基于N-gram超核的中文倾向性句子识别
2011-10-15廖祥文李艺红
廖祥文,李艺红
(福州大学数学与计算机科学学院,福建福州350108)
1 引言
随着互联网的迅猛发展,特别是进入Web 2.0时代,越来越多网民通过网络来表达自己的观点、意见或看法。例如,人们不仅可以在网络购物时对商品做出评论,也可以在论坛、博客等媒介上对某些热点话题发表自己看法。因此,网络已成为人们表达意见的重要渠道,如何分析人们的这些观点、看法变得至为重要。对观点、看法等倾向性信息分析可广泛应用于市场调查、商品比价等相关领域,有着重要的实用价值。
文本倾向性分析就是对文本中评价者所表达出的观点态度进行分析,已经引起了国内外研究人员的广泛关注:国际检索评测会议(Text REtrieval Conference,TREC)连续三年举办了博客倾向性检索评测[1];国内连续组织了针对中文的中文倾向性分析评测(COAE)[2]。倾向性句子识别是文本倾向性分析的重要组成部分,其目的是判断一篇文章中的句子对评价对象是否持有情感倾向。目前国内外关于倾向性句子识别的研究工作主要分为以下两类:(1)基于语义规则的方法;(2)基于机器学习的方法。基于语义规则的方法虽然在特定的语料取得不错的效果,但是由于规则构造不完备,泛化能力较差。基于机器学习的方法把倾向性句子识别看成是二分类问题,从倾向性特征选择出发,采用SVM 等分类器识别倾向性句子,取得较好的效果。目前倾向性特征选择主要集中在倾向词词频统计、特殊符号等。然而,句子的倾向性不仅与倾向词有关,而且还跟句法、语义等因素有关[3]。如何融合这些特征构造分类器,将有助于提高分类精度。本文提出了一种基于N-gram超核的中文倾向性句子识别算法。该算法从词语的上下文信息及句法层面捕获句子的倾向性信息,构造N-gram超核函数,最后采用支持向量机分类器识别中文倾向性句子。实验结果表明,基于N-gram超核的中文倾向性句子识别算法在一定程度上能有效识别倾向性句子。
本文主要结构如下:第2节介绍了国内外的相关工作;第3节是基于N-gram超核的中文倾向性句子识别;第4节给出实验方法和实验结果;第5节对本文的主要工作进行总结。
2 相关工作
文本倾向性分析[4](Sentiment Analysis)就是分析用户对文本中某种事件的看法或评论,从而得到该看法或评论对事件是属于积极或消极的意见。倾向性句子识别是文本倾向性分析的重要组成部分,其目的是判断一篇文章中的句子的评价者对评价对象是否持有情感倾向。目前国内外关于倾向性句子识别的研究工作主要分为以下两类。
(1)基于语义规则方法。该方法主要有两种,第一种是先抽取分析文本中的形容词或能够体现主观色彩的短语,然后对抽取出来的形容词或短语逐一进行倾向性判断并赋予一个倾向值,最后将所有倾向值累加起来得到文本的总体倾向性,比较具有代表性的工作是Hatzivassiloglou[5];第二种是预先建立一个倾向性语义模式库,有时还会附带一个倾向性字典,然后将待评估文档参照语义模式库做模式匹配,最后累加所有匹配模式对应的倾向性值从而得到整个文档的倾向性,主要代表性的工作是Yi等[6]。
(2)基于机器学习的方法。该方法先人工标注一些文档的倾向性,然后将这些文档作为训练集,再通过机器学习的方法构造一个褒贬两类分类器,最后使用构造好的分类器对待评估文本进行分类,即识别出该文本的倾向性。Pang等人[7]分别使用朴素贝叶斯(Native Bayes)、最大熵(Maximum Entropy)及支持向量机[8](Support Vector Machines,SVM)方法进行文本倾向性研究,并对三种方法作了比较分析,发现三者的效果差别并不太大,SVM的效果稍微比前两种方法好一些。徐琳宏等人[9]就是选取褒贬倾向性比较强烈的词作为特征项,构造了一个SVM褒贬两类分类器来进行文本倾向性分析的。
姚天昉等人[3]以词语的原始字符串、词性、有无倾向性三个特征来设计词语的相似性核,以此引出短语集合的相似性核,继而设计出核函数。这样的算法比较直观,但不够全面:(1)其抽取的短语集合不够全面;(2)核函数缺乏考虑不同倾向词的倾向性强度。针对句子层的倾向性问题,本文提出了一种基于N-gram超核的中文倾向性句子识别算法。该算法从词语的上下文信息及句法层面捕获句子的倾向性信息,构造N-gram超核函数,最后采用支持向量机分类器识别中文倾向性句子。
3 基于N-gram超核的中文倾向性句子识别
本文提出的N-gram超核较之姚天昉等[3]提出的N-gram核,更能融合了中文句子语法、上下文信息等特征,能更有效地识别中文倾向性句子。下面介绍如何构造N-gram超核来识别中文倾向性句子。
3.1 基于向量空间模型的句子表示
对于中文文本,汉字是最基本的语言单位,词或短语是最小具有语义的语言单位。因而在中文倾向性句子识别中可以采用词或者短语作为中文句子的特征。词语一般具有三个特征:原始字符串、词性及倾向性。姚天昉等人[3]以词之间三个特征直接比较相同与否,来设计词相似性核,很直观,但较缺乏词的倾向性信息。我们可以充分利用倾向性词表的信息,构建句子的向量空间模型。
这里我们定义t表示一个词,它是一个三元组:

其中w为词权重;pos为词语t的词性权重;s为词语t的倾向性强度。
本文翻译SentiWordNet并扩展性地添加同义词,以原有的倾向性评分作为倾向性词的倾向性程度。词权重是刻画该词出现时该句子具有倾向性的可能性,以词语与倾向词的相关度来计算。同时,为了度量各种不同词性在倾向性句子的不同作用,我们以词性与倾向性句子的相关度来计量词性的权重。
3.1.1 词语与倾向词的相关度
设句子中的词集合T={ti|i=1,2,…,n},给定倾向性词集合D={di|i=1,2,…,m},互信息是计算相关性的常用统计量,我们定义词 a,b的相关度为:
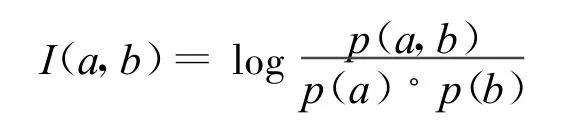
其中p(a),p(b)分别表示出现词a,b的概率。p(a,b)表示词a,b在句子中同时出现的概率,采用拉普拉斯平滑后为:
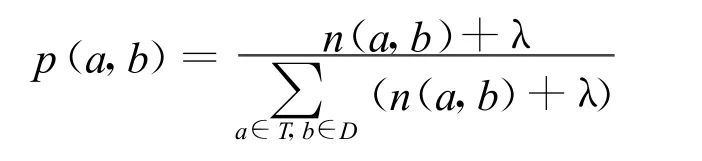
这样我们定义词权重为:

3.1.2 词性与倾向性句子的相关度
给定词性集合P=pi|i=1,2,…,n和句子集合S=si|i=1,2,…,m,根据文档中词频(Term Frequency)和逆文档频率(Inverse Document Frequency)的定义,我们可以相应的给出句子中词性频率和逆句子频率的定义,并以此来计算词语词性与倾向性句子之间的相关性强度:
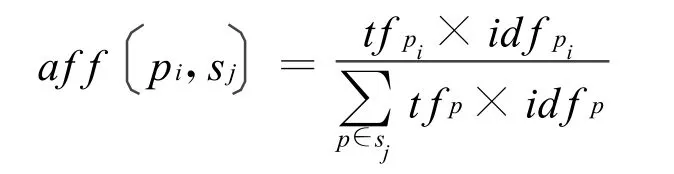
3.2 N-gram超核函数
核函数方法[10]是目前常用的分类算法,该方法在不增加计算复杂度的前提下可以有效地提高分类性能。核函数方法善于将样本经非线性映射到特征空间,而核函数能在特征空间中变换成内积表达形式。
在满足Mercer[11]条件下,核函数可以有多种形式供选择[12-13]。目前常用的核函数主要有三种:多项式核函数、高斯核函数和sigmoid核函数。多项式核函数学习能力强,但泛化能力较弱,而高斯核函数泛化能力强,但学习能力较弱。因此可以用高斯核较强的泛化能力这一优点,来弥补多项式核学习能力强但泛化能力弱的缺陷。Smitsgt等[14]把高斯核和多项式核组合起来,组成的超核函数具有更好的学习能力和泛化能力。
为了能够更好地融合反映句子倾向性的句法、语义等特征,本文利用超核函数的良好学习能力和泛化能力,提出了一种N-gram超核函数。具体构造过程如下:
核函数反映的是输入数据间的相似性,则设定词语ti、tj,可以定义词语相似性核为:

其中,ρ∈[0,1]是调节多项式核函数与高斯核函数之间的比例系数。
在倾向性句子中,倾向性词、形容词、动词的贡献较大,但副词也起了一定的作用,例如:屡次、终于、必定、的确、尤其。设倾向性词、形容词、动词及副词[15]的 n-元短语模式为 phr=(t1,…tkey,…tn),则短语间的相似性核为:
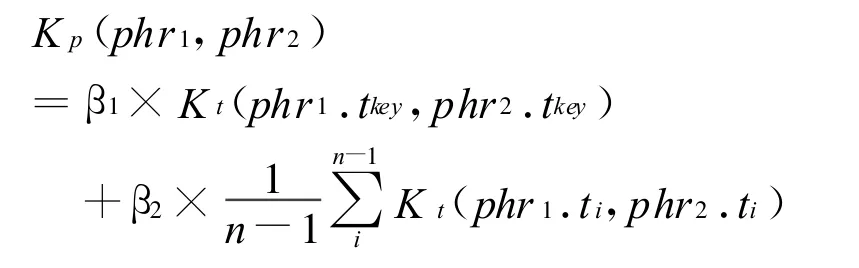
倾向性句子由倾向性词、形容词、动词及副词来体现出倾向性,我们可以利用句子中的倾向性词、形容词、动词及副词的短语集信息来计算句子间的相似性。短语集合间的相似性核可以定义为:
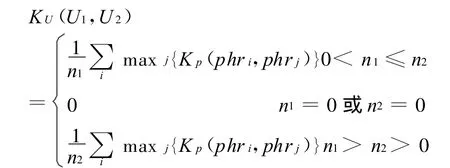
其中,phri∈U1,1≤i≤n1,phrj∈U2,1≤j≤n2,n1为U1的元素个数,n2为U2的元素个数。
这样可以定义N-gram超核函数为:
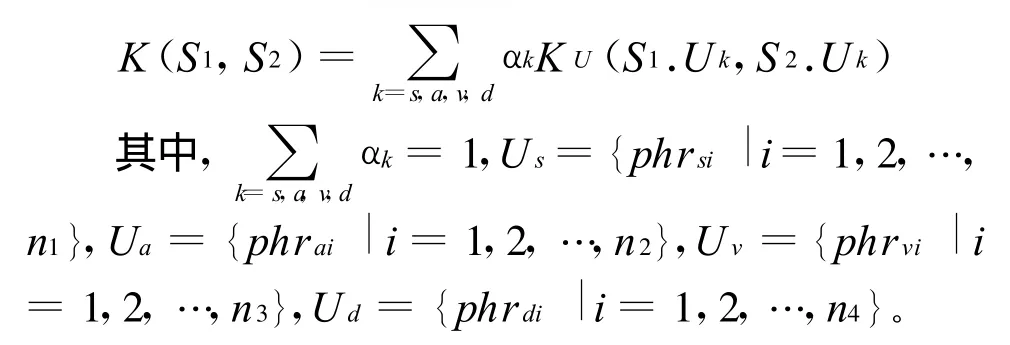
4 实验结果及分析
4.1 实验设计
语料采用第二届中文倾向性分析评测(COAE2009)任务三“中文观点句子抽取”的评测结果7335句以及从百度、Google的新闻、论坛、博客等网页中抽取的句子2059句,总共9394句:其中有5975个倾向性句子和3419个非倾向性句子。
为了验证N-gram超核算法的优越性,在算法之间的比较实验中,本文设计了三个实验:第一个是单核函数与超核函数之间的学习结果比较,以验证超核函数的学习能力;第二个是姚天昉提出的N-gram核[3]与加进副词短语集的N-gram核之间学习结果的比较,验证副词在倾向性句子中的作用;第三个是N-gram核与N-gram超核之间的比较,以验证N-gram超核的有效性。
实验以微F1值(MicroF1)和宏F1值(MacroF1)作为评价标准,采用三份交叉验证:首先把整个语料分成三份,然后取其中的两份进行训练,另一份作为测试数据,再把这三次的平均结果作为实验结果。
此外,本文采用了大小为5234的倾向性词表,其中褒义词2418个,贬义词2816个。分句、分词采用哈尔滨工业大学信息检索研究室提供的LTP分句工具和中国科学院计算技术研究所提供的ICTCAS分词工具。
4.2 评价标准
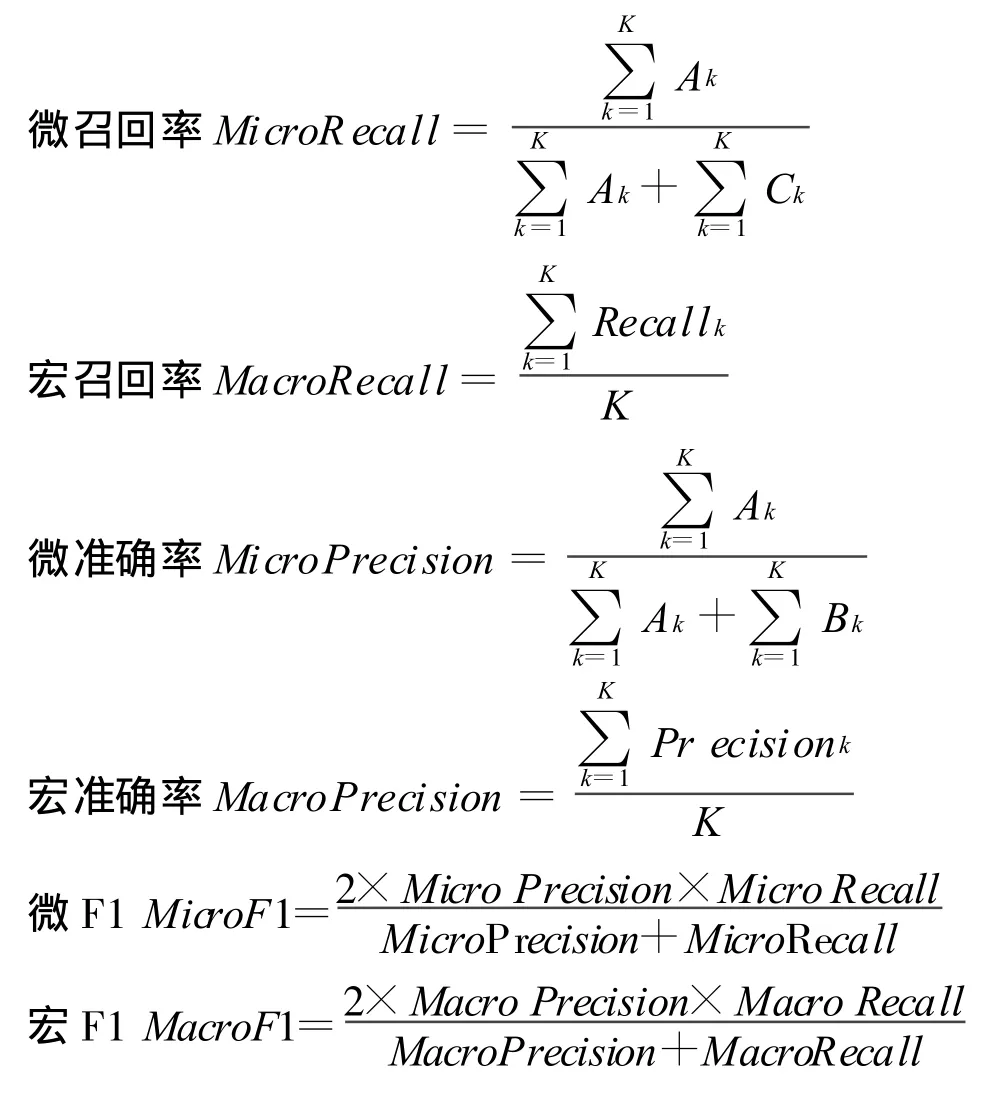
4.2.1 召回率和准确率
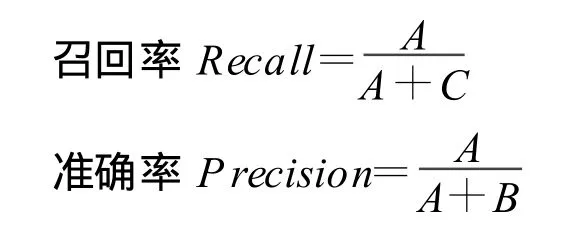
其中,A表示正确地分配到该类别的句子数;B表示不正确地分配到该类别的句子数;C表示被该类别不正确拒绝的句子数。为了便于理解,我们在表1中给出了A,B,C三者之间的关系。
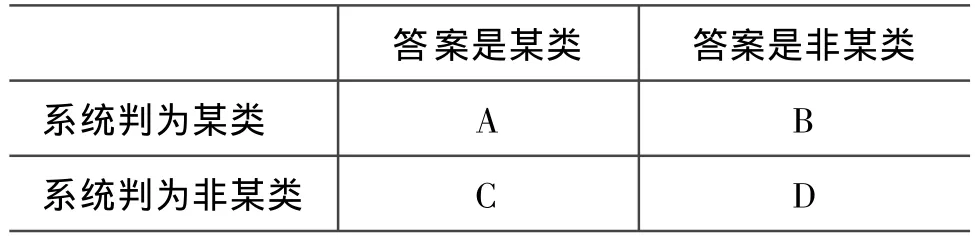
表1 邻接表
4.2.2 微F1和宏F1
4.3 实验结果及分析
为了验证超核函数是否比单核函数具有更好的学习能力,首先基于4.1节介绍的语料,采用多项式核函数、径向基核函数和Smitsgt等[14]设计的超核函数进行分类比较,实验结果如表2和表3所示。

表2 Smitsgt超核函数与单核函数的微F1值/%
从表2和表3可以看出,三种核的微F1值都在60%左右,宏F1值都在53%左右,说明超核函数继承了多项式核函数学习能力强的优点,具备了良好的学习能力。同时,如果不充分考虑数据特征,只是把超核函数直接应用于同样的特征矩阵,超核优越性不能得到很好的体现。

表3 Smitsgt超核函数与单核函数的宏F1值/%
在3.2节中提到,副词在倾向性句子中也起到一定的作用,例如:
“人民终于创立了自己的基业,夺取了政权。”
“她们的敬业精神尤其值得我们学习。”
在例句中副词:“终于”、“尤其”虽不带有倾向性,却提升了倾向性句子的倾向程度。因此在该比较实验中,本文在姚天昉等[3]提出的N-gram核基础上,在短语集中加入副词短语集构成Adv+N-gram核与N-gram核进行微F1值和宏F1值的比较,验证添加副词短语集的合理性。同时,为了验证本文所提出的改进算法是否有效,基于4.1节介绍的语料,以微F1值与宏F1值作为评价指标,将N-gram核与N-gram超核进行比较。实验结果如表4和表5所示。
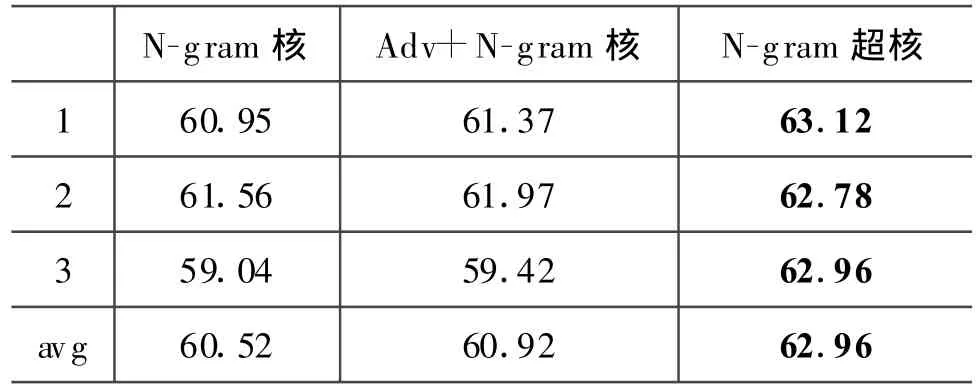
表4 N-gram核、Adv+N-gram核和N-gram超核的微F1值/%

表5 N-gram核、Adv+N-gram核和N-gram超核的宏F1值/%
从表4和表5中,可以看出:
◦Adv+N-gram核的微F1值和宏F1值都比N-gram核的稍高,这表明中倾向性句子识别中加入副词短语集是有效的,Adv+N-gram核比N-gram核更能消除倾向性词表覆盖率不足的影响;
◦N-gram超核的微F1值和宏F1值比N-gram核的都来得高,这表明设计的N-gram超核更具有捕获上下文信息和句法信息的能力,能更有效的提高分类的精度;我们设计的N-gram超核能有效扩张倾向性词表,弥补倾向性词表覆盖率不足的缺陷,更能从语义层面判断中文句子的倾向性。
综合以上实验结果,基于N-gram超核的方法是一种有效的倾向性句子识别方法。它不仅考虑了倾向词并且考虑了句中的形容词、动词和副词,从一定程度上弥补了倾向性词表覆盖率不足的缺陷。通过N-gram超核函数的定义,超核的方法能够从上下文信息和语义层面上捕获倾向信息,提高分类的准确率。
5 总结
针对中文句子的句法、语义及上下文信息,本文提出了一种基于N-gram超核函数的中文倾向性句子识别算法。该方法考虑句子的句法、语义等特征,利用超核函数构造N-gram超核函数,最后采用支持向量机识别中文倾向性句子。实验结果表明,与单核函数和姚天昉等提出的N-gram核[3]相比,N-gram超核从上下文信息和和语义层面上捕获倾向信息,提高倾向性句子识别的精度。
致谢
感谢中国科学院计算技术研究所为我们提供ICTCLAS分词工具和哈尔滨工业大学信息检索研究室为我们这个任务提供LTP分句工具。
[1]C.Macdonald,I.Ounis,I.Soboroff.Overview of the TREC-2007 Blog Track[C]//The sixteenth International Text REtrieval Conference,2007.
[2]许洪波,姚天昉,黄萱菁.第二届中文倾向性分析评测[C]//(COAE2009),上海,2009.
[3]Linlin Li,Tianfang Yao.A Kernel-based Sentiment Classification Approach for Chinese Sentences[C]//Sixth International Conference on Advanced Language Processing and Web Information Technology,IEEE,2009.
[4]Peter D.Turney,Michael.Littman.Measuring Praise and Criticism[C]//Inference of Semantic Orientation from Association,ACM Transactions on Information Systems,2003:315-346.
[5]Hatzivassiloglou,V,McKeown,K.R.Predicting the semantic orientation of adjectives[C]//Proceedings of the Eighth Conference on European Chapter of the Association For Computational Linguistics.European Chapter Meeting of the ACL.Association for Computational Linguistics,Morristown,NJ,1997:174-181.
[6]Yi,J.,Nasukawa,T.,Bunescu,R.,Niblack,W.Sentiment analyzer:Extracting sentiments about a given topic using natural language processingtechniques[C]//The Third IEEE International Conference on Data Mining,November 2003,.IEEE Computer Society Press,Los Alamitos,2003:427-434.
[7]BoPang,Lillian Lee,Shivakumar Vaithyanathan,Thumbs up?Sentiment Classification using Machine Learning Techniques[C]//Conference on Empirical Methods in Natural Language Processing.2002:79-86.
[8]L.Mangasarian,D.R.Musicant.Lagrangian support vector machines[J].Journal of Machine Learning Research,2001,1:161-177.
[9]徐琳宏,林鸿飞,杨忠豪.基于语义理解的文本倾向性识别机制[J].中文信息学报,2007,21(1):96-100.
[10]Aizerman M,Braverman E,Rozonoer L.Theoretical foundations of the potential function method in pattern recognition learning[J].Automation and Remote Control,1964,25:821-837.
[11]Mercer J.Functions of positive and negative type and their connection with the theory of integral equations[J].Philosophical T ransactions of the Royal Society of London,1909,A209:415-446.
[12]Chapelle O,Vapnik V N,Bacsquest O,et al.Choosing multiple parameters for support vector machine[J].Machine Learning.2002,46:131-159.
[13]Cucker F,Smole S.On the mathematical foundations of learning[J].Bulletin of the American Mathematical Society,2001:1-49.
[14]Smithsgf,Jordaanem.Improved SVM regression using mixtures of kernels[C]//Proceedings of the 2002 International Joint Conference on Neural Networks.Washington,DC:IEEE,2002,3:2785-2790.
[15]Turney P,Littman M..Measuring praise and criticism:Inference of semantic orientation from association[J].ACM Transactions on Information Systems,2003,21(4):315-346.
