基于可重构计算技术的ASIP设计与实现
2012-07-12宋奂寰王树宗邵利兵
宋奂寰,王树宗,邵利兵
(海军工程大学兵器工程系,湖北 武汉 430033)
基于可重构计算技术的ASIP设计与实现
宋奂寰,王树宗,邵利兵
(海军工程大学兵器工程系,湖北 武汉 430033)
为了加速计算密集或数据密集类算法,设计了Kahn线程定义的虚拟指令,以及嵌入式粗粒度可重构阵列流水线处理器的体系结构。通过指令流水线设计,实现虚拟指令的并行执行,将指令级并行扩展为线程级并行。系统运行时,采用订阅/发布机制作为可重构阵列的通信机制,利用可重构系统可重复配置的特点,提高了系统的计算效率。通过仿真实验验证了基于可重构计算技术的流水线处理器结构的有效性。
可重构计算;粗粒度可重构阵列;循环指令流水线;订阅/发布机制
0 引言
可重构计算兼顾定制计算的高效性与通用计算的灵活性,是一种新型的时空域计算模式。在可重构计算系统中,通过硬件的时域复用完成复杂的功能定制和系统任务。通过设计合理的重构粒度,可以提高硬件的计算能力[1]。
文献[2]介绍一种粗粒度可重构多核协处理器体系结构,用于加速计算密集或数据密集类算法。在该结构中采用具有猜测执行机制的循环自动流水线技术,将流水线并行执行和数据驱动执行紧密结合。采用以循环程序为单位的固定指令多数据流执行模式,在循环执行期间,每个单元固定执行一种指令,配置信息量减少,支持快速动态重构。设计了多种特殊数据传递指令,如非平衡数据复制指令、数据选择指令等,充分利用循环迭代内部、循环迭代间的数据相关,开发数据重用性,减少对存储器带宽的需求。文献[3]提出了一种数据驱动处理器阵列结构,该结构能有效平衡存储和计算,适合用于在FPGA上实现高性能的算法加速。
本文设计了循环指令流水线和循环算数流水线,以数据驱动的方式填充和排空循环流水线。通过Kahn进程定义的虚拟指令使流水线在嵌入式可重构阵列上自动运行。利用可重构系统的通信网络具有可配置的特点,采用订阅/发布通讯机制,灵活地改变网络的拓扑结构。
1 预备知识
专用指令集处理器(ASIP)综合了软件占优和硬件占优2类系统的特点,能在微处理器和专用集成电路间进行权衡,提供了嵌入式设计的一种良好解决思路;ASIP可通过定制获得需要的功能,成为通用处理器和ASIC的替代者[4-5]。粗粒度可重构阵列采用 FPGAs或其他可编程硬件,可配置逻辑块(CLB)是FPGA内的基本逻辑单元。若干个功能部件CLB有规则地组成FPGA逻辑单元阵列结构,形成一个可配置处理单元(RU),以完成用户指定的逻辑功能。粗粒度可重构阵列以RU为一个可配置单位,RU是硬件向用户提供的最小编程接口。所有建立在粗粒度可重构阵列之上的设计单元都要被翻译为这些RU器件,否则是不可实现的。粗粒度可重构阵列作为协处理器,嵌入专用指令集处理器,实现基于粗粒度可重构阵列的流水线处理器(见图1)。
粗粒度可重构阵列作为主控处理器的协处理器,主控处理器用于执行控制可重构逻辑或执行不能被加速执行的编程代码,粗粒度可重构阵列作为主控处理器数据通道中定制的功能单元使用。当主控处理器遇到密集型计算时,向粗粒度可重构阵列定制可配置处理单元。可配置处理单元分为用于循环控制和存储访问控制的MPE和用于计算任务的CPE。处理单元与互联网络上的路由器相连。接口控制器是连接主控处理器、外部主存储器和粗粒度可重构阵列处理器的桥梁,用于粗粒度可重构阵列加载配置信息、以DMA方式在外部主存储器和内部数据存储器之间加载数据或读取结果,或是主控制处理器向粗粒度可重构阵列发送启动命令及查询运行状态。
为了最大限度地利用可重构硬件,粗粒度可重构阵列上的密集型计算必须具备重复计算的特点,即对于多组输入数据执行的操作是相同的,因此本文引进流水线作为粗粒度可重构阵列上的任务单元。
2 粗粒度可重构阵列上的流水线
流水线处理器是当前指令集处理器设计中广泛应用的技术[6]。流水线就是将一个操作分解为一些小规模的基本操作,并且在基本操作之间增加适当的寄存器,把基本操作产生的中间值存放在这些寄存器中,并在下一个时钟周期内继续运算。在流水线处理器设计中,要流水化的运算就是每个指令周期所要进行的工作。流水线设计的主要任务可以看做是将逻辑指令周期映射到物理机器周期。换句话说,就是将指令周期所对应的运算分成一个子运算的序列,由流水线的各段运行。流水线的类型主要分为指令流水线和算术流水线2种。
2.1 指令流水线设计
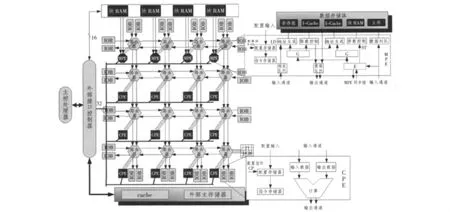
图1 基于粗粒度可重构阵列的流水线处理器Fig.1 Pipeline processor based on coarse-grained reconfigurable array
一个典型的指令周期按功能可以划分为取址(IF)、译码(ID)、取操作数(OF)、执行(EX)和存储(OS)等5个基本运算分量。指令流水线的设计任务是将以上运算分量进行划分或组合,使模块执行时间均衡,以平衡指令流执行时间。指令流水线重复处理的指令具有不同的指令类型:算数操作(ALU)、数据移动(LOAD、STORE)和指令定序(BRANCH)。统一不同的指令类型,将不同资源需求有效地整合到1条指令流水线中去,使得这条流水线适合于所有的指令类型。整合的目标是尽量减少流水线所需要的资源数,同时尽量提高流水线中所有资源的利用率,整合后的TYP指令流水线[6]如图2所示。
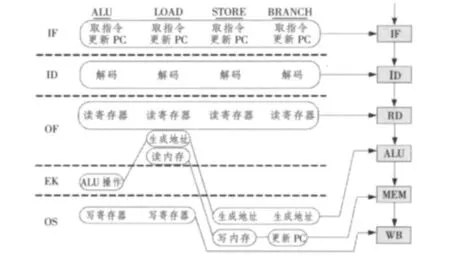
图2 TYP指令流水线Fig.2 TYP instruction pipeline
专用指令集处理器根据指令的相关性,在可重构阵列上定制指令流水线,只要程序计数器PC所指向的指令地址不为空,就会有指令不断填充TYP指令流水线。用虚拟指令描述TYP指令流水线的行为,如表1所示。指令流水线所访问的存储体采用分层结构,即ALU寄存器、I-cache(专用于存放指令)、D-cache(专用于存放数据)、外部主存储器。ALU寄存器、I-cache和D-cache只有1个端口,因此在1个时钟周期内,只能对其执行读(LD)或写(ST)指令之一。多端口的主存储器在1个时钟周期内即可进行读操作又可进行写操作,因此除了执行LD和ST指令之外,还可执行MM指令。
2.2 算术流水线设计
当指令流水线ID段解析到循环体程序时,可以通过流水线向量化算法[7],将串行执行的循环体展开成可并行执行的程序段,然后根据数据流图,为粗粒度可重构阵列定制循环算术流水线功能单元。只要循环未结束,就会有数据不断填充算术流水线。用虚拟指令描述算术指令流水线的行为,如表2所示。

?
表1和表2的虚拟指令有很多是相同的,采用Kahn进程[8]实现这些虚拟指令。将这些虚拟指令映射到基于嵌入式粗粒度可重构阵列的流水线处理器中:①LD指令和ST指令根据接口地址Address_in和Address_out的地址格式在MPE中访问不同的存储体;②流水线启动(G)/关闭(E)指令、F指令和G与数据存储体紧密相关,因此它们集中在MPE中实现;③用于算术和逻辑运算的Compute指令集中在CPE中实现;④Jump指令根据给出的地址,更新I-cache的内容和程序计数器PC的值,因为Jump指令与存储体密切相关,所以在MPE中实现;⑤F,Join与J指令分别采用CPE提供的逻辑运算O=I?L:R和O=L op R来实现。
2.3 流水线时钟周期的计算
时钟是流水线执行的控制器,也是流水线深度的决定因素之一。流水线的时钟周期也叫机器周期。流水线的每一级是由1组组合逻辑电路F和1个寄存器组成。在实现过程中,为减少信号的传输延迟和节约逻辑资源,这个寄存器通常由CLB单元中的触发器D实现。定义TM为通过F的最大传输延迟,即通过最长信号路径的延迟;Tm为通过F的最小传输延迟,即通过最短信号路径的延迟;TD为正确建立时钟信号所需要的额外时间,包括必要的建立和保持时间,以保证正确的锁存,同时还包括可能的时钟扭曲,即到达不同触发器的时钟沿的最大时差。假设1组信号X1自T1时刻作用在流水线某一级的输入端,那么F的输出最迟将在T1+TM时刻有效,要保证D的正确锁存,F的输出信号在T1+TM+TD时刻必须仍然有效。当第2组信号X2自T2时刻作用在F的输入端时,最快只要到T2+Tm时刻就能传到锁存器L。要保证第2组信号不覆盖第1组信号,必须满足公式[9]:
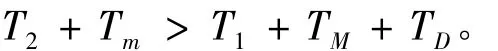
上式可改写为
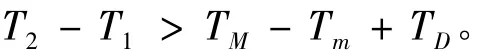
其中:T2-T1为最短时钟周期。因此流水线的时钟周期T必须比TM-Tm+TD大,最大时钟频率不能超过1/T。
2.4 通信机制
订阅/发布通信机制由生产者、消费者和事件通知服务组成[9]。生产者和消费者分别是对产生事件对象和消费事件对象的统称,事件通知服务即通常意义上的订阅/发布中间件。消费者以订阅的方式向事件通知服务注册,表达对特定事件的兴趣,生产者发布事件到事件通知服务,并将生产的数据送到数据池中。事件通知服务充当生产者和消费者的中介,负责订阅的管理,根据订阅过滤事件,并以通知的形式发送事件到感兴趣的消费者,消费者收到通知后,从数据池中取出所需的数据,如图3所示。

图3 订阅/发布通信模型示例Fig.3 Examples of communication model
核即是订阅/发布机制的生产者/消费者。由于订阅/发布系统具有松耦合、匿名、多对多通信和可扩展的特点,符合粗粒度可重构阵列的通信网络是可配置的要求,因此是基于嵌入式粗粒度可重构阵列的流水线处理器体系结构理想的通信模式。数据存储体(块RAM,触发器,用于数据存储的查找表)充当数据池的角色。粗粒度可重构阵列内嵌有数字时钟管理模块。将时钟频率不同的设计划分到不同的时钟区域,通过异步FIFO以及双口RAM为不同的时钟区域建立不同的数据池,设计转发器实现不同数据池间数据的传输,这样可避免信号直接跨越不同的时钟域并在一定程度上化解流水线相关。Xilinx提供了片上RAM,特别是大量的块RAM,可以配置成双口RAM或ROM,它们存储量大、速度快且不占逻辑资源[10]。将这些块RAM资源以数据池的形式分配给时钟频率相同的可配置的处理单元,当某个核所需的初始数据在数据池中被初始化后,该核自动被启动执行。若干个核同时配置到粗粒度可重构阵列空间,就形成了循环流水的自动执行,提高了数据的吞吐率和并发程序的执行效率。
3 实验与性能分析
基于可重构计算技术的ASIP的软件实验环境包括 Modelsim SE 6.5, Simulink, Xilinx System Generator(系统生成环境)和Xilinx ISE 9.1i(系统综合环境),硬件实验环境包括Xilinx公司的大容量FPGA芯片 Virtex4xc4vsx35-10ff668,32MB SDRAM和PCI桥。
首先,通过PCI桥将FPGA芯片与主控处理器相连,SDRAM与FPGA间有64位数据通路。该实验平台能运行应用程序并提供时钟准确的运行结果。其次,用Verilog硬件描述语言实现粗粒度可重构阵列的体系结构。用模块实现自定义的IP核(MPE核、CPE核),用双口RAM实现1个系统周期同时读出2个数据。
用本文提出的思想,在嵌入式粗粒度可重构阵列的流水线处理器实验平台上实现边界检测算法,过程如下:
步骤1 在流水线处理器上执行高级语言程序。高级语言程序的每一条语句依次通过图2所示的TYP流水线。当解码得到的指令为循环指令时,进入步骤2。
步骤2 将循环程序转换成用虚拟指令表示的伪代码。将循环程序利用表1和表2所示的虚拟指令转换成伪代码。
步骤3 画出虚拟指令表示的伪代码数据流图。
步骤4 使用Simulink,Xilinx System Generator以及IP核实现步骤3的数据流图。由于该段程序不存在流水线相关,所以这个3级流水线使系统的吞吐率提高了3倍;利用粗粒度可重构阵列上的块RAM,有效地缓解了读取存储器的瓶颈问题。
步骤5 利用Xilinx ISE进行设计综合。由主控处理器通过PCI总线写入FPGA芯片,最终边界检测算法在基于可重构计算技术的ASIP上运行,循环流水线占用FPGA资源情况如表3所示,可见基于可重构计算技术的ASIP设计方法在计算速度和占用资源方面的有效性。
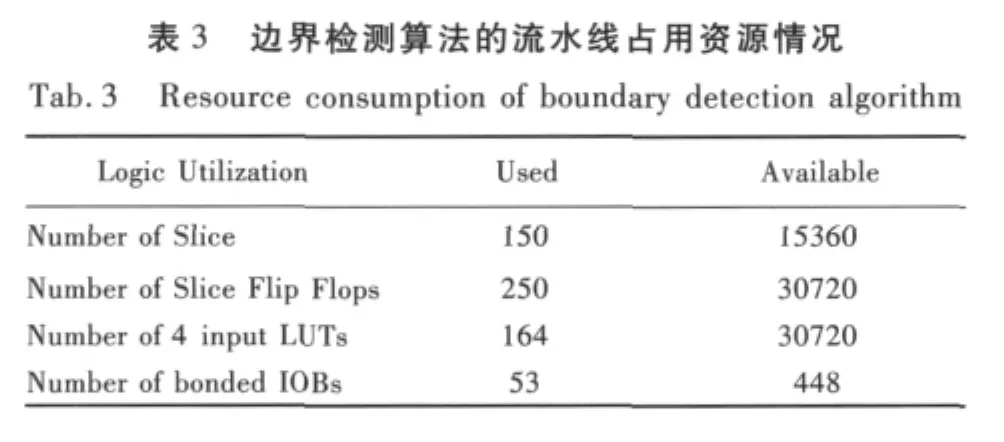
?
4 结语
本文的创新点有:将可重构计算技术应用于ASIP实现集成电路的定制;在可重构阵列上引入流水线技术,实现指令的并行执行;采用订阅/发布通信机制实现并行任务间的通信。具体方法有:采用Kahn进程定义虚拟指令,在专用指令集处理器上执行。通过虚拟指令在循环流水线上的并行执行实现了Kahn进程的并行执行。粗粒度可重构阵列既可以执行循环算术流水线,执行数据密集或计算密集类算法,又可以执行循环指令流水线,执行指令的取指、译码、取操作数、执行和存储等操作。体系结构采用模块化设计,为循环流水线设计的可配置处理单元是最小的资源分配单位,采用多种可配置指令,实现了虚拟指令的功能。订阅/发布通讯机制使得分布在粗粒度可重构阵列之上的各个处理单元拥有灵活的拓扑网络结构和共享的数据池,当某处理单元所需的数据准备完毕后,由数据驱动流水线自动执行。实验结果验证了基于可重构技术的ASIP方法的可行性与有效性。
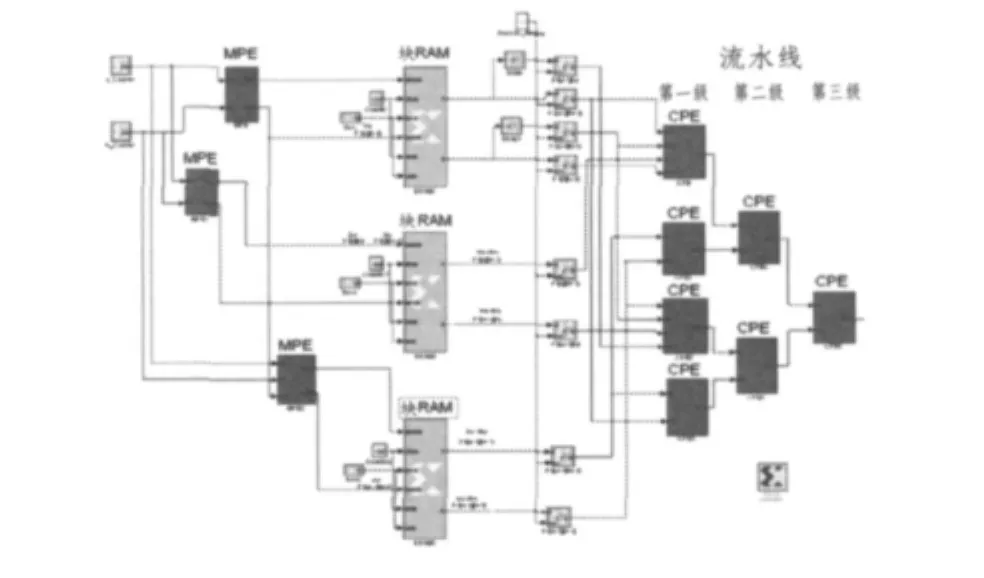
图4 使用Simulink,Xilinx System Generator实现数据流图的仿真程序Fig.4 Simulation program of data flow diagram in Simulink,Xilinx System Generator environment
[1]孙康.可重构计算相关技术研究[D].杭州:浙江大学,2007.
[2]窦勇,邬贵明,等.支持循环自动流水线的粗粒度可重构阵列体系结构[J].中国科学,2008,38(4):579 -591.
[3]邬贵明,窦勇,等.面向数据驱动处理器阵列的自动综合[J].计算机工程与科学,2009,31(S1):42-45.
[4]杨君,专用指令集处理器(ASIP)体系结构设计研究[D].合肥:中国科技大学,2006.
[5]KEUTZER K,MALIK,S,NEWTON A R.From ASIC to ASIP:the next design discontinuity[C].Proceedings of the 2002 IEEE International Conference on Computer Design:VLSI in Computers and Processors,2002.84 -90.
[6]SHEN J P,LIPASTI M H.现代处理器设计技术[M].北京:电子工业出版社,2004.24-61.
[7]WEINHARDT M,LUK W.Pipeline vectorization[J].IEEE Transactions on computer-aided design of integrated circuits and systems,2001,20(2):234 -248.
[8]KAHN G.The semantics of a simple language for parallel programming[C].Proceedings of the IFIP Congress,North-Holland,1974.471-475.
[9]施东材.基于对等网络的语义发布/订阅系统的关键技术研究[D].杭州:浙江大学,2007.
[10]田耘,徐文波.Xilinx FPGA开发实用教程[M].北京:清华大学出版社,2008.3-105.
Design and realize for ASIP based on reconfigurable computing
SONG Huan-huan,WANG Shu-zong,SHAO Li-bing
(Department of Weapon Engineering,Naval University of Engineering,Wuhan,430033,China)
In order to accelerate algorithm of computation-intensive and data-intensive,virtual instructions designed by Kahn thread and pipeline processor for embedded coarse-grained reconfigurable array are introduced.Instruction-level parallelism is extended to contain thread-level parallelism by design of instruction pipeline.Communication of reconfigurable array adopts subscribe/published mechanism.Finally,the simulation result validates the architecture of pipeline processor.
reconfigurable computing;ASIP;cycle pipline;subscribe/published mechanism
TP314
A
1672-7649(2012)05-0078-05
10.3404/j.issn.1672-7649.2012.05.018
2011-08-08;
2011-09-06
国防973项目资助(613660202);中国博士后科学基金资助项目(200902668)
宋奂寰(1983-),女,博士研究生,从事可重构技术与故障处理研究。
