基于分组的STL模型快速切片算法
2014-01-25侯聪聪
侯聪聪,南 琳,张 磊
(1.中国科学院沈阳自动化研究所,沈阳 110016;2.中国科学院大学,北京 100049)
0 引言
快速成型技术RP( Rapid Prototyping ) 是集机械、计算机、光学、电子及新材料为一体的新型先进制造技术,通过逐层增加材料制造零件[1,2]。在所有的RP工艺中,无论是由CAD造型软件还是由逆向工程生成的零件CAD模型,都必须经过分层处理才能将数据输入到RP设备中,因此分层算法是RP制造中的一个关键环节。
STL文件是RP系统中数据交换的标准文件类型[3],用三角网格面近似地表现三维CAD模型,并记录模型中每个三角面片的几何信息,包括三角面片所在平面的法矢和它所包含的三个顶点的坐标。由于STL模型数据格式简单、易于交换处理,基于STL模型的切片处理已被大多数RP系统采用。
目前,STL模型的切片算法主要分为以下两类:
1)基于几何拓扑信息的STL模型切片算法[4~8]。该类算法根据三角面片的点、边和面数建立STL模型的整体拓扑信息,利用拓扑信息可以迅速查找到相邻三角面片,并通过对相邻三角面片的追踪得到有向轮廓线。其优点是利用拓扑关系,无需排序,可直接获得首尾相连的封闭轮廓线。但该算法也存在一定局限性:获取STL模型整体拓扑信息的过程相当费时,尤其对于复杂的STL模型占用系统资源较多;当STL文件有错误时,可能无法得到正确的截面轮廓线。
2)基于三角面片几何特征的STL模型切片算法[9~12]。该类算法根据三角面片顶点坐标沿切片方向投影值的大小进行分组排序,减少三角面片与切片平面位置关系的判断次数,加快分层处理速度。但是该算法的局限性在于:对大量三角面片的排序是一个耗时的过程;在后续轮廓线的生成过程中,还要进行交线连接关系的搜索判断;三角面片分组界限比较模糊,经常无法判断三角面片与分层平面的位置关系。
针对以上两种分层算法的优缺点,本文提出整体分组排序,局部建立基于链表的拓扑关系的思路以进一步的降低分层算法的复杂度。针对具体的零件模型,通过仿真对比分析,得到合适的分组组数。同时本文提出了基于链表的STL文件拓扑重建算法,在建立拓扑关系的同时去除了冗余数据,节省了存储空间,提高了存储效率。
1 基于链表的拓扑重建算法
STL文件的数据量很大,一个表面复杂的实体模型由几万甚至几十万个三角形面片构成,由于对任意多面体,均存在欧拉公式F-E +V=2,其中F表示面的数目,E表示边的数目,V表示点的数目。对于一个由三角面片构成的多面体,每个三角面片具有3条边,每条边被2个三角面片共享,因此可得出E=3F/2。将其带入欧拉公式得V=F/2+2,而STL文件中所存顶点数是三角面片数的3倍,所以平均分裂后的点数为原拓扑点数的6倍。因此数据的冗余现象比较严重。如果简单地照原样提取数据,会占用大量的计算机资源,降低计算速度,而且使得后续的处理计算量增大。因此从文件中提取数据时必须进行数据筛选,去除冗余信息。因而,STL文件拓扑重建过程通常由两部分组成:冗余数据的去除和拓扑结构的建立。
本文提出了基于链表的STL文件重建算法。该算法采用链表[13]作为数据结构,将两部分融合为一个整体,对冗余点和冗余边进行了处理,实现了数据的无重复存储。节省了存储空间,提高了存储效率,同时建立了拓扑结构,提高了数据的可操作性,为后续分层奠定了基础。
1.1 拓扑重建的数据结构
拓扑重建过程数据结构分为三类,面( Facet)、边(Edge)和顶点(Vertex),由三个类产生三个对象,并建立相应的对象链表。为了节省拓扑关系存储的时间和空间,顶点链表只记录该点的坐标,边链表只记录所包含的顶点在顶点链表中的编号和所属面片在面链表中的编号,面链表只记录所包含的边在边链表中的编号。具体的数据结构如图1~图3所示。
1.2 拓扑结构重建
本算法以三角面片为基本单位,依次读取每个三角面片的顶点数据,对顶点链表中的顶点进行查询,在判断一个顶点为非冗余点后,将其插入顶点链表并为其建立邻域信息,并在插入了其他点后对其进行实时更新;以同样方法进行边的去冗余及建立邻域信息,最终建立一个完整的拓扑结构。
算法具体步骤如下:FaceCount为STL文件中的三角面片个数总和。
Step1:分别创建点对象链表vlist、边对象链表elist及面对象链表f l ist。
Step2:创建三个点对象v1、v2、v3,三条边对象e1、e2、e3和面对象f,并将f添加到flist,取三角面片三个顶点数据,分别赋给v1、v2、v3。
Step3:取v1,查找vlist中是否有相同的点。如果有,则将该点在vlist中对应的索引号赋给e1的EVertexIndex1、e3的EVertexIndex2;如果没有,则将v1添加到vlist,并将v1在vertexlist中对应的索引号赋给e1的EVertexIndex1、e3的EVertexIndex2。v2和v3同v1。
Step4:取e1,查找elist中是否有相同的边,如果有,则将该边在elist中对应的索引号赋给f的FEdgeIndex1,同时将f在flist中的索引号赋给该边的EFacetIndex2;如果没有,则将e1添加到elist,并将e1在elist中对应的索引号赋给f的FEdgeIndex1,同时将f在flist中的索引号赋给e1的EFacetIndex1。e2和e3同e1。
Step5:读第n个三角面片,如果n≤ FaceCount,则返回step2;否则退出程序,拓扑结构创建完成。
1.3 算法复杂度分析

图1 顶点链表

图2 边链表

图3 面链表
该算法的时间复杂度主要是冗余点和冗余边的滤除时间。对于上述算法,设STL文件中三角面片个数为n,则顶点数和边数均为3n。依据上述STL文件中三角面片的公式E=3F/2,V=F/2+2,得到最终存储的顶点数为n/2,边数为3n/2。对于一个顶点i(i=1,2,…,3n),在链表中查找的平均时间复杂度为o(l)(l为链表长度,l=1,2,…,n/2),则去除冗余顶点的时间复杂度为o(n2)。同理,去除冗余边的时间复杂度为o(n2)。因此,该算法的总的时间复杂度为o(n2)。与其他算法相比,该算法在相同的时间复杂度的情况下,既去除了冗余顶点和边,又建立了拓扑关系,提高了算法的效率,节省了存储空间。
2 基于分组思想的分层算法
该算法的基本思想是“整体分组排序,借助分组结果,局部建立基于链表的拓扑关系”,即先对所有的三角面片依据其在分层方向的投影值的大小将其分为几个大组,在此基础上建立局部拓扑关系,进行分层处理。
2.1 整体分组
假设Z轴为分层切片方向,STL模型在Z轴上的最大值为Zmax,最小值为Zmin。假设将整个模型分为k组,各组的范围分别为:[Z0,Z1],[Z1,Z2]…[Zi-1,Zi]…[Zk-1,Zk],Z0=Zmin,Zk=Zmax。三角面片F在Z轴投影范围[Fzmin,Fzmax],Fzmin,Fzmax分别为三角面片在Z轴投影的最小和最大值。如果[Zi-1,Zi](i=1,2…k)与[Fzmin,Fzmax]有交集,则F属于第i组。在进行分层时通过分层平面的高度可以直接在对应的组中查找与切平面相交的首个三角面片,减少了三角面片与平面位置关系判断的次数。
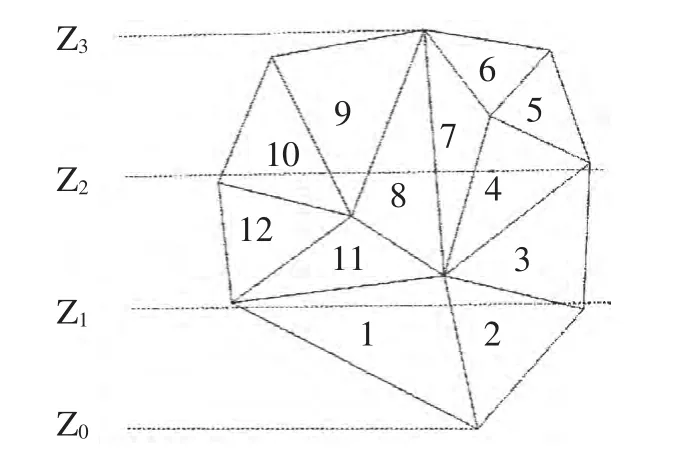
图4 分组实例
以图4所示的局部STL模型为例,运用上述分组思想,分组结果如表1所示。
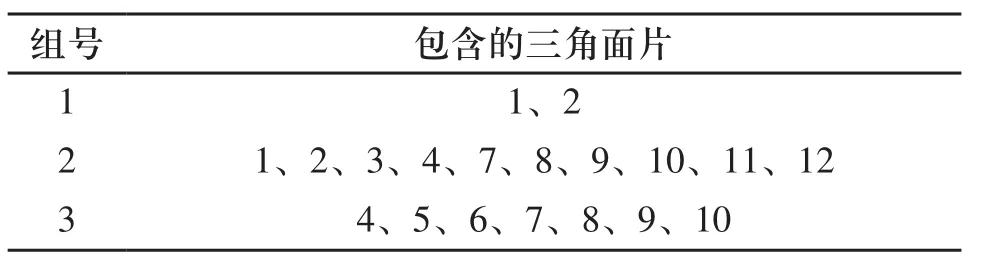
表1 分组结果
2.2 分层切片求取轮廓线
分组之后,采用小节1中拓扑重建算法建立局部拓扑结构,分层求交,获取轮廓线。先找到一条与当前切平面有交点且未被切过的边,求出此边与切平面的交点,保存,并将此边的位置标志为已切。根据上述拓扑关系找到此边所属的三角面片,在三角面片中查找与切平面有交点且未被切过的边,求其交点,保存。以此类推,则可得到与当前切平面相交的一组首尾相连、封闭的多边形轮廓线。设Z轴为分层方向,具体分层求交算法如下:
Step1:确定第一个切平面高度h=Zmin(模型在分层方向上的最小值)。
Step2:将elist中所有边对象的mark置为false,f l ist中所有面对象的mark置为false。
Step3:找到一个与当前切平面相交且未被切过的边edge0,如果存在则执行下一步,否则跳到step8。
Step4:求边edge0与切平面的交点,保存,并将该边的mark置为true。
Step5:根据拓扑关系找到包含该边的且未被切过的三角面片,将该三角面片的mark置为true,求三角面片另外两条边中与当前切平面相交且未被切过的边,求交点保存,并将该边的mark置为true。
Step6:重复step5直到回到初始边edge0,得到与当前切平面相交的一个多边形轮廓线。
Step7:返回step3,直至求出所有与当前切平面相交的多边形轮廓线。
Step8:令 h= h+thick (切片厚度),如果h≤Zmax(模型在分层方向上的最大值),返回step2,否则,退出程序,切片完成。
整体分组、局部建立拓扑关系可以有效的降低STL建立拓扑关系的算法复杂度。由于建立拓扑关系时的算法复杂度与面片个数的平方成正比,假设一个STL文件中包含n个三角面片,如果对整个模型建立拓扑关系算法复杂度为o(n2);如果将整个STL文件按分层方向分为k(k 理论上,k越大,即组数越多,算法复杂度越小,但是k过大,组之间重叠的三角面片数量过多,重叠的面片在不同的组之间重复建立拓扑关系增加了算法的复杂度。以图5所示轴套为例,三角面片的数目为8537个,分组数分别取1、10、20、30、40、50,分层厚度为2mm,分组切片时间开销(每个分层组数重复仿真20次,求取时间的平均值)如表2所示。 通过对表2进行分析,可以发现当分组数目逐渐增大时,分层算法的时间开销逐渐减少;但是当分组数目大于20时,时间开销开始增加。由此可见,分组组数并不是越大越好。因此,对于不同的零件和三角面片数量要选择合适的分组组数。 在软硬件环境相同的情况下,三种不同切片算法的对比如表3所示,其中m为三角面片的个数,h为分层厚度,T1为基于拓扑信息的切片算法所用时间,T2为基于三角形几何特征的切片算法所用时间,T3为本文算法所用时间(每种算法重复仿真20次,求取时间的平均值),g为本文算法对三角面片进行分组所得的组数。由表1可以看出,与其他2种算法相比,随着模型三角形面片个数的增加,本文算法的效率逐渐提高。 该算法综合考虑了现有切片算法的特点,提出了分组的思想降低了建立拓扑关系的算法复杂度,并同时提出了基于链表的拓扑重建算法,在建立拓扑关系的同时去除了冗余数据,降低了算法空间开销。最后通过实例仿真,证明了算法的可行性和高效性。根据三角面片数量以及零件形状精确的确定最优的分组数量以使算法复杂度得到进一步的降低是未来研究的重点。 表3 不同切片算法对比 [1]颜永年,张伟,卢清萍,王刚,刁庆军,时晓明.基于离散/堆积成型概念的RPM原理和发展[J].中国机械工程,1994,5(4):64-66. [2]韩光超,张海鸥,王桂兰.面向金属模具快速制造的机器人成型加工系统[J].机器人,2006,28(5):515-518. [3]刘光富,李爱平,王东立.三维实体零件分层处理软件的研究与开发 [J].制造业自动化,2004,26(11): 21-24. [4]王素,刘恒,朱心雄.STL模型的分层邻接排序快速切片算法[J].计算机辅助设计与图形学学报,2011,26(4):4-6. [5]谢存禧,李仲阳,成晓阳.STL文件毗邻关系的建立与切片算法研究[J].华南理工大学学报(自然科学版),2000,28(3):33-38. [6]李仲阳,谢存禧,杨家红.基于STL文件的快速成型分层算法与毗邻拓扑信息的快速提取[J].计算机工程与应用,2002,38(7):32-35,79. [7]赵吉宾,刘伟军.快速成形技术中基于STL模型的分层算法研究[J].应用基础与工程科学学报,2008,16(2):224-233. [8]CHOI S H,KWOK K T.A tolerant slicing algorithm for layered manufacturing[J].Rapid Prototyping Journal,2002,8(3):161-79. [9]赵保军,汪苏,陈五一.STL数据模型的快速切片算法 [J].北京航空航天大学学报,2004,30(4):329-333. [10]胡德洲,李占利,李涤尘,et al.基于STL模型几何特征分类的快速分层处理算法研究[J].西安交通大学学报,2000,34(1):37-40,45. [11]李占利,梁栋,李涤尘,et al.基于信息继承的快速分层处理算法研究[J].西安交通大学学报,2002,36(1):43-46. [12]赵吉宾,刘伟军.快速成型技术中分层算法的研究与进展[J].计算机集成制造系统,2009,15(2): 2-21. [13]SAHNI S.数据结构,算法与应用 [M].北京:机械工业出版社.2000.3 模型仿真与对比
4 结论

