基于话音识别的骚扰电话呼叫检测技术分析
2014-02-07杜海涛张峰高曼颖胡入祯杨光华
杜海涛,张峰,高曼颖,胡入祯,杨光华
(1 中国移动通信集团公司研究院, 北京 100053; 2 中国移动通信集团公司信息安全管理与运行中心, 北京 100053)
基于话音识别的骚扰电话呼叫检测技术分析
杜海涛1,张峰1,高曼颖2,胡入祯2,杨光华1
(1 中国移动通信集团公司研究院, 北京 100053; 2 中国移动通信集团公司信息安全管理与运行中心, 北京 100053)
通过对话音识别中的模板匹配技术DTW算法的研究和改进,实现了一种应用于判别骚扰电话录音的话音识别系统。实验结果表明,该系统具有较高的识别精度,是一种有效的应用于判别骚扰电话的话音识别系统,能显著提高骚扰电话人工审核的效率,进一步完善骚扰电话治理工作。
话音识别;骚扰电话;MFCC;DTW
随着通信技术的不断发展,利用移动通信网络拨打骚扰电话的现象大量出现,为了更好地净化网络通信环境,各运营商已经建立了骚扰电话监控系统,骚扰电话的识别需要大量人工进行审核。近年来,随着话音识别技术的成熟,话音识别已经广泛应用于办公室和商务系统、电话话音拨号、移动终端话音控制等许多领域,通过引入话音识别技术对录音文件进行判别,可以极大提高骚扰电话的审核效率。本文通过对话音识别数学模型DTW的研究和改进,实现了一个应用于判别骚扰电话录音的话音识别系统。
1 骚扰电话治理现状
目前骚扰电话监控系统收集各省信令监测平台的详单数据,经过骚扰电话监控策略筛选出疑似骚扰电话,然后经过自动拨测录音,进一步的筛选认证,最后通过人工审核判别出骚扰电话。现有方案设计的骚扰电话监控系统结构如图1所示。
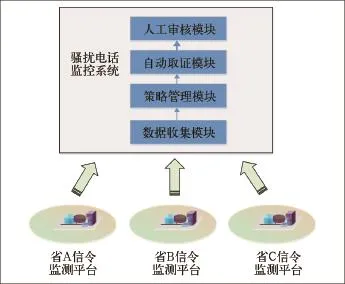
图1 骚扰电话监控系统
(1)数据收集模块:数据收集模块负责收集各省信令监测平台的详单数据,作为策略管理模块的数据源。
(2)策略管理模块:策略管理模块负责制定监控策略和策略的参数、约束,通过策略监控,判定出疑似骚扰电话。
(3)自动取证模块:自动取证模块负责对策略管理模块输出的疑似骚扰电话进行拨测录音,并对呼叫成功的通话自动录音,录音过程中可根据配置向被叫用户播放提示音,从而进行进一步的筛选。
(4)人工审核模块:人工审核模块是疑似骚扰电话的审核与处理中心。审核模块汇总疑似骚扰电话,根据设定好的审核规则,由人工自动对全部的疑似骚扰电话进行审核。
疑似骚扰电话主要分为忙音、来电提醒等提示音和代孕、假中奖、诈骗类等骚扰电话,通过对录音的内容进行归类和分析,发现提示音类电话重复性比较高,骚扰电话重复性不是很高。目前骚扰电话判定主要依靠人工审核的方法,随着话音识别技术的逐步成熟,尤其是针对重复内容的识别处理技术更是具有不可替代的作用。骚扰电话的分类和比例,如表1所示。
目前,话音识别方法可以分为两类,一类是基于内容的(连续话音识别),主要利用高层信息对音频进行分类和识别,另一类是基于特征相似度的(或称基于模版匹配)。因此,对于代孕、假中奖、诈骗类等骚扰电话的审核,可引入连续话音识别技术,该技术的应用场景有待进一步探索;对于重复性比较高的提示音类电话的审核,可引入话音识别的模板匹配技术,该技术比较成熟,可行性较好,也是本文研究实现的重点,能显著提高骚扰电话的审核效率,从而进一步完善骚扰电话的治理工作。
2 话音识别技术实现原理
话音识别系统化本质上是一种模板匹配系统,包括预处理、端点检测、特征提取、模板库、模板匹配等基本单元,基本结构图如图2所示。
2.1 预处理
话音信号的预处理包括预加重、分帧和加窗、端点检测3个步骤。其主要目的是对话音信号采样、去噪,便于后期的特征提取。

表1 骚扰电话的分类和比例
预加重通过滤波提升高频分量并消除工频干扰,常用一阶数字滤波器来实现,其系统函数为:
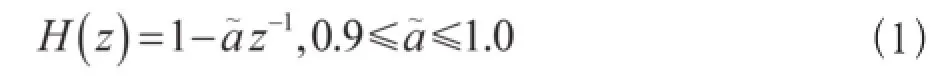
其中α为预加重系数,一般取值为0.95。
为了得到短时平稳信号,要对话音进行分帧处理,分帧采用滑动的有限窗口进行加权,保持话音流的连续性。实验中采用的窗函数为汉明窗,其形式:

其中,L为窗长。
话音的端点检测就是根据某些特征参数准确地判断出话音的起点和终点,排除话音的噪声段、静音段等。常用的端点检测参数是短时能量和短时过零率。为提取有效的话音信号,通常采用短时能量和短时过零率相结合的方法进行端点检测,即双门限端点检测。

图2 话音识别基本结构图
2.2 特征提取
特征提取是话音识别的关键环节,常用的特征提取方法有线性预测倒谱系数LPCC和Mel频率倒谱特征参数MFCC。线性预测倒谱系数LPCC是从人的发声模型角度出发,利用线性预测编码技术,而Mel频率倒谱特征参数MFCC充分考虑了人耳的听觉特性。研究表明,MFCC具有更好的鲁棒性,所含的信息量比LPCC更多,能较好的表现话音信号,因此,选用MFCC作为特征参数具有一定的优势,MFCC的提取流程如图3所示。
Mel频率表示公式为:
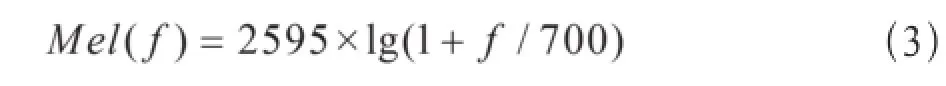
式中f为频率,单位为Hz。
MFCC的提取过程中,首先对话音信号进行分帧、加窗,然后作离散傅立叶变换得频谱分布信息,求出频谱平方,即能量谱,再用Mel滤波器组(通常为三角形带通滤波器)进行滤波,得到功率谱。将每个滤波器的输出取对数并进行反离散余弦变换,得到MFCC系数,MFCC系数计算公式:
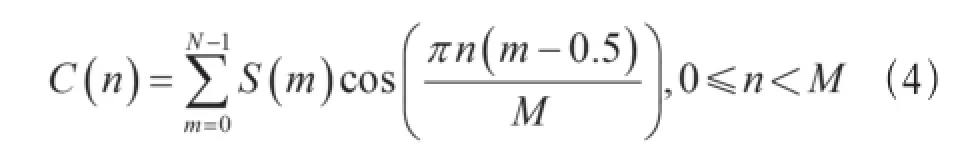
由于MFCC只反映了话音参数的静态特性,需对MFCC系数进行差分计算得到反映话音动态变化的差分参数。
2.3 模板匹配
话音信号具有相当大的随机性,即使是同一个人在不同时刻所讲的同一句话、发的同一个音,也不可能具有完全相同的时间长度。在模板匹配过程中,为了确定参考模板和测试模板的时间对应关系,通常采用动态时间规整DTW算法,该算法基于动态规划(DP)的思想,解决了发音长短不一的模板匹配问题,是话音识别中出现较早、较为经典的算法之一。
假设参考模板的特征矢量序列为:{R(1),R(2),…R(m),…R(M)}

图3 MFCC提取流程图
其中,m为参考模板话音信号的第m帧,m=1时表示话音帧开始,m=M时表示话音帧结束,即M模板话音的帧数,并且R(m)为第m帧的特征向量。
测试模板的特征矢量序列为:
{T(1),T(2),… T(n),… T(N)}
其中,n为测试模板话音信号的第n帧,n=1时表示话音帧开始,n=M时表示话音帧结束,即M模板话音的帧数,并且T(n)为第n帧的特征向量。
DTW就是通过寻找一个时间规整函数,将测试矢量的时间轴非线性的映射到参考模板的时间轴上。通常规整函数被限制在一个平行四边形的网格内,如图4所示,它的一条边斜率为2,另一条边斜率为1/2。规整函数的起点是(1,1),终点为(M,N)。DTW的目的是在此平行四边形内由起点到终点寻找一个规整函数,使其具有最小的代价函数。
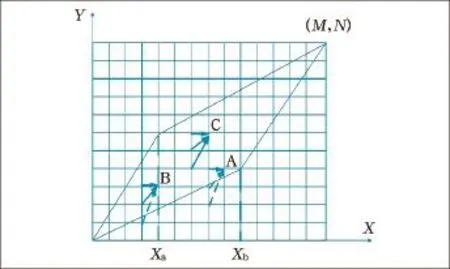
图4 DTW算法搜索路径约束图
一般的DTW算法在匹配过程中限定了弯折的斜率,许多格点是达不到的,即平行四边形之外的格点对应的帧匹配距离是不需要计算的,也没有必要保存所有的帧匹配距离矩阵和累积距离矩阵,并且每一列格点上的匹配计算只用到了前一列的3个网格,充分利用这两个特点,为了减少计算量和节省存储空间,出现了一种改进的DTW算法。在图4平行四边形的基础上,将其分成动态弯折的3段,其动态弯折的3段为(1,Xa),
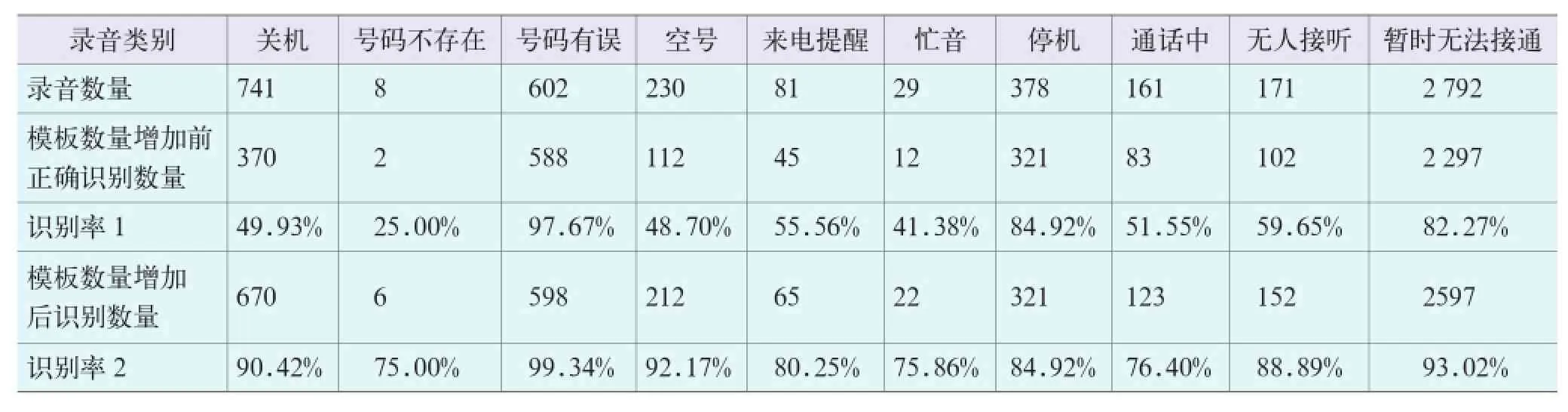
表2 待测录音的正确识别情况表
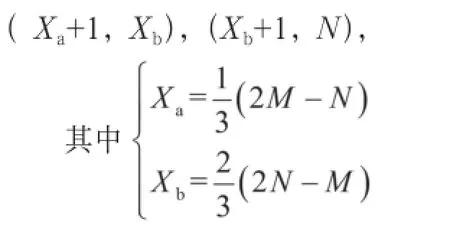
此时X轴上的每一帧不再需要与Y轴上的每一帧进行比较,而只与Y轴上[Ymin,Ymax]间的帧进行比较。如图中点A、点B、点C所示,实线表示有效路径,虚线表示无效路径,这样就避免了整个过程中每次搜索路径按3点匹配的繁琐,可以大大缩短匹配中的计算量,提高匹配速度。
3 系统的编程实现
系统的主程序是Voice Harass,基于Linux操作系统运行,系统的组成模块与话音识别系统的构成基本一致。模板训练过程中,首先对模板录音生成音频列表Addlist,然后对模板录音进行预处理,对音频进行去除静音和切分,将音频切分为数个音频片段,将预处理后的音频片段送入声学特征提取模块,将音频片段转换为对应的特征矢量MFCC,作为模板话音的识别特征,生成模板库Template。为了增强系统的鲁棒性和话音识别的准确率,在实验中选择不同类别的录音进行模板训练,不断丰富模板库。在识别阶段,首先也需要对待测录音生成音频列表Wavlist,然后对待测录音进行预处理和特征提取,提取话音的特征矢量MFCC,最后进行音频匹配,即将待测录音的特征矢量与模板库中话音模板逐一进行相似性度量的比较,从而得出最佳的匹配结果。
本实验采用的录音是骚扰电话监控平台的自动取证模块对疑似骚扰电话进行拨测后录取的通话录音,并且选取重复性比较高的提示音作为样本数据,录音采用的录音格式为wav格式,话音的采样率为8kHz,量化精度为8bit。通过进行多次的模板训练,实验数据表明,模板训练的正确识别率为99.23%。实验分别对模板数量增加前后的待检测录音的识别率进行了统计,识别率1和识别率2分别是模板数量增加前后的实验结果,待测录音的正确识别情况详见表2和图5,平均识别率分别为59.66%和85.26%,由表2和图5可知,话音识别的模板匹配技术识别效果较好,且增加模板数量,可大大提高话音的识别率。
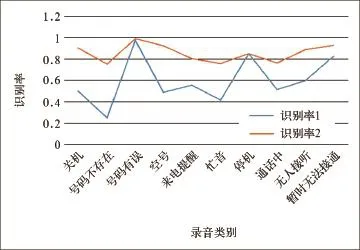
图5 待测录音识别率对比
4 结束语
本文介绍了目前骚扰电话的治理现状,分析了骚扰电话治理中存在的问题,提出引入话音识别检测技术的方法,可准确识别出提示音录音。通过对DTW算法的改进,以及对系统各个部分详细的探究和实验,实现了一种基于话音识别的骚扰电话判别系统,实验数据表明话音识别的模板匹配技术识别效果较好,并且增加模板数量,可显著提高话音的识别率。但是对于代孕类、假中奖类、金融诈骗类等骚扰电话,利用连续话音识别技术进行检测,将是下一步工作的重点和难点。
[1] 林波,吕明.基于DTW改进算法的孤立词识别系统的仿真与分析[J].信息技术,2006(4).
[2] 靳月英. 话音识别ASIC中端点检测算法研究与实现[J]. 计算机与现代化, 2011(12).
[3] 王令斌.特定音频过滤算法的研究[D]. 天津大学,2008.
[4] 胡亚洲,王新民,曹江涛. 基于改进DTW的机器人话音指令识别系统研究[J]. 计算机技术与发展, 2013(7).
[5] 徐利军. 基于DTW的孤立词话音识别研究[J]. 软件导刊,2012(2).
[6] 王娜, 刘政连. 基于DTW的孤立词话音识别系统的研究与实现[J]. 九江学院学报, 2010(3).
News
中国移动物联卡业务正式商用
11月26日,中国移动物联网专网专号(物联卡)业务正式商用。据悉,该业务由中国移动总部统一负责产品规划和管理,由物联网公司承担全网运营支撑工作。
据了解,中国移动物联网专网专号业务采用物联网专用号段作为MSISDN的移动通信接入业务,商用后使用名将由原来的“机器卡”更名为“物联卡”。2013年9月,中国移动物联网机器卡业务开始试商用,试商用省区业务发展趋于规模化,非试商用省区业务功能也逐渐完善,为正式商用奠定了良好基础。商用期间,中国移动物联网专网将为客户提供物联卡与业务平台之间的无线数据传输和短信通信基本功能,并通过物联网专网业务管理平台向客户提供智能通道服务,包括通信管理、终端管理、位置定位等。
记者获悉,中国移动物联卡业务将在今年年底具备4G功能,届时,物联卡将在4G的基础上充分发挥码号资源丰富、漫游结算成本低、计费灵活、业务管理能力强等优势,在前装、大流量、业务管理和非实时交互四大类应用领域实现突破,满足物联网亿量级用户终端连接需求。 (高雅)
Analysis and experiment of disturbing call detection technology based on speech recognition
DU Hai-tao1, ZHANG Feng1, GAO Man-ying1, HU Ru-zhen1, YANG Guang-hua1
(1 China Mobile Research Institute, Beijing 100053, China; 2 China Mobile Information Security Center, Beijing 100053, China)
Based on the research and improvement of template matching technology DWT algroithm in speech recongnition, speech recongnition technology is applied to disturbing call syetem. The experimental results shows that the technology is more accuracy and effective to call record, so it can signif cantly improve artif cial audit eff ciency, and elevate the management work of telephone harassment.
speech recognition; disturbing call; MFCC; DTW
TN918
A
1008-5599(2014)12-0005-05
2014-11-16
