基于训练集的自动文摘方法的研究
2011-12-27程传鹏
程传鹏
(中原工学院,郑州 450007)
基于训练集的自动文摘方法的研究
程传鹏
(中原工学院,郑州 450007)
提出了一种基于训练集的自动文摘方法.依据训练集所产生的主题词,设计出一种新的段落加权公式和一种新的句子重要性加权公式,将生成的主题句消除冗余后得到文摘.测试结果表明,该方法具有一定的实用性.
训练集;主题词;主题句;自动文摘
自动文摘就是利用计算机从文档中提取尽可能少的句子,要求这些句子语意连贯,并且能够最大限度地体现原文档所要表达的中心思想.随着Internet的迅猛发展以及无纸化办公的普及,各种格式的电子文件大量涌现.从这些电子文档中迅速、准确地进行自动文摘,已经成为一项重要的研究课题.目前,自动文摘的方法大体上可以分为2类:基于统计的机械文摘方法和基于理解的文摘方法[1].前者主要是简单的对词频(词条在全文中所出现的次数)进行统计,依照词频来确定主题词,主题句的产生也只是依赖所包含主题词的数量的多少.它的优点是实现简单,文摘效率较高,但得到的文摘往往不能很好地体现原始文档的中心思想.后者则是利用人工智能技术,特别是自然语言理解技术为核心,在对文本进行语法结构分析的同时,利用领域知识对文本的语义进行分析,通过判断推理,得出文摘句的语义描述,根据语义描述自动生成摘要.这种方法虽然一定程度上弥补了机械文摘的不足,提高了文摘的质量,但需要构建复杂的推理规则,文摘生成过程所耗时间长,实时性能低劣.
文摘的质量固然重要,但低劣的实时性也是不能接受的.基于此,本文提出了一种基于训练集的自动文摘方法,首先对自动文摘中主题词的选择、主题句的产生、文摘的生成等关键技术进行了研究与分析.在此基础上,设计出了一个自动文摘原型系统,最后对该方法进行了实验和评价.
1 关键技术分析
自动文摘从原始文档中提取最精简、最能体现原始文档意思的语句,文摘的优劣跟主题词的选择、主题句的选择以及自动文摘息息相关.下面对这些关键技术进行介绍.
1.1 主题词的选择
本文中,主题词的界定参照了文档分类中特征提取的方法,通过分词后的文档词汇,数量是相当大的,原始的特征空间可能由出现在文章中的全部词条构成.而中文的词条总数有二十多万条,这样高维的特征空间对于几乎所有的分类算法来说都偏大[2].为了提高分类的效率和精度,在分类之前必须进行特征抽取来剔除那些表现力不强的词汇.在主题词的选择过程中,给出如下的定义:
定义1训练集:由专家系统筛选出来的,具有某相近主题的文档集合.本文用S来表示训练集.
定义2主题词:最能代表训练集的一些词条.本文用T来表示主题词.
定义3主题词权重:主题词Ti在文档中的重要程度.本文用TWi来表示第i个主题词权重.
符号定义:
A:包含词条t且属于类别c的文档频数.
B:包含t但是不属于c的文档频数.
C:属于c但是不包含t的文档频数.
N:语料中文档总数.
有了上面的定义后,主题词的选择步骤如下:
(1)对训练集中所有的文档进行分词,分词后得到的词条,都作为候选主题词.
(2)采用互信息的方法选取主题词.互信息是信息论中的概念,它用于度量一个消息中2个信号之间的相互依赖程度[3].对于每个候选主题词,计算候选主题词t和训练集类c的互信息量:
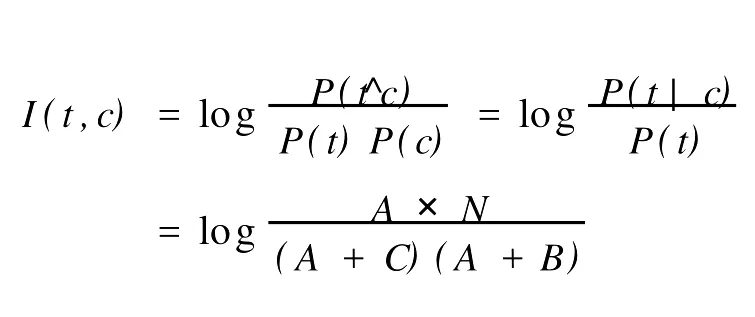
式中:I(t,c)表示候选主题词和类别c之间的互信息量;P(t^c)表示候选主题词t和类别c同时出现的概率;p(t)表示候选主题词t出现的概率;p(c)表示类别c出现的概率;p(t|c)表示类别c里出现候选主题词的概率.
(3)对训练集中的所有候选主题词,依据上面计算的互信息量进行排序.
(4)依据词的互信息量大小,抽取一定数量的词作为主题词.
1.2 段落权重计算以及主题句选择
同一篇文章中,不同的段落,具有不同的重要程度,段落中所包含的主题词数量、段落的长度,都决定着段落在整篇文档中的重要性.此外,经过对大量文档的观察,我们发现,一个句子是否能够成为主题句,不仅与句子所在的段落的重要性有关,而且和句子的长度(SL)、句子在段落中的位置(SP)以及句子中所包含的主题词个数(f)有着密切的联系.
在主题句的选择过程中给出如下的定义:
定义4段落:是按照中文习惯所形成的语言段落.本文用P来表示段落.
定义5段落权重:一个段落在整篇文档中的重要程度.本文用PW来表示段落权重.
定义6句子:按照中文标点符号分割成的,由字、词、词组所组成的语言单位.本文用S来表示句子.
定义7句子权重:句子在整篇文档中的重要程度.本文用SW来表示句子权重.
主题句产生的步骤如下:
(1)对用户提交的待摘要文档进行段落划分,形成段落集{P1,P2,P3…Pi…Pn}.
(2)对段落Pi进行中文分词,计算每个段落的权重.计算公式如下:

式中:WTi为段落中出现的主题词的权重;fi为该主题词在段落中出现的频率;PLi为段落的长度;DL为整篇文档的长度.
(3)计算句子SWi的权重.计算公式如下:
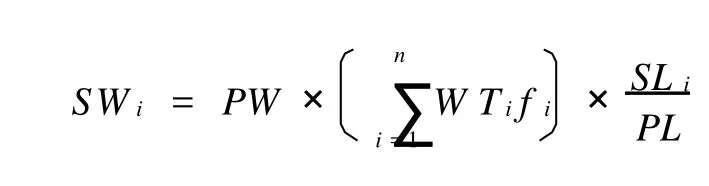
式中:PW为主题词所在段落的权重;fi为该主题词在段落中出现的频率;SL为段落的长度;PL为主题词所在段落的长度.
(4)对所有句子,依照权重大小进行排序,选择权重最大的N个句子作为主题句.N的大小跟生成的文摘长度有关.
1.3 文摘的生成
自动文摘应该以尽可能少的文字,最大程度地体现原文所表达的意思.通过以上2个步骤所得到的主题句,并不能完全作为文摘提交给用户.因为经过系统初步筛选出的主题句,往往具有较多的冗余信息.常见的冗余信息有以下3种:
(1)语意相似.比如下面2个语意相似的句子:①吴文俊老师在拓扑学领域取得了丰硕的成果;②吴文俊老师在拓扑学方面获得了骄人的成就.(2)同一主语.除了语意相似产生的信息冗余外,相邻主题句如果主语相同,也会产生文摘的信息冗余.比如下面2个句子:
①吴文俊是着名的数学家,他的研究工作涉及到数学的诸多领域;
②吴文俊的主要成就表现在拓扑学和数学机械化2个领域.
(3)过渡性词语.在主题句里,有时会出现一些承上启下的连词或者转折词,这些词条对文摘没有任何意义,只是在原文中起到一种过渡的作用.比如:“因为”,“也就是说”,“对我来说”.
基于以上原因,我们还要对主题句经过相似度比较并且对主题句进行压缩,对于语意相似的句子,进行删减;对于主语相同的相邻主题句,保留一个主语;对于过渡性词语,在分词时利用停止词表进行剔除.对主题句经过上面步骤处理后,按照主题句在原文中的顺序进行输出,最终产生较为理想的文摘.
2 系统实现
在上述分析的基础上,我们采用VC++6.0开发平台,设计出了一个自动文摘系统原型.本系统包含主题词生成模块、文摘生成模块、用户接口模块.系统结构图如图1所示.
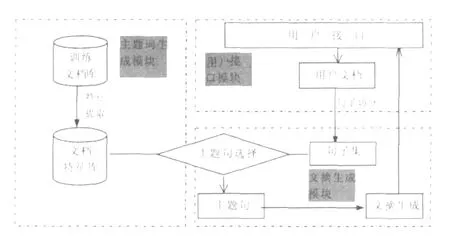
图1 自动文摘系统模型
下面对系统中各模块作简要介绍:
(1)主题词生成模块.从词典数据库里读出词条,按照汉字的 GBK编码在机器内存中建立词典.从网页库里依次读出所有的主题网页,按照最大匹配法的分词方法(未登录词的识别按照统计的方法)对网页进行分词.对分词得到的所有词条去掉停止词后,进行特征提取,提取出最能表现该领域主题的特征词,即主题词.
(2)文摘生成模块.其功能是将对用户提交的文档进行段落划分,计算段落的权重,依照词条的权重以及主题词所在段落的权重,确定一个句子是否能成为主题句.对主题句进行冗余信息消除后,生成文摘.
(3)用户接口模块.该模块为用户提供可视化的查询输入和结果输出界面.在输入界面中,用户可以提交待摘取的文档.在输出界面中,系统提交给用户较为理想的文摘.
3 实验结果及分析
目前,还没有一种很好的自动文摘的评价方法,我们采用了文献[4]所提到的一种评价指标:主题覆盖度,即原文中的主题内容被文摘句所覆盖的百分比.主题覆盖度的值可通过多个人工专家分别打分,所取得分的平均值来确定.这里假设人工专家主题覆盖度为100%,经过实验形成如表1所示的数据.

表1 实验结果
从表1可以看出,本文中的方法在时间性能上要优于基于理解的方法,而在主题覆盖度上又优于机械统计的方法.因此,本文中所提出的方法,在提高了文摘主题覆盖度的同时,又兼顾了时间性能,具有一定的实用性.
4 结 语
随着互联网的迅猛发展以及无纸化办公的普及,会涌现出大量的电子文档,如何快速准确地从繁多的文档中提取“主题思想”,已经成为自动文摘需要迫切解决的一个课题.本文提出了一种基于训练集的文摘自动生成方法,实验结果表明,该方法所产生的主题句能够较好地体现原始文档的中心思想,能较全面地表达原文档的内容.该系统生成的文摘,比较适合一些对文摘实时性要求较高,但对文摘质量不是过于苛刻的场合.
[1]傅间莲,陈群秀.基于规则和统计的中文自动文摘系统[J].中文信息学报,2006,20(5):10-16.
[2]代六玲.中文文本分类中特征抽取方法的比较研究[J].中文信息学报,2004,24(1):26-32.
[3]李粤,李星,刘辉,等.一种改进的文本网页分类特征选择方法[J].计算机应用,2004,24(7):119-121.
[4]胡拍,何婷婷,姬东鸿.基于主题区域发现的中文自动文摘研[J].计算机应用,2005,32(1):177-181.
Research of Automatic Abstraction Method Based on Training Set
This paper p roposes a method of automatic abstraction based on training set.Keyword is p roduced acco rding to training set,and a new paragraph w eighting fo rmula and a new sentence impo rtance w eight formula are designed.Abstraction obtained through the elimination of redundant topic sentence.Experiments show that the system has a certain utility.
training set;topic words;topic sentence;automatic abstraction
CHENG Chuan-peng
(Zhongyuan University of Technology,Zhengzhou 450007,China)
TP391.1
A
10.3969/j.issn.1671-6906.2011.01.017
1671-6906(2011)01-0062-04
2011-01-03
程传鹏(1977-),男,河南郑州人,讲师,硕士.
