基于模型驱动数据挖掘的低阻油层识别方法
2010-09-07朱丽萍李雄炎李洪奇
朱丽萍,李雄炎,李洪奇,
(1.中国石油大学(北京)计算机科学与技术系,北京 102249; 2.中国石油大学(北京)油气资源与探测国家重点实验室,北京 102249; 3.中国石油大学(北京)地球探测与信息技术北京市重点实验室,北京 102249)
基于模型驱动数据挖掘的低阻油层识别方法
朱丽萍1,李雄炎2,3,李洪奇1,2,3
(1.中国石油大学(北京)计算机科学与技术系,北京 102249; 2.中国石油大学(北京)油气资源与探测国家重点实验室,北京 102249; 3.中国石油大学(北京)地球探测与信息技术北京市重点实验室,北京 102249)
基于多参数信息的低阻油层的识别属于高维、非线性的模式识别问题.结合研究工区低阻油层储层特征,分析研究工区构造和沉积特征,以数据挖掘方法为基础,确定模型驱动数据挖掘的理论框架;以测井、岩心和试油的相关信息为源数据,利用聚类和关联分析获取敏感参数;以敏感参数为核心,采用决策树、贝叶斯网络、支持向量机和人工神经网络方法获得多参数组合的预测模型,并结合参数的物理含义和低阻油层的实际特征,对预测模型进行修正,改进预测模型的实用性.结果表明:利用模型驱动数据挖掘方法得到的最优预测模型,预测研究工区的低阻油层的识别准确率为90.05%.
模型驱动;数据挖掘;低阻油层;储层预测;特征参数;预测模型;识别
0 引言
20世纪90年代以来,由于低阻油层分布广、储量大、评价难、易遗漏,一直受到普遍的关注,是老井复查、二次开发、多次开发、高成熟精细勘探阶段的主要目标[1].根据区块地质特征,定义低阻油层,形成基于低阻油层成因机理研究的低阻油层识别方法[2-6],同时分类归纳算法中的支持向量机在低阻油层的识别中也有不同程度的应用[7-8].由于实际地质特征的复杂性和测井曲线的模糊性,使得基于成因机理的测井解释模型存在较大依赖性,反映在方法上是误差较大、评价及识别的准确率较低.由于算法单一,基于支持向量机的识别方法仅考虑数据驱动,没有与地质和地球物理背景有效结合完善预测模型.因此,尽管支持向量机对小样本具有较强的学习和泛化能力,获得较高的识别率,但对未知领域低阻油层的发现缺乏指导意义.
数据挖掘技术在油藏管理和油藏描述、提高采收率、精细勘探、地学数据处理等方面有不同程度的应用[9-12],可是没有形成系统的挖掘思路,受数据源的有限性和方法的单一性制约,并未在地质和地球物理背景下取得实质性的挖掘成果.笔者考虑模型驱动,形成模型驱动数据挖掘的理论框架,根据研究工区低阻油层的特征,以系统挖掘作为指导,最大限度地获取各种属性之间的内在联系,生成预测低阻油层的模型,这对研究工区低阻油层的勘探开发具有一定的理论和实践意义.
1 基本原理
1.1 模型驱动数据挖掘
数据挖掘(Data Mining)出现于20世纪80年代后期,是从海量数据中获取正确的、新颖的、潜在有用的、最终可理解的模式的非平凡过程[13].在数据挖掘的早期研究中,算法的高效性和工具的灵活性是人们热衷的对象,但是现实世界中的各种限制被忽略了,致使考虑数据驱动所获取的知识大部分不具有实用性.为了克服数据挖掘算法和工具的“高效”与所获取知识的“低能”之间的矛盾,“领域驱动数据挖掘(Domain-Driven Data Mining)”被提出[14-15],即将相关领域的先验知识作为附属条件,使其参与挖掘过程,利用该条件的限制作用,对所获取知识的实用性进行检验,确保最终挖掘所得知识对于目标事物具有足够的有效性.对储层评价和流体识别领域,各种解释和评价模型蕴含着丰富的领域知识,因此传统的解释和评价模型可以作为储层评价和流体识别领域的背景知识,参与和限制整个挖掘过程,将其有效地融合于数据挖掘的理论框架中,即“模型驱动数据挖掘”,其主要方法有聚类分析、关联分析和分类归纳等算法.
1.1.1 聚类分析
将物理或抽象对象的集合分成相似的对象类的过程称为聚类,它是一种在无监督的情况下根据对象间的相似程度自动地将其分割为一组有意义的类的处理过程[13].无监督是指待分类对象没有预先给定的类标识;有意义是指聚类的结果应该反映原始数据的自然结构特征.聚类分析的三要素为相似性测度、聚类准则和聚类算法.对单一属性,聚类分析可以通过聚类而间接实现连续型数据的离散化,是一种数据归约的形式,即以区间的形式分割数据;对多个属性,聚类分析按不同的试油结论进行聚类,可以间接获取不同参数组合对目标储层的敏感性.
1.1.2 关联分析
关联分析是发现无明确因果关系的属性之间内在联系最有效的方法之一,以支持度和置信度为主、提升度为辅的评估框架衡量已发现的规则,结合实际背景展开分析.由于关联分析不能处理连续性数据,因此在进行关联分析之前必须对数据进行离散化.离散化方法的选择对关联分析的结果影响很大.
1.1.3 分类归纳
分类归纳是以核心参数为中心,进行多种参数组合,获得已知属性与目标属性之间的关系,决策树、贝叶斯网络、支持向量机和神经网络具备这一功能,只是算法原理和所获取知识的表达形式有所区别.
决策树(Decision Tree)由内部节点和叶子节点构成,以分类和决策为目的[13],其建树过程分为树生成和树剪枝.它简单直观、建立速度快、精度高、生成的规则容易理解,可以处理连续值和离散值属性,并能清晰显示属性的权重.
贝叶斯网络(Bayesian Network)是基于概率分析、图论的一种不确定性知识表达和推理模型,提供一种将知识直觉地图解可视化的方法[13].它是一个有向无环图,由代表变量的节点及连接节点的有向弧构成,有向弧代表变量间的关系,变量之间的关系强度由节点与其父节点之间的条件概率表示.对不完全数据和变量间的因果关系,贝叶斯网络具有较强的处理和学习能力.
支持向量机(Support Vector Machine)是根据有限的数据信息,在训练样本中构造最优分类超平面,在尽可能正确分开两类样本的同时使两类差异性最大.支持向量机寻找最优分类超平面的方法是通过核技巧,将待挖掘的数据点投影到高维空间,在高维空间寻找具有最大分类间隔的超平面,即最优分类超平面[13].因此,对两类属性进行判别,支持向量机有较强的能力;对高维属性的样本,支持向量机也有很好的泛化和推广能力.
人工神经网络(Artificial Neural Network)是模拟生物的直观性思维建立起来的一种信息智能处理系统,具有自组织、自学习、快速处理及很强的非线性函数逼近能力等特点,由神经元、网络结构和学习规则组成.神经元是构成网络的基本单位,网络结构是由多个神经元按一定规则通过权重联接在一起的网状结构,学习规则是神经元之间连接权重的调整方法[13].人工神经网络通过对样本进行有限次数的迭代学习,计算所得的预测模型为黑盒,故存在未知性和不确定性.
1.2 识别流程
基于模型驱动数据挖掘识别低阻油层的流程见图1,分为数据预处理、特征参数的提取、预测模型的建立和预测模型的修正.数据的预处理是指根据曲线定性的形态模型和定量的数值模型,采用数据清洗、聚类分析等方法排除质量较差、数值异常的数据点,使数据源具有较高的质量.另外,为了丰富数据的维数和可能敏感的特征参数,理性和非理性的数据变换和构造也是数据预处理的重要环节.特征参数的提取是指结合每个参数具体的物理模型,利用聚类分析和关联分析获取对目标储层敏感的特征参数.由于部分参数受非低阻油层特征的影响,使其在数值上表现出多解性,因此有必要结合参数的物理模型,正确分析数值特征的原因,最后确定对低阻油层敏感的特征参数.预测模型的建立是指运用分类归纳中的多种方法,分析以敏感参数为核心的多组参数组合,以准确率为主要评估指标,参考每个参数的物理模型和研究区低阻油层的储层特征,形成低阻油层的初步预测模型.预测模型的修正是指在实际的应用过程中,结合非模型因素所导致的问题对预测模型进行修正,改进预测模型的实用性.另外,预测模型的建立和修正有时可能是一个循环反复的过程,应根据具体问题,最大化预测模型的实用性.
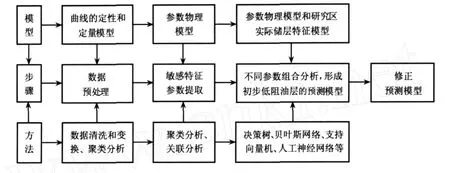
图1 基于模型驱动数据挖掘识别低阻油层的流程
2 低阻油层识别
2.1 研究区块概况
某研究区块为构造-岩性油藏,从三角洲内前缘相过渡到三角洲外前缘相,并且分布大面积的滨湖沉积和部分滨湖泥坪.储层类型以席状砂和滨湖砂脊为主,岩性主要为一套灰色粉砂岩夹灰、灰绿色泥岩及过渡岩性.由于薄互层发育,受岩性细、泥质和地层导电矿物含量高、外来液侵入、压裂等因素影响,使得油水关系相对复杂,表现为油层电阻率接近或小于本地区相同地质条件下的水层电阻率,给依赖传统模型法的测井解释带来困难,其识别精度有限.
研究区有试油结论的97口探井和评价井,包含272个试油层段,其中油层(124个)、油水同层(43个)、水层(53个)、低阻油层(52个),油层相对比较发育.测井信息主要包括LLD(深侧向电阻率)、LLS (浅侧向电阻率)、ILD(深感应电阻率)、ILM(中感应电阻率)、DEN(体积密度)、CNL(中子孔隙度)、AC (纵波时差)、CAL(井径)、GR(自然伽马)和SP(自然电位).
2.2 预测模型
特征参数的选择是构建预测模型的核心问题,基于等频和聚类离散化方法[13],当最小支持度和置信度分别为10%、80%时,LLD、AC、GR与不同的储层类型有较强的关系.以特征参数LLD、AC、GR为核心,进行多参数组合,以决策树、贝叶斯网络、支持向量机和人工神经网络的整体识别率为衡量指标,选取最优参数组合对低阻油层进行评价,结果见表1.
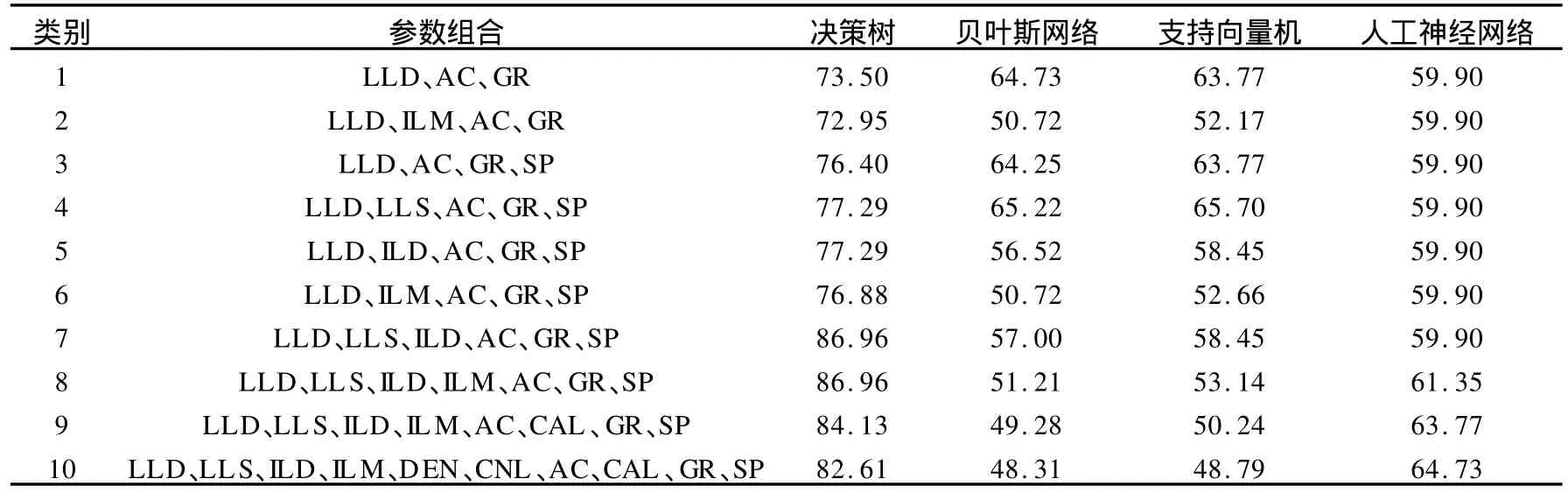
表1 挖掘多种参数组合的识别结果%
由表1可知,由于不同方法的算法机理存在一定的差异,4种方法在不同的参数组合上所获得的整体识别率明显不同,其中决策树在LLD、LLS、ILD、AC、GR、SP(第7种)参数组合获得最高的整体识别率,其生成树结构见图2,深度为8.
以决策树为主要方法, LLD、LLS、ILD、AC、GR、SP为主要参数组合,兼顾其他3种方法和参数组合,得出全区识别油层、油水同层、水层和低阻油层的预测模型,结合微相特征和测井曲线的物理意义对预测模型进行修正,结果见表2.为便于理解,模型的表达形式主要以规则为主.研究区低阻油层定义为电阻率小于围岩电阻率2倍的油层,反映在数值上是电阻率小于7,甚至小于水层的电阻率.
由表2可知:低阻油层、油层和水层的识别规则中深侧向电阻率反映电阻率的特点,符合实际的储层特征.另外,低阻油层不同的识别规则中,不同曲线在数值上的差异性反映不同成因导致的低阻油层.油层和低阻油层的识别率明显高于整体识别率的86.96%,油水同层和水层的识别率稍低,其主要原因是油层和低阻油层的储层性质特殊,物理特征明显,反映在数据上是数值特征规律性较强.
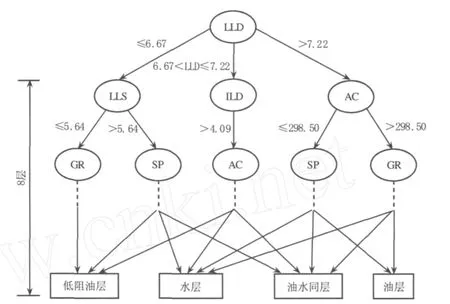
图2 某研究区块的决策树结构
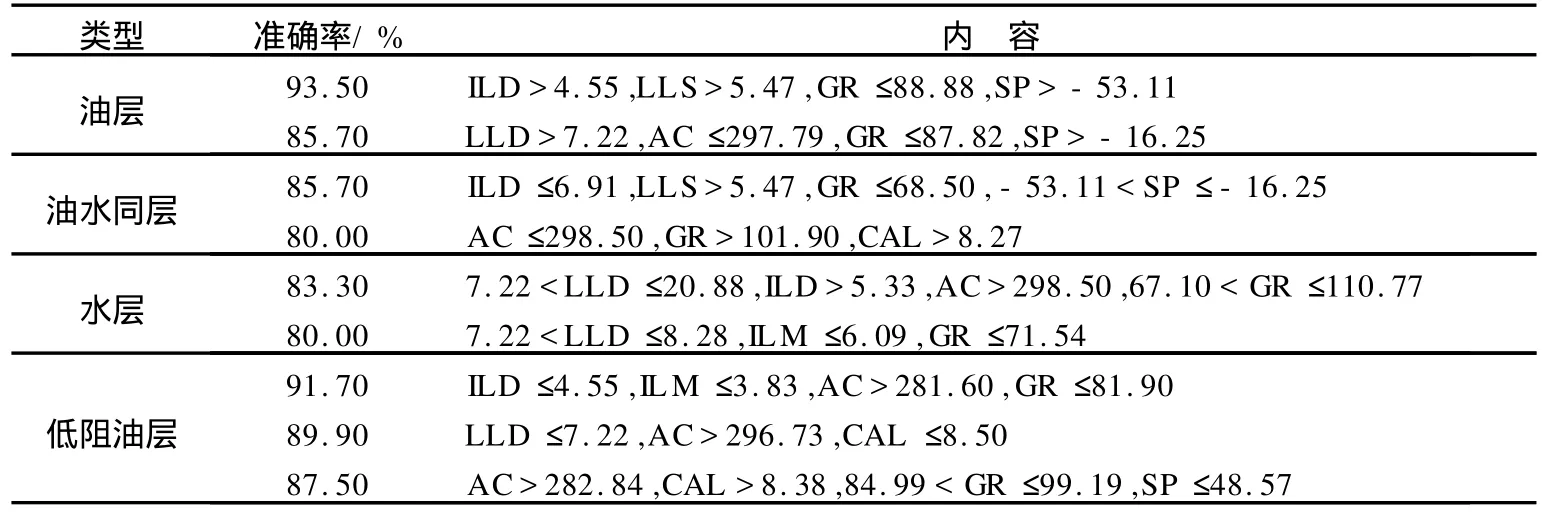
表2 数据挖掘预测模型的规则
3 应用实例
为了验证和改进预测模型的有效性和实用性,利用表2不同类型储层的预测模型衍生低阻油层、油层和油水同层的识别参数,分别为DZYC、YC和YSTC,其值为1时,指示对应的层段分别为低阻油层、油层和油水同层;其值为0时,不是相应的储层类型.对研究工区的97口试油老井进行复查,新发现12个油层、9个油水同层和20个低阻油层,净增有效厚度66.75m;整体识别的准确率为86.96%,低阻油层识别的准确率为90.05%.
其中A井处于三角洲内前缘的河口坝微相和构造的低部位,岩性以细粉砂岩为主,泥质含量高,砂泥岩薄互层和微孔隙较发育,为低阻油层的发育提供有利条件.DZYC新发现1号和2号层为低阻油层,射孔产油,净增有效厚度6.60m;YC指示3号和4号层为油层,试油结论为日产油6.37t.与正常油层相比,1号和2号层的低阻油层在电阻率上明显偏小;与围岩相比,低阻油层的电阻率和三孔隙度曲线变化的幅度较小,其含油特征不明显,隐蔽性较强.
B井处于研究区的边部,受压裂的影响,油藏不同程度地被破坏;储层致密和高含钙造成油水呈非均质分布,致使储层产油、产水交替出现,油水同层较发育.YSTC新发现1号和2号层为油水同层,净增有效厚度0.55m;YSTC指示3号层为油水同层,射孔日产油3.10t、日产水2.70m3.由于部分可动水的存在,与围岩相比,油水同层的三孔隙度曲线,尤其是纵波时差曲线的变化幅度较小,反映含油性的特征较微弱.
4 结论
(1)模型驱动数据挖掘方法以地质背景为基础,综合考虑储层的岩性、物性、流体和导电矿物的导电性,利用决策树、贝叶斯网络、支持向量机和人工神经网络等分类归纳方法构建低阻油层和其他储层的最优预测模型,并结合实际储层特征对预测模型进行适当修正,提高其实用性,识别低阻油层的准确率为90.05%.
(2)在该方法实现过程中,盆地类型、沉积因素和储集层岩性结构等地质因素为待挖掘数据进行分类提供标准;测井曲线的物理意义为特征参数的选择提供参考,同时二者也能对挖掘结果进行验证.
(3)数据源的准确性和丰富程度决定挖掘结果的可靠性,结合背景对预测模型进行合理性的修正决定识别的准确率.从理论探索的角度,模型驱动数据挖掘方法的量化处理方法增强分析和解决问题的客观性,减少随意性,为石油天然气勘探开发提供一种新的思路和手段.
[1] 李国欣,欧阳健,周灿灿,等.中国石油低阻油层岩石物理研究与测井识别评价技术进展[J].中国石油勘探,2006(2):43-50.
[2] 孙建孟,陈钢花,杨玉征,等.低阻油气层评价方法[J].石油学报,1998,19(4):83-88.
[3] 李薇,田中元,闫伟林,等.Y油田低电阻率油层形成机理及RRSR识别方法[J].石油勘探与开发,2005,32(1):60-62.
[4] 汪爱云,宋延杰,刘江,等.葡西地区低阻油层的成因[J].大庆石油学院学报,2005,29(1):18-20.
[5] 唐晓敏.低阻油层通用有效介质电阻率模型研究[D].大庆:大庆石油学院,2007.
[6] 唐晓敏,宋延杰,张传英.低阻油层通用有效介质对称电阻率模型的应用[J].大庆石油学院学报,2008,32(2):18-25.
[7] 连承波,赵永军,钟建华,等.基于支持向量机的低阻油层识别方法及应用[J].石油天然气学报,2008,30(1):80-82.
[8] 张银德,童凯军,郑军,等.支持向量机方法在低阻油层流体识别中的应用[J].石油物探,2008,47(3):306-310.
[9] 石广仁.支持向量机在多地质因素分析中的应用[J].石油学报,2008,29(2):195-198.
[10] 石广仁,张光亚,石骁騑.多地质因素的勘探目标优选—人工神经网络法与多元回归分析法比较研究[J].石油学报,2002,23(5):19 -22.
[11] 张绍红.概率神经网络技术在非均质地层岩性反演中的应用[J].石油学报,2008,29(4):549-552.
[12] 候键,郭兰磊,元福卿,等.胜利油田不同类型油藏聚合物驱生产动态的定量表征[J].石油学报,2008,29(4):577-581.
[13] Han Jiawei , Micheline K. Data mining concept s and techniques[M] . Second Edition. Beijing : China Machine Press , 2006
[14] Wang G Y, Wang Y. Domain-oriented data-driven data mining : A new understanding for data mining[J ] . Journal of Chongqing Universityof Posta and Telecommunications : Natural Science Edition , 2008 ,20 (3) ,266 - 271.
[15] Cao L B , Zhang C Q. Domain-driven actionable knowledge discovery in t he real world ∥The Lot h Pacific-Asia Conference on KnowledgeDiscovery and Data Mining[ C] . Singapore : Springer , 2006 :821 - 830.
Identifying the lowresistivity oil reservoir based on the model-driven data mining/2010,34(4):30-34
ZHU Li-ping1,LI Xiong-yan2,3,LI Hong-qi1,2,3
(1.Department ofCom puter Science and Technology,China University ofPetroleum(Beijing), Beijing102249,China;2.State Key L aboratory ofPetroleum Resource and Prospecting,China University ofPetroleum(Beijing),Beijing102249,China;3.Key L aboratory of Earth Prospecting and Inf ormation Technology,China University ofPetroleum(Beijing),Beijing102249,China)
The identification of the low resistivity oil reservoir based on many logging information is actually of a high-dimensional,non-linear pattern recognition.In the premise of fully awareness of the structural features and sedimentary characteristics in the region of interest,the fundamental principle of model-driven data mining is generated based on the data mining concepts and techniques.On the basis of the logging data,core data and well testing data,the cluster analysis and association analysis can help us to obtain the sensitive parameters.With the sensitive parameters as the core,the Decision Tree,Bayesian Network,Support Vector Machine and Artificial Neural Network would acquire the initial predictivemodel to identify the low resistivity oil reservoir.Its practicability will be improved after the initial predictive model is corrected.The recognition accuracy rate of the optimal model to predict the low resistivity oil reservoir is up to 90.05 percent.
model-driven;data mining;low resistivity oil reservoir;reservoir prediction;characteristic parameter;predictive model;identify
book=4,ebook=391
TE19
A
1000-1891(2010)04-0030-05
2010-03-26;审稿人:袁 满;编辑:任志平
国家高新技术研究发展计划863项目(2009AA062802)
朱丽萍(1973-),女,硕士,副教授,主要从事数据挖掘、计算机网络方面的研究.
