基于运动矢量可分级的视频编码方法*
2010-06-25袁嘉晟方志军叶金财
袁嘉晟,方志军,叶金财
(江西财经大学 信息管理学院,江西 南昌 330013)
1 引言
为适应复杂多变的异构环境,视频编码引入了可分级编码的概念,可分级视频编码(Scalable Video Coding,SVC)可以使视频流较好地适应各种不同的网络环境和用户终端,并具有一定的容错性和可分级性。在编码后的视频流中,纹理信息占据了大部分比特,但是在低码率下,运动矢量占据了大部分的码流,如在可分级视频编码中,运动矢量占据了基本层码流中的绝大部分[1-2]。因此在可分级视频编码中,对运动矢量的可分级编码是一个重要要求,特别是在低码率或者小图像中。针对这一问题,笔者提出了一种基于运动矢量的视频可分级编码思想。
2 运动矢量编码技术与可分级技术
2.1 运动矢量
视频编码是数字视频处理的重要应用,在许多通信服务中起着至关重要的作用。视频序列在时间维上有很强的相关性,即存在着大量冗余,利用运动估计和运动补偿技术可以有效地去除视频帧间的冗余,实现编码压缩。运动估计是视频处理系统的一个重要的组成部分,已广泛运用于视频压缩的标准中。在运动估计中,模拟化运动的最简单形式是用一个常量位移表示,这个常量位移就是运动矢量(MV)。 图 1是测试视频序列“foreman”中第1帧到第2帧的运动矢量表示图。
计算出的运动矢量即可用于运动估计和运动补偿,图2是原视频序列第1帧和第2帧的直接差值效果图,图3是用加入运动矢量的视频第1帧,来预测第2帧,并将预测出的第2帧与原视频序列第2帧进行差值的效果。从图2和图3的比较中可以看出,若不加运动矢量,第1帧和第2帧的差值是明显的,两帧之间的变化部分可以清楚得看到;若加入运动矢量预测下一帧,预测效果明显变好,预测出的帧图像与原序列帧相差不大,其中可以根据搜索匹配块和精度的大小调节预测精度。
2.2 可分级技术

图1 第1帧到第2帧的运动矢量表示图

图2 原序列第1帧图像与第2帧直接差值

图3 加入运动矢量预测出的帧图像和原序列第2帧图像差值
可分级性(Scalable)是指通过仅解码一部分压缩的比特流物理地恢复有意义的图像或视频信息的能力[3]。即视频图像经过一次编码后,其压缩视频流的码率可以根据网络的变化而调节,生成不同码率的视频流,因此在码率降低后,视频流也可以解码后正常播放。因此可分级编码一般通过生成不同码率的视频流来实现,采取的方式有PSNR(质量)可分级、空间可分级、时间可分级或它们的组合。可分级编码技术将视频编码成N层可分级的比特流,第1层为基本层,其他层为增强层,第1层提供了能够解码重建最基本图像视频的比特流,对其他层的解码能提高重建图像视频的质量,直至最佳效果。目前视频编码中常用的可分级技术主要有质量可分级[4-6]、空间可分级[7]、时间可分级[8]等。
质量可分级是利用越来越精细的量化步长产生的图像信息的损失来对每帧图像进行分层。其基本思想是通过对原始图像和第1层重建图像之间的量化差值进行编码以形成增强层。
空间可分级是从改变单帧图像分辨力的角度来对视频进行分级,形成不同分层。其基本思想是通过解码第1层,形成一个低分辨力的图像版本,随后解码第2层,将第1层解码的图像内插到第2层解码图像中,随后以相同的方式解码后面的增强层。
时间可分级是从改变视频帧序列的帧率的角度对视频进行分级,形成不同分层。其基本思想是先将视频帧进行采样分割,基本层根据本身的数据编码以提供基本的帧率,增强层通过对基本层或增强层的预测编码,最后产生原始视频的全时间分辨力。
因为运动矢量是由两帧帧间的运动估计来表示,所以运动矢量具有时间可分级性,但是不经过编码的运动矢量并不具有质量可分级性和空间可分级性。在目前的大多数视频压缩编码标准里,如H.263,MPEG-4等,运动矢量的编码使用的是预测差分编码,即1个宏块的运动矢量与其空间相临的3个宏块的运动矢量的中值作差,然后对差值进行编码;而在MC-EZBC[9]中,提出了一种基于上下文的自适应二进制算数编码对运动矢量进行编码,使其具有质量可分级和空间可分级。
目前的这些运动矢量编码方法本质上是对块匹配后计算出的运动矢量比特流进行熵编码,并能够对编码后的比特流进行截取,达到相应的可分级性。然而这些运动矢量编码方法并没有对运动矢量本身进行分析,笔者针对这种情况,提出一种对运动矢量本身进行处理的的思路。
3 基于运动矢量模值可分级编码方法
前面提到的运动矢量编码方法虽然具有可分级性,但是这些编码方法都是编码所有的运动矢量,而当前视频编码标准中的运动估计中都是分块进行匹配,因此运动矢量本身存在着大量冗余,例如:相邻两帧块运动可能并不剧烈或者没有运动,其运动矢量的幅值不大或为零。试验发现,在运动矢量比特流中,有一些运动矢量对其后的运动估计和运动补偿预测的影响不大,但是这些运动矢量所占用的比特流还是一定的,因此可以将这些运动矢量的比特流进行截取以达到可分级的效果。
对运动矢量进行分析判断,先设定阈值T,将运动矢量的模与阈值比较,若运动矢量的模值大于阈值,则将该运动矢量保留,反之则去除。其判断依据为
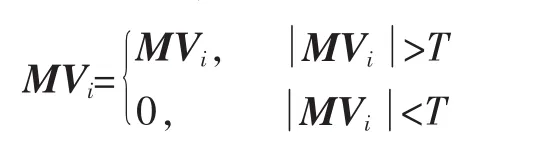
两帧之间的运动矢量存在一个最大值,因此T可以先取最大值,此时运动矢量比特流为0,随后逐渐减小T,可以逐步得到部分的运动矢量比特流,直到完全获取运动矢量比特流,最后再对截取出的运动矢量比特流进行相应的运动矢量编码。图4是阈值为5时测试视频序列foreman第1帧到第2帧截取后的运动矢量表示图。比较图1可见,一些模值相对小的运动矢量被去除了,如背景图案部分,而保留了模值较大即块运动较为剧烈的运动矢量,如脸部部分。

图4 阈值为5时,截取后第1帧到第2帧的运动矢量表示图
4 实验结果与分析
为了评估文中提出的思想,使用了stefan和foreman视频序列进行测试。其视频序列为CIF格式,帧率30 f/s(帧/秒),分块大小8,搜索范围4,精度为半像素。对视频的前2帧进行分析,将第1帧设为参考帧,第2帧设为预测帧,随后对计算出的运动矢量由阈值进行截取,得到运动矢量的比特流,计算其模值大小;然后将截取后的运动矢量加入到参考帧中,以预测下一帧;将预测出的帧图像与原序列第2帧作差值,算出方差和峰值信噪比。图5为foreman视频序列第1帧,图6为foreman视频序列第2帧,图7为在设定阈值为5时,加入截取后运动矢量比特流的foreman视频序列第1帧预测出的帧图像,图8为预测出的帧图像(阈值5)与原序列第2帧图像的差值图像。将图8与第2节介绍的加入全运动矢量比特流预测出的帧图像作比较,可以看到差别不是很大;但在一些运动变化较小的区域,差值的效果变得明显,如背景图案部分,这是因为经过阈值判断后,去除了模值小的运动矢量。

图5 foreman序列第1帧

图6 foreman序列第2帧

图7 阈值为5时的预测帧

图8 预测出的第2帧(阈值5)与原序列第2帧的差值图
针对foreman视频序列,表1显示的是在不同阈值下,第1帧加入运动矢量预测出的第2帧与原序列第2帧的方差(SE)和峰值信噪比(PSNR)值及待编码的运动矢量比特数。表中阈值为0时,表示运动矢量全保留,此时SE最小,PSNR和比特数最大;其次因为相邻两帧之间的运动矢量模值必存在一个最大值,在阈值达到这个最大值时,运动矢量将全被去除,此时相当于第1帧不预测,而差值正是两帧之间相减,此时SE最大,PSNR最小,比特数为0。
图9为stefan视频序列第1帧,图10为stefan视频序列第2帧,图11为在设定阈值为5时,加入截取后运动矢量比特流的stefan视频序列第1帧预测出的帧图像,图12为预测出的帧图像(阈值5)与原序列第2帧图像的差值图像。
针对stefan视频序列,表2显示的是在不同阈值下,第1帧加入运动矢量预测出的第2帧与原序列第2帧的方差和峰值信噪比值及待编码的运动矢量比特数。

表1 foreman视频序列在不同阈值下的SE和PSNR和比特数

图9 stefan序列第1帧

图10 stefan序列第2帧

图11 阈值为5时的预测帧

图12 预测出的第2帧(阈值5)与原序列第2帧的差值图
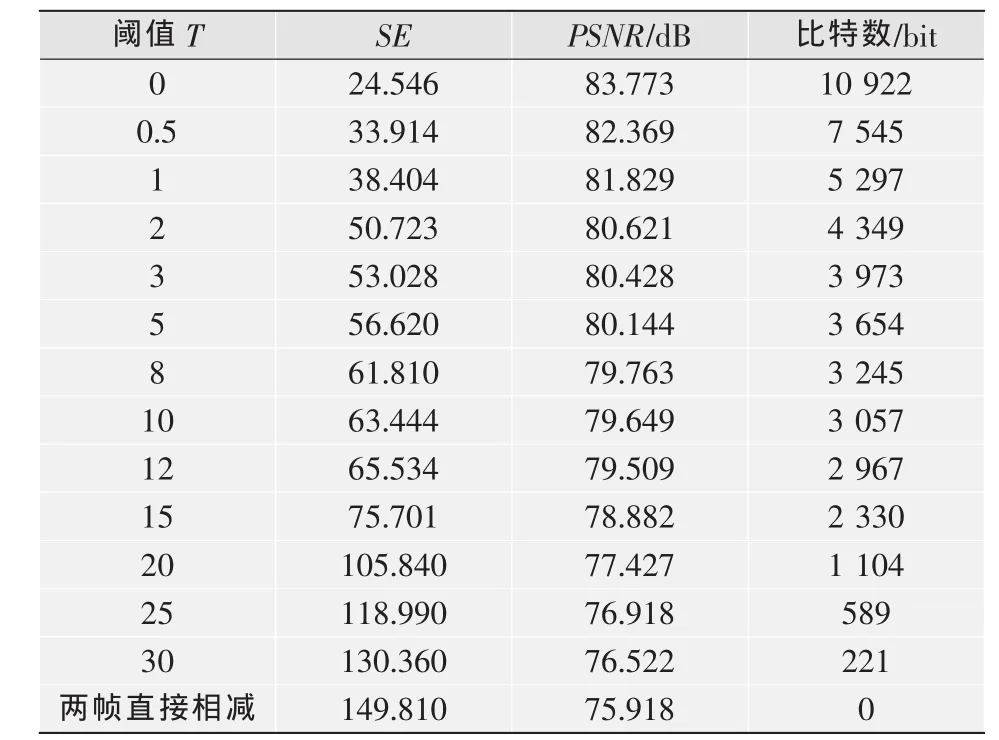
表2 stefan视频序列在不同阈值下的SE和PSNR和比特数
从两个实验结果可见,随着阈值的增大,运动矢量的比特数也随之减少,且减少的幅度较大。这样可以对运动矢量的比特流在任意点截取,将截取的运动矢量加入到参考帧中,以预测下一帧。这样做可以在预测时先传输一部分运动矢量,其后渐进传输剩下的运动矢量比特流,以逐步提高预测后的视频帧图像质量,达到质量可分级的目的。
5 小结
笔者提出了一种基于运动矢量可分级的视频编码方法,对运动矢量模进行判断,截取其比特流,以达到质量可分级,并通过实验分析,说明了该方法的可行性。但该方法的进一步应用还有诸多问题需要解决,如截取运动矢量比特流的方式、与熵编码的结合方式等,这也是下一步研究的方向。
[1]LI Weiping.Overview of fine granularity scalability in MPEG-4 video standard[J].IEEE Trans.Circuits and Systems,2001,11(3):301-317.
[2]哈力旦·A,方勇.一种改进的运动矢量编码方法[J].西安电子科技大学学报:自然科学版,2005,32(4):639-642.
[3]WANG Y,OSTERMANN J,ZHANG YQ.视频处理与通信[M].候正信,译.北京:电子工业出版社,2003.
[4]朱莹,郁梅,陈恳,等.H.264标准的新扩展——可伸缩性编码及应用[J].电视技术,2006(4):11-13.
[5]韩涛,王群生,杨春玲.精细可伸缩性视频编码的研究[J].电视技术,2007,31(9):12-14.
[6]杨雪婷,林其伟.基于H.264的精细可分级编码结构改进方案[J].电视技术,2009,33(S1)∶36-37.
[7]冯璐,鲍卫兵,刘峰.基于H.264的空间SVC快速模式选择算法[J].电视技术,2007,31(12):20-22.
[8]阎金,全子一,门爱东.基于H.264的时间可分级编码结构的研究[J].电视技术,2006(1):16-18.
[9]CHEN Peisong.Fully scalable subband/wavelet coding[D].Troy,NY USA:Rensselaer Polytechnic Institute,2003.
