基于因果关系图进行多因素回归分析的变量筛选*
2014-03-10郑卫军王晓燕王
郑卫军王晓燕王 憓
基于因果关系图进行多因素回归分析的变量筛选*
郑卫军1△王晓燕1王 憓2
在流行病学研究中,常见的是采用建立线性或者logistic回归的方法分析两种或者多种现象之间的因果关系。观察性的研究中,研究者期望分析某种健康/疾病产生的多种原因,因此在构建线性或者分类回归(如logistic)模型上,往往采用同时纳入多种变量的方式模拟真实场景来分析这种健康/疾病现象产生的可能原因;临床试验中,虽然研究者主要关注干预或者实验措施的有效性,但是多因素回归模型往往也是最受欢迎的统计学方法。
存在的变量选择问题
由于回归分析方法的积极作用和其使用的相对简单性,采用多因素线性回归特别是logistic回归分析的论文汗牛充栋,研究人员乐此不彼,但是由此产生了大量滥用、错用、误用的论文[1],即便是国家级核心期刊也无法幸免。纵观文献,鉴于本文主要关注的是模型变量筛选问题,从变量筛选方面来看,最大的问题是很多论文希望能够更加真实地模拟现实状况,把回归方程建成一个庞大的因果关系体系。因此,一个模型往往包括十几个甚至数十个自变量。由此产生很多问题[2-3],如:①由于样本量有限,造成模型系数的标准误过大,②多重共线性的问题普遍存在,③大量多余的变量纳入到模型中,最终导致模型拟合效果较差,所构建的模型无法反映真实状况。针对这种情况,很多学者也提出了一些建议[2,4],包括调整样本量与模型自变量数量的比例、处理多重共线性、设置纳入变量的标准(如单因素分析中P值小于一定水平的变量纳入到多因素回归模型)。笔者看来,上述方法具有一定的效果,但是依然只是从统计学层面而未能更深层次地探讨多因素回归变量筛选的困惑。
因果关系图
因果关系图特别是有向无环图(directed acyclic graphs,DAGs)是流行病学研究中分析疾病因果关系一种重要的理论框架[5-6]。因此,本文将通过构建DAGs的方式来阐述行之有效的多因素回归变量选择方法。
一个简单的DAGs如图1。
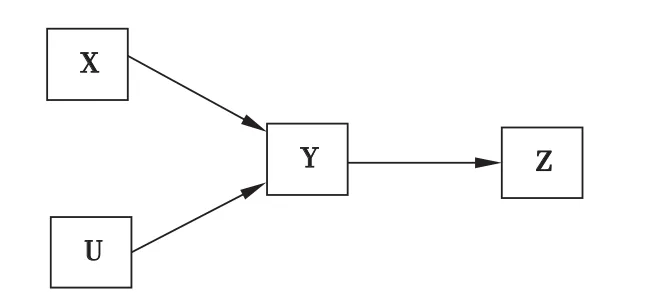
图1 基本的DAGs示意图
从图1可以描述以下几种因果关系。
(1)X、U都是Y的影响因素,对Y有直接的影响
(2)Y是Z的直接影响因素
(3)X、U都是Z的影响因素,对Z有间接的影响
从统计学角度来说,该DAGs将存在下述的现象:
(1)X、U与Y、Z都存在着统计学相关
(2)X、U在统计学上相互独立
(3)DAGs模型存在着连接点和障碍点。X、Z本身相关,两者存在着相关通路,然而,当建立条件相关模型时,即整个统计分析存在着另外一个变量Y时,X、Z不再存在统计学相关,即因此Y又称X、Z的障碍点(blocker);另外一种情况,X、U本身在统计学上独立,然而整个模型存在着Y或者Z时,同时X、U箭头均指向因此Y和Z在这种情况可被称之为X、U的连接点(collider)。
从DAGs模型,可以一窥多因素模型中,因素与因素之间的关系。认真考虑因素之间的关系和其中存在着的障碍点、连接点,完全可以从更深层次的角度来进行变量的筛选。
DAGs与统计变量的筛选
为了更详细展示借助DAGs进行回归模型变量的筛选,本文对图1模型进行更为复杂的构建(见图2)
若Z为一种发病或者不发病的状态,欲研究Z疾病产生的危险因素,是否可以将X、W、T、S、U、Y都纳入进来?目前大量的论文采取的策略便是全部纳入到logistic回归模型,采用逐步回归法进行分析。这是一种错误的策略。
(1)如果X、Y同时在场,其结果如何?在这种情况下,Z、Y的统计学关联将不受影响,然而Z、X的关系本来是直接和间接关系的总和,但由于因此Z、X的关系只剩下直接关系,而间接的关系因为障碍点的存在已经无法在统计学上体现出来了。
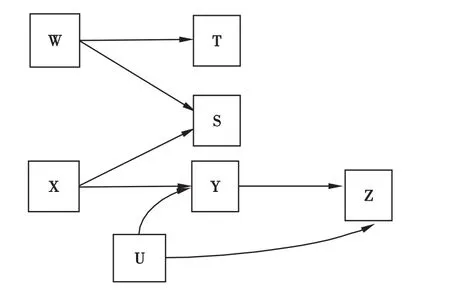
图2 多层次、多因素复杂DAGs示意图
(2)S与Z存在着什么样的关系?从DAGs的理论来说,由于S和Z都受到X的影响,因此两者存在着相关性,然而,两者却不存在因果关系。
(3)W、T与Z的关系呢?此时,可以发现,W、T与Z本身是统计学上独立,两者不存在着相关性,但是X、S都为连接点,因此当四者同时存在时W、T将建立与Y的相关性。
(4)如果研究Y、Z的关系,需要不需要U的存在?从DAGs模型,可以很容易发现,U是一个重要的混杂因素(U既影响Z,也影响Y),根据DAGs理论,Y和Z的关系因为U的存在而发生了偏倚,模型必须要纳入U,剔除U的影响,才可以正确描述Y和Z的因果关系。
因此,如果要研究Y和Z的关系,不能过多地考虑S、W、T的关系,从理论上它们与Z不存在因果关系;同时,必须考虑混杂因素U的存在,将其纳入到模型中来。在模型中X和Y的关系非常微妙,若要研究X和Z的关系,便不能允许Y这个变量在模型中,否则X的影响力将被改变,但此时不影响Y和Z的关系。
工具变量和未知混杂因素的研究
在流行病学研究中,往往所分析的因素有限,一些未知的混杂因素在很大程度上将影响对若干重要变量的评估。这种情况在观察性研究和干预性研究中较为常见。比较典型的一个例子出现在临床试验中意向性治疗现象中(the intent-to-treat,ITT)[7]。某一些群体由于未知的原因未能按照临床试验的要求接受治疗或成为对照组,造成临床随机状态不复存在,但又无法将未知的混杂因素纳入到模型中,所以干预结果可能存在一定的偏倚。针对这种情况,近年来,学者根据DAGs提出了一个工具变量(instrumental variables,IV)的概念,用于调整流行病学中的未知混杂变量[8]。
工具变量是一类符合下列条件之一的变量:①对干预(暴露)因素有作用,也只能通过干预(暴露)因素与结局的发生关联,②与干预(暴露)因素相关,也只能通过干预(暴露)的因素与结局发生关联。但凡可以通过影响其他变量或与其他变量相关的方式与干预(暴露)因素或者结局建立关联的变量,就不再是工具变量。结合图2来看,X是一类工具变量,符合条件①,而S是另外一类工具变量,符合条件②。深入探讨工具变量,可以从图2中X(工具变量)、Y(干预变量)、Z(结局变量)、U(混杂变量)四者的概率关系予以分析:
假如欲分析干预变量Y和结局变量Z的因果关系,那么,
(1)Y、Z的关系包括了Y和Z真实的因果关系以及由于混杂因素U存在,Y、Z建立起来的虚假因果关系。由于混杂因素U未知,Y、Z真实的关系将存在偏倚。
(2)已知的情况有两种(均不受U影响),X与Y的真实关联性,X与Z的真实关联性。其中,X与Y的关系可以表述为因此,由于从而我们可以算出真实的建立Y和Z真实关系。
例如:进行临床某新型降血糖药物的干预研究,采用随机双盲实验,将研究对象随机分为药物组和安慰剂,而结局为血糖降到正常水平(是/否),然而,由于某种原因,导致病情好转或恶化,研究对象选择了放弃或者改变药物治疗手段,从而导致随机化这一努力失败。无论是排除这一特殊群体,还是根据所有人群实际情况进行分析,其真实的药物效果都可能受到干扰。
从工具变量的角度可以发现,随机化分组对疗效具有明显的作用,但是它不会影响其他任何的行为,只通过影响研究对象是否进行干预而最终影响疗效,所以它是一个比较好的工具变量。
举例:为什么人口社会经济学特征一般不作为解释变量进行讨论
笔者将以往论文的数据作为例子进行再分析[9],探讨糖调节受损者糖尿病发病的主要发病因素,假设待研究的包括自变量性别、年龄、家族糖尿病史、基线血糖水平,和因变量糖调节受损者转归结局(2年后)。
常规的方法是将上述所有自变量放在logistic回归模型中进行多因素回归分析。如果同时列入性别、年龄、家族史、基线血糖水平,logistic模型将得到以下结果(表1):除了基线血糖水平,其他因素都没有统计学意义。那么如果根据这个结果,是否可以暂时认为性别、年龄、家族史对糖调节受损者的转归没有影响?然而,如果去掉基线血糖水平这个因素再重新建模,结果发现,三个因素都有统计学意义。

表1 两个logistic回归模型的分析结果
理论上,上述变量的因果关系图较为明确(图3)。年龄、性别、家族史将先通过影响基线血糖水平从而影响糖调节受损者转归,但是在本例中发挥着非直接,而是间接的作用。基线血糖扮演的角色则是障碍点,采用logistic回归分析,在基线血糖这个变量存在的情况下,年龄、性别、家族史的作用无法体现出来。在这种情况下,如果讨论年龄、家族史和性别的作用,那么就将产生错误结论。因此,考虑到混杂偏倚的情况,较为妥善的思路是,人口社会经济学特征只是作为协变量或者调解变量存在,在论文的讨论中不应着墨分析。
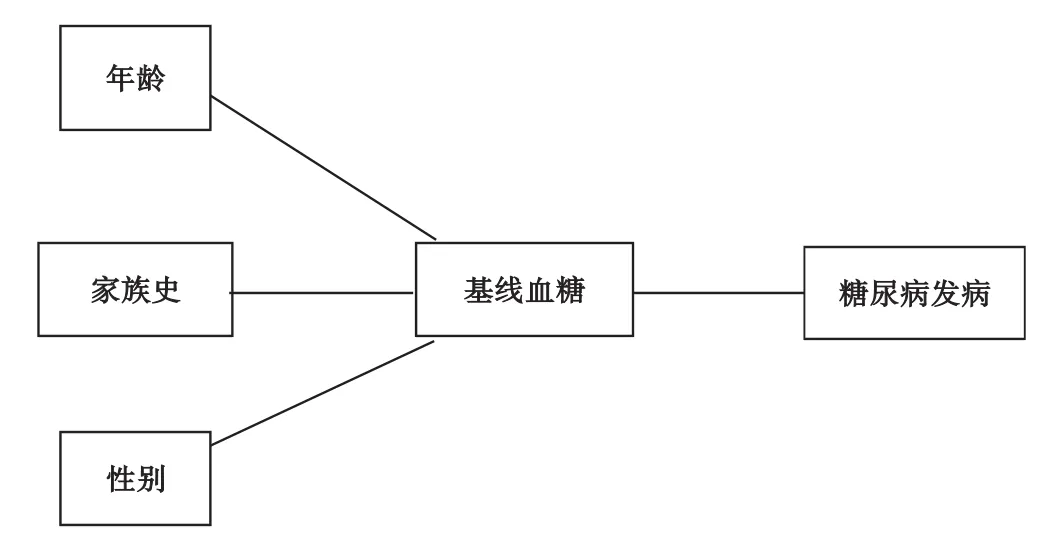
图3 糖尿病发病因素简单DAGs示意图
讨论和建议
从上述分析可以发现,DAGs模型在回归分析中发挥了一定的作用。它可以较为清晰地展现变量与变量之间的关系,了解自变量的层次结构、变量之间的因果或者相关关联、自变量与因变量的直接和间接关系,从而有助于统计分析中进行模型变量纳入筛选。通过比较DAGs模型和目前文献中多因素回归分析现状,可以发现当前很多论文中:①很多只是存在相关的变量,被纳入到模型中建立了因果关联性如图2中S变量;②一些事实上与结局没有因果甚至是相关的变量,由于连接点的存在,统计分析中成为了有统计学意义的因素,如W、T变量;③由于另外变量的存在,一些因素的作用被改变,比如由于Y的存在,导致了X的作用被误解;④混杂因素被放大或者被忽略,如将任何其他变量都作为潜在混杂因素放入模型,或者完全不考虑重要的混杂变量。
从DAGs中,笔者归纳总结出以下几点想法:第一,构建多因素回归模型之前,认真进行理论因果模型的构建势在必行,必须改变目前只看数据不论因果进行统计推断的现状。采用DAGs的方法可控制模型的因素,纳入合适的主要变量进行分析,提高统计模型的效能。第二,不同水平的变量尽量分别建模,如X、Y尽量在不同模型去考虑对Z的影响,这将减少多重共线性对模型的影响。特别需要考虑人体一些疾病标志物因素。这些因素与结局变量存在着高度相关(如本文举例的“基线血糖”),一旦其进入回归模型,其他因素的作用将很难体现出来。第三,混杂因素已经成为流行病学研究中考虑的关键因素,在统计分析中应重点考虑。在统计推断之前,需认真分析潜在混杂变量与干预(暴露)因素和结局变量的关系,一旦与两者都不存在着关联性,可以初步认定为非混杂因素,可以考虑不纳入到模型中。在模型分析阶段,目前有一些已知混杂因素处理方法,如逐步回归法、倾向性匹配技术等,这些方法已经成熟,不再赘述。笔者认为,在可能的情况下,可以试图考虑未知混杂因素的处理,尝试寻找工具变量的方法进行分析。当然,必须承认的事实是,工具变量是一类较难发现的变量,一般情况下,那些类似于随机分组的变量,往往最有可能成为工具变量,这是寻找的一种策略。
1.冯国双,陈景武,周春莲.logistic回归应用中容易忽视的几个问题.中华流行病学杂志,2004,25(6):544-545.
2.刘宏杰.Logistic回归模型使用注意事项和结果表达.中国公共卫生,2001,17(5):466-467.
3.金水高.第十五讲logistic回归方法的正确应用及结果的正确解释.中华预防医学杂志,2003,37(3):204-206.
4.杨梅,肖静,蔡辉.多元分析中的多重共线性及其处理方法.中国卫生统计,2012,29(4):620-624.
5.Greenland S,Pearl J,Robins JM.Causal diagrams for epidem iologic research.Epidem iology,1999,10(1):37-48.
6.Weng HY,Hsueh YH,Messam LL,etal.Methods of covariate selection:directed acyclic graphs and the change-in-estimate procedure.Am JEpidemiol,2009,169(10):1182-1190.
7.Hollis S,Campbell F.What ismeant by intention to treat analysis?Survey of published randomised controlled trials.BMJ,1999,319(7211):670-674.
8.Davies NM,Sm ith GD,W indmeijer F,et al.Issues in the reporting and conduct of instrumental variable studies:a systematic review.Epidem iology,2013,24(3):363-9.
9.郑卫军,沈祥峰,周驰.糖调节受损者睡眠质量与糖尿病发病关系的研究.中华流行病学杂志,2012,33(11):31-33.
(责任编辑:刘 壮)
*基金支持:浙江省自然科学基金(LQ13H260001)
1.浙江中医药大学基础医学院预防教研室(310053)
2.浙江省疾病预防控制中心
△通信作者:郑卫军,E-mail:deardangjun@163.com
