概念图构建中概念术语自动提取的研究与实现
2012-07-25孙珠婷顾倩颐
孙珠婷,顾倩颐,2+
(1.四川师范大学 计算机科学学院,四川 成都610101;2.可视化计算与虚拟现实四川省重点实验室,四川 成都610068)
0 引 言
概念图作为一种知识表示和知识组织的工具已经应用到商业、政府、国防等方面,并被引入到知识管理领域,用以支持知识提取、知识组织、知识评价等活动的完成[1-2]。概念图的构建主要包括领域概念术语的自动化提取、概念关系的自动抽取。因此,概念术语的自动提取是概念图构建的基础,并且该提取的准确率直接影响了概念关系的确定。目前,概念术语的提取往往是由领域专家或相关研究人员手工构建完成,显然这种通过人工提取概念术语的方式存在着一定的局限性:建立一个准确、完整的领域概念图必须由该知识领域的教学专家们投入大量的时间和精力来完成概念的提取。
当前,网络资源因其丰富、实时及便捷的特性已使其成为人们获取信息的主要来源。因此,如何降低概念图构建过程中的人力复杂度,从网络资源中自动挖掘各领域概念术语,并提高其准确度已经成为人们迫切需要解决的问题。
1 相关研究
目前国内一些学者对于概念图的构建已提出各自的方法。并在一定程度上缓解概念图的手工构建问题。如Chen等运用文本挖掘技术从文献中自动生成了电子学习领域的概念图[3],其中概念来源于文献的关键词。该方法存在两个问题,一是仅得到电子学习该领域的概念术语,不能用于获取其它领域概念术语,导致概念图的构建存在领域固定化;二是由于文献中的关键词往往带有作者的主观性,并非都是概念术语。张会平等在构建概念图过程中概念术语来源于文献数据库中频率最高的关键词[4],由于该方法没有过滤概念术语中的同义词、多义词,因而容易出现概念冗余现象。并且文献数据库是通过人工获取。吴江宁等在提出基于主题地图的多层次文献组织模型 (TMDOM)的过程中,概念术语则需要手动给出[5]。
根据笔者收集的文献来看,领域概念术语的提取主要存在两个问题:一是仅提取某领域概念术语,且大多来源于人工获取的文献数据库;二是领域概念术语的提取过于粗糙导致存在冗余概念。容易导致概念关系确定时出现冗余及混乱的现象。基于此,本文利用网络爬虫技术爬取指定领域学科站点下的大量文本资源,提取特征项并运用潜在语义潜在语义分析(LSA)挖掘出特征项与文本之间的潜在语义结构,同时消除噪音和冗余数据,并提高概念术语提取的准确率。
2 概念术语提取方法
结合网络爬虫技术和LSA的领域概念术语自动提取分为4个步骤:①利用网络爬虫技术获取领域文本资源;②文本预处理;③特征项提取;④概念术语挖掘,利用LSA提取无冗余且更准确的概念术语。如图1所示。

图1 概念术语提取流程
2.1 领域文本资源获取
2.1.1 指定站点资源链接获取
通过调研的方式获取某学科领域的专业网站网址,通过调用Jsoup包解析并实现爬取指定站点 (可多个站点)中指定深度的链接。
2.1.2 解析所有获取的链接当中的正文
采用DOM[6]树解析模式,利用超链接密度法为主要判断依据的标记窗算法。具体步骤如下:
步骤1 解析出符合HTML语法规则的字符串,使用其构造一个w3c的Document对象,并利用该对象构造一个文本抽取器。
步骤2 运用该文本抽取器寻找对该网页贡献最大 (权重最大)的节点标签。
定义1tT为HTML全文的纯文本长度,tA为超链接文字数,tI为总信息节点个数,t为该标签节点包含有效文本长度,at为锚文本长度,i为信息节点个数。w为该标签节点的权重,其权重计算公式可表示为式 (1),且表1为各个变量及函数的说明


表1 各变量及函数说明
步骤3 构造一个段落分解器。
定义2 段落是介于篇章和句子之间的文字块,每个文字块因为对文档的贡献不同而可以被赋予不同的值,称之为权重。
定义3 M为权重最大的标签的半HTML文本,T为全文的半HTML文本。以M为中心,把T分成三段A、M及B,其基准分依次为0.1、0.3及0.1,通过分解T的每一行,并把残存的视觉标签转化成得分,累加到主题的分里,合并权重相同的段落。最后选取权重大于一定阀值的段落合并形成该网页的正文,阀值一般取0.2或0.3。用户可根据不同网站选择不同阀值,获取相对准确的网页正文。
2.2 文本预处理及特征项提取
本文采用中国科学院计算技术的汉语词法分析系统ICTCLAS进行无词典分词。并把相邻且共现频率高的被切分的词汇重新合并成新词[7],词性设为new。过滤并保留名词、动词及词性为new的新词。接着,采用TFIDF[8]算法进行特征项提取。
2.3 概念术语提取
以往的研究表明,粗糙地以特征项表示概念术语往往出现准确率不高和冗余概念等问题。基于此,本文运用LSA方法对特征项进行去噪除杂,提取概念术语。LSA的基础是向量空间模型,即LSA是VSM的一种扩展。
2.3.1 向量空间模型 (VSM)[9]
VSM是把文本内容简化为特征项及其权重的向量表示。
定义4D为一领域文本集,则F(Di)= (Wi1,Wi1,…,Wim)称为文本i中的特征向量,Wij表示第i个特征项在Dj中的权重值。
定义5T为D的特征项集,若ti∈T(1≤i≤m),dj∈D(1≤j≤n),则VSM矩阵可表示为Vm×n=Wij。
2.3.2 潜在语义分析 (LSA)
LSA的基础是Vm×n。将该矩阵进行奇异值分解,得到潜在语义结构模型[10]。如图2所示。

图2 三维-潜在语义分析空间示例[10]
上图可知LSA把特征项和文本以向量的形式处于同一空间用于计算它们之间的相关性。
下面讨论LSA进行奇异值分解过程:
对于任何一个矩阵X,如特征项/文本矩阵,都可以分解为式 (2)
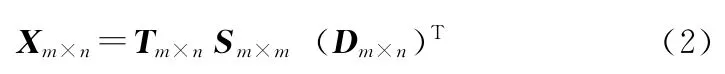
T和S分别是X的奇异向量,而S是X的奇异值的对角矩阵,S=diag(λ1,λ2,λ3,......,λm)。r是X的秩。
接着,LSA通过寻找X的k-秩近似矩阵,即k<<r,使得在保留特向量之间的潜在语义关系的同时能够实现降维,大大减少计算量。这里k的取值可描述为:由于LSA把词向量和文本向量处于一个空间中,k的取值不断变化导致向量在空间中不停的旋转,使得当旋转角度达到某个值时向量之间的距离最理想、最合理,这时k的值即最优值。因此,k不宜过大或过小。文献 [10]利用矩阵空间的压缩率来选取k值。通过计算

然后选择k使得≥θ,其中θ根据情况选择,如65%,70%,85%等。
确定k值后,得到X的k-秩近似矩阵X′,如式 (4)

2.3.3 消除同义词
通过式 (3)计算特征项的贡献值,构建特征项关联矩阵,并利用余弦距离公式寻找相似特征组并消除冗余特征项。下面对主要概念进行定义:
定义6rij表示第ti在Dj中的关联值,rij=X′ij,则贡献值Ri=ri1+ri2+…+rin。
定义7 设m为特征项数目,则特征项关联矩阵为Um×m,Uij为ti和tj的余弦距离。
定义8 -ti∈T,ta,tb,…,tm∈T,若满足Uia,Uia,…,Uia>0.9,则gi=﹛ta,tb,…,tm﹜,称gi为ti的相似特征组;若满足Ri=Max﹛Ri,Ra,Rb,…,Rm﹜,则gi=﹛ti﹜。
3 实验测试与分析
实验测试过程由领域文本资源获取、文本预处理及特征项提取及概念术语提取构成。
3.1 领域文本资源获取
笔者通过调研获得6个领域的专业网址,爬取深度为1的链接,并从中提取网页正文。为了验证该方法的实际效果,这里通过与人工提取的正文内容做比较分析。实验结果见表2。

表2 文本资源获取实验结果
这里,起始站点更具体可能会提高文本资源获取的有效率,同时爬取深度也可能影响获取结果。
3.2 文本预处理及特征项提取
这里以教育技术领域为例。首先下载复旦大学公开的中文文本分类语料库作为背景语料集,该库包含20个领域,共9878篇文献,以爬取得到的100篇教育技术领域的文献作为领域文本集。以合并的新词作为用户词典,采用中科院的ICTCLAS用户词典分词方法进行分词。采用中文停用词表 (含1208个停用词)过滤并保留名词和词性为new的新词,运用TFIDF算法计算词语权重,并选取前220个特征项。
3.3 领域概念术语提取
(1)构建X矩阵,行为特征项 (220),列为文本(100),TFIDF值作为矩阵元素。
(2)LSA对X进行奇异值分解,这里X的秩为99,k值取9,得到X的k-秩近似矩阵X′。
(3)利用余弦距离 (取绝对值)公式构建特征项关联矩阵Um×m。矩阵元素表示特征项之间的相似度,部分矩阵实验结果见表3。

表3 部分LSA特征项关联矩阵
从表3的第一列可得,与 “网络教学”的相似度大于0.9的特征项有 “远程教育”、“网络教育”及 “远程教学”。这里把这4个特征项称为一个相似特征组。
下面以表3中的10个特征项 (近似权重值为3以上)作为测试集,实验结果如图3所示。

图3 测试特征项集的概念术语提取
由图3可得 “网络教学”为表3相似特征组中贡献值最大的特征项,这里,消除该组其它特征项。最后得出贡献值为3以上的特征项形成该测试集的概念术语。从图3可看出,LSA方法能够消除相似特征项,去除冗余概念,同时可以过滤 “电子刊物”、“康复医学”等非教育技术领域概念,提高概念术语提取的准确率。
4 结束语
结合网络爬虫技术和LSA方法进行领域概念术语自动提取。由实验结果可看出,利用网络爬虫技术可以自动获取有效领域文本资源,避免了文本资源来源的领域固定化、手工化等问题;采用LSA的方法可以提高领域概念术语提取的准确率并消除冗余概念。但是,领域文本集规模和测试集过小,可能会影响实验结果。这里,笔者认为若能在特征项提取的过程中利用TFIDF结合其它特征提取算法,如互信息、相对熵及x2统计量等,并综合考虑其它重要因素,相信结果会有更进一步的提高。
[1]MA Fei-cheng,HAO Jin-xing.Applications of concept maps in knowledge representation and knowledge evaluation(I) [J].Journal of Library Science in China,2006,32 (3):5-9 (in Chinese).[马费成,郝金星.概念地图在知识表示和知识评价中的应用 (I)——概念地图的基本内涵 [J].中国图书馆学报,2006,32 (3):5-9.]
[2]ZHANG Hui-ping,ZHOU Ning,CHEN Yong-yue.Research on application of concept map in knowledge organization [J].Information Science,2007,25 (10):1570-1574 (in Chinese).[张会平,周宁,陈勇跃.概念图在知识组织中的应用研究 [J].情报科学,2007,25 (10):1570-1574.]
[3]Chen Nian-Shing,Kinshuk,Wei Chun-wang,et al.Mining e-learning domain concept map from academic articles [C].Proceedings of the Sixth IEEE International Conference on Advanced Learning Technologies,2006:694-698
[4]ZHANG Hui-ping,ZHOU Ning.Research on the autoconstruction of the term co-occurrence-based concept map [J].Information Studies:Theory & Application,2008 (6):928-930(in Chinese).[张会平,周宁.基于词共现的概念图自动构建研究 [J].情报理论与实践,2008 (6):929-903.]
[5] WU Jiang-ning,TIAN Hai-yan.Study of document organization method based on topic map [J].Journal of the China Society for Scientific and Technical Information,2007,26 (3):323-331 (in Chinese).[吴江宁,田海燕.基于主题地图的文献组织方法研究 [J].情报学报,2007,26 (3):323-331.]
[6]ZHAO Xin-xin,SUO Hong-guang,LIU Yu-shu.Web content information extraction method based on tag window [J].Application Research of Computers,2007,24 (3):144-146 (in Chinese).[赵欣欣,索红光,刘玉树.基于标记窗的网页正文信息提取方法[J].计算机应用研究,2007,24 (3):144-146.]
[7]LI Xiao-hong.Feature extraction methods for Chinese text classification [J].Computer Engineering and Design,2009,30 (17):4127-4129(in Chinese).[李晓红.中文文本分类中的特征词抽取方法[J].计算机工程与设计,2009,30 (17):4127-4129.]
[8]WANG Mei-fang,LIU Pei-yu,ZHU Zhen-fang.Feature selection method based on TFIDF [J].Computer Engineering and Design,2007,28 (23):5795-5799 (in Chinese). [王美方,刘培玉,朱振方.基于TFIDF的特征选择方法 [J]计算机工程与设计,2007,28 (23):5795-5799.]
[9]HU Xiao,WANG Li,PAN Shou-hui.Web text classification approach based on improved VSM [J].Journal of Intelligence,2010,29(5):144-147 (in Chinese).[胡晓,王理,潘守慧.基于改进 VSM的 Web文本分类方法 [J].情报杂志,2010,29 (5):144-147.]
[10]XU Wen-hai.Model and mapping algorithm of transformation from text cell to knowledge cell[D].Shaanxi:Xidian University,2008:1-63(in Chinese).[徐文海.文本单元向知识单元转化的模型与映射算法 [D].陕西:西安电子科技大学,2008:1-63.]
