散乱点云线性八叉树结构在GPU中的实现
2013-09-12徐万银刘胜兰
徐万银,刘胜兰
(南京航空航天大学机电学院,江苏南京 210016)
散乱点云线性八叉树结构在GPU中的实现
徐万银,刘胜兰
(南京航空航天大学机电学院,江苏南京 210016)
为快速建立散乱点云的空间邻接关系,研究了更快速构建线性八叉树。采用Morton码描述八叉树的节点,并按照层次顺序对叶节点进行遍历,通过建立两个查询表,实现对节点相邻信息的快速查询。算法利用了GPU架构的并行度,实验表明,该算法有较高的效率。
八叉树;Morton码;并行算法;GPU
八叉树数据结构以其结构简单、易于遍历、算法实现方便成为建立散乱点云的空间邻近关系,是近年来科研人员研究的热点。其实现方式主要有指针八叉树、线性八叉树。指针八叉树采用一组指针来记录节点父子之间的关系,由于指针高效的随机访问特性,用这种方式查询效率高,但需要大量的指针存储空间。线性八叉树只保存叶节点的空间位置和属性,其中空间位置通过编码来表示。查询过程就是对编码的遍历和比较[1],查询效率较低,但结构更紧凑,可以直接访问任一叶节点。
随着图形处理器(GPU)性能的大幅度提高,使得GPU的应用受到研究人员的关注。指针八叉树中的指针,在GPU中用父节点对子节点的索引来记录指针,利用GPU中的纹理存储器来存储这些索引[2],实现八叉树的构建。线性八叉树在GPU中实现的关键是如何编码以及对节点进行访问,利用Morton码实现完全在GPU中构建并遍历八叉树[3],在GPU中创建八叉树的节点、边、面等信息[4],并将其应用于散乱数据的曲面重建。
本文研究一种线性八叉树在GPU中的实现方法,通过与CPU算法的比较可知,本文利用GPU大大加快了八叉树建立,提高了查询的效率。
1 线性八叉树的GPU实现
本文建立的线性八叉树算法流程主要包括2个步骤(如图1所示):
a.对数据点进行Morton编码,包括输入散乱点云,根据数据点云获得包围盒,并行计算每个点的Morton码3个部分。
b.节点数组创建,包括排序 Morton码,压缩Morton码,扩充八叉树节点,生成每层节点数组和生成邻节点算法。
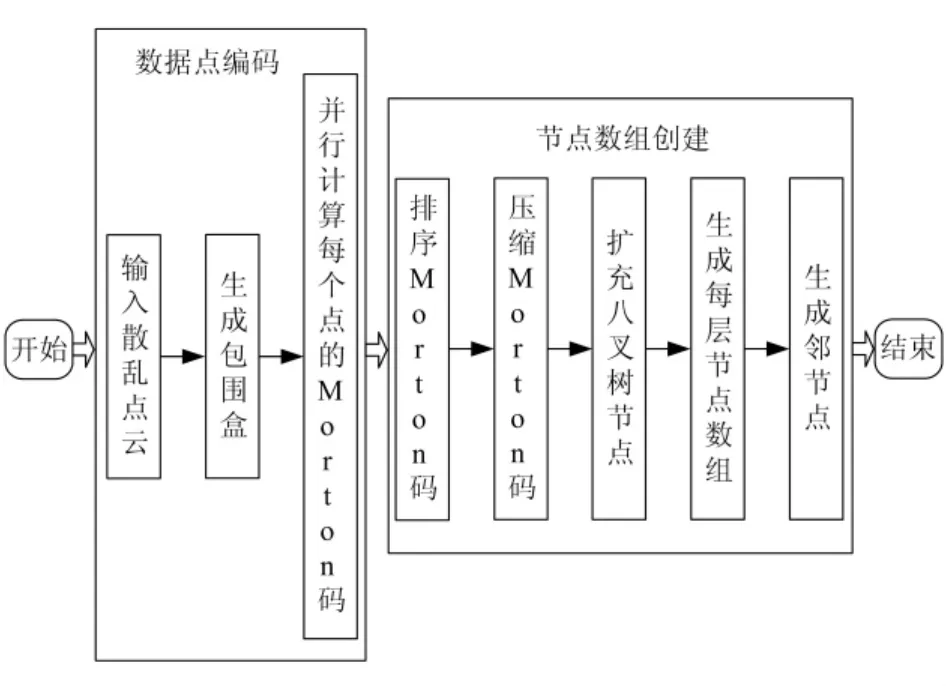
图1 线性八叉树算法流程图
1.1 数据点编码
Morton码是一种实现多维数据到一维映射的有效方法,它通过交叉存储多个维数的位产生一个数。本文中将深度为M层的八叉树节点的Morton码记为:x1y1z1x2y2z2…xMyMzM。深度为M层的八叉树Morton码有3M位,本文中规定Morton码是32位的,因此可表示的八叉树的最大深度为10,其中未用到的位(31,32位)设为0。
采样点v在m(1≤m≤M)层的x位的值按如下公式计算:其中cm是点v所在的(m-1)层的节点的中心,xm即是m层中x的状态值,y位和z位在m层的状态值即ym,zm也可以按上述方法同样计算得到。
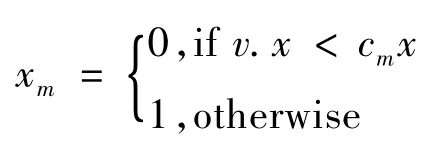
采用并行方法计算Morton码,首先计算第一层节点的中心,直至第M层的中心,其中第一层节点中心可根据包围盒的大小来计算,具体算法流程为:

1.2 节点数组创建
1.2.1 节点数据结构
节点是八叉树结构中的基本元素,每个节点(记为t)中包含以下信息:该节点的Morton码,节点的索引号,节点中包含的采样点数量,首个采样点的索引,节点的父节点、子节点和邻节点。这样就能通过某数据点所在节点,查询其父节点、子节点和邻节点中的数据点,从而建立散乱无序点云间的拓扑关系。
节点的数据结构为:

1.2.2 创建每层节点数组
a.Morton码排序并去除冗余。
根据散落无序的采样点获得的Morton码是无序的。本文利用 sort[5]将Morton码按从小到大顺序排序,并重新生成数据点顺序。对重复的Morton码进行压缩,生成节点数组 UniqueNode。在UniqueNode结构中记录了每个节点所包含的点云个数,同时也保存了每个节点中第一个点在点数组中的索引。
b.扩充八叉树节点。
八叉树中每个节点有0个或8个子节点,因此需要对UniqueNode中某些节点进行扩充,保证已有Morton码节点的父节点有8个子节点。利用scan[6]算法得到对应的节点地址数组nodeaddress。
c.生成每层的节点数组OctreeNode。
算出扩充后新增节点的Morton码,将这些节点的ptnumbers设为0。通过 nodeaddress和3位xMyMzM的Morton码定位UniqueNode中的每个节点在OctreeNodeM中的对应元素。
根据第M层节点数组,依次建(M-1)层,直至第一层节点数组。在OctreeNodeM中,将每个节点Morton码中xMyMzM位设为000,即生成(M -1)层节点的Morton码。如同第二步那样扩充节点,最终生成OctreeNodeM-1。按相同方式依次建立其他层节点数组,直至第一层。根据每层的UniqueNode可以推算出每层节点的父节点、子节点的索引。所有层的节点数组组成整个的节点数组OctreeNode。
1.2.3 生成邻节点
对于节点数组OctreeNode,还需要知道每个节点的26个相邻节点,这26个节点分布在同一父节点的子节点和与其父节点相邻的子节点中。本文事先建立两个查找表来加速邻近节点的计算。现将两个查找表定义如下。
父表:父表Tableparent为二维数组,表示邻节点的父节点在当前节点的父节点中的相对索引。对当前节点t,其父节点为p,如果t的索引在p.children是 i,则节点 t的第 j个邻节点 t.neighs[j]的父节点索引在 p.neighs是 Tableparent[i][j]。
子表:子表Tablechild为二维数组,表示邻节点在该邻节点父节点中的索引。对当前节点t,其父节点为 p,如果t的索引在p.children是i,节点t的第j个邻节点 t.neighs[j] 的父节点为 h ,则 t.neighs[j]在 h.children 中 的 索 引 是Tablechild[i][j]。
子表和父表的数组大小均为8×27,Tableparent[8][27]、Tablechild[8][27]如图 2 所示。
计算节点的邻节点时,采用从根部开始逐层遍历的方式遍历八叉树,如果节点t的第j个邻节点不存在,将 t.neighs[j]设为 -1。
2 实验结果
将本文的线性八叉树算法在环境为Visual Studio 2008,CPU 为奔腾 Dual-Core 2.5GHz,显卡为NVDIA GeForce 9500GT机器上进行实验。图3所示为各模型构建好的八叉树图。将本文的算法与CPU自适应的八叉树算法[7]进行比较,该算法在CPU上属于特别高效的方法,与CPU的高效算法相比(见表1),从表1中可知,算法效率至少提高了50%。因此,本文的八叉树构建算法是解决海量点云存储问题的有效方法。

图2 八叉树的父表和子表

图3 八叉树构建图
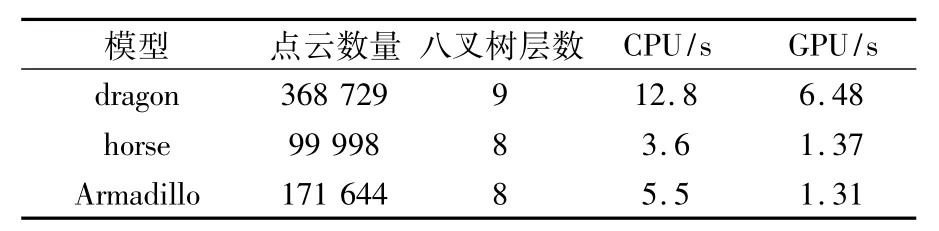
表1 GPU八叉树和CPU八叉树算法时间
3 结束语
本文在GPU上实现了用Morton码创建线性八叉树。实验表明,在GPU上构建的线性八叉树,在效率方面相对CPU而言确实有较大的提高,在某种程度上反映了GPU硬件平台进行并行运算的优越性。因此对于数据量大的算法可考虑在GPU硬件平台上实现,但对于GPU运算能力来说,本文八叉树构建时间稍有点长,可考虑进一步挖掘GPU的并行性,更高效地构建八叉树。
[1]Choi M,Ju E G,Chang J,et al.Linkless octree usingm multilevel perfect hashing[J].Pacific Graphics,2009,28(7):1773-1780.
[2]Benson D,Davis J.Octree textures[J].ACM Transactions on Graphics,2002,21(3):785 -790.
[3]Jeroen B,Evghenii G,Simon P .A sparse octree gravitational N-body code that runs entirely on the GPU processor[J].Journal of Computational Physics,2012,231(7):2825 -2839.
[4]Zhou K,Gong M M,Huang X,et al.Data-parallel octrees for surface reconstruction[J].IEEE Transactions on Visualization and Computer Graphics,2011,17(5):669 -681.
[5]Harris M,Owens J,Sengupta S,et al.CUDA Data Parallel Primitives Library[EB/OL].[2012 -03 -14].http://code.google.com/p/cudpp/.
[6]Sengupta S,Harris M.Scan primitives for GPU computing[C]//GH'07:Proceedings of THE 22ndACM SIGGRAPH/EURGRAPHICS Symposium on Graphics Hardware.Aire-la-Ville(Switzerland)Eurographics Association for computer graphics,2007:97 -106.
[7]Kazhdan M,Bolitho M,Hoppe H.Poisson surface reconstruction[C].//SGP'06:Proceedings of the 4thEurographics Symposium on Geometry Processing.Aire-la-Ville(Switzerland):Eurographics Association,2006:61 -70.
Realization of linear octree for scattered point cloud on GPU
XU Wanyin,LIU Shenglan
(Nanjing University of Aeronautics& Astronautics,Jiangsu Nanjing,210016,China)
In this paper a kind of linear GPU octree is proposed to establish scattered point cloud space adjacent relation fastly.The linear GPU octree uses Morton code for descripting octree node.Moreover,the leaf node are traversed with the hierarchy sequence and two luts are established to query adjacent nodes quickly.The algorithm makes full use of parallelism of GPU structure,which experiments show that,the new algorithm has higher efficiency.
Octree;Morton code;Parallel algorithm;GPU
TP391
A
2095-509X(2013)04-0005-03
10.3969/j.issn.2095 -509X.2013.04.002
2013-01-06
徐万银(1989—),女,江苏盐城人,南京航空航天大学硕士研究生,主要研究方向为CAD/CAM。
