一种有效缓解协同过滤推荐评价数据稀疏问题的算法
2013-09-17黄永锋覃罗春
黄永锋,覃罗春
(东华大学 计算机科学与技术学院,上海 201620)
一种有效缓解协同过滤推荐评价数据稀疏问题的算法
黄永锋,覃罗春
(东华大学 计算机科学与技术学院,上海 201620)
在采用协同过滤算法构建个性化推荐的系统中,经常面临用户评价数据稀疏问题,这将严重降低个性化推荐的准确度.针对此问题,提出了一种混合加权预测填充算法,从用户访问的资源特征以及该资源在整个用户群体中被访问的热度出发,对用户访过的但未给出评价的数据进行预测并填充,从而降低了由于用户评价数据缺失所造成的评价矩阵稀疏程度,提高推荐准确度.在MoiveLense数据集上的试验结果表明,该算法能够明显地提高推荐准确度.
个性化推荐;协同过滤;数据稀疏;预测填充;资源特征
在互联网服务供应商提供海量信息时,通过个性化推荐能够更快、更准确地为用户找到可能感兴趣的信息资源,提供更加智能的服务,从而有效地提高用户的忠诚度,扩大品牌影响力,提高企业销售.个性化推荐目前广泛地应于互联网各个领域,如电子商务、数字图书馆、网络广告定向投放、网络新闻订制等[1].而基于协同过滤的个性化推荐是迄今为止使用最为广泛也是最受欢迎的个性化推荐算法之一[2-3].
协同过滤是利用拥有共同兴趣偏好的群体来为用户推荐感兴趣资源的一种过滤算法,该算法假设推荐系统有m个用户的集合U= {u1,u2,…,um}以及n个资源的集合I= {i1,i2,…,in}.对于推荐系统中的每一位用户ui∈U,记录ui访问过的资源集合Iui= {iui,1,iui,2,…,iui,n|iui,n∈I},Iui⊆I,并且用户ui对集合Iui中的某些或者全部访问过的资源给出表达其对这些资源偏好的反馈信息,推荐系统记录用户对访问过资源的评价信息,构成推荐系统的用户 -资源评价矩阵.对于每一个需要给出个性化推荐资源的用户ua,称之为活动用户.协同过滤算法通过以下两个过程为活动用户推荐其可能最感兴趣的N个资源:
(1)预测:预测一个数值Puaij,该值表示活动用户ua对未曾访问过的资源ij的偏好程度,其中ij∉Iua;
(2)推荐:推荐产生N个资源的集合Iua,r,Iua,r∈I,Iua,r∩Iua= ∅,将这N个用户最感兴趣并且是用户未曾访问过资源推荐给用户ua.
协同过滤个性化推荐通常分为两种[4],即基于用户的以及基于项的.由于具有非常好的扩展性,基于项的协同过滤被更多地用来构建个性化推荐系统.全球最大的电子商务网站Amazon就采用了基于项的协同过滤构建其个性化推荐系统.
但是,无论采用基于项的还是基于用户的协同过滤算法,其推荐准确度都会依赖于用户-资源评价矩阵的稀疏程度,评价矩阵越稀疏则推荐准确度越低[5].现有的缓解用户-资源评价矩阵稀疏问题的方法,如基于资源特征预测填充算法和基于资源访问热度的预测填充算法都存在一些弊端.本文针对上述算法存在的弊端,提出了一种混合加权预测填充算法,该算法以资源访问热度为加权量,将基于资源特征和基于资源访问热度两种算法融合起来,汲取每一种算法的优点,同时有效地规避每一种算法的不足,对用户访问过但是未给出评价值的资源的评分进行预测,并用预测值填充未评价值,以降低用户-资源评价矩阵稀疏程度,提高推荐准确度.
1 混合加权预测填充算法
1.1 现有预测填充算法的不足
基于资源特征的预测填充算法根据人们通常会对具有较高相似性的资源给出较为相似的评价值,通过提取资源在某些特征上的相似度,将最为相似的一些资源的评价值通过调和加权后,作为用户访问过但未给出的评价值.该算法可以有效地降低用户-资源评价矩阵稀疏程度[6],但也存在下述一些缺陷.
(1)未考虑整个用户群体对资源的评价值对该用户产生的主观影响,用户对访问过的资源给出的评价值不仅受用户自身对资源的偏好所决定,还受系统中用户群体对资源的评价影响,而基于资源特征的预测填充算法只考虑了用户对资源的自身偏好因素,未能考虑用户群体的影响因素.
(2)依赖于用户自身对其他资源的访问并给出的评价值,基于资源特征预测填充算法未给出评价值的目标资源与目标用户访问过并且给出评价值的资源的相似度,当用户访问过并且给出的评价值较少的情况,该算法预测出来的评价值会严重地偏离用户可能给出的真实评价值.
(3)资源的特征准确识别并提取困难,系统中的资源具有大量的特征,如何抽取资源合理的特征子集作为计算资源之间的相似度是该算法面临的一个难题.若抽取的特征过多,则会严重影响算法的效率,但是提取的特征数量比较少,则无法表现该类资源在特征上的识别度,造成无法准确地计算资源之间的相似度,并对最终的预测准确度造成严重的影响.
基于资源访问热度的预测填充算法则是从整个用户群体出发,依据资源在整个用户群体中的受欢迎程度预测影响目标用户对该资源的偏好程度.该算法通过统计待预测填充资源在整个群体的访问评价情况,然后将均值加权修正,计算该资源的待预测评价值[7].但是基于资源访问热度的预测填充算法存在一个较为明显的缺陷,即无法满足目标用户的特殊偏好,群体用户都喜欢的资源,该目标用户不一定会喜欢,而群体用户不喜欢的资源,目标用户却可能非常喜欢.
1.2 引入资源访问热度的混合加权预测填充算法
现有的基于资源特征以及基于资源访问热度的预测填充算法,虽然能有效地降低用户评价矩阵的稀疏度,但两种算法都存在明显的缺陷.因此考虑引入一种加权因子,将上述两种算法结合起来,以融合两种算法的优点,同时降低单独一种算法的缺陷.
在协同过滤个性化推荐系统中,用户群体访问资源集合后给出的评价值会形成一个用户-资源评价矩阵,如表1所示.
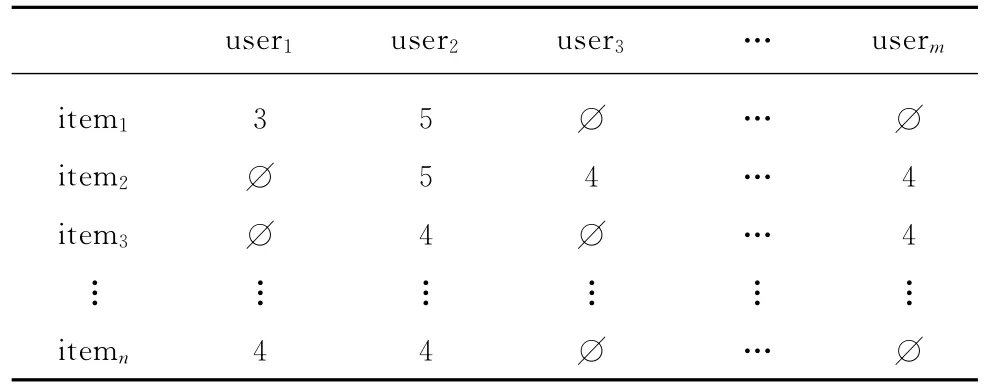
表1 用户-资源评价矩阵Table 1 User-item rating matrix
表1中 ∅表示用户未曾访问某个资源,或者目标用户u访问过资源i但是未给出评价值.资源i为待预测评价值的资源,简称为目标资源,定义资源i的访问热度为该资源在整个群体中被访问次数在整个用户群体中所占的比例,如式(1)所示.
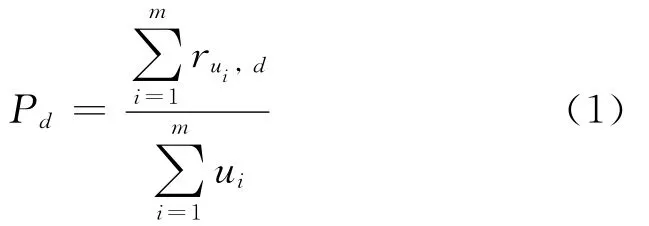
其中:Pd表示目标资源i的访问热度;rui,d表示每个用户访问目标资源的次数;ui表示推荐系统中的每个用户.资源访问热度可以很好地体现目标资源在整个用户群体中的访问特征.
为了克服上述基于资源特征以及基于资源访问热度的预测填充算法所面临的不足,这里引入资源访问热度作为加权因子的混合加权预测填充算法,该算法以资源访问热度为加权值,因此,将基于资源特征预测的评价值和基于资源访问热度预测的填充值结合起来,最终产生对目标资源的预测评价值.
设系统中所有用户集合为U,资源集合为I,目标用户u存在访问过但是未给出评价值的资源i,V表示用户u访问过并且给出评价值的资源集合,定义资源特征集合C={c1,c2,…,cm}.为了计算目标资源i与V中每个资源在特征集C上的相似度,定义欧几里得距离为相似度计算方法,如式(2)所示.
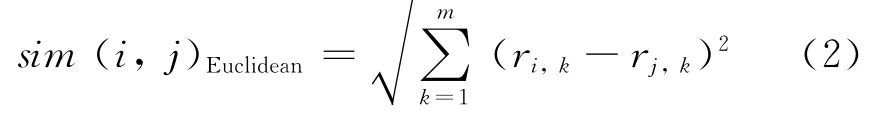
其中:sim(i,j)Euclidean表示资源i和j的特征相似度;ri,,k,rj,k分别表示资源i和j在特征集C上的相应取值.在资源特征向量的相似度基础上,可以通过调和加权方法得到基于资源特征的预测评价填充值[8],如式(3)所示.
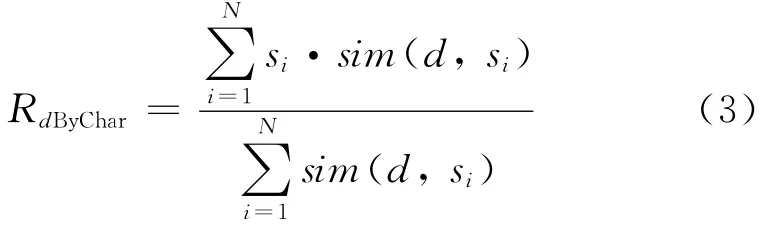
其中:si表示对第i个资源的评价值;sim(d,si)表示待预测填充的资源d与资源i在特征上的相似度;N为目标用户访问过并且给出评价值的资源数量.由式(4)可以得到基于资源访问热度的预测填充值.
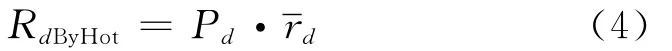
其中:表示待预测资源在整个群体中被访问过并且给出评价值的均值.在得到基于资源特征预测评价值和基于资源访问热度预测评价值的基础上,引入资源访问热度加权因子,由式(5)可以得到最终的混合加权预测评价值.
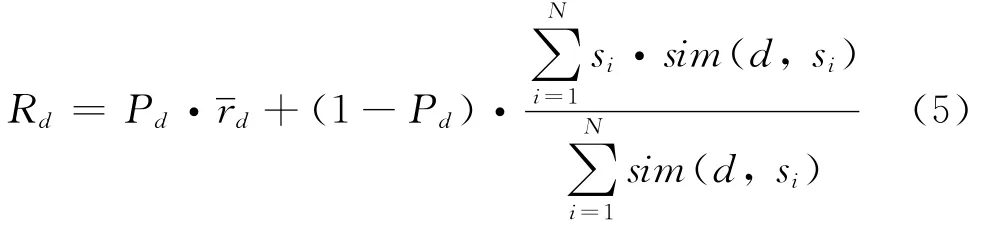
将最终得到的预测值Rd替换目标用户u对资源i的评价值.
1.3 算法描述
根据上述分析,可以得到基于资源特征和基于资源访问热度的混合加权预测填充算法,具体描述如下:


2 试验结果及分析
2.1 试验数据集
本文使用GroupLens提供的MovieLense系统上的10kbytes数据集作为评价算法效果的试验数据集[9],该数据集由943个用户、1 682部电影、共100 000条访问评价记录组成.每个访问记录由4个字段组成(uid,mid,rt,dt),其中uid表示用户标识符,mid表示电影标识符,rt表示用户uid对电影mid的评价值,其值范围为[1,5],dt表示Unix时间戳.抽取每部电影的发行日期、电影类型、发行国家、发行语言等信息作为每一部电影的特征向量.
本文把100 000记录分为训练集和测试集,其中随机将每个用户访问的15条记录单独保存起来作为测试集,剩下的记录作为训练集,用来检验采用混合加权算法对推荐质量的提升程度.
2.2 评价标准
用信息检索领域评估系统效果的准确度作为评价标准[10],如式(6)所示.

其中:H为推荐命中的数量;N为推荐的数量.
2.3 试验结果和分析
为了比较基于资源特征预测填充的和无预测填充的基于项的协同过滤算法,在不同的用户-资源评价矩阵稀疏程度下的推荐准确度,本文采用矩阵稀疏度来衡量用户-资源评价稀疏程度,如式(7)所示.

其中:L表示评价矩阵稀疏度;rs表示推荐系统中目标用户访问过某个资源并且给出的评价值;Z表示推荐系统中所有用户数量;X表示推荐系统中所有不重复资源的数量.L越小表示稀疏程度越高.试验将训练集分别设置用户评价矩阵稀疏度为0.41%,1.41%,2.41%,3.41%,4.41%,设计了 4 组试验,分别采用无预测填充、基于资源访问热度的预测填充、基于资源特征预测填充和混合加权预测填充的评价矩阵,然后采用传统的基于项的协同过滤算法进行推荐,比较4种情况的推荐效果,试验结果如图1所示.
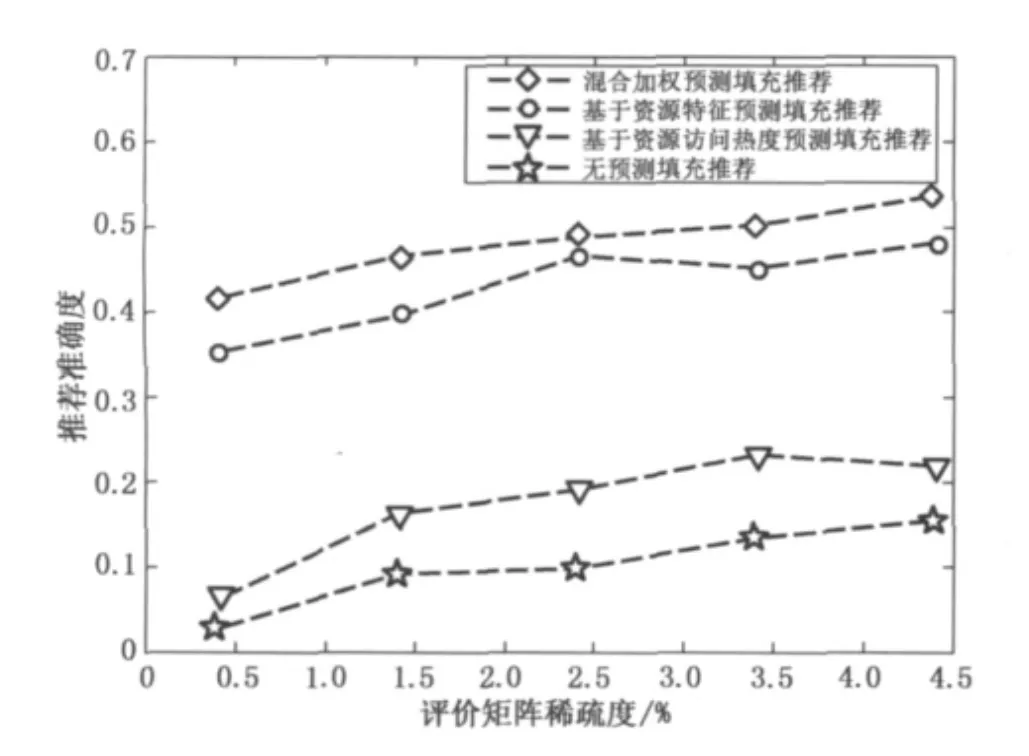
图1 4种推荐准确度对比效果Fig.1 Comparison effect of four kinds of recommendation accuracy
从图1可以看出,无预测填充的基于项的协同过滤推荐曲线随着矩阵稀疏程度不同,推荐准确度也随之改变,评价矩阵稀疏度越小,则推荐准确度越低.基于资源访问热度预测填充算法无法解决用户特殊偏好问题,虽然能够提高评价矩阵稀疏度,但是与无预测填充的基于项的协同过滤相比,推荐准确度未见明显提高.基于资源特征的预测填充算法能够很好地根据资源自身的客观属性对稀疏矩阵进行预测填充,效果比基于资源访问热度的预测填充算法好,但是它只考虑资源本身的客观属性,没能考虑人类随众心里以及整个用户群体行为对个体行为的影响.混合加权预测填充算法能够很好地融合基于资源特征和基于资源访问热度预测填充算法的优点,并且也可以弥补两者之间的不足,使得混合加权预测填充得到的推荐准确度要高于基于资源特征和基于资源访问热度的推荐准确度.与此同时,混合加权预测填充与无预测填充的推荐结果相比,在不同的评价矩阵稀疏程度下,推荐准确度平均提升39%.因混合加权预测填充算法具有较好的客观性,可以在一定程度上修正用户由于心情好坏等主观情绪对给出评价值的影响,使得预测的填充值更加符合用户真实的客观评价值,进一步地提高最终个性化推荐的准确度.特别是在评价矩阵严重稀疏的情况,采用混合加权预测填充算法能够提供很好的初始推荐准确度,一定程度上缓解了采用协同过滤算法构建的个性化推荐中冷启动问题.
3 结 语
本文针对在基于项的协同过滤推荐算法中,因数据稀疏严重降低推荐准确度的问题,将基于资源特征预测填充和基于资源访问热度预测填充算法有机地结合起来,形成混合加权预测填充算法.经试验表明,该算法能够有效预测用户访问过但是未曾评价的资源的评价值,并采用此值对缺失值进行填充,降低用户-资源评价矩阵的稀疏度,另外,基于协同过滤算法构建的推荐系统在经过混合加权预测填充算法对评价矩阵进行填充后,通常能够获得更好的推荐效果.但是该算法的时间复杂度高,还可以通过进一步优化来提高算法的效率,并且基于资源特征预测依赖资源自身的特征区分度,如何选择合适的特征也是下一步需要研究的问题.
参 考 文 献
[1]ADOMAVICIOUS G,TUZHILIN A.Towards the next generation of recommender systems:A survey of the state-ofthe-art and possible extensions[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(6):734-749.
[2]SU X Y,TAGHI M K.A Survey of collaborative filtering techniques[J].Advances in Artificial Intelligence,2009,Article ID 421425,1-19.
[3]邢春晓,高凤荣,战思南,等.适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,2007,44(2):296-301.
[4]SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based collaborative filtering recommendation algorithms [C]//Proceedings of the 10th International Conference on World Wide Web.Hong Kong,China,2001:285-295.
[5]吴颜,沈洁,顾天竺,等.协同过滤推荐系统中数据稀疏问题的解决[J].计算机应用研究,2007,24(6):94-97.
[6]LIU Z B,WANG H,QU W Y,et al.Sparse matrix prediction filling in collaborative filtering [C]//IEEE International Conferece on Scalable Computing and Communications:The Eighth International Conference on Embedded Computing.2009:304-307.
[7]MA H,KING I,LYU M R.Effective missing data prediction for collaborative filtering[C]//Proceeding of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.2007:39-46.
[8]SEGARAN T.Programming collective intelligence [M].Sebastopol:O'Reilly,2009.
[9]Group Lense Research.Project MoiveLense[EB/OL](2007-05-01)[2011-09-15].http://www.grouplens.org/.
[10]刘建国,周涛,郭强,等.个性化推荐系统评价方法综述[J].复杂系统与复杂性科学,2009,6(3):1-10.
An Effective Algorithm for Relieving Sparse Data in Collaborative Filtering Recommendation
HUANGYong-feng,QINLuo-chun
(School of Computer Science and Technology,Donghua University,Shanghai 201620,China)
Personalized recommendation system based on collaborative filtering often faces the data sparsity which seriously reduces the recommendation accuracy.An efficient hybrid weighted prediction algorithm is presented,which predicts the data visited but not rated by the characteristics and the access frequency,and fills the user-item matrix with the predictions.In this way,the sparsity of the user-item matrix is reduced,and the accuracy of recommendation is improved accordingly.Experimental results on MoiveLense data set clearly indicate that the algorithm can significantly improve the recommendation accuracy.
personalized recommendation;collaborative filtering;data sparsity;prediction filling;item characteristic
TP 274+.5
A
1671-0444(2013)01-0083-05
2011-10-28
国家自然科学基金资助项目(30770589);中央高校基本科研业务费专项资金资助项目(2011D11206)
黄永锋(1971—),男,山东泰安人,副教授,博士,研究方向为数据挖掘、机器学习和模式识别.E-mail:yfhuang@dhu.edu.cn
