Conference on Ad-vanced Computer Theory and Engineering(ICACTE).Chengdu:[s.n.],2010:455-458.
[10]王宇.基于搜索历史的用户兴趣建模[D].上海:复旦大学,2011.
[11]南智敏.基于网页兴趣度的用户兴趣模型体系研究[D].上海:复旦大学,2012.
[12]吴月萍,郑建国.协同过滤推荐算法[J].计算机工程与设计,2011,32(9):3019-3021.
[13]朱征宇,孙俊华.改进的基于《知网》的词汇语义相似度计算[J].计算机应用,2013,39(8):2276-2279.
(责任编辑 杨黎丽)
Improved PageRank Algorithm Based on User Interest Degree
HUANG Xian-ying,CHEN Hong-yang
(School of Computer Science and Engineering,
Chongqing University of Technology,Chongqing 400054,China)
Traditional PageRank algorithm had such drawbacks as theme drifting,history pages being emphasized and the user's interests in results being ignored.Facing the above defects described,an improved ranking algorithm called PRUI was proposed,which was based on user interest degree.It mainly re-estimated PR value of web page integrating objective characteristics of web page with subjective characteristics of user's interests,and ranked the web page according to the calculated PR value again.The experimental results show that PRUI algorithm has acquired higher retrieval accuracy as well as first page hit ratio,compared with traditional PageRank algorithm.
search engine;PageRank algorithm;user interest degree;page ranking
TP391.03
A
1674-8425(2014)05-0074-05
10.3969/j.issn.1674-8425(z).2014.05.015
2013-12-19
国家自然科学基金项目(61173184);重庆市教委科技计划项目(KJ100821);重庆理工大学研究生创新基金项目(YCX2012317)
黄贤英(1967—),女,重庆人,教授,硕士生导师,主要从事嵌入式技术、移动技术研究;陈红阳(1989—),女,河南南阳人,硕士研究生,主要从事信息检索研究。
黄贤英,陈红阳.基于用户兴趣度的PageRank改进算法[J].重庆理工大学学报:自然科学版,2014(5):74-78.
format:HUANG Xian-ying,CHEN Hong-yang.Improved PageRank Algorithm Based on User Interest Degree[J].Journal of Chongqing University of Technology:Natural Science,2014(5):74-78.
