Hadoop中任务调度算法的改进
2012-09-26苏小会何婧媛
苏小会,何婧媛
(西安工业大学 计算机科学与工程学院,陕西 西安 710032)
云计算技术发展到现在,已经出现了很多云计算的软件平台,但是功能强、性能稳定的基本都是商业软件,目前只有Hadoop是可实现大规模分布式计算的开源软件平台[1],因此对于Hadoop的应用和研究也最多。
Hadoop旨在构建一个具有高可靠性和良好扩展性的分布式系统,在很多大型网站上都已经得到了应用,可以说是目前最为广泛应用的开源云计算软件平台[1]。Hadoop有以下优点:扩容能力强、成本低廉、效率高、高可靠性、免费开源及良好的可移植性。
Hadoop0.20.0中的任务调度算法包括FIFO调度算法(First In First Out)、公平调度算法(Fair Scheduler)和计算能力调度算法(Capacity Scheduler)。FIFO算法的整体性能和系统资源的利用率不高;公平调度算法负载不均衡,系统的响应时间长,配置文件的好坏影响整个系统的性能;计算能力调度算法中队列设置和队列组无法自动进行从而影响系统整体性能的提高。因此对于Hadoop中任务调度算法的改进和优化一直就没有停息,文中根据对任务执行过程的实时监控,依据任务执行结果放的反馈,动态调整后续任务的分配和执行,在现有任务调度算法的基础上提出一种基于改进遗传算法(IGA)的任务调度算法,该算法最大特点是利用遗传算法的群体搜索技术使得群体进化到包含或接近最优解,从而解决现有任务调度算法收敛速度慢、任务完成时间长、负载不均、资源利用率低、系统整体性能低等缺点。
1 问题分析
任务调度算法作为Hadoop平台的核心技术之一,直接关系到Hadoop平台的整体性能和对系统资源的利用,本文的研究目标是改进和完善任务调度算法以提高平台的整体性能和系统资源使用率。
1.1 Hadoop中的任务调度算法
Hadoop的MapReduce任务调度[2]是一个主动请求的任务,其任务请求调度过程如图1所示。slave的SubTaskTracker主动向master的TaskTracker请求任务,当SubTaskTracker接到任务后,通过自身调度在本slave建立起SubTask,执行任务。
这个过程可以简单地概括为以下4个步骤:
1)TaskClient提交任务;
2)TaskTracker接收任务生成子任务;
3)SubTaskTracker申请子任务;
4)TaskTracker分配并监控子任务。
对Hadoop中调度算法的改进也已经有很多研究,文献[3]中作者提出了一种基于朴素贝叶斯分类的作业调度算法。改进遗传算法的并行任务调度[4]中提出了一种基于改进遗传算法的并行任务调度算法。文献 [5]中HP实验室开发的Dynamic Priority schedule调度,允许用户不断地增加或更改他们的队列优先顺序来满足当前负载的需要。文献[6]中介绍了延迟调度并提出了一种基于特征加权的朴素贝叶斯分类器算法来解决公平调度算法中需要对队列和资源池进行资源配置的问题,

图1 Hadoop的任务请求调度过程示意图Fig.1 Process schematic diagram of the task request scheduling in hadoop
1.2 问题分析
Hadoop0.20.0中公平调度算法和计算能力调度算法都需要在分配任务资源之前进行一些配置工作,比如管理员需要对SubTaskTracker上可以同时运行的最大子任务数进行正确设置。但要准确设置最大子任务数,需要管理员深入掌握Hadoop平台上运行的MapReduce任务和SubTaskTracker两者各自资源使用特点。公平调度算法和计算能力调度算法虽然比FIFO调度算法有很大程度上的提高,但仍然需要预先设置任务池和用户池的容量或是权重,实际操作中遇到多用户、多任务情况下预先设置任务池和用户池的容量或是权重难度很大。
文中研究不预先设置最大子任务数以及任务池和用户池的容量或是权重,而对任务执行过程进行实时监控,根据任务执行结果的反馈,对后续任务进行动态调度,在现有任务调度算法的基础上对最大子任务数以及任务池和用户池的容量或是权重的取值使用遗传算法进行动态计算,得到最佳取值后再应用公平调度算法或者计算能力调度算法进行调度。IGA任务调度算法试图做出以下一些改进:
1)对遗传算法的初始种群生成方式进行改进,以达到减少迭代次数,并提高运行速度的目的;
2)用两个适应度来选择种群,以便达到总任务的完成时间和任务平均所用时间都较短的目的;
3)在选择、交叉、变异等遗传操作过程中,有可能会破坏当前种群中适应度最高的个体,加入最优保留策略来更好的对种群进行优胜劣汰以提高算法的收敛精度;
4)采用规则约束的交叉和变异操作以提高个体质量;
5)引入加速进化策略以避免早熟而使得算法停滞的问题。
2 基于改进遗传算法的设计
2.1 初始种群生成
基于均匀分布策略的初始种群生成方式可以保证随机产生的个体间有明显的差异,使它们比较均匀地分布在解空间上,保证初始种群有较丰富的模式,从而提高搜索收敛于全局最优解的可能,再进行几代进化,使得种群中解的质量逐渐提高,然后通过寻找提交给遗传算法的任务间的相似性,重复使用先前相似任务的解决方案作为当前任务的种群染色体个体,以此来形成当前任务的初始种群,从总体上减少总的进化次数。IGA的初始种群采用基于均匀分布策略通过随机方式产生整个算法的第一代种群,以保证有足够的个体差异性。
为实现改进遗传算法的初始种群选择性建立问题,本文引入一个历史表用来存储对任务的描述和对应的调度方案。
定义1:任务的描述是任务在资源上执行时间的矩阵ETC[i,j],ETC矩阵表示各个子任务在每个资源上执行时间,ETC[i,j]表示第i个子任务在第j个资源上执行完成所需要的时间。
定义2:不同样本之间的相似性度量(Similarity Measurement)通常采用计算样本间“距离”(Distance) 的方法,任务的相似性判断可以通过输入任务的期望执行时间矩阵ETC与表中存储的历史任务执行时间矩阵计算得到,两个含有k个元素的向量 a(x11,x12,…,x1k)与 b(x21,x22,…,x2k),则两向量的相似性可由下式得出:

2.2 最优保留策略
最优保留策略,即在群体交叉、变异之前,先选出本代适应度最高的两个个体进行保留,不参加选择、交叉、变异等遗传操作。而等本代个体完成遗传操作之后,用先前保留的两个个体与完成遗传操作的种群中适应度最小的两个个体进行替换,这使得种群更好的进化,提高了优胜劣汰的质量。
2.3 规则约束的交叉和变异操作
交叉将选中个体的基因进行交叉,从而生成包含更优良结构的新个体。交叉操作在解空间中进行有效的搜索,同时降低对有效模式的破坏概率。变异随机地改变选中个体串结构数据中某个串的值来产生新个体,以改善算法的局部搜索能力并维持种群多样性。由于目前云计算中任务调度的特点,传统的单点、多点和顺序等交叉变异方法不再适用,所以本文采用规则约束的交叉和变异操作。
假设a和b是进行交叉操作的两个个体,则根据以下规则进行交叉:任意将a和b中的一个或者多个串值进行对换,且对换的串值最好是不同的。
变异操作针对选中个体的串结构数据,任意选择n个串中的一个或者多个根据以下规则进行变异:
1)将该串值变异为串结构数据中任意的一个值;
2)将任意串移动到距其所在串结构的前一不同串值的任意位置。
2.4 加速进化策略
算法后期的种群中容易导致早熟局部收敛,为了避免早熟而使得算法停滞的问题,本文引入了加速进化策略,即在检测到算法的早熟指标Dp≤$后,则将交叉和变异的概率均临时性的提高k倍,文中将k取值为10,以保证在加速进化后的交叉和变异概率达到100%;当早熟指标Dp>$后,又将交叉和变异的概率恢复正常。其中$为早熟判断门限值,其值由求解中某代个体平均适应度的量级确定,即1×10x。若50个任务,由平均适应度的量级确定x=-2,则$=0.01。

其中,fmax表示本代个体最大适应度值,fmin表示本代个体最小适应度值,favg表示本代个体平均适应度值。
3 基于改进遗传算法的实现
3.1 算法流程
根据第2节的描述,算法的求解过程如下:
1)初始化控制参数;
2)对基因进行编码,并随机产生初始种群;
3)评价群体中每个个体的适应度函数值;
4)选出适应度最高的个体进行保留;
5)根据定义的遗传算子,分别对种群进行选择、交叉、变异操作,产生下一代子群;
6)将保留的个体与新种群中适应度最小的个体进行替换;
7)根据加速进化策略对种群进行进化;
8)若满足收敛条件,返回最优解,结束算法;否则,返回到步骤 3)。
根据上述描述,可以得到基于IGA的任务调度算法流程图如图2所示。
3.2 算法实现
根据3.1节给出的算法流程图,将基于IGA的任务调度算法的过程概括如下:
1)客户端提交MapReduee任务;
2)初始化任务,创建运行子任务列表;

图2 基于IGA的任务调度算法流程图Fig.2 Flow chart of the task scheduling algorithm based on IGA
3)SubTaskTraeker空闲时, 主动发出心跳请求TaskTraeker分配任务;
4)TaskTracker采用基于IGA的任务调度算法选择一个最优的任务;
5)选择该任务的一个子任务分配给发送心跳请求的SubTaskTracker;
6)SubTaskTracker被分配了子任务后开始运行子任务,子任务完成时告知TaskTracker;
7)TaskTracker在接到子任务完成的通知后,把任务的状态设置为“成功”,并显示一条消息告诉用户。
3.3 实验验证
由于实验条件有限,本实验平台是由3台机器构成的集群,其中一台作为 Master,负责 NameNode和 TaskTracker的工作,另两台作为Slave,负责DataNode和SubTaskTracker的工作。每台实验机器上均运行Ubuntu 10.10系统,java版本1.6,Hadoop版本0.20.2。实验中的三台机器分别设置主机名为 hadoop1、hadoop2、hadoop3,其中 hadoop1 为 Master,其他为Slave,图3为Hadoop平台结构示意图,具体配置过程简单概括为以下3步:

图3 Hadoop平台结构示意图Fig.3 Schematic diagram of the Hadoop platform
1)下载 Linux环境下的 JDK安装包 jdk-6u27-linuxi586.bin进行安装,并配置环境变量。
2)配置SSH及无密码登陆本机
3)安装并配置Hadoop:
使用前面搭建的Hadoop集群来评估算法的性能。将本文提出的IGA任务调度算法与Hadoop平台现有的3种算法进行性能比较实验,选取同一个任务,每次用不同的算法运行这个任务,总共运行10次,记录每次算法运行的时间。初始条件:任务数量为50;收敛条件:1)达到最大进化代数MaxGen(这里取 MaxGen=100);2)如果连续 50代总任务完成时间和任务平均完成时间都没有变化,认为算法基本收敛,终止算法。在生成初始种群时若相似度Simlarity(a,b)的取值大于或等于0.75就认为任务a和b相似。实验参数如表1所示。

表1 实验主要参数Tab.1 Test main parameters of experiment
要将调度算法从Hadoop平台现有的调度算法配置为本文IGA任务调度算法,需要将已经编写好的IGA任务调度程序拷贝到Hadoop_Home/lib下,然后在Hadoop中修改配置文件并加入IGA任务调度模块,最后检查调度算法是否运行。对实验结果进行分析后得到图4。
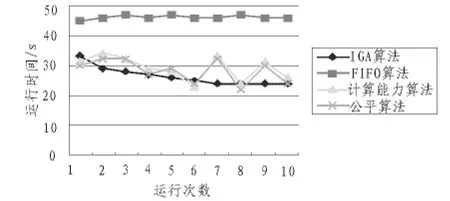
图4 性能比较实验Fig.4 Performance comparison test
由上图可知,FIFO算法的运行时间最长,且效率低,但是运行时间比较稳定。公平算法和计算能力算法随着SubTaskTracker上最多可同时运行的子任务数以及任务池或者任务队列的设置不同而存在较大的波动。总的来说公平调度算法和计算能力调度算法的运行时间是低于IGA算法的。本文提出的IGA算法虽存在波动,但是运行几次后算法开始收敛并趋于稳定。
4 结 论
文中通过对Hadoop现有调度算法和IGA任务调度算法的性能比较实验可知,IGA任务调度算法的性能比FIFO算法要高的多,相对公平算法和计算能力算法存在着优势,不仅提供非常不错的性能同时减轻了管理员和用户的负担、提高了管理效率。通过仿真实验也表明IGA算法可以对Hadoop下编程模式实现较为理想的任务调度,满足了实际操作中多用户、多任务的需求动态变化,解决了公平调度算法和计算能力调度算法中预先设置困难的问题,使得改进的任务调度算法迭代次数少、收敛速度快、任务完成时间少、负载均衡、资源利用率高、系统整体性能高,是一种有效的任务调度算法。
[1]Hadoop[EB/OL].(2011-04-16)http://www.Hadoop.org.
[2]宋坤芳.基于蚁群算法的云计算资源调度策略研究[D].武汉:武汉纺织大学,2011.
[3]夏袆.Hadoop平台下的作业调度算法研究与改进 [D].广州:华南理工大学,2010.
[4]袁雪莉,钟明洋.改进遗传算法的并行任务调度[J].计算机工程与应用,2011,47(10) :56-59.
YUAN Xue-li,ZHONG Ming-yang.Parallel task scheduling algorithm using improved genetic algorithm[J].Computer Engineering and Applications,2011,47(10):56-59.
[5]Sandholm T,Lai K.Dynamic proportional share scheduling in Hadoop[J].In:Springer:2010:110-131.
[6]余正祥.基于hadoop平台作业调度算法研究[D].昆明:云南大学,2011.
