An HLA/RTI Architecture Based on Multi-thread Processing
2010-07-25GUANLi管莉ZOURuping邹汝平ZHUBin朱斌HAOChongyang郝重阳
GUAN Li(管莉),ZOU Ru-ping(邹汝平),ZHU Bin(朱斌),HAO Chong-yang(郝重阳)
(1.Institute of Electronics and Information Engineering,Northwestern Polytechnical University,Xi'an 710072 Shaanxi,China;2.No.203 Research Institute of China Ordnance Industries,Xi'an 710065 Shaanxi,China)
Introduction
HLA,as a criterion of new distributed interactive simulation architecture,has been officially accepted as IEEE standard.By virtue of its reusability and excellent interactivity,it has been widely used in various simulation systems for military and civil gradually.RTI(run time infrastructure)[1]is a middleware that provides essential service to HLA and fits the interface of HLA.As the real-time distributed interactive simulation becomes predominant,better and better predictive ability of RTI is required.However,generally,HLA aims at large-scale distributed simulation.Network system standards are too complex.And,its RTI's realtime performance is relatively good[9-10],it still can not satisfy the requirements in small and medium realtime simulation[5]. Normally, the requirements for real-time performance in the small and medium simulation systems are tens of milliseconds,therefore,the communication efficiency and real-time performance of HLA system are influenced certainly.This is also one of the major reasons why HLA/RTI's applications for comparatively high real time requirement are restricted.Therefore,some scholars propose using transport protocols with specific purpose,rather than the traditional TCP/UDP protocol in RTI to enhance communication performance.As for this method,Bruzman,et al.[2]suggested a VRTP(virtual reality transport protocol),which satisfies the basic requirements of distributed real-time interaction between RTI and federate and among federates.Some scholars put forward the usage of QoS communication and RTOS(real-time operating system)instead of GPOS(general purpose operating system),so that RTI can provide real-time service[1,3].However,there are certain limitations in their application environment.Through the research on the interactive control in HLA system,this paper endeavors to improve and enhance the real-time performance of RTI.
Generally,the main factors that influence the real-time running of simulation system are the federates'time cost to run the simulation object model and the message communication time among federates.Regarding the later,the communication efficiency can be improved through introducing efficient message processing mode into the system's running mode.A multithread scheme with deprivation dispatch is generally adopted as the method to improve RTI system's realtime performance.Although the system's real-time performance can be improved to some extent in this way,it is still not sufficient in those occasions that have higher requirements.To this end,this paper adopts multithread processing model and multithread processing with the thread pool and dispatch strategy of semicomplete deprivation of priority to fulfill the requirements of real-time simulation,so that the system's realtime performance is improved.The distributed interactive simulation training system designed and developed by utilizing this processing mode has gained practical application.
1 HLA/RTI System
HLA is open software architecture,and can unite several computer simulation members to form a largescale simulation system.In HLA,the whole comprehensive simulation system is called as federation,while every simulation subsystem that constitutes the federation is named as federate.One federate consists of several objects,and the object is the basic element of federation.HLA mainly consists of three parts[4].
1)Rules.HLA defines ten rules to describe the responsibilities of federation and federates.They are the principle and agreement that must be complied with,for implementation of interaction among federates.
2)Object model templates(OMT).OMT is used to describe object model,including FOM(federation object model)and SOM(simulation object model).FOM describes the shared information and exchange conditions among members during federation execution,and SOM describes the capability that simulation member can provide when it participates in federation execution.
3)Interface specifications.The interface specification precisely defines the interface between federates and RTI.As the core component of HLA,RTI is a middleware that fits the interface of HLA[1]and provides essential service to HLA,and six management services for the system,including federation,time,statement, object, ownership and data distribution managements.
According to the rules of HLA,data communication among federates must be implemented through RTI.RTI is the core of HLA framework,and can be considered as a distributed operating system with specific function.Allfederatesexchange information through RTI,as shown in Fig.1.All federates and RTI constitute an open-ended distributed simulation system and make the whole system expandable.In the simulation,RTI is like a soft bus,and each federate can be inserted into RTI just like a plug-in,i.e.,it can join in or exit from federation at any time.In this way,the interconnection and interoperation of simulation system and reuse of federates are effectively supported.In the design of HLA,there is no definition for specific data structure similar to PDU(protocol data unit)in DIS to implement data exchange particularly.Instead,the interaction is realized according to the declaration/orderrelationship defined in FOM,thus,further enhances the flexibility of the system.Moreover,HLA does not have specific requirements on federate type.The federate can be a simulation model entity,an actual simulation agent,or a manager used for federation management,data acquisition and record.

Fig.1 HLA/RTI system
It can also be the interface between command and controlpersonneland simulation system,which achieves the intercommunication,interconnection and interoperation of different platforms.
2 Multi-thread Processing Model in RTI
In HLA system,different process models determine the ways that the federate calls from RTI and RTI calls callback function.They also decide how the fed-erates and RTI share CPU resource.The implemented already RTI has three process modes[5],namely,single-thread,asynchronous and multi-thread modes.For different applications,these three modes have their respective strengths and weaknesses.In order to implement efficient processing of RTI,this paper adopts multi-thread mode design,which directs at real-time RTI architecture.
In the implementation of multi-thread design,it is necessary to add two kinds of resources,the request signal and the message task queue.Besides, two threads are set up in the stage of federate initialization,which run in parallel,as shown in Fig.2.One of them is responsible for the extraction of local federates'requests for RTI service,while another takes charge of handling messages coming from communication channel,i.e.remote RTI service request.These two types of requests possess the same opportunity to be processed.Each thread has its corresponding request message queue,and stores in the queue the arriving message requests.Although the processes that the two threads gain messages are different,and the handling ways after extracting messages from the queues are not the same,either,the basic processing flows are the same.The process shown in Fig.3 is in circular running,if the external interruption or abnormality does not occur.

Fig.2 Multi-thread model
Firstly,the thread checks whether the waiting message queue is empty or not.If empty,the thread frees the system resource that has been taken up.Then,it is set to be in idle status,waiting for the arrival of messages.When receiving new message request,it gets signals and processes the request message.If the message queue is not empty,it processes the message on the very top of the waiting message queue accordingly,and releases this message.Then,it handles other message requests in the message queue with the same circular.The pseudo codes for processing message queue are listed as follows.

Fig.3 Thread processing procedure

The implementation method in this paper can expand the system,i.e.add more threads to serve more message queues according to demands.This type of multi-thread processing model can optimize the resource utilization more effectively.Besides,it handles parallel threads through eliminating dependency between federates and LRC,thus enhancing the overall real-time performance of the system.
3 Thread Dispatch Strategies
In the whole HLA system,except the multi-thread in RTI communication,each simulation member can also have other running threads,such as scene display thread and data processing thread,etc.Therefore,all the threads in the system should be reasonably dispatched according to their corresponding priority.Not only the threads with high priority should be responded to in time,but also their switching times should be reduced to the greatest extent,so as to reduce the necessary system cost for thread switching.In order to satisfy these requirements,the support from the structure is necessary;on the other hand,an appropriate dispatch strategy is required.This paper introduces the thread pool and the dispatch method of semi-complete thread deprivation to implement efficient parallel running of multiple threads.
3.1 Thread Pool
The thread pool is a set of threads,established at the start of application programs and destructed at the end of application programs[8].Before running the processing,the maximum number of threads that can run in parallel is designated according to the system resource,which is the most significant configuration parameter in the thread pool.
When a message requests for processing,its corresponding thread in thread pool is allocated to process this request.If there is no corresponding thread,then it is necessary to create a dynamic thread first.Then,the thread dispatch is carried out according to the maximum number of threads.When the thread number does not reach its limit,corresponding resource will be allocated to finish processing;however,when the thread number reaches its limit,it is necessary to process according to certain thread dispatch strategy.
All threads in thread pool share the same memory space and system resource,therefore,it is necessary to guarantee exclusive visit to shared resource,so as to maintain system stability.In operating system,a mutex technology is adopted to solve this problem,as shown in Fig.4.

Fig.4 Working process in mutex
Only if the queue is successfully locked by a certain thread,i.e.,the resource is exclusive to the thread,this queue can be visited by the thread.After the visit,the thread can unlock the mutex to release the shared resource.This method makes sure that every shared resource can only be processed by a certain thread at any given moment.The pseudo codes for multi-thread processing mode based on the thread pool are listed as follows.


3.2 Thread Dispatch with Semi-complete Deprivation
In multi-thread processing mode based on thread pool,the thread dispatch strategy influences system efficiency greatly.When the system resource is fixed,the system performance differs a lot if different dispatch ways are adopted.Generally,the multi-thread dispatch usually adopts a complete deprivation mode.In order to make sure that the request with the highest priority can be processed first,when there is no free resource in the thread pool to be allocated to some thread request for its processing,if the thread that is being processed is with lower priority,the processing right for the thread with lower priority will be deprived and transferred to the thread with higher priority.This thread dispatch way will result in relatively frequent switch of the thread control right among threads with different priorities,so that the system burden increases.In order to reduce the switch burden,this paper puts forward a semi-complete deprivation mode to dispatch the threads with different priorities,as shown in Fig.5.

Fig.5 Thread dispatch with semi-complete deprivation
In this mode,the threads are classified according to priority first.The threads with close priority are included into one set.When there is no resource to be allocated to new thread request,it should be judged whether or not the priorities of corresponding thread for new request and the thread with processing right differ a lot first,i.e.,whether they belong to the same set or not.If they belong to the same set,it is unnecessary to switch.If they are not in the same set,i.e.,the priorities differ a lot and the new request possesses higher priority,then things will go on according to deprivation based on higher priority.In this way,not only there is not much system thread switch cost,but also the system's relatively quick response to high priority is guaranteed.Balance is reached between these two aspects.The pseudo codes for thread dispatch strategy with semi-complete deprivation are listed as follows.


4 Implementation of Distributed Simulation System Based on HLA
4.1 System Design and Operation
In this paper,a certain missile's launching training system is designed.The system is a complicated human-machine system with the characteristics of realtime and openness.The system simulation involves multi-layer interaction between human and device and among devices.The design of the system with HLA architecture combines various kinds of resources necessary for system operation to implement the simulation of the whole process of missile launching.
Figure 6 shows a structure chart of all simulation members in the training system based on HLA.According to the system function and workflow analysis,eight federates are designed to compose this simulation system.They are 1)federate for task setting and management;2)federate for communication management;3)federate for simulation database;4)federate for training data record and analysis;5)federate for shooter;6)federate for target;7)federate for missile;8)federate for external hardware device.
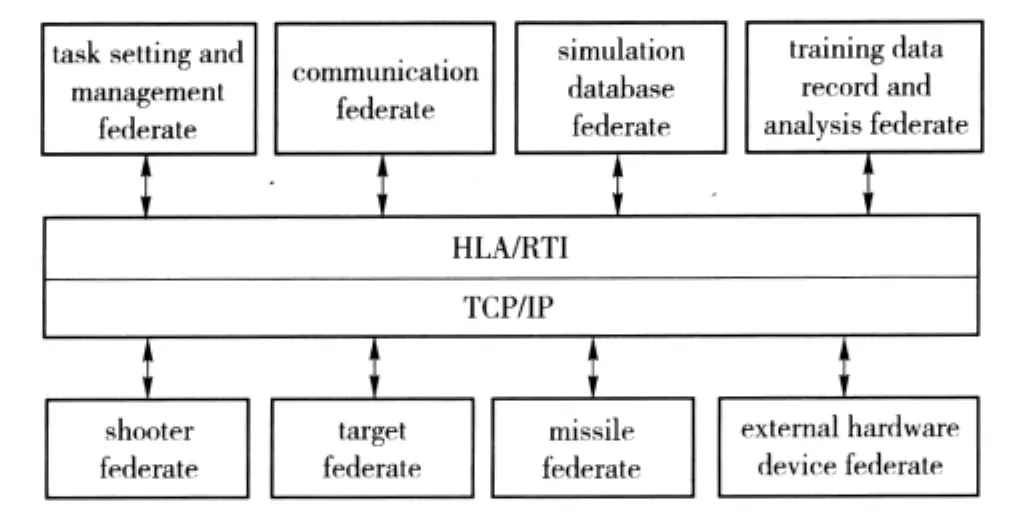
Fig.6 Basic structure of simulation member of missile launch training system based on HLA
All federates in the system do not communicate directly.Instead,they all connect with RTI.Their mutual communication is implemented through service provided by RTI.In bottom-level,TCP/IP network protocol is used to guarantee the communication quality.
During system operation,RTI and federate distributed on each simulation member get started respectively.At this moment,the federation execution does not exist yet.The creation of federation execution is completed through sending a“create federation execution”request to RTI by the first federate,generally,it is task setting and management federate.After the federation execution is created,the federates will apply to RTI to join in federation execution through activating RTI service.RTI will register an example of federate in corresponding federation execution according to the federate's application,and return the handle of this example to it.
After the simulation execution starts,each federate sends data only to its native RTI,and illustrates the specific position that data points to and other relevant information.The specific communication is completed by RTI.When RTI receives the request of“federation execution end”,it closes all the registered federate examples,and notifies them.Each federate ends the operation itself.
The test results show that,in the simulation system designed in this paper,the time cost to run simulation object model is approximately 1/3 to 1/2 of the message communication time.It is clear that the system's real-time performance can be effectively improved by reducing the message communication time among federates.This simulation system requires that the relevant command information's calculation and transmission should finish within 20 ms.RTI communication,which introduces the multi-thread processing mode and efficient thread dispatch strategy,not only guarantees the coordination of spatial,time and logical relationships among different simulation entity members,but also enables the transmission processing of simulation data among federates to satisfy the requirements of accuracy and real-time performance.
4.2 Communication Performance
The simulation system designed in this paper is used for testing.Under three different RTI communication ways,namely single-threaded,multi-thread with complete deprivation dispatch and multithread mode with semi-complete deprivation dispatch,the system's delays are measured and compared.
The test conditions are:8-10 federates;100 M Ethernet;all federates are running on Dell PC with over 2 GHz master frequency;operating system is Windows XP;timing system adopts CPU clock.
Under the circumstance there is no other message transmitted on the network,the test results of time delay for different data volumes in different RTI communication ways are shown in Fig.7.The horizontal axis denotes the data communication volume,while the vertical axis denotes the corresponding time delay in different communication ways.It can be seen from the results that the performance is best in multi-thread with semi-complete deprivation dispatch.Therefore,it is proved that the uses of multi-thread mode and thread dispatch with semi-complete deprivation can improve the communication performance of RTI and reduce the time delay of the system greatly.
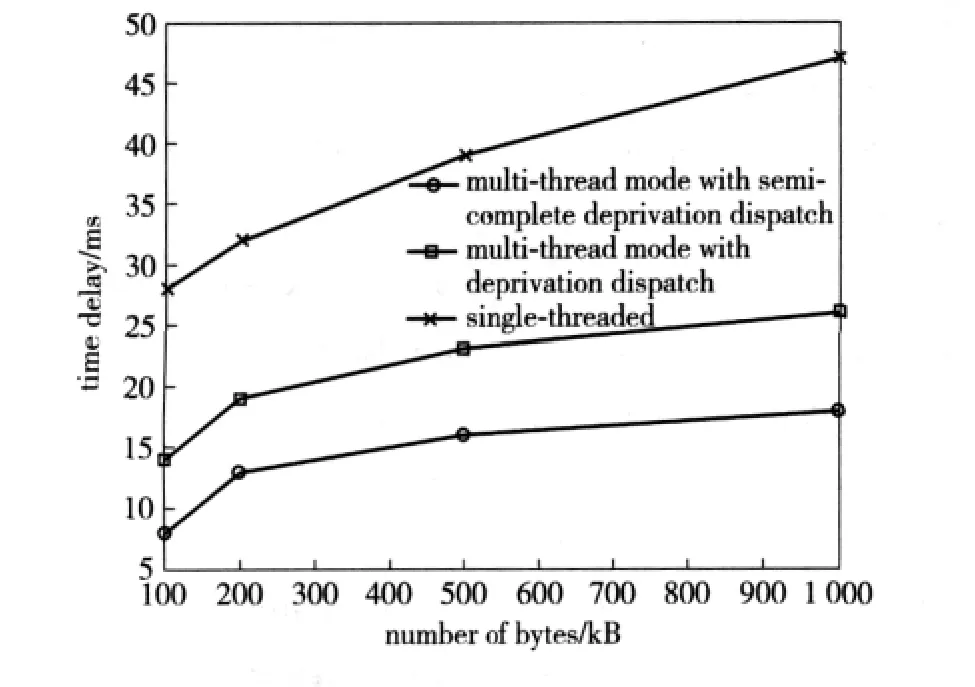
Fig.7 Performance comparison of three RTI communication modes
In the distributed simulation system designed in this paper,the average communication data rate is 0.5-1.5 kB/s.By means of adopting the RTI communication way described above,the average communication delay is 4 ms to 13 ms,which is better than single-threaded and multi-thread with deprivation dispatch and also fulfills the requirement of certain practical project.
5 Conclusions
Thispaperintroducesmulti-thread processing model into HLA/RTI architecture,and reduces system cost brought by frequent switch of thread control right through thread pool and dispatch strategy with semicomplete deprivation of priority,so as to improve the system's real-time performance.In addition,this paper applies this processing mode to the design of a certain distributed system.The efficiency of data communication among system members is guaranteed,and the system performance is enhanced.
[1]McLean R Fujimoto,Perumalla T K,Tacic I.Design of high performance RTI software[C]∥Fourth IEEE International Workshop on Distributed Simulation and Real-Time Applications(DS-RT'00),San Francisco,CA,USA.2000:89-96.
[2]Bruzman Don,Zyda Michael,Watsen Ken,et al.Virtual reality transfer protocol(vrtp)design rationale[C]∥Proc of the Sixth IEEE International Workshop on Enabling Technologies:Infrastructure for Collaborative Enterprises,Distributed System Aspects of Sharing a Virtual Reality,Cambridge,MA 1997:179 -186.
[3]ZHAO Hui,Georganas Nicolas D.Architecture proposal of real-time RTI simulation interoperability workshop[C]∥Proc 2001 Fall Simulation Interoperability Workshop,Orlando,FL,2001.
[4]WU Guo-qing,CAI Hong.Design and development of artillery command system simulation based on HLA/RTI[J].Fire Control& Command Control,2004,29(6):55-57.(in Chinese)
[5]YU You-zhi,SHEN Wei-qun,SONG Zi-shan,A realtime communications model based on HLA[J].Computer Simulation,2008,25(2):145 -147.(in Chinese)
[6]BI Hui-juan,WANG Xing-ren,PENG Xiao-yuan.Communication mechanism of HLA[J].Journal of System Simulation,1998,10(5):20 -25.(in Chinese)
[7]LIANG Yan-gang,TANG Guo-jin,WANG Feng.Research on strategy to improve real-time performance of HLA-based simulation system[J].Journal of System Simulation,2005,17(2):361 -363.(in Chinese)
[8]Azzedine Boukerche,LU Kai-yuan,A novel approach to real-time RTI based distributed simulation system[C]∥Proceedings of the 38th Annual Simulation Symposium(ANSS'05),2005:267-274.
[9]Roberts Chell A,Dessouky Yasser M.An overview of object-oriented simulation,Simulation,00S-SIW-85[EB/OL].http:∥www.sisostds.org,2004-08-15.
[10]Dahmann Judith S.Standards for simulation:as simple as possible but not simpler the high level architecture for simulation,Simulations,99F-SIW-54 [EB/OL].http:∥www.sisostds.org,2004-08-15.
杂志排行

Defence Technology的其它文章
- Analysis on Velocity Characteristics of Cavitation Flow Around Hydrofoil
- Influence of Accelerated Aging on Detonation Performance of Explosives
- Research on Additional Loss of Guidance Optical Fiber
- A Fuzzy Adaptive Algorithm Based on“Current”Statistical Model for Maneuvering Target Tracking
- Beam Pattern Synthesis Based on Hybrid Optimization Algorithm
- Robust Stability Criterion for Uncertain Neural Networks with Time Delays