电话语音中基于多说话人的声纹识别系统
2010-03-11郑燕琳杨晓炯许星宇
郑燕琳,杨晓炯,许星宇
(公安部第三研究所 上海 200031)
1 引言
声纹识别技术[1]是生物识别技术的一种,能够识别说话人的身份。在电话语音中,目前单说话人声纹识别有较高识别准确率,但是在实际应用中,说话人不可避免地会发生切换,或者由于设备的问题,不能将对话双方的语音自动分离,从而使得输入语音含有多个说话人,由于不能有效地将对话双方的语音自动分离,直接影响到系统的识别性能。本文依据电话语音特点和系统实际运行效率提出电话语音中基于多说话人的声纹识别系统,有效解决电话语音声纹识别在多说话人情况下的实际应用。
2 多说话人声纹识别
2.1 识别系统方案
多说话人声纹识别复杂性远大于单一说话人的纯净语音,系统需从多说话人混合语音中提取出单人的纯净语音,用于声纹识别系统的模型建立和比对识别。本文提出一种改进的语音分离技术——语音二次分离技术,在声纹识别系统模型建立和比对识别模块分别应用语音分离技术。同时,本文在系统实际应用中,根据实际运行效果和运行效率设定一些限定条件,以保证本系统的可行性。识别系统结构如图1所示。
2.2 语音分离
语音分离[2]是指从一段多人语音里将每个人语音分离出来,输出结果为多人各自的单人语音。一般来说,语音分离包括两个步骤:说话人分割和说话人聚类[3~5]。前者是指从多人语音中找到说话人身份发生变化的时间点;后者是指从多人语音中找出说话人的数目和每个说话人在什么时候说话,即按照语音段说话人的身份进行归类。电话语音声纹系统实际应用中,我们目前只分离包含两个说话人的电话语音,两人语音也是目前电话语音实际应用最常遇到的,3人以上语音分离效果比较差,实际使用中很少遇到,予以排除。本系统的多说话人语音分离都指两个说话人语音分离。语音分离结构如图2所示。
以往的语音分离算法有基于距离度量的分割聚类算法和基于模型搜索的分割聚类算法。前者是利用一定的距离度量准则来判断两段语音是属于同一个说话人还是属于不同的说话人,其有一定的应用局限性,对于不同的应用场景或说话人,需要设定不同的阈值;后者是利用得到的说话人模型来对原始多人语音按窗进行搜索,以便找出该话者发音的时间信息,这种算法用时长,初始模型训练选择的语音段不恰当会导致最后分割聚类的结果不好。本系统将两者有效结合起来,在基于UBM的说话人分割聚类算法[6]基础上提出二次语音分离技术,速度快,可取得较好效果。二次语音分离流程如图3所示。
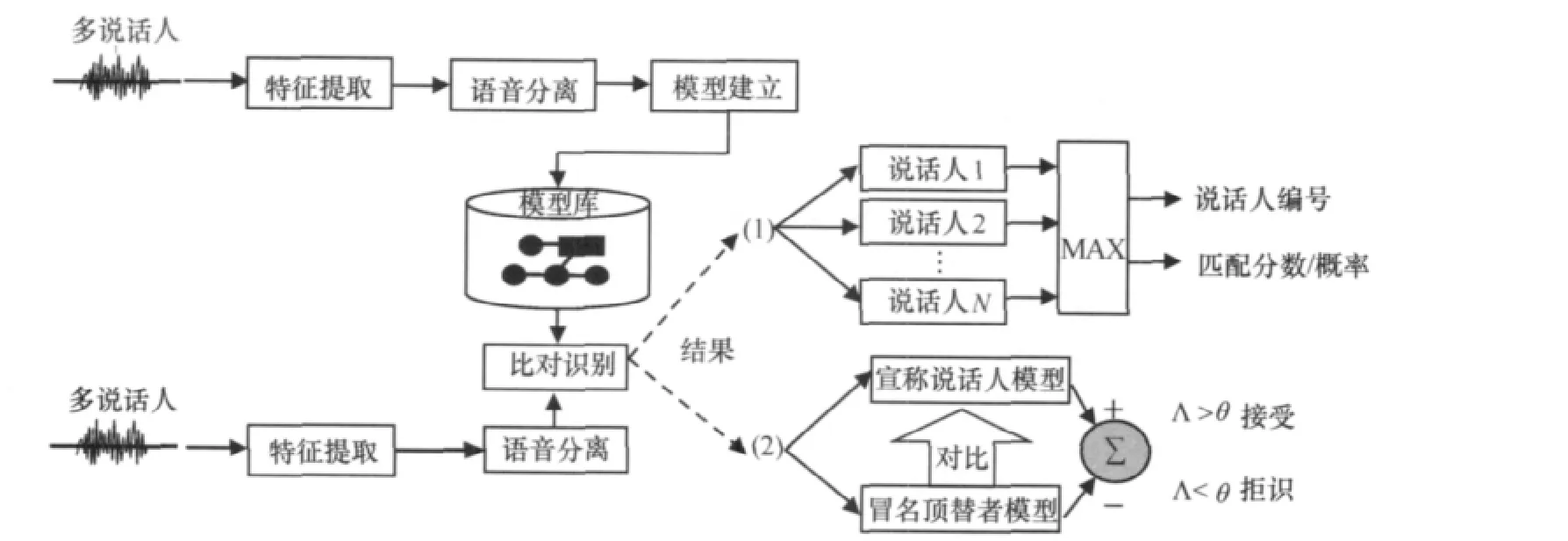
图1 识别系统结构框图
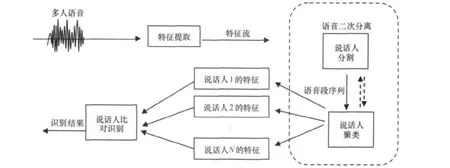
图2 语音分离结构框图

图3 二次语音分离流程图
基于UBM的说话人分割聚类算法包括3个步骤:初始分割采用UBM上的对数似然比分来作为电话交谈语音分割的一种度量准则,并利用BIC来对分割后的语音段进行合并判决,以降低算法的分割错误率;聚类阶段使用了说话人模型间的分数差来作为一种将语音段按说话人身份进行归类的判断准则;最后重分割降低初始分割时产生的漏检错误。此算法通过重分割虽然能降低分割点错误,但分割点错误处往往夹杂其他人的大段语音,类纯度不高,影响最终比对识别结果。本系统在前者分割聚类后的语音基础上进行语音二次分离,步骤如下。
(1)对UBM的说话人分割聚类后得到的语音建立模型 A、模型 B。
(2)分别对前者分割聚类后的语音进行分窗处理,使用的窗长为0.4 s,窗移为0.2 s。
(3)分窗后,对每窗语音计算在模型 A、模型 B下的ΔSiAB=L(Xi|SA)-L(Xi|SB),
①如果 ΔSiAB大于 0且 ΔSi+1AB大于 0,则该窗属于模型A;
②如果 ΔSiAB小于 0且 ΔSi+1AB小于 0,则该窗属于模型B;
③否则认为i窗语音属于两说话人混合区域,去掉该窗语音。
其中,ΔSiAB是i窗语音对于模型A和模型B的似然比分,ΔSi+1AB是i+1窗语音对于模型A和模型 B的似然比分,L(Xi|SA)和L(Xi|SB)分别为i窗语音在两模型上的似然得分。
通过在第一次语音分离的基础上进行二次分离,可进一步提高说话人纯度,提高比对识别准确率。
本系统根据实际运行效果和运行效率设定如下限定条件,以保证系统运行可行性。
·输入有效语音少于3 s,系统认为输入语音太短,影响后期识别效果,自动去除,分离后无输出语音。
·输入有效语音少于15 s,常常只含单个人说话语音,系统自动认为为一个说话人,分离输出一条语音。
·输入语音信噪比小于15 dB,处理为噪声,去噪过程中去除。
2.3 多说话人模型建立
电话语音声纹识别系统实际应用时,用于建模语音有单说话人和多说话人两种情况,系统无人监守,无法对单人语音和多人语音通过人为方式区分处理。通过实际应用测试,本系统提出对输入的语音全部进行语音分离,分离后人工选择所需语音,系统提供语音人工编辑功能,可依据实际需要选择是否人工编辑语音,之后将语音建立模型入库。多说话人模型建立结构如图4所示。
笔者认为,模型质量对系统声纹识别准确率影响非常大,建议在建立模型时,为了保证模型的质量,对系统语音自动分离后所选建模语音人为干预,手工编辑。
2.4 多说话人比对识别
本系统比对识别模块,对输入用于比对语音不分单说话人和多说话人,前端都进行语音分离,分离后两条语音无需处理,分别自动与库中模型进行比对识别,得到两个识别结果,匹配分数靠前者可作为最终结果参考。本系统此过程全程无人为干预,语音自动分离、自动比对识别,满足实际应用的需要。多说话人比对识别结构如图5所示。
3 系统应用与结论
本系统实际应用中,采用计算机Intel Core2 CPU,2 GB内存,语音数据为实际获取包含单说话人和多说话人的电话语音,语音覆盖男、女声音和CDMA、PSTN、GSM电话信道,语音包含彩铃、回铃音和各种环境噪音。语音共150条,选自15个说话人语音数据,每条语音时长2 min左右;3个电话信道各50条语音,各选自5个说话人语音,其中单说话人语音20条,多说话人语音30条。

图4 多说话人模型建立结构框图

图5 多说话人比对识别结构框图
测试本系统3个性能指标:语音分离准确率、系统比对识别准确率和系统比对效率,模型语音在语音二次分离后未经人工编辑直接建模。采用“类纯度”、“等错率”和“比对实时率”3个得分作为本系统测试的评测指标。类纯度指的是语音分离后,分离得到某个说话人中确实属于该说话人的语音帧数占所有语音帧数的比例,该值越大,分离效果越好;等错率指的是错误接受率和错误拒绝率相等时的错误率,该值越小,识别性能越好;比对实时率指的是单位时间内能够比对的有效语音数据长度,该值越大,比对速度越快。测试结果见表1、表2和表3。

表1 多说话人语音二次分离类纯度

表2 电话语音基于多说话人声纹识别系统识别等错率

表3 电话语音基于多说话人声纹识别系统比对实时率
从表1~3中可以看到,本系统在实际多说话人电话语音应用中,语音分离准确率达到85.8%,比对识别等错率低于20%,实时速度接近10。分离效果、比对识别效果基本满足应用要求。
本系统在电话语音单说话人声纹识别系统的基础上,研究多说话人声纹识别的实际应用,提出了在原有语音分离算法上改进的语音二次分离技术,并在系统模型建立和比对识别阶段策略性的应用语音二次分离技术,有效解决了电话语音多说话人声纹识别技术的应用,并在实际应用中取得了较好的效果。
1 Lawrence R.语音识别基本原理.北京:清华大学出版社,1999
2 李从清,孙立新,龙东等.语音分离技术的研究现状与展望.声学技术,2008,27(5):779~787
3 张薇,刘加.电话语音的多说话人分割聚类研究.清华大学学报(自然科学版),2008,48(4):575~578
4 何磊.语音识别中的说话人鲁棒性和自适应技术研究.清华大学计算机系博士学位论文,2001
5 Jing Deng,Thomas Fang Zheng,Wenhu Wu.UBM based speaker segmentation and clustering for 2-speaker detection.ISCSLP 2006
6 邓菁.电话信道下多说话人识别研究.清华大学计算机系博士学位论文,2006
