一种某高校网络用户上网形式的数据挖掘方法
2008-04-26康健
康 健
摘 要: 数据挖掘是利用各种分析工具在海量数据中发现某些模型和数据间关系的过程。如 何根据用户上网日志发现用户感兴趣的信息和资源,帮助网络中心科学地管理和规范其网络 用户,已经成为一个迫切的问题。本文通过问题陈述、数据搜集、数据预处理、数据挖掘和 结论几个步骤用SPSS软件对某高校某一时段的网络用户上网日志进行分析,为科学的网络管 理提供依据。
关键词:数据挖掘; SPSS; 上网日志
中图分类号:TP301 文献标识码:A 文章编号:1672-1098(2008)03-0069-04
数据挖掘是一个从大量数据中抽取挖掘出未知的、有价值的模式或规律等知识的过程 ,它已经成为各行各业对数据进行分析的不可或缺的手段。过去,各企业、政府部门、学校 、科研机构等往往投入大量资金去收集和存储数据,并把很多精力都放在提高存储效率上。 事实上,在这些海量数据中,只有一部分是有用的。现在,越来越多的企业认识到,从他们 的客户信息中挖掘出最有价值客户,或者从这些信息中找出客户消费的某种规律,要比存储 大量的历史数据更有价值。 这就是数据挖掘(data mining), 即在“数据”的矿山中挖掘 出“金块”。 数据挖掘可以在帮助企业减少不必要投资风险的同时提高资金收益, 它给企 业带来的回报几乎是无止境的。
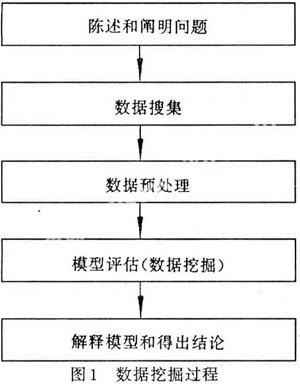
数据挖掘是一个利用各种分析工具在大量数据中发现模型和数据间关系的过程,这些模型和 关系可以用来做出预测[1]83。其程序一般包括:陈述和阐明问题、数据搜集、数 据预处理、模型评估、解释模型和得出结论。具体过程如图1数据挖掘过程所示。本文也将 根据这个流程,利用统计专业软件SPSS对某高校网络用户上网行为模式进行分析。
1 SPSS简介
SPSS(Statistical Package for the Social Science,社会科学统计软件包)。 是为了强调它在社会科学应用的一面(因为社会科 学研究中的许多现象都是随机的,要使用统计学来进行研究),而实际上广泛应用于经济学 、社会学、生物学、教育学、心理学、医学以及体育、工业、农业、林业、商业和金融等各 个领域[2]14。
SPSS集数据录入、资料编辑、数据管理、统计分析、报表制作、图形绘制为一体。SPS S统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线 性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类。SPSS也有专 门的绘图系统,可以根据数据绘制各种图形[2]15。
目前为止,SPSS已具有适合于DOS、Windows、Unix、Macintosh、OS/2等多种操作系统 使用的产品,本文使用的是Windows版本。
2 问题陈述
自从某高校校园网开通以来,其网络用户都是通过计费上网的。这就使该校网络中心 积累了大量的用户上网日志,数据量不断地迅速膨胀。 这些数据犹如茫茫的信息海洋,能 否 从中了解这些表面毫无关联的数据之间是否存在或多或少的关系?怎样才能找到这些关系并 运用到网络管理中呢?例如,能否有助于发现上网成瘾而影响学习的同学,为辅导员做好学 生工作提供帮助;对上网时间过长的用户加以适当限制等。这就是数据挖掘要做的工作。
本文会利用用户信息文件User.txt和用户上网日志文件Log.txt对网络用户的上网行为 模式进行分析。
2.1 数据搜集
本文是对两个数据文件进行分析的,分别是用户信息文件User.txt和用户上网日志文 件Log.txt。其中User.txt 为用户信息文件,主要包括:用户名和用户所在的用户组,其中 102代表研究生组,103代表本科生组,104代表教职工组,105代表办公用户组。Log.txt为 用户上网日志文件。
2.2 数据分析方法
要对数据进行分析,首先要将这些数据导入数据库中。因为最初获得的数据是.txt形 式的,所以要利用某种语言(如Java)编写的代码将其导入数据库的表中,或者直接利用某个 软件直接将其导入库中,如Microsoft SQL Server 2000 Enterprise Edition。本次分析 采用SPSS 15.0 for Windows。
3 数据预处理
(1) Log.txt数据导入 首先将Log.txt利用SPSS导入表中,可以发现总共有389 348条记 录,每条记录的格式如图2所示。其中的属性分别为用户IP、用户名、访问时间戳、端口、 访问方法、访问内容(即URL) 、版本、提交和发送的数据包以及传送方式。在导入时,此日 志是以空格作为分隔符的。

(2) User.txt数据导入 User.txt导入后的格式如图3所示,其中共有1 703条记录,属性分 别为用户名(userid)和用户组名(groupid)。其中:102代表研究生组,103代表本科生组,1 04代表教职工组,105代表办公用户组。

4 数据挖掘
4.1 用户上网日志文件的分析
[JP1]将Log.txt导入表中后,发现其中有一些属性如端口、版本、提交和发送的数据包以及传送 方式等在挖掘过程中是几乎没有用途的,所以可以将它们略去以节省资源。图4所示为用户 上网频数统计图。

从图4中可以发现user1601至user1728之间有一用户上网频 数遥遥领先于其他用户。再查频数统计表可以发现此用户为user1660,其上网频数为11 959 ,占全部用户总频数的3.1%。从user表中可以查出此用户属于104组(教职工组)。
对user1 660的上网记录进行分析,可以发现其记录是按照秒为单位进行计时的。此用户浏览 的网址多以 .gif结尾,且包含一些政府部门的网站,可以推断出:由于平时工作的繁 忙,该教师于2006年11月10日(周六休息日)在家或办公室浏览一些新闻及图片,了解国内外的时事政治;此用户还访问了一些论坛的网站,可以推断该教师可能比较喜欢在论坛 上和朋友们一起对某时事或观点发表言论;网站中还包含有“taobao”,推断该教师可能喜 欢网上购物,所以会访问诸如“淘宝”这类的大型网上购物网站。
4.2 用户信息文件的分析
表1所示为用户信息频数统计表,从表中看出用户组除了有103至1 05外,还包含有1、14、61、101、108和65 534,这些组共包含记录15条。将这15条记录当 作 错误信息处理。 剩下的1 688条记录中, 103(本科生组)的用户最多, 共731条, 占总用 户的42 .9%;其次是104(教职工组),共569条,占总用户的33.4%;102(研究生组)共299条,占17.6 %;105(办公用户组)共89条,占5.2%。
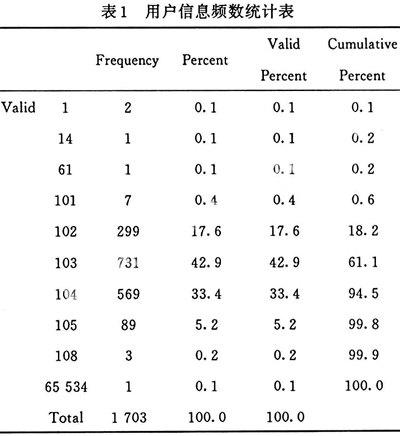
从这个表中可以发现本科生的上网用户数最多,可以分析是由两个原因造成的:一是 本科生在全校的人数最多,所占比例较大;二是2006年11月10日当天为周六休息日,学生不 用上课,所以网络用户较多。其次是教职工组用户,由于周六不是工作时间,所以这组用户 所占比重居第二。办公用户组所占比重最小,因为周六不是办公时间,大多数工作人员都休 息。
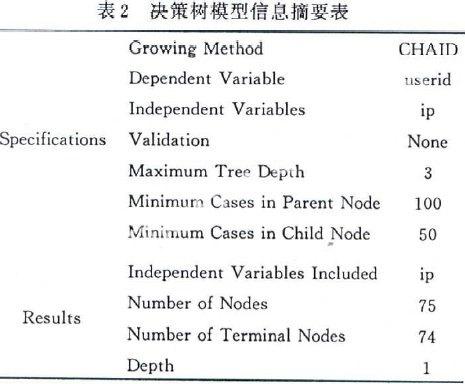
表2是用CHAID方法分析的决策树模型信息摘要表。因为记录太 多,所以只能抽样对其进行分析。从抽取的样本中可以看出,大多数用户上网时间较短。可 能因为当时是10/Nov/2006(周六),大多数用户都会选择周末给自己放个假,放松一星期上 班或上学疲惫的身心。预测随着时间渐晚直到周日,上网用户数会增长,用户上网时间也会 增加。
5 结论
数据挖掘是在大量数据中由未知去发现知识,属于挖掘型分析的范畴。挖掘型分析又 分为描述性分析和预测型分析。描述性分析用于了解系统实际数据存在的特性,其目的是为 预测做准备。预测型分析是在描述性分析得到结论的基础上对系统的发展进行估计,通过预 测型分析得到最终需要的结果,能够为决策者提供直接的依据[1]85。
描述性分析包含了关联分析、序列分析、聚类分析和滤除分析等方法。预测型分析包 含分类型预测和统计回归型预测。分类型预测是对某个事物可能归属于某个类别的概率进行 度量。回归型预测是指预测一个变量值的变化。预测型分析常用的数学模型包括:决策树模 型、规则推理模型和神经元网络模型[1]86。本文采用的是决策树模型中的CHAID方 法。
参考文献:
[1] 林宇等.数据仓库原理与实践[M].北京:人民邮电出版社,2003:83-86 .
[2] 米红,张文璋.实用现代统计分析方法与SPSS应用[M].北京:当代中国出 版社,2000:14-15.
[3] 高祥宝,董寒青.数据分析与SPSS应用[M].北京:清华大学出版社,2007.
[4] 陈文伟,黄金才.数据仓库与数据挖掘[M].北京:人民邮电出版社,2004.
[5] 陈京民.数据仓库与数据挖掘技术[M].北京.电子工业出版社,2002.
(责任编辑:李 丽)
